") 缺失值處理你確定你真的會(huì)了嗎
缺失值處理你確定你真的會(huì)了嗎
缺失值處理是一個(gè)數(shù)據(jù)分析工作者永遠(yuǎn)避不開(kāi)的話(huà)題,如何認(rèn)識(shí)與理解缺失值,運(yùn)用合適的方式處理缺失值,對(duì)模型的結(jié)果有很大的影響。本期Python數(shù)據(jù)分析實(shí)戰(zhàn)學(xué)習(xí)中,我們將詳細(xì)討論數(shù)據(jù)缺失值分析與處理等相關(guān)的一系列問(wèn)題。
作為數(shù)據(jù)清洗的一個(gè)重要環(huán)節(jié),一般從缺失值分析和缺失值處理兩個(gè)角度展開(kāi):-
缺失值分析
- 缺失值處理
Part 1
缺失值分析數(shù)據(jù)的缺失主要包括記錄的缺失和記錄中某個(gè)字段信息的缺失,兩者都會(huì)造成分析結(jié)果的不準(zhǔn)確,以下從缺失值類(lèi)型、產(chǎn)生的原因及影響等方面展開(kāi)分析。- 缺失值類(lèi)型
2、完全隨機(jī)丟失(MCAR,Missing Completely at Random)
數(shù)據(jù)的缺失是完全隨機(jī)的,不依賴(lài)于任何不完全變量或完全變量,不影響樣本的無(wú)偏性。3、非隨機(jī)丟失(MNAR,Missing not at Random)
數(shù)據(jù)的缺失與不完全變量自身的取值有關(guān)。正確的理解和判斷缺失值的類(lèi)型,對(duì)工作中對(duì)缺失值分析和處理帶來(lái)很大對(duì)便利,但因沒(méi)有一套成熟但缺失值類(lèi)型判斷方法,大多考經(jīng)驗(yàn)處理,這里不作過(guò)多闡述。- 缺失值成因
1、信息暫時(shí)無(wú)法獲取、獲取信息代價(jià)太大;
2、信息因人為因素沒(méi)有被記錄、遺漏或丟失;3、部分對(duì)象或某些屬性不可用或不存在;4、信息采集設(shè)備故障、存儲(chǔ)介質(zhì)、傳輸媒體或其他物理原因造成的數(shù)據(jù)丟失。- 缺失值影響
1、使系統(tǒng)丟失大量的有用信息;
2、使系統(tǒng)中所表現(xiàn)出的不確定性更加顯著,系統(tǒng)中蘊(yùn)涵的確定性成分更難把握;3、包含空值的數(shù)據(jù)會(huì)使數(shù)據(jù)挖掘過(guò)程陷入混亂,導(dǎo)致不可靠的輸出。- 缺失值分析
data.info(); data.describe()來(lái)查看數(shù)據(jù)的基本情況。代碼:
>>>data.info()
輸出結(jié)果:
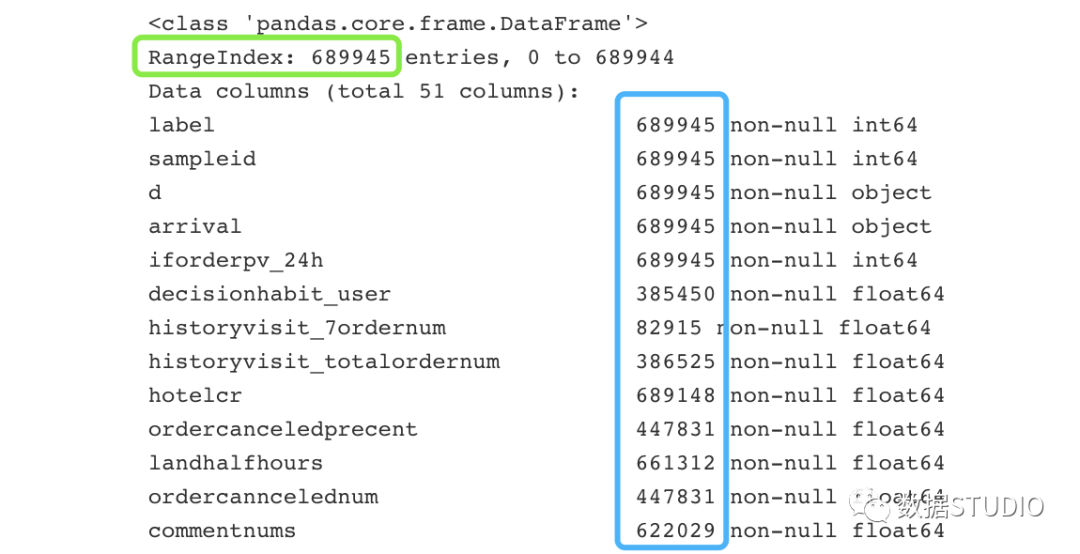
結(jié)果圖中綠色框是數(shù)據(jù)總索引數(shù),藍(lán)色框?yàn)槊總€(gè)變量的總記錄數(shù),它們的差值為每個(gè)變量的缺失值總數(shù)。代碼:
>>>data.describe()
輸出結(jié)果:
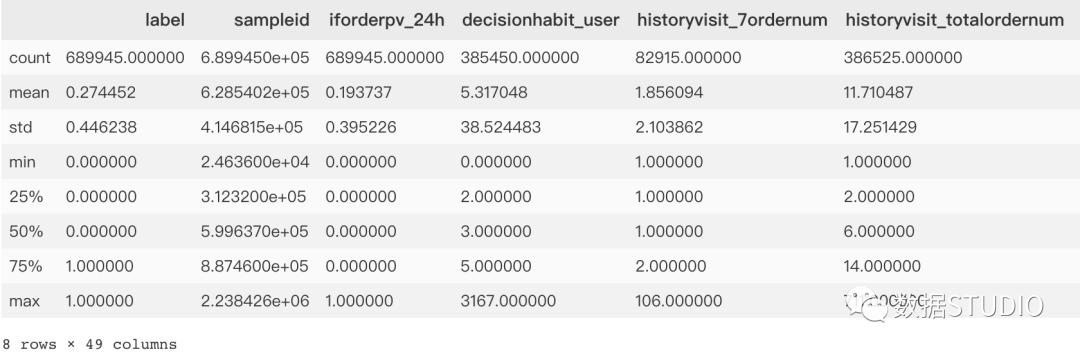
結(jié)果圖中count為每個(gè)變量的非空計(jì)數(shù),其與總索引數(shù)的差值,即為缺失值總數(shù)。
以上方法在查看數(shù)據(jù)的總體概況下表現(xiàn)較佳,但用于數(shù)據(jù)缺失值分析顯得力不從心。下面介紹幾個(gè)更加便于缺失值分析的方法。
-
統(tǒng)計(jì)缺失值
>>>importpandasaspd
>>>missing=data.isnull().sum().reset_index().rename(columns={0:'missNum'})
>>>missing.head(10)
輸出結(jié)果:
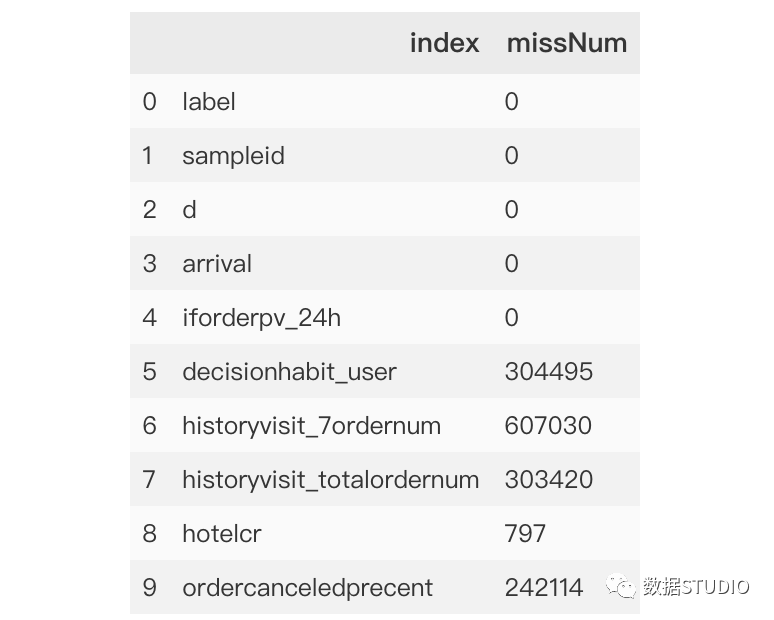
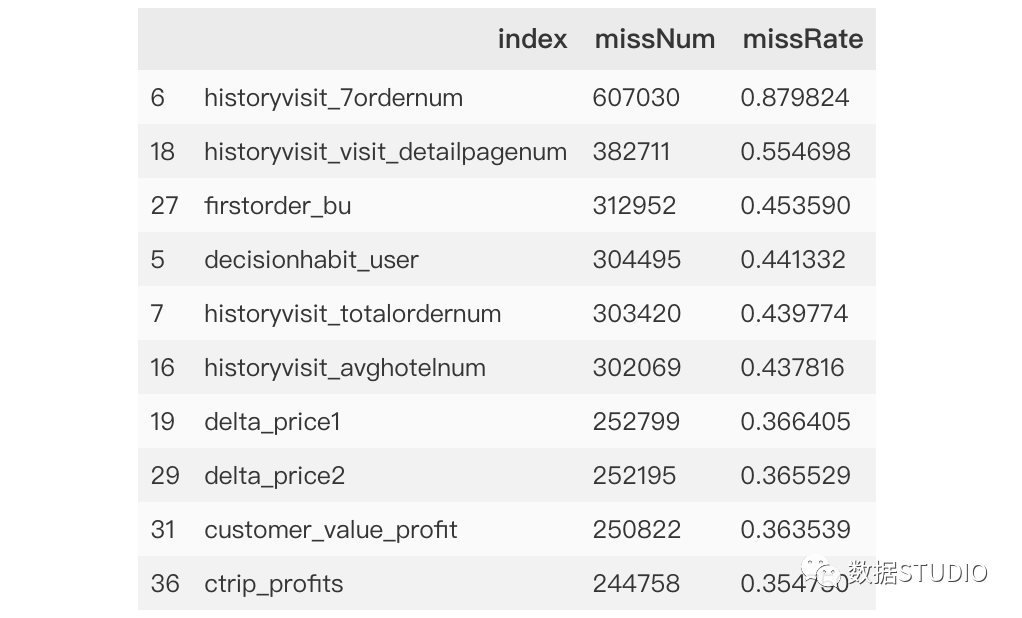
為方便展示,本例中只顯示前10個(gè)特征。從上面數(shù)據(jù)描述查看信息data.info()可以看出,本數(shù)據(jù)總計(jì)為689945條,從missNum中可以清洗看出每條特征變量的缺失情況:索引0-4為無(wú)缺失特征,索引8為缺失最少,而索引6則缺失超60萬(wàn)條。
-
計(jì)算缺失值比例
>>>missing['missRate']=missing['missNum']/data.shape[0]
>>>missing.head(10)
輸出結(jié)果:data.shape[0] 得到數(shù)據(jù)記錄總數(shù)。
missing.head(10) 只顯示前10條記錄。
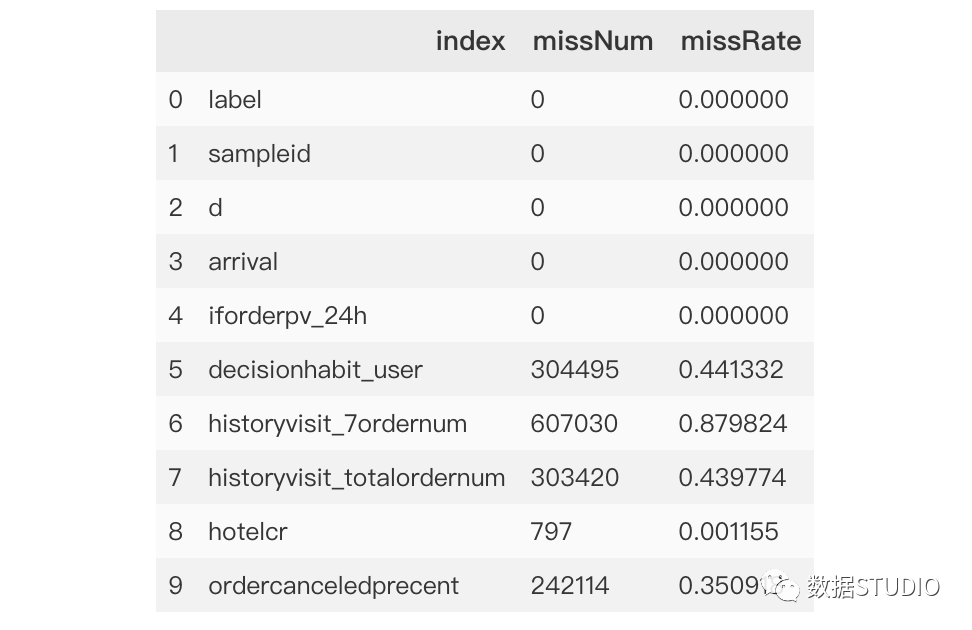
missNum 比數(shù)據(jù)總量data.shape[0] 得到缺失比值missRate,這樣更加直觀地看出缺失值相對(duì)數(shù)量,便于后續(xù)選擇合適的缺失值處理。-
按照缺失率排序顯示
代碼:
>>>miss_analy=missing[missing.missRate>0].sort_values(by='missRate',ascending=False)
>>>miss_analy.head(10)
輸出結(jié)果:miss_analy 存儲(chǔ)的是每個(gè)變量缺失情況的數(shù)據(jù)框。
-
缺失值可視化
matplotlib庫(kù)--條形圖
利用常規(guī)matplotlib.pyplot庫(kù)可視化出每個(gè)變量的缺失值比例,以及總體排名情況,一目了然。代碼:
>>>importmatplotlib.pyplotasplt
>>>importpylabaspl
>>>colors=['DeepSkyBlue','DeepPink','Yellow','LawnGreen','Aqua','DarkSlateGray']
>>>fig=plt.figure(figsize=(20,6))
>>>plt.bar(np.arange(miss_analy.shape[0]),list(miss_analy.missRate.values),align='center',color=colors)
>>>font={'family':'TimesNewRoman','weight':'normal','size':23,}
>>>plt.title('Histogramofmissingvalueofvariables',fontsize=20)
>>>plt.xlabel('variablesnames',font)
>>>plt.ylabel('missingrate',font)
#添加x軸標(biāo)簽,并旋轉(zhuǎn)90度
>>>plt.xticks(np.arange(miss_analy.shape[0]),list(miss_analy['index']))
>>>pl.xticks(rotation=90)
#添加數(shù)值顯示
>>>forx,yinenumerate(list(miss_analy.missRate.values)):
plt.text(x,y+0.08,'{:.2%}'.format(y),ha='center',rotation=90)
>>>plt.ylim([0,1.2])
#保存圖片
>>>fig.savefig('missing.png')
>>>plt.show()
條形圖繪制參數(shù)詳解:bar(left, height, width=0.8, bottom=None, color=None, edgecolor=None, linewidth=None, tick_label=None, xerr=None, yerr=None, label = None, ecolor=None, align, log=False, **kwargs)x:sequence of scalars 傳遞數(shù)值序列,指定條形圖中x軸上的刻度值。
height:scalar or sequence of scalars傳遞標(biāo)量或標(biāo)量序列,指定條形圖y軸上的高度。
width:scalar or array-like, optional,default: 0.8 指定條形圖的寬度,默認(rèn)為0.8.
bottom:scalar or array-like, optional, default: 0條形基的y坐標(biāo), 用于繪制堆疊條形圖。
align:{'center', 'edge'}, optional, default: 'center'
*"center": 在 x 位置上居中。*"edge": 用 x 位置對(duì)齊條的左邊。要對(duì)齊右邊緣上的條,請(qǐng)通過(guò)一個(gè)負(fù)的 width 和 "align='edge' "。color:scalar or array-like, optional 指定條形圖的填充色。
edgecolor:scalar or array-like, optional 指定條形圖的邊框色。
linewidth:scalar or array-like, optional 指定條形圖邊框的寬度,如果指定為0,表示不繪制邊框。
tick_label:string or array-like,optional 指定條形圖的刻度標(biāo)簽。
xerr,yerr:scalar or array-like of shape(N,) or shape(2,N), optional,defaultNone
如果 not None,表示在條形圖的基礎(chǔ)上添加誤差棒;值是相對(duì)于數(shù)據(jù) +/- 誤差棒大小;*標(biāo)量: 對(duì)稱(chēng)的+/- 誤差棒值為所有條;*shape(N,): 每個(gè)bar對(duì)稱(chēng)+/- 誤差棒值;*shape(2,n): 為每個(gè)bar分別設(shè)置-和+ 誤差棒值。第一行包含較低的錯(cuò)誤,第二行包含上的錯(cuò)誤。* None:沒(méi)有錯(cuò)誤。(默認(rèn))label:string or array-like, optional 指定條形圖的標(biāo)簽,一般用以添加圖例。
ecolor:scalar or array-like, optional, default: 'black'ecolor 指定條形圖誤差棒的顏色。*align:指定x軸刻度標(biāo)簽的對(duì)齊方式,默認(rèn)為'center',表示刻度標(biāo)簽居中對(duì)齊,如果設(shè)置為'edge',則表示在每個(gè)條形的左下角呈現(xiàn)刻度標(biāo)簽。
log:bool, optional, default: False 是否對(duì)坐標(biāo)軸進(jìn)行l(wèi)og變換。
**kwargs 關(guān)鍵字參數(shù),用于對(duì)條形圖進(jìn)行其他設(shè)置,如透明度等。
missingno庫(kù)--矩陣圖、條形圖、熱圖、樹(shù)狀圖
mssingno
- 矩陣圖
代碼:
>>>importmissingnoasmsno
>>>msno.matrix(data,labels=True)
矩陣圖繪制參數(shù)詳解:msno.matrix(df,filter=None, n=0, p=0, sort=None, figsize=(25, 10), width_ratios=(15, 1), color=(0.25, 0.25, 0.25), fontsize=16, labels=None, sparkline=True, inline=False, freq=None, ax=None)df:DataFrame, default None 被映射的
"DataFrame"。filter: str, default None 用于熱圖的濾鏡。可以是
"top","bottom",或"None"(默認(rèn))之一。n:int, default 0過(guò)濾后的數(shù)據(jù)格式中包含的最大列數(shù)。
P:int, default 0過(guò)濾后的數(shù)據(jù)框中列的最大填充百分比。
sort:str, default None 要應(yīng)用的行排序順序。可以是
"ascending"、"descending",或"None"(默認(rèn))。figsize:tuple, default (25, 10) 顯示的圖形的大小。
fontsize:int, default 16圖形的字體大小。
labels:list, default None是否顯示列名。如果有的話(huà),當(dāng)數(shù)據(jù)列數(shù)為50列或更少默認(rèn)為基礎(chǔ)數(shù)據(jù)標(biāo)簽,超過(guò)50列時(shí)不使用標(biāo)簽。
sparkline:bool default True 是否顯示
sparkline。width_ratios:tuple default (15,1)矩陣的寬度與
sparkline的寬度之比。如果"sparkline=False",則不執(zhí)行任何操作。color:default (0.25,0.25,0.25) 填充欄的顏色。
實(shí)際使用中,直接使用默認(rèn)值即能滿(mǎn)足大部分情況下的需求。如常用的參數(shù)labels能夠根據(jù)數(shù)據(jù)標(biāo)簽的數(shù)量自動(dòng)選擇參數(shù)值。
-
條形圖
---- 是針對(duì)標(biāo)簽列缺失值的簡(jiǎn)單可視化
代碼:
>>>msno.bar(data.iloc[:,0:18])#使用默認(rèn)參數(shù)即可
矩陣圖繪制參數(shù)簡(jiǎn)介:
msno.bar(df, figsize=(24, 10), fontsize=16, labels=None, log=False, color='dimgray', inline=False, filter=None, n=0, p=0, sort=None, ax=None,)從參數(shù)列表中可以看出,條形圖與矩陣圖參數(shù)類(lèi)似,其中參數(shù)
inline將在后面的版本中刪除,可以忽略。"The 'inline' argument has been deprecated, and will be removed in a future version"
missingno的條形圖與matplotlib條形圖有異曲同工之秒:封裝的庫(kù),使用更加方便,既能看出缺失值數(shù)量,又能看出缺失值對(duì)百分比。可通過(guò)參數(shù)對(duì)特征變量按照缺失值缺失情況排序顯示。代碼:
>>>msno.bar(data.iloc[:,0:18],sort='descending')
細(xì)心的讀者不難看出,此圖與上圖(未排序)的主題風(fēng)格并不相同,可利用matplotlib.pyplot來(lái)設(shè)置主題:
>>>importmatplotlib.pyplotasplt
>>>plt.style.use('seaborn')
>>>%matplotlibinline
- 熱圖
----相關(guān)性熱圖措施無(wú)效的相關(guān)性:一個(gè)變量的存在或不存在如何強(qiáng)烈影響的另一個(gè)的存在。
代碼:
>>>msno.heatmap(data.iloc[:,0:13])#使用默認(rèn)參數(shù)即可
輸出結(jié)果:
兩個(gè)變量的無(wú)效相關(guān)范圍從-1(如果一個(gè)變量出現(xiàn),另一個(gè)肯定沒(méi)有)到0(出現(xiàn)或不出現(xiàn)的變量對(duì)彼此沒(méi)有影響)到1(如果一個(gè)變量出現(xiàn),另一個(gè)肯定也是)。
數(shù)據(jù)全缺失或全空對(duì)相關(guān)性是沒(méi)有意義的,所以就在圖中就沒(méi)有了,比如date列就沒(méi)有出現(xiàn)在圖中。
大于-1和小于1表示有強(qiáng)烈的正相關(guān)和負(fù)相關(guān),但是由于極少數(shù)的臟數(shù)據(jù)所以并不絕對(duì),這些例外的少數(shù)情況需要在數(shù)據(jù)加工時(shí)候予以注意。
熱圖方便觀察兩個(gè)變量間的相關(guān)性,但是當(dāng)數(shù)據(jù)集變大,這種結(jié)論的解釋性會(huì)變差。
-
樹(shù)狀圖
代碼:
>>>msno.dendrogram(data.iloc[:,0:18])
輸出結(jié)果:樹(shù)狀圖采用由scipy提供的層次聚類(lèi)算法通過(guò)它們之間的無(wú)效相關(guān)性(根據(jù)二進(jìn)制距離測(cè)量)將變量彼此相加。在樹(shù)的每個(gè)步驟中,基于哪個(gè)組合最小化剩余簇的距離來(lái)分割變量。變量集越單調(diào),它們的總距離越接近0,并且它們的平均距離越接近零。
在0距離處的變量間能彼此預(yù)測(cè)對(duì)方,當(dāng)一個(gè)變量填充時(shí)另一個(gè)總是空的或者總是填充的,或者都是空的。
樹(shù)葉的高度顯示預(yù)測(cè)錯(cuò)誤的頻率。
和矩陣Matrix一樣,只能處理50個(gè)變量,但是通過(guò)簡(jiǎn)單的轉(zhuǎn)置操作即可處理更多更大的數(shù)據(jù)集。
這樣的統(tǒng)計(jì)計(jì)算以及可視化基本已經(jīng)看出哪些變量缺失,以及缺失比例情況,對(duì)數(shù)據(jù)即有個(gè)缺失概況。
Part 2缺失值處理
缺失值處理思路
先通過(guò)一定的方法找到缺失值,接著分析缺失值在整體樣本中的分布占比,以及缺失值是否具有顯著的無(wú)規(guī)律分布特征,即第一部分介紹到缺失值分析。然后考慮使用的模型中是否滿(mǎn)足缺失值的自動(dòng)處理,最后決定采用那種缺失值處理方法,即接下來(lái)介紹到缺失值處理。缺失值處理?法的選擇,主要依據(jù)是業(yè)務(wù)邏輯和缺失值占比,在對(duì)預(yù)測(cè)結(jié)果的影響盡可能小的情況下,對(duì)缺失值進(jìn)行處理以滿(mǎn)足算法需求,所以要理解每個(gè)缺失值處理方法帶來(lái)的影響,下?的缺失值處理?法沒(méi)有特殊說(shuō)明均是對(duì)特征(列,變量)的處理。
- 丟棄
-
占?較多,如80%以上時(shí),刪除缺失值所在的列如果某些行缺失值占比較多,或者缺失值所在字段是苛刻的必須有值的,刪除行。
#刪除‘col’列
>>>data.drop('col',axis=1,inplace=True)
#刪除數(shù)據(jù)表中含有空值的行
>>>data.dropna()
#丟棄某幾列有缺失值的行
>>>data.dropna(axis=0,subset=['a','b'],inplace=True)
#去掉缺失比例大于80%以上的變量
>>>data.dropna(thresh=len(data)*0.2,axis=1)
參數(shù)詳解:
data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)inplace : bool, default False 如果為真,執(zhí)行就地操作并返回None。
subset : array-like, optional 要考慮沿著其他軸的標(biāo)簽,例如,如果您要?jiǎng)h除行,這些將是要包含的列的列表。
thresh : int, optional, default 'any' 只保留至少有thresh個(gè)非na值的行。
how : {'any', 'all'},default 'any' 確定是否從DataFrame中刪除了行或列至少有一個(gè)NA或全部NA。* 'any':如果有任何NA值,刪除行或列。* 'all':如果所有的值都是NA,刪除行或列。
axis : {0 or 'index', 1 or 'columns'}, default 0 確定包含缺失值的行或列是否為移除。* 0,或“索引”:刪除包含缺失值的行。* 1,或“columns”:刪除包含缺失值的列。
- 補(bǔ)全
-
占比一般,30%-80%時(shí),將缺失值作為單獨(dú)的?個(gè)分類(lèi)如果特征是連續(xù)的,則其他已有值分箱如果特征是分類(lèi)的,考慮其他分類(lèi)是否需要重分箱
-
- 等深分箱法(統(tǒng)一權(quán)重法): 將數(shù)據(jù)集按記錄(行數(shù))分箱,每箱具有相同的記錄數(shù)(元素個(gè)數(shù))。每箱記錄數(shù)稱(chēng)為箱子深度(權(quán)重)。
- 等寬分箱法(統(tǒng)一區(qū)間法): 使數(shù)據(jù)集在整個(gè)屬性值的區(qū)間上平均分布,即每個(gè)箱的區(qū)間范圍(箱子寬度)是一個(gè)常量。
- 用戶(hù)自定義區(qū)間:當(dāng)用戶(hù)明確希望觀察某些區(qū)間范圍內(nèi)的數(shù)據(jù)時(shí),可根據(jù)需要自定義區(qū)間。
-
占?比少,10%-30%時(shí),一般使用模型法,基于已有的其他字段,將缺失字段作為目標(biāo)變量進(jìn)行預(yù)測(cè),從而得到最為可能的不全值。連續(xù)型變量用回歸模型補(bǔ)全;分類(lèi)變量用分類(lèi)模型補(bǔ)全。如進(jìn)行多重插補(bǔ)、KNN算法填充、隨機(jī)森林填補(bǔ)法,我們認(rèn)為若干特征之間有相關(guān)性的,可以相互預(yù)測(cè)缺失值。
# interpolate()插值法,缺失值前后數(shù)值的均值,但是若缺失值前后也存在缺失,則不進(jìn)行計(jì)算插補(bǔ)。
>>>data['a']=data['a'].interpolate()
#用前面的值替換,當(dāng)?shù)谝恍杏腥笔е禃r(shí),該行利用向前替換無(wú)值可取,仍缺失
>>>data.fillna(method='pad')
#用后面的值替換,當(dāng)最后一行有缺失值時(shí),該行利用向后替換無(wú)值可取,仍缺失
>>>data.fillna(method='backfill')#用后面的值替換
B. 多重插補(bǔ)法
常見(jiàn)插值函數(shù):牛頓插值法、分段插值法、樣條插值法、Hermite插值法、埃爾米特插值法和拉格朗日插值法,以下詳細(xì)介紹拉格朗日插值法的原理和使用。
>>>fromscipy.interpolateimportlagrange
>>>x=[1,2,3,4,7]
>>>y=[5,7,10,3,9]
>>>f=lagrange(x,y)
'numpy.lib.polynomial.poly1d'>4
#這一行是輸出a的類(lèi)型,以及最高次冪。
>>>print(f)
432
0.5472x-7.306x+30.65x-47.03x+28.13
#第一行和第二行就是插值的結(jié)果,顯示出的函數(shù)。第二行的數(shù)字是對(duì)應(yīng)下午的x的冪,
>>>print(f(1),f(2),f(3))
5.0000000000000077.00000000000001410.00000000000005
#此行是代入的x值,得到的結(jié)果。即用小括號(hào)f(x)的這種形式,可以直接得到計(jì)算結(jié)果。
>>>print(f[0],f[2],f[3])
28.1333333333333430.65277777777778-7.3055555555555545
#此行是提取出的系數(shù)。即可以用f[a]這種形式,來(lái)提取出來(lái)對(duì)應(yīng)冪的系數(shù)。
C. KNN填充利用KNN算法填充,將目標(biāo)列當(dāng)做目標(biāo)標(biāo)簽,利用非缺失的數(shù)據(jù)進(jìn)行KNN算法擬合,最后對(duì)目標(biāo)標(biāo)簽缺失值進(jìn)行預(yù)測(cè)。(對(duì)于連續(xù)特征一般是用加權(quán)平均法,對(duì)于離散特征一般是用加權(quán)投票法)拉格朗日插值法
from scipy.interpolate import lanrange對(duì)于空間上已知的n個(gè)點(diǎn)(無(wú)兩點(diǎn)在一條直線(xiàn)上)可以找到一個(gè) n-1 次多項(xiàng)式 ,使得多項(xiàng)式曲線(xiàn)過(guò)這個(gè)點(diǎn)。需滿(mǎn)?的假設(shè):MAR:Missing At Random,數(shù)據(jù)缺失的概率僅和已觀測(cè)的數(shù)據(jù)相關(guān),即缺失的概率與未知的數(shù)據(jù)無(wú)關(guān),即與變量的具體數(shù)值無(wú)關(guān)。迭代(循環(huán))次數(shù)可能的話(huà)超過(guò)40,選擇所有的變量甚至額外的輔助變量。
>>>fromsklearn.neighborsimportKNeighborsClassifier,KNeighborsRegressor
>>>defKNN_filled_func(X_train,y_train,X_test,k=3,dispersed=True):
..."""
...X_train為目標(biāo)列中不含缺失值的數(shù)據(jù)(不包括目標(biāo)列)
...y_train為不含缺失值的目標(biāo)標(biāo)簽
...X_test為目標(biāo)列中為缺失值的數(shù)據(jù)(不包括目標(biāo)列)
..."""
...ifdispersed:
...KNN=KNeighborsClassifier(n_neighbors=k,weights="distance")
...else:
...KNN=KNeighborsRegressor(n_neighbors=k,weights="distance")
...KNN.fit(X_train,y_train)
...returnX_test.index,KNN.predict(X_test)
D. 隨機(jī)森林填補(bǔ)法
其思想與KNN填補(bǔ)法類(lèi)似。
>>>fromsklearn.ensembleimportRandomForestRegressor,RandomForestClassifier
>>>defRF_filled_func(X_train,y_train,X_test,k=3,dispersed=True):
..."""
...X_train為目標(biāo)列中不含缺失值的數(shù)據(jù)(不包括目標(biāo)列)
...y_train為不含缺失值的目標(biāo)標(biāo)簽
...X_test為目標(biāo)列中為缺失值的數(shù)據(jù)(不包括目標(biāo)列)
..."""
...ifdispersed:
...rf=RandomForestRegressor()
...else:
...rf=RandomForestClassifier()
...rf.fit(X_train,y_train)
...returnX_test.index,rf.predict(X_test)
- 占?較少,10%以下,一般使用統(tǒng)計(jì)法(連續(xù)型變量用均值、中位數(shù)、加權(quán)均值;分類(lèi)型變量用眾數(shù))。
-
平均值適用于近似正態(tài)分布數(shù)據(jù),觀測(cè)值較為均勻散布均值周?chē)?/span>
-
中位數(shù)適用于偏態(tài)分布或者有離群點(diǎn)數(shù)據(jù),中位數(shù)是更好地代表數(shù)據(jù)中心趨勢(shì);
-
眾數(shù)一般用于類(lèi)別變量,無(wú)大小、先后順序之分。
pandas 內(nèi) df.fillna() 處理缺失值
#均值填充
>>>data['col']=data['col'].fillna(data['col'].means())
#中位數(shù)填充
>>>data['col']=data['col'].fillna(data['col'].median())
#眾數(shù)填充
>>>data['col']=data['col'].fillna(stats.mode(data['col'])[0][0])
-
sklearn.preprocessing.Imputer()處理缺失值
>>>fromsklearn.preprocessingimportImputer
>>>imr=Imputer(missing_values='NaN',strategy='mean',axis=0)
>>>imputed_data=pd.DataFrame(imr.fit_transform(df.values),columns=df.columns)
>>>imputed_data
此外還有結(jié)合實(shí)際,運(yùn)用專(zhuān)家補(bǔ)全。
-
真值轉(zhuǎn)化法
認(rèn)為缺失值本身以一種數(shù)據(jù)分布規(guī)律存在。將變量的實(shí)際值和缺失值都作為輸入維度參與后續(xù)數(shù)據(jù)處理和模型計(jì)算中。 -
不處理
對(duì)于一些模型對(duì)缺失值有容忍度或靈活處理方法,可不處理缺失值。如KNN、決策樹(shù)、隨機(jī)森林、神經(jīng)網(wǎng)絡(luò)、樸素貝葉斯、DBSCAN等。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101047 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7134瀏覽量
89393 -
eda
+關(guān)注
關(guān)注
71文章
2785瀏覽量
173619 -
信息采集
+關(guān)注
關(guān)注
0文章
81瀏覽量
21228 -
樸素貝葉斯
+關(guān)注
關(guān)注
0文章
12瀏覽量
3390
原文標(biāo)題:缺失值處理,你真的會(huì)了嗎?
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開(kāi)發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
嘗試仿真figure68的信號(hào)調(diào)理電路如圖所示,結(jié)果顯示增益達(dá)不到計(jì)算值,為什么?
eda中常用的數(shù)據(jù)處理方法
如何訓(xùn)練ai大模型
干貨篇:Air780E之RS485通信篇,你學(xué)會(huì)了嗎?

spwm載波頻率和幅值怎么確定
關(guān)于DAQExpress軟件中電壓的最大值最小值是根據(jù)什么來(lái)確定的?
劃重點(diǎn)!面試常考的ADC你真的會(huì)了嗎?

風(fēng)速繼電器的工作原理、風(fēng)速設(shè)定值的確定方法
車(chē)路云協(xié)同,這次它真的來(lái)了嗎?

降價(jià)潮背后:大模型落地門(mén)檻真的降了嗎?

你真的了解駐波比嗎?到底什么是電壓駐波比?
藍(lán)牙信標(biāo)室內(nèi)定位算法如何確定 A,n 值






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論