") AI訓練勢起,GPU要讓位了?
AI訓練勢起,GPU要讓位了?
電子發(fā)燒友網(wǎng)報道(文/周凱揚)人工智能在進化的過程中,最不可或缺的便是模型和算力。訓練出來的通用大模型省去了重復(fù)的開發(fā)工作,目前不少大模型都為學術(shù)研究和AI開發(fā)提供了方便,比如華為的盤古、搜狗的BERTSG、北京智源人工智能研究院的悟道2.0等等。
那么訓練出這樣一個大模型需要怎樣的硬件前提?如何以較低的成本完成自己模型訓練工作?這些都是不少AI初創(chuàng)企業(yè)需要考慮的問題,那么如今市面上有哪些訓練芯片是經(jīng)得起考驗的呢?我們先從國外的幾款產(chǎn)品開始看起。
英偉達A100
英偉達的A100可以說是目前AI訓練界的明星產(chǎn)品,A100剛面世之際可以說是世界上最快的深度學習GPU。盡管近來有無數(shù)的GPU或其他AI加速器試圖在性能上撼動它的地位,但綜合實力來看,A100依然穩(wěn)坐頭把交椅。

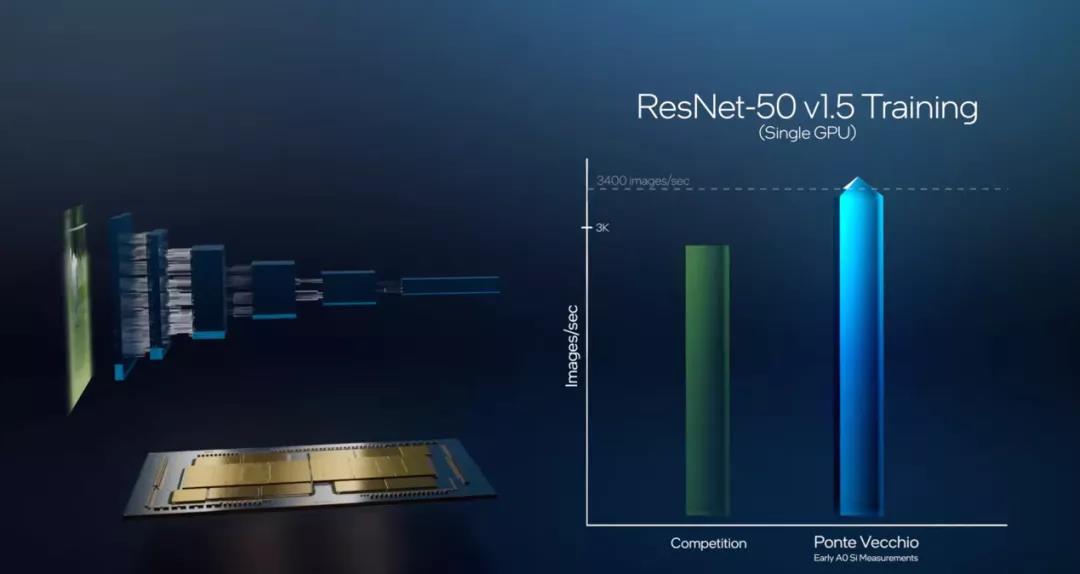
英特爾Gaudi和Ponte Vecchio
19年12月,英特爾收購了以色列的Habana Labs,將其旗下的AI加速器產(chǎn)品線納入囊中。Habana Labs目前推出了用于推理的Goya處理器和用于訓練的Gaudi處理器。盡管Habana Labs已經(jīng)隸屬英特爾,但現(xiàn)有的產(chǎn)品仍然基于臺積電的16nm制程,傳言稱其正在開發(fā)的Gaudi2將用上臺積電的7nm制程。 目前Gaudi已經(jīng)用于亞馬遜云服務(wù)AWS的EC2 DL1訓練實例中,該實例選用了AWS定制的英特爾第二代Xeon可擴展處理器,最多可配置8個Gaudi處理器,每個處理器配有32GB的HBM內(nèi)存,400Gbps的網(wǎng)絡(luò)架構(gòu)加上100Gbps的互聯(lián)帶寬,并支持4TB的NVMe存儲。

亞馬遜Trainium
最后我們以亞馬遜的訓練芯片收尾,亞馬遜提供的服務(wù)器實例可以說是最多樣化的,也包含了以上提到的A100和Gaudi。亞馬遜作為云服務(wù)巨頭,早已開始部署自己的服務(wù)器芯片生態(tài),不僅在今年推出了第三代Graviton服務(wù)器處理器,也正式發(fā)布了去年公開的訓練芯片Trainium,并推出了基于該芯片的Trn1實例。


小結(jié)
GPU一時半會不會跌落AI訓練的神壇,但其他訓練芯片的推陳出新證明了他們面對A100和Ponte Vecchio這種大規(guī)模芯片同樣不懼,甚至還有自己獨到的優(yōu)勢。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
gpu
+關(guān)注
關(guān)注
28文章
4767瀏覽量
129199 -
AI
+關(guān)注
關(guān)注
87文章
31438瀏覽量
269832
發(fā)布評論請先 登錄
相關(guān)推薦
GPU是如何訓練AI大模型的
在AI模型的訓練過程中,大量的計算工作集中在矩陣乘法、向量加法和激活函數(shù)等運算上。這些運算正是GPU所擅長的。接下來,AI部落小編帶您了解GPU
訓練AI大模型需要什么樣的gpu
訓練AI大模型需要選擇具有強大計算能力、足夠顯存、高效帶寬、良好散熱和能效比以及良好兼容性和擴展性的GPU。在選擇時,需要根據(jù)具體需求進行權(quán)衡和選擇。
PyTorch GPU 加速訓練模型方法
在深度學習領(lǐng)域,GPU加速訓練模型已經(jīng)成為提高訓練效率和縮短訓練時間的重要手段。PyTorch作為一個流行的深度學習框架,提供了豐富的工具和
GPU服務(wù)器AI網(wǎng)絡(luò)架構(gòu)設(shè)計
眾所周知,在大型模型訓練中,通常采用每臺服務(wù)器配備多個GPU的集群架構(gòu)。在上一篇文章《高性能GPU服務(wù)器AI網(wǎng)絡(luò)架構(gòu)(上篇)》中,我們對GPU

AI大模型的訓練數(shù)據(jù)來源分析
AI大模型的訓練數(shù)據(jù)來源廣泛且多元化,這些數(shù)據(jù)源對于構(gòu)建和優(yōu)化AI模型至關(guān)重要。以下是對AI大模型訓練數(shù)據(jù)來源的分析: 一、公開數(shù)據(jù)集 公開
GPU服務(wù)器在AI訓練中的優(yōu)勢具體體現(xiàn)在哪些方面?
GPU服務(wù)器在AI訓練中的優(yōu)勢主要體現(xiàn)在以下幾個方面: 1、并行處理能力:GPU服務(wù)器擁有大量的并行處理核心,這使得它們能夠同時處理成千上萬個計算任務(wù),極大地加速
蘋果承認使用谷歌芯片來訓練AI
蘋果公司最近在一篇技術(shù)論文中披露,其先進的人工智能系統(tǒng)Apple Intelligence背后的兩個關(guān)鍵AI模型,是在谷歌設(shè)計的云端芯片上完成預(yù)訓練的。這一消息標志著在尖端AI訓練領(lǐng)域
AI訓練的基本步驟
AI(人工智能)訓練是一個復(fù)雜且系統(tǒng)的過程,它涵蓋了從數(shù)據(jù)收集到模型部署的多個關(guān)鍵步驟。以下是對AI訓練過程的詳細闡述,包括每個步驟的具體內(nèi)容,并附有相關(guān)代碼示例(以Python和sc
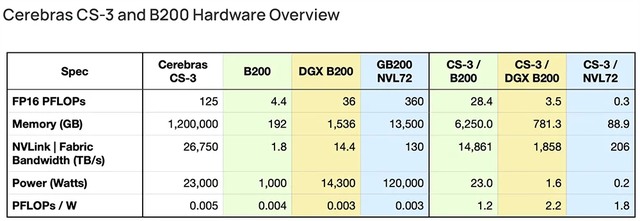
AI初出企業(yè)Cerebras已申請IPO!稱發(fā)布的AI芯片比GPU更適合大模型訓練
美國加州,專注于研發(fā)比GPU更適用于訓練AI模型的晶圓級芯片,為復(fù)雜的AI應(yīng)用構(gòu)建計算機系統(tǒng),并與阿布扎比科技集團G42等機構(gòu)合作構(gòu)建超級計算機。基于其最新旗艦芯片構(gòu)建的服務(wù)器可輕松高
摩爾線程與師者AI攜手完成70億參數(shù)教育AI大模型訓練測試
近日,國內(nèi)知名的GPU制造商摩爾線程與全學科教育AI大模型“師者AI”聯(lián)合宣布,雙方已成功完成了一項重要的大模型訓練測試。此次測試依托摩爾線程夸娥(KUAE)千卡智算集群,充分展現(xiàn)
AI訓練,為什么需要GPU?
隨著由ChatGPT引發(fā)的人工智能熱潮,GPU成為了AI大模型訓練平臺的基石,甚至是決定性的算力底座。為什么GPU能力壓CPU,成為炙手可熱的主角呢?要回答這個問題,首先需要了解當前人

國產(chǎn)GPU在AI大模型領(lǐng)域的應(yīng)用案例一覽
不斷推出新品,產(chǎn)品也逐漸在各個領(lǐng)域取得應(yīng)用,而且在大模型的訓練和推理方面,也有所建樹。 ? 國產(chǎn)GPU在大模型上的應(yīng)用進展 ? 電子發(fā)燒友此前就統(tǒng)計過目前國內(nèi)主要的GPU廠商,也介紹了

FPGA在深度學習應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
對神經(jīng)網(wǎng)絡(luò)進行任何更改,也不需要學習任何新工具。不過你可以保留你的 GPU 用于訓練。”
Zebra 提供了將深度學習代碼轉(zhuǎn)換為 FPGA 硬件指令的抽象層
AI 硬件前景
發(fā)表于 03-21 15:19





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論