 存儲與GPU性能皆已成倍增長,IO表現為何遲遲不見好轉?
存儲與GPU性能皆已成倍增長,IO表現為何遲遲不見好轉?
存儲與GPU性能皆已成倍增長,IO表現為何遲遲不見好轉?
伴隨著HPC、自動駕駛、深度學習和VR/AR需求的不斷增加,IO性能也在逐步凸顯瓶頸,尤其是GPU與存儲之間的讀寫。處理器速度已經從KHz進化至了GHz,VRAM從KB進化至了GB,IO速度也從KB/s進化至了GB/s,然而GB/s的大幅度改善從直觀角度來看依然像是MB/s。
比如在有線連接的VR應用中,圖形需要經過電腦進行處理,再經有線傳輸顯示在VR屏幕上,這就引發了高延遲和長讀取時間等問題。這不禁讓人開始遐想,在CPU、GPU和存儲都已經革新換代的情況下,我們是否真正有效地應用了硬件性能?為此微軟和英偉達都提出了直接存儲的概念來改善IO的現狀。
微軟:Windows上的DirectStorage
微軟在不久前的Windows 11發布會上重點提到了DirectStorage技術,這是一個最初為主機設計的DirectX API,如今微軟也將把這一技術帶到PC上。
在當前NVMe SSD和PCIe技術的演進下,存儲帶寬遠超舊式的硬盤存儲技術,過去10MB每秒的速度已經達到數GB每秒。但PC上的圖形工作量也在逐步進化,數據量的增加對于讀取提出了更高的要求。過去大量數據的讀取只需要少量的IO請求,但如今的圖形渲染會將材質等資源分成小塊,只有在場景提出要求時載入所需的部分,如此一來雖然提高了效率,卻引入了更多IO請求。

當前的GPU資源讀取流程 / 微軟
而目前的存儲API并沒有對大量IO請求作出優化,因此拖累了NVMe,使得讀寫瓶頸愈發明顯。即便采用高端的PC硬件,也無法飽和利用存儲帶寬優勢。除此之外,這些數據往往需要經過壓縮傳輸下一個環節,傳入內存后,還要CPU進行一部分解壓工作,最后再傳入GPU顯存里,這樣一來每個節點都存在效率損失。
而DirectStorage采用了全新的路徑,從存儲讀取的數據傳給內存后,直接傳給GPU顯存。而GPU對于這些數據的解壓速度遠快于CPU,所以極大地優化了IO性能。
英偉達:RTX IO和Magnum IO GPUDirect Storage
英偉達在RTX 30系列顯卡上引入了RTX IO,面向消費市場,提升游戲場景下的讀取速度。英偉達稱RTX IO將與微軟的DirectStorage結合,與傳統硬盤下的存儲API相比,可將IO性能提高百倍。過去需要數十個CPU內核的工作全部交由RTX GPU來處理。
值得一提的是,英偉達的RTX IO雖然也用到了微軟的DirectStorage,但該技術并沒有將數據傳輸到內存,而是直接由SSD轉向GPU。微軟一名圖形開發者在GSL 2021大會上表示,未來DirectStorage的目標也是繞過系統內存。
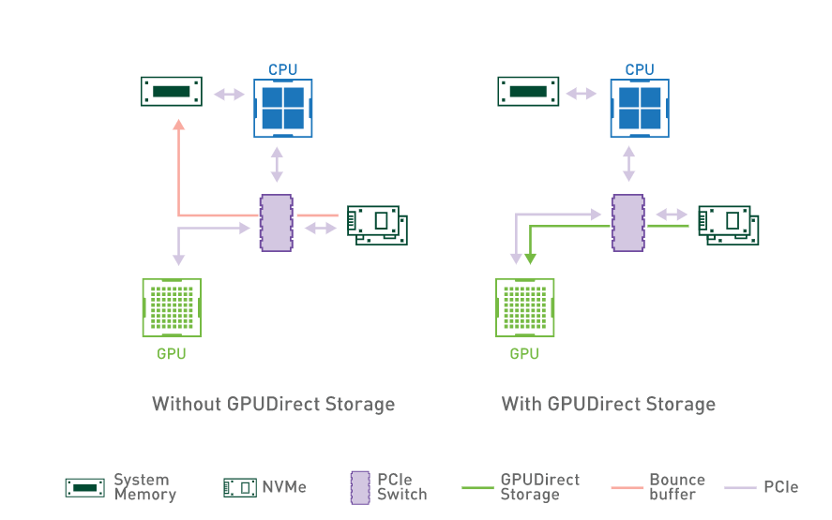
GDS技術 / 英偉達
除了消費市場外,英偉達在HPC市場也推出了對應的直接存儲技術,Magnum IO GPUDirect Storage(GDS)。GDS技術同樣是一個繞過CPU的技術,與消費級GPU不同,HPC場景下往往要用到多塊GPU,如此一來受IO延遲和CPU的影響更大。GDS在本地存儲與GPU顯存之間建立直接的數據通道,消除了CPU引入的延遲和讀寫瓶頸。
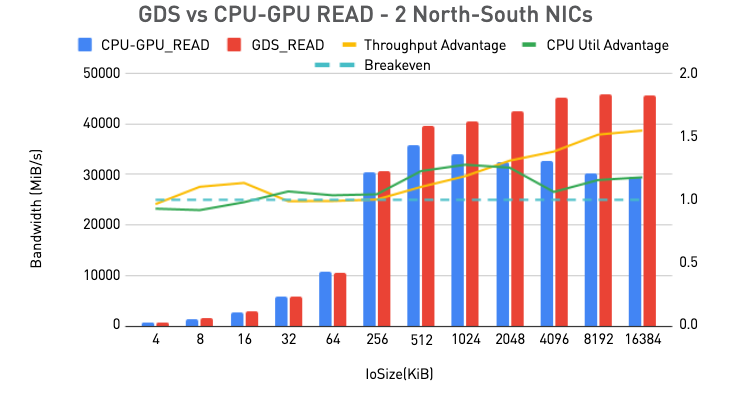
GDS與CPU傳輸至GPU讀取性能對比 / 英偉達
在運用GDS后,帶寬提升達到1.5倍,與傳統CPU回彈緩沖的數據路徑相比,CPU利用率也有2.8倍的提升。
目前英偉達已經將這一技術加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已經開始了相關產品的量產,而IBM、美光等五家廠商也在積極引入這一技術。三星、鎧俠、西數和戴爾等廠商也開始了GDS的早期集成與認證計劃。
小結
直接存儲技術進一步放大了GPU廠商與存儲廠商的優勢,目前HPC市場前景巨大,英偉達在相關業務上的盈利已經讓其看到了商機。不僅是GPU,英偉達采用Arm架構的Grace CPU同樣引入了NVLink這樣的數據傳輸改善方案。在這樣的性能改善下,即便存儲方案不同,英偉達的GPU也很可能成為HPC應用的首選。
伴隨著HPC、自動駕駛、深度學習和VR/AR需求的不斷增加,IO性能也在逐步凸顯瓶頸,尤其是GPU與存儲之間的讀寫。處理器速度已經從KHz進化至了GHz,VRAM從KB進化至了GB,IO速度也從KB/s進化至了GB/s,然而GB/s的大幅度改善從直觀角度來看依然像是MB/s。
比如在有線連接的VR應用中,圖形需要經過電腦進行處理,再經有線傳輸顯示在VR屏幕上,這就引發了高延遲和長讀取時間等問題。這不禁讓人開始遐想,在CPU、GPU和存儲都已經革新換代的情況下,我們是否真正有效地應用了硬件性能?為此微軟和英偉達都提出了直接存儲的概念來改善IO的現狀。
微軟:Windows上的DirectStorage
微軟在不久前的Windows 11發布會上重點提到了DirectStorage技術,這是一個最初為主機設計的DirectX API,如今微軟也將把這一技術帶到PC上。
在當前NVMe SSD和PCIe技術的演進下,存儲帶寬遠超舊式的硬盤存儲技術,過去10MB每秒的速度已經達到數GB每秒。但PC上的圖形工作量也在逐步進化,數據量的增加對于讀取提出了更高的要求。過去大量數據的讀取只需要少量的IO請求,但如今的圖形渲染會將材質等資源分成小塊,只有在場景提出要求時載入所需的部分,如此一來雖然提高了效率,卻引入了更多IO請求。
當前的GPU資源讀取流程 / 微軟
而目前的存儲API并沒有對大量IO請求作出優化,因此拖累了NVMe,使得讀寫瓶頸愈發明顯。即便采用高端的PC硬件,也無法飽和利用存儲帶寬優勢。除此之外,這些數據往往需要經過壓縮傳輸下一個環節,傳入內存后,還要CPU進行一部分解壓工作,最后再傳入GPU顯存里,這樣一來每個節點都存在效率損失。
而DirectStorage采用了全新的路徑,從存儲讀取的數據傳給內存后,直接傳給GPU顯存。而GPU對于這些數據的解壓速度遠快于CPU,所以極大地優化了IO性能。
英偉達:RTX IO和Magnum IO GPUDirect Storage
英偉達在RTX 30系列顯卡上引入了RTX IO,面向消費市場,提升游戲場景下的讀取速度。英偉達稱RTX IO將與微軟的DirectStorage結合,與傳統硬盤下的存儲API相比,可將IO性能提高百倍。過去需要數十個CPU內核的工作全部交由RTX GPU來處理。
值得一提的是,英偉達的RTX IO雖然也用到了微軟的DirectStorage,但該技術并沒有將數據傳輸到內存,而是直接由SSD轉向GPU。微軟一名圖形開發者在GSL 2021大會上表示,未來DirectStorage的目標也是繞過系統內存。
GDS技術 / 英偉達
除了消費市場外,英偉達在HPC市場也推出了對應的直接存儲技術,Magnum IO GPUDirect Storage(GDS)。GDS技術同樣是一個繞過CPU的技術,與消費級GPU不同,HPC場景下往往要用到多塊GPU,如此一來受IO延遲和CPU的影響更大。GDS在本地存儲與GPU顯存之間建立直接的數據通道,消除了CPU引入的延遲和讀寫瓶頸。
GDS與CPU傳輸至GPU讀取性能對比 / 英偉達
在運用GDS后,帶寬提升達到1.5倍,與傳統CPU回彈緩沖的數據路徑相比,CPU利用率也有2.8倍的提升。
目前英偉達已經將這一技術加入到其HGX AI超算中,DDN、VAST和WEKA三家公司已經開始了相關產品的量產,而IBM、美光等五家廠商也在積極引入這一技術。三星、鎧俠、西數和戴爾等廠商也開始了GDS的早期集成與認證計劃。
小結
直接存儲技術進一步放大了GPU廠商與存儲廠商的優勢,目前HPC市場前景巨大,英偉達在相關業務上的盈利已經讓其看到了商機。不僅是GPU,英偉達采用Arm架構的Grace CPU同樣引入了NVLink這樣的數據傳輸改善方案。在這樣的性能改善下,即便存儲方案不同,英偉達的GPU也很可能成為HPC應用的首選。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
微軟
+關注
關注
4文章
6623瀏覽量
104299 -
gpu
+關注
關注
28文章
4766瀏覽量
129189 -
HPC
+關注
關注
0文章
321瀏覽量
23823 -
英偉達
+關注
關注
22文章
3833瀏覽量
91644
發布評論請先 登錄
相關推薦
λ-IO:存儲計算下的IO棧設計
動機和背景? ? 存儲計算存儲資源的充分利用。IO棧是管理存儲器的的基本組件,包括設備驅動、塊接口層、文件系統,目前一些用戶空間IO庫(如S

GPU在虛擬現實中的表現 低功耗GPU的優缺點
GPU在虛擬現實中的表現 虛擬現實(VR)技術的發展離不開高性能的圖形處理單元(GPU)。GPU在VR中扮演著至關重要的角色,它負責渲染復雜
NPU與GPU的性能對比
NPU(Neural Processing Unit,神經網絡處理單元)與GPU(Graphics Processing Unit,圖形處理單元)在性能上各有千秋,它們各自的設計初衷和優化方向決定了
DM6446+TLV320AIC33錄音功能不好,表現為能聽到錄制的聲音,但聲音小,是哪里出了問題?
我現在平臺是DM6446+TLV320AIC33,用來實現錄音和播放功能,輸入為麥克風,輸出為耳機。現在播放功能是正常額,在耳機里能清楚地聽到播放的wav文件,問題是錄音功能不好,表現為能聽到錄制的聲音,但聲音小。請教大家有可能是哪里出了問題?
發表于 11-08 07:38
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
本篇閱讀學習第七、八章,了解GPU架構演進及CPGPU存儲體系與線程管理
█從圖形到計算的GPU架構演進
GPU圖像計算發展
●從三角形開始的幾何階段
在現代圖形渲染中,三角形是最常用
發表于 11-03 12:55
如何提高GPU性能
在當今這個視覺至上的時代,GPU(圖形處理單元)的性能對于游戲玩家、圖形設計師、視頻編輯者以及任何需要進行高強度圖形處理的用戶來說至關重要。GPU不僅是游戲和多媒體應用的心臟,它還在科學計算、深度
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
經典 GPU 算力芯片解讀
10.1 NVIDIAGPU芯片
10.2 AMDGPU芯片
10.3 IntelXeGPU架構
10.3.4 超大芯片Ponte Vecchio
第11章 存儲與互連總線
發表于 10-15 22:08
TLV320AIC3100IRHBR的MIC接口功能異常,主要表現為MIC管腳對GND的阻抗非常低,為什么?
TLV320AIC3100IRHBR的MIC接口功能異常,主要表現為MIC管腳對GND的阻抗非常低,一般這個是由什么原因造成的?
發表于 10-15 07:12
韓企存儲芯片在華熱銷,營收翻倍增長
2024年上半年,韓國存儲芯片巨頭三星電子與SK海力士在中國市場的表現極為亮眼,營收均實現了超過100%的顯著增長。這一驕人成績主要得益于全球存儲芯片市場需求的強勁復蘇以及產品價格的持
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
設計。在GPU和NPU等加速器部分,介紹了GPU為何能從單純的圖形任務處理器變成通用處理器。GPU在設計邏輯、存儲體系、線程管理,以及面向A
發表于 09-02 10:09
為什么倍壓整流電路輸出電流不隨倍壓倍數增加而成倍增加?
倍壓整流電路是一種特殊的電源電路,它能夠將輸入的低電壓交流信號轉換為高電壓直流信號,但其輸出電流并不隨倍壓倍數的增加而成倍增加。
全方位性能對比 | 遠距離Wi-Fi VS 傳統Wi-Fi
應用。然而在物聯網設備成倍增長的今天,更多的應用場景對通信的連接距離、功耗、穿透性、接入量方面有了更高的要求,需要一種更符合場景需要的可靠通信方式來保持聯通。自連遠距

英飛凌推出高密度功率模塊,為AI數據中心提供基準性能,降低總體擁有成本
? 【 2024 年 3 月 1 日, 德國慕尼黑和加利福尼亞州長灘 訊】 人工智能(AI)正推動全球數據生成量成倍增長,促使支持這一數據增長的芯片對能源的需求日益增加。英飛凌科技股份公司近日推出
發表于 03-05 13:52
?953次閱讀

鴻蒙這么大聲勢,為何遲遲看不見崗位?最新數據來了
對鴻蒙下一階段的發展更具信心。
鴻蒙人才供需
報告中的數據顯示,春節后第一周,鴻蒙相關職位數同比增長163%,投遞人數同比增長349%,即分別增至去年同期的2.6倍、4.5倍,漲勢突出。
這背后是自去年
發表于 02-29 20:53





 工商網監
工商網監
評論