 在不更改模型結構和不修改數據的情況下提升智能體
在不更改模型結構和不修改數據的情況下提升智能體
2018 年 Anderson 等人提出了視覺語言導航(Vision-and-Language Navigation,VLN)任務和對應的基準數據集(Room-to-Room Dataset)。該任務旨在探究智能體是否能在仿真模擬環境中遵循自然語言指令,因此可以形式化的評估智能體是否具有跨模態的理解能力。先前的工作取得了長足的進步,然而少有工作專注于探究智能體是否充分學習了數據中的信息,或者說,智能體是一個好學生嗎?在計算機視覺領域,Hlynsson 等人試圖通過衡量數據效率來回答這個問題。具體而言,該工作將模型性能作為數據集大小的函數,并衡量在不同規模數據集上模型的性能。在視覺語言導航領域,Huang 等人開發了基于神經網絡的數據鑒別器(discriminator),可以過濾低質量的指令路徑對以提升智能體的學習效率。而在本文中,我們試圖回答:能否在不更改模型結構和不修改數據的情況下進一步提升智能體?
我們監控了智能體在導航過程中所犯的第一個錯誤,并在下圖中展示了不同錯誤的比率。我們發現當智能體導航失敗時,大約 50% 的錯誤是由代理錯誤地預測下一個室內方向引起的。此類錯誤的比例隨著導航任務跨越更多房間而降低,但仍保持在一個較高水平。這些現象表明導航智能體受限于它在一個房間內和兩個房間之間導航的能力。因此,我們認為傳統學習過程使得智能體不能充分地學習數據中的信息,采用類似范式進行訓練的導航智能體很可能被低估了。
02 Methods
智能體在這些簡單案例上的糟糕表現激勵我們借鑒課程學習的想法。課程學習是一類關注數據集中樣本難度的分布的訓練范式,由 Bengio 于 2009 年提出,主要思想是模仿人類學習的特點,讓模型先從容易的樣本開始學習,并逐漸進階到復雜的樣本和知識。本文借鑒了課程學習的理念,首創性地提出了基于課程的 VLN 訓練范式。
首先,我們為導航任務設計了合適的課程。從抽象角度看,課程被視為一系列訓練準則。每個訓練準則都與訓練樣本上的一組不同的權重相關聯,或更普遍地,與訓練樣本分布的重新加權有關。要定義課程,首先需要定義樣本的難度。對于人類來說,很容易在很小的范圍內找到特定物體或地點。在經過簡單的探索后,人類就可以利用有關環境的知識來完成更艱巨的任務。因此,我們假設路徑 可以覆蓋的房間數量 主導了導航任務的難度級別。我們建議根據 對基準數據集R2R數據集進行重新劃分,劃分后的數據集如下表所示:
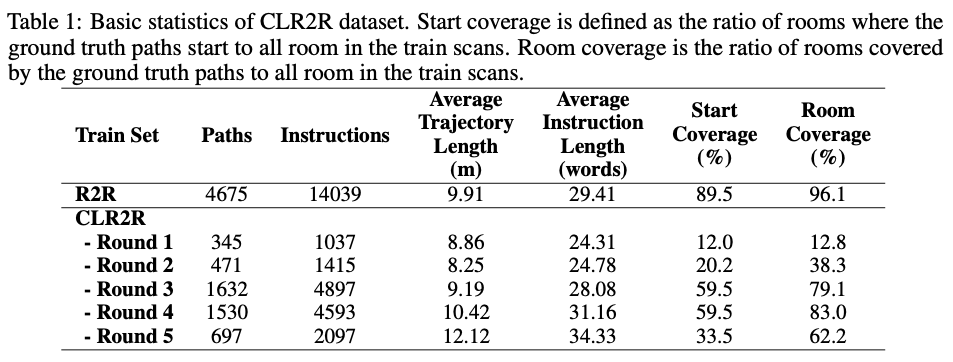
我們認為從簡單到困難的數據集劃分方式使得對智能體在這些子集上的學習與玩街機游戲非常相似,因此我們根據子集中樣本的難度將訓練集的各個子集命名為第一回合(Round 1)至第五回合(Round 5)。從平均路徑長度、平均指令長度和全景圖覆蓋率可以看出,我們劃分的數據子集呈現出明顯的階梯特征。這說明我們對數據集難度的劃分是合理的。新數據集被稱為為課程學習設計的R2R數據集(R2R for curriculum learning dataset,CLR2R dataset)。
有許多方法可以應用在 CLR2R 數據集上。如果我們將每個子集都視為一個課程,則 CLR2R 適用于自動課程學習。如果我們將整個數據集視為一個大課程,則每個回合中的樣本應被賦予相同的優先級,因此可以使用自定進度的課程學習。在本文中,我們將重點放在后一種模式上。
由 Jiang 等人提出的自定進度課程學習(Self-Paced Curriculum Learning,SPCL)是一種“師生協作”學習方法,它在統一框架中考慮了訓練之前人類對于數據的先驗知識和訓練過程中智能體對數據的學習進度。具體而言,SPCL 的目標損失函數定義為
其中 表示參數化的導航智能體, 是反映樣本重要性的權重變量。 稱為控制學習方案的自定進度函數, 是限制學習速度的超參數。 是編碼預定課程表(predetermined curriculum)信息的可行區域。本文將 CLR2R 數據集看作一個完整的課程。因此每個回合中的樣本應被賦予相同的課程等級。因此,在 CLR2R 數據集上只需 5 個標量就足以定義課程區域的參數向量。Jiang 等人討論了一些自定進度函數的具體形式,在本文中, 我們主要關注兩種較為簡單的自定進度函數:二進制方案(binary scheme)和線性方案(linear scheme)。
容易發現,公式(1)中的兩個參數是可以交替優化的。具體而言,對于參數 的優化是一個凸優化問題,
在 和簡單自定進度函數的條件下具有封閉解。本質上公式(2)是一個線性約束凸優化問題。對于一般的課程區域 我們可以應用投影梯度下降法(Projected Gradient Descent,PGD)來獲得最優權重 。
通常, 公式(1)中的優化問題可以采用交替凸搜索算法(Alternative Convex Search,ACS)求解。原始算法的主要問題是在第 4 步,其中使用固定的最新權重向量 來學習最佳模型參數 。在基于神經網絡的導航智能體的訓練中,由于梯度下降方法優化的神經網絡缺乏全局最優保證以及計算復雜度問題,我們不可能計算的確切最優值。因此本文建議無需計算確切的最小值,將原算法中的第 4 步替換為機器學習訓練范式中的多個梯度下降更新步驟。這樣做能使算法的速度加快,并且此時權重向量 實際上是通過考慮 “當前”學習進度而不是 “最終” 學習進度來更新的。
03 Experiments
3.1 Setup
在實驗中,我們采用了三種訓練范式
機器學習: 對訓練數據集進行一致采樣(Uniform Sampling),采樣得到的數據作為批數據(mini-batch)呈遞給模型進行學習。
樸素課程學習(Na?ve Curriculum Learning):對訓練集中的樣本從易到難進行排序,按照從易到難的順序將樣本呈遞給模型進行學習。具體而言, 智能體首先在 CLR2R 數據集的 Round 1 子集上進行學習, 然后在 Round 1~2 子集上進行學習, 最終在集合 Round 1~5 (也就是 R2R 的訓練集) 上進行學習。
自定進度課程學習(Self-Paced Curriculum Learning):如前所述,為了應用 SPCL 算法,我們需要首先確定課程區域和自定進度函數。對于課程區域,我們假設 CLR2R 數據集中每個 Round 子集中的樣本都具有相同的難度,因此我們設置 Round 。對于自定進度的函數,由于在導航任務中每個樣本對于的損失 是不受限的,因此我們選擇二進制方案和線性方案。
3.2 Results
主要結果:下表提供三個 SOTA 智能體在不同的訓練設置下在驗證集的上的實驗結果。實驗表明,采用自定進度課程學習訓練的智能體在已見和未見的驗證劃分上都可以達到最佳性能。
學習速率:整體而言,相比于傳統機器學習,采用自定進度課程學習訓練的智能體在迭代相同的次數之后可以獲得更優的性能表現。相同精度的結果,采用自定進度課程學習所需要的循環次數大大減少。這說明自定進度課程學習不僅可以提升模型的性能,還可以優化模型的訓練效率。
SPCL 超參數魯棒性:為了理解權重 初始化和步長 的選擇對自定進度課程學習的影響,我們對這兩個超參數進行網格搜索,結果如圖所示。下圖表明,自定進度課程學習對權重初始化和步長選擇并不敏感,在大多數情況下采用自定進度課程學習訓練的導航智能體在驗證集上的結果都要優于機器學習基準。
損失地形:為了探究自定進度課程學習為何能夠提升導航智能體的性能,我們遵循計算機視覺分析批歸一化采用的方法,通過計算最大和最小損失之間的距離來研究智能體訓練期間的損失地形。結果如圖所示。一般而言,我們的實驗結果與理論結果一致,即課程學習可以有效地平滑優化環境、改善損失地形。
遷移學習:使用課程學習訓練 的智能體既可以保持在 R2R 數據集上的導航性能,也能夠遷移到 RxR-en 數據集上完成更難的導航任務。
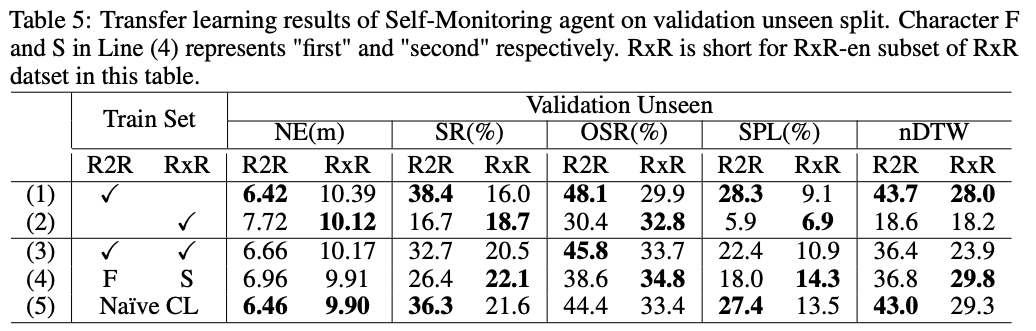
與預訓練方法結合:為了探究采用課程學習范式訓練的導航智能體是否也可以從預訓練方法中受益,我們將智能體與基于視覺語言 Transformer 的模型 VLN-BERT(Majumdar 等,2020)相結合。我們將束搜索大小限制為 5,并純粹使用 VLN-BERT 模型來評分和選擇路徑-指令對。在未見驗證劃分上的結果如圖所示。Beam search 和 VLN-BERT 都可以提高智能體的導航性能。通過基于課程的方法訓練的導航智能體獲得更多改進。
04 Conclusion
我們首先建議將有關訓練樣本的人類先驗知識整合到導航智能體的訓練過程中,首先提出采用課程學習對導航智能體進行訓練。
我們為視覺語言導航任務設計了第一個課程,并基于 Room-to-Room ( ) 數據集構建了可用于課程學習的第一個 VLN 數據集。
我們采用自定進度課程學習提出了一種導航智能體的訓練范式。這種訓練范式能在不增加模型復雜度的前提下提高智能體的訓練效率和性能。
我們驗證了課程學習的作用是平滑損失函數 (smooth loss landscape),從而加速學習進度、使智能體收斂到更好的局部最優點。
我們進一步的實驗表明,課程學習適用于遷移學習,并能與預訓練方法相結合。
責任編輯:haq
-
機器視覺
+關注
關注
162文章
4402瀏覽量
120552 -
導航
+關注
關注
7文章
532瀏覽量
42494
原文標題:NeurlPS2021 | 視覺語言導航的課程學習
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCM4222如何通過PCMEN在不RST情況下控制PCM輸出控制?

為什么電容在低電壓情況下會發熱







 工商網監
工商網監
評論