

訓練AI大模型是一個復雜且耗時的過程,涉及多個關鍵步驟和細致的考量。
一、數據準備
1. 數據收集
- 確定數據類型 :根據模型的應用場景,確定需要收集的數據類型,如文本、圖像、音頻等。
- 尋找數據源 :從可靠的來源獲取數據,如公開數據集、內部數據庫或第三方數據提供商。
2. 數據清洗
- 去除重復數據 :確保數據集中沒有重復項,以避免在訓練過程中引入冗余信息。
- 處理缺失值 :對于缺失的數據,可以采取填充、刪除或插值等方法進行處理。
- 標準化數據格式 :確保所有數據都符合統一的格式和標準,以便后續處理。
3. 數據預處理
- 數據劃分 :將數據集劃分為訓練集、驗證集和測試集。訓練集用于訓練模型,驗證集用于調整模型參數和防止過擬合,測試集用于評估模型性能。
- 特征工程 :根據業務需求,提取和選擇對模型訓練有重要影響的特征。
- 數據增強 :對于圖像或音頻等數據,可以通過數據增強技術來增加數據的多樣性和豐富性。
二、模型設計
1. 確定問題類型
- 分類問題 :如果目標變量是離散的,則可能是分類問題,如文本分類、圖像分類等。
- 回歸問題 :如果目標變量是連續的,則可能是回歸問題,如房價預測、股票價格預測等。
- 聚類問題 :如果需要將數據集中的樣本分為不同的組,則可能是聚類問題,如客戶細分、市場細分等。
2. 選擇模型類型
3. 設計模型結構
- 選擇合適的算法 :根據問題類型和數據集的特點,選擇適當的算法。
- 確定網絡結構 :對于神經網絡模型,需要確定網絡的層數、節點數、激活函數等。
- 設置超參數 :如學習率、批量大小、迭代次數等,這些參數對模型的訓練效果有重要影響。
三、模型訓練
1. 選擇訓練框架
- TensorFlow :一個開源的機器學習框架,支持分布式訓練,適用于大規模數據集和復雜模型。
- PyTorch :另一個流行的深度學習框架,具有靈活性和易用性,適用于研究和原型開發。
2. 配置計算資源
- GPU/TPU加速 :利用高性能計算設備(如NVIDIA GPU、Google TPU)來加速訓練過程。
- 分布式訓練 :將訓練任務劃分為多個子任務,并在多臺計算設備上并行處理,以加快訓練速度。
3. 調整模型參數
- 學習率調整 :根據模型的訓練情況,動態調整學習率,以加快收斂速度并提高訓練效率。
- 正則化方法 :使用L1、L2正則化等技術來防止模型過擬合。
4. 監控訓練過程
- 損失函數 :監控損失函數的變化情況,以判斷模型的訓練效果。
- 驗證集性能 :定期在驗證集上評估模型的性能,以便及時調整模型參數。
四、模型評估
1. 選擇評估指標
- 準確率 :分類問題中,正確分類的樣本數占總樣本數的比例。
- 召回率 :分類問題中,正確分類的正類樣本數占所有正類樣本數的比例。
- F1分數 :準確率和召回率的調和平均數,用于綜合評估模型的性能。
2. 進行測試集評估
- 在測試集上運行模型,并計算評估指標的值。
- 根據評估結果,判斷模型的性能是否滿足業務需求。
五、模型優化與部署
1. 模型優化
- 模型剪枝 :通過移除不重要的神經元和連接來減小模型的規模,以提高運行效率。
- 模型量化 :將模型的權重和激活值轉換為低精度表示,以減少模型的存儲空間和計算成本。
2. 模型部署
- 選擇合適的部署平臺 :根據業務需求和技術要求,選擇合適的部署平臺,如云服務、邊緣設備等。
- 進行集成和測試 :將模型集成到業務系統中,并進行全面的測試,以確保其穩定性和可靠性。
3. 監控和維護
- 監控模型性能 :定期監控模型的性能,以便及時發現并解決問題。
- 更新和優化 :根據業務需求和技術發展,不斷更新和優化模型。
綜上所述,訓練AI大模型需要經歷數據準備、模型設計、模型訓練、模型評估以及模型優化與部署等多個環節。每個環節都需要細致入微的考慮和操作,以確保最終訓練出的模型能夠滿足業務需求并具有高性能。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
神經網絡
+關注
關注
42文章
4797瀏覽量
102220 -
數據
+關注
關注
8文章
7232瀏覽量
90713 -
AI大模型
+關注
關注
0文章
358瀏覽量
462
發布評論請先 登錄
相關推薦
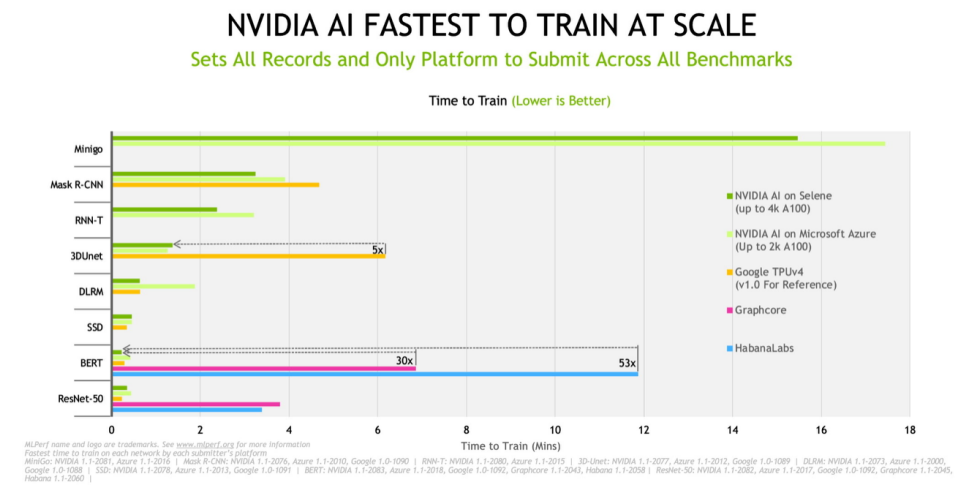
云服務、OEM 借助 NVIDIA AI讓AI訓練更上層樓
借助 NVIDIA AI,戴爾、浪潮、Microsoft Azure 和 Supermicro 在今天發布的新 MLPerf 基準測試中創下快速訓練 AI 模型的記錄。
發表于 12-03 10:19
?1648次閱讀
如何高效訓練AI模型?這些常用工具你必須知道!
大模型的發展同樣面臨瓶頸,訓練所需的硬件資源日益增加,比如英偉達的芯片、電力等(這也可能是ChatGPT5遲遲沒有出來的原因)。業界有觀點認為,在大多數情況下,并不需要全能的大模型,而是更適合專注于
“聯邦學習”或將推動AI在醫療行業加速落地?
只有獲取更多的數據進行訓練,AI模型才能更強健,而數據現狀顯然有礙于深度學習理論下AI模型的進展。“聯邦學習”能否打破壁壘,實現
NVIDIA為需要加速計算的企業客戶運行測試服務器
借助 NVIDIA AI,戴爾、浪潮、Microsoft Azure 和 Supermicro 在今天發布的新 MLPerf 基準測試中創下快速訓練 AI 模型的記錄
如何使用NVIDIA TAO快速準確地訓練AI模型
利用 NVIDIA TLT 快速準確地訓練人工智能模型的探索表明,人工智能在工業過程中具有巨大的潛力。

NVIDIA聯合構建大規模模擬和訓練 AI 模型
Champollion 超級計算機位于格勒諾布爾,由慧與和 NVIDIA 聯合構建,它將為全球科學和工業領域的用戶創建大規模模擬和訓練 AI 模型。
構建、訓練AI模型不必令人困惑且耗時
毫不夸張地說,人工智能(AI)幾乎可以用于工業領域的任何應用。隨著技術被推向物聯網的邊緣,使用數量大幅攀升。開發人員正在迅速部署其AI架構,這要歸功于Vecow等供應商的進步。
構建、訓練AI模型不必令人困惑且耗時
毫不夸張地說,人工智能(AI)幾乎可以用于工業領域的任何應用。隨著技術被推向物聯網的邊緣,使用數量大幅攀升。開發人員正在迅速部署他們的人工智能架構,這要歸功于Vecow等供應商的進步。
EyeEm平臺默認使用用戶照片訓練AI模型,用戶可自行刪除作品
據報道,攝影分享平臺EyeEm近期更新服務協議,宣稱將默認使用用戶上傳的圖片進行AI模型訓練,若用戶對此提出異議,則需自行刪除所有作品。
如何訓練自己的AI大模型
訓練自己的AI大模型是一個復雜且耗時的過程,涉及多個關鍵步驟。以下是一個詳細的訓練流程: 一、明確需求和目標 首先,需要明確自己的需求和目標。不同的任務和應用領域需要不同類型的
微軟否認使用用戶數據訓練AI模型
近日,微軟公司正式否認了一項關于其使用Microsoft 365應用程序中客戶數據來訓練人工智能模型的指控。這一聲明旨在澄清近期在社交媒體上流傳的某些用戶的疑慮和誤解。 此前,部分用戶在社交媒體平臺
訓練AI大模型需要什么樣的gpu
訓練AI大模型需要選擇具有強大計算能力、足夠顯存、高效帶寬、良好散熱和能效比以及良好兼容性和擴展性的GPU。在選擇時,需要根據具體需求進行權衡和選擇。
GPU是如何訓練AI大模型的
在AI模型的訓練過程中,大量的計算工作集中在矩陣乘法、向量加法和激活函數等運算上。這些運算正是GPU所擅長的。接下來,AI部落小編帶您了解GPU是如何





 工商網監
工商網監

評論