 英偉達最新推出的自動駕駛芯片Atlan詳解
英偉達最新推出的自動駕駛芯片Atlan詳解
英偉達在2019年12月推出Orin后沉寂一年半推出新一代自動駕駛SoC,即Atlan,從命名來看,Nvidia 還在使用《海王》(Aquaman)系列中的名字。在2019年開始,Nvidia宣布的Orin SoC,就是以亞特蘭蒂斯的第一統治者命名的。而最近 Nvidia 宣布了以 Orin 之父命名的 Atlan SoC。相對Orin,Atlan可謂顛覆性的,與Orin遠非一個系列的產品,與其說它是一個車載芯片,不如說它是一個大型數據中心服務器芯片,不太考慮成本,不太考慮功耗。
英偉達從未公開Orin芯片的內部布局圖,但Atlan一開始就公布了,或許是對Atlan信心更足。
英偉達在2019年11月發布的Orin芯片官方圖片。不過在網上可以找到Orin的大致布局圖。
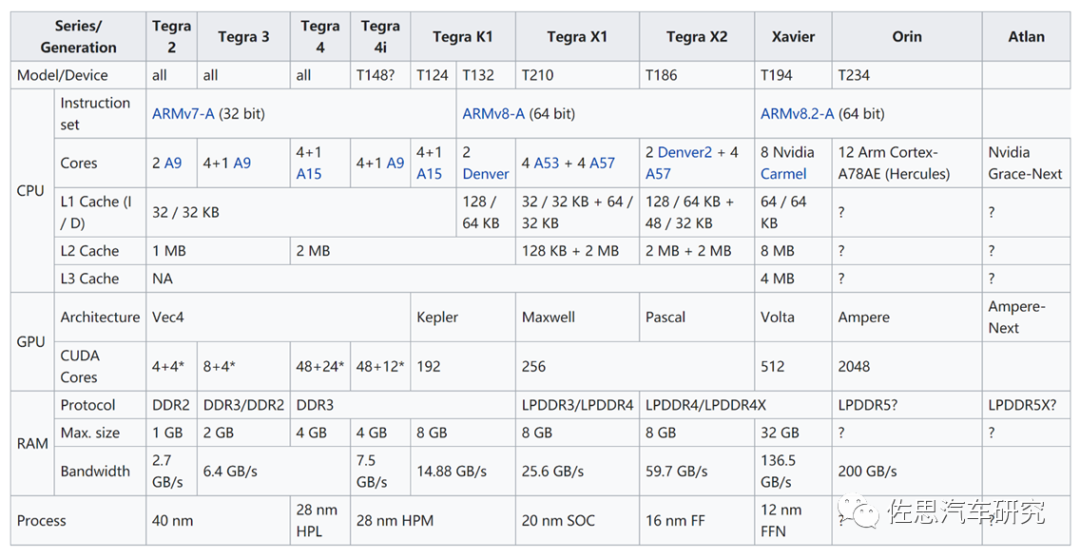
Atlan不再沿用使用了近10年ARMv8的指令集,改為ARM Neoverse V1指令集。開發人員可能需要花大量精力來熟悉這種從未出現過的指令集。最大的改動是CPU使用了ARM針對服務器領域的Zeus架構,增加了Bluefield即DPU部分,增加了針對功能安全的安全島設計。 先來看CPU部分。
ARM在2019年3月針對服務器市場推出Neoverse平臺,按照計劃最初是Ares,即希臘神話里的戰神;2020年是Zeus,即希臘神話里二代天神中的最高神的宙斯;2021年是Poseidon,即希臘神話里的海神波塞冬。或許不會有Hades,冥王哈迪斯。至少這個系列代號可以用11代。
Neoverse平臺再分3個系列,分別是V、N、E三個系列,分別對應高性能、高效率、低功耗三大應用場景。V系列中第一個產品,順便說一下,N2平臺代號是Perseus,即希臘神話里的宙斯之子,砍下美杜莎腦袋的希臘英雄珀爾修斯。英偉達破天荒推出的CPU即是以宙斯為平臺的CPU。
V1可以看作ARM剛剛發布的ARM v9指令集的SVE強化版,ARM v9指令集中最大變化就是增加了SVE,SVE(Scalable Vector Extension)是ARM AArch64架構下的下一代SIMD指令集,旨在加速高性能計算。 ARM v7的高級SIMD (即ARMNEON 或“MPE” 多媒體處理引擎) 指令集自2005年發布,已經面世十幾年了。ARM v7 NEON的主要特性如下:
支持8/16/32位整數操作,支持非IEEE兼容單精度浮點操作,支持指令條件執行
32個64位矢量寄存器,也可視為16個128位矢量寄存器
旨在CPU端加速多媒體處理任務
在升級到ARMv8架構時,AArch64 NEON指令集做出了許多改進,比如:
支持IEEE兼容單精度和雙精度浮點操作和64位整數矢量操作
2個128位矢量寄存器
這些改進使NEON指令集更適用于通用計算,而不僅僅是多媒體計算
但是到了現在,ARMv8的新市場需要更徹底的SIMD指令改進。需要能夠并行處理非常規數據和復雜數據結構,也需要更長的矢量,SVE因此而生,SVE旨在加速高性能計算。
128位的整數倍。 最高可支持2048位
不同的實現可以適應不同的應用場景,不用更改指令集
每通道預測
支持復雜嵌套循環和if/then/else條件跳轉, 沒有循環尾數。
聚集加載和分散存儲支持復雜數據結構,如步長數據存取、數組索引,鏈表等。
橫向操作
支持基本的reduction操作,降低循環依賴性
SVE2于2019年4月和V1一起發布,SVE和SVE2的優勢還在于其可變的向量大小,范圍從128b到2048b,從而允許向量的可變粒度為128b,無論實際運行的硬件是什么。純粹從向量處理和編程的角度來看,這意味著軟件開發人員將只需要編譯一次其代碼,并且如果將來某個CPU帶有本機512b SIMD執行管道,該代碼將能夠已經充分利用了單元的整個寬度。
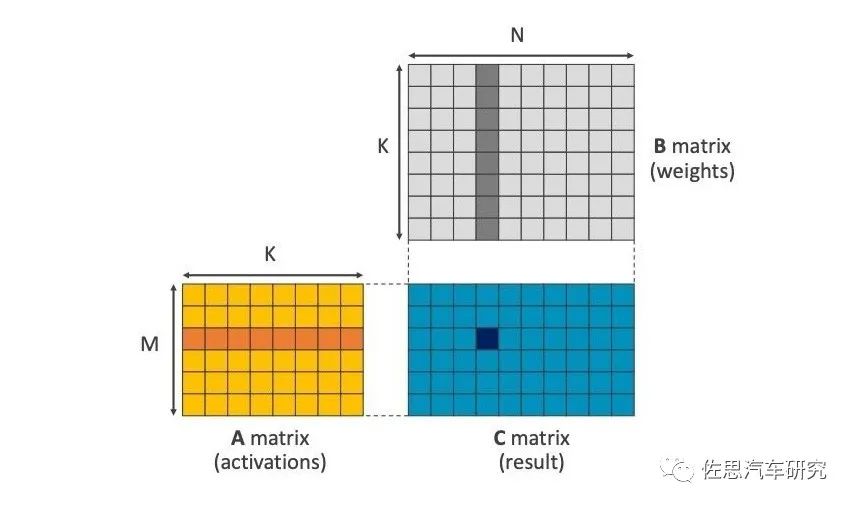
SVE2是針對機器學習設計的,通用矩陣乘法GEMM指令是其最突出特色。我們都知道AI加速器就是乘和累加MAC的堆砌,其特色就是一次可以執行乘和加兩個指令。實際是一種矩陣乘法累加器,在ARM v8.6中也加入了GEMM指令,乘法累加器中,乘法要遍歷每一個矩陣中的數值(通常是像素),這是最費時間的地方,加法器則要快的多,ARM的CPU不能像AI那樣堆砌MAC,但是可以加速矩陣乘法,讓后端的多核處理器部分工作量大大減輕。這近似于一個超高速DSP,頻率不高,但帶寬很高。
V1的突出特色還有CCIX和CXL,也就是大名鼎鼎的小芯片chiplet,chiplet的概念其實很簡單,就是die級別的重用。設計一個系統級芯片,以前的方法是從不同的IP供應商購買一些IP,軟核(代碼)或硬核(版圖),結合自研的模塊,集成為一個SoC,然后在某個芯片工藝節點上完成芯片設計和生產的完整流程。 未來,對于某些IP,你可能不需要自己做設計和生產了,而只需要買別人實現好的die片,然后在一個封裝里集成起來,很像SiP( System in Package),但兩者有很大不同,chiplet是晶圓級的,晶圓制造的中段mid-end封裝,只有晶圓廠Foundry才能做,封裝之間是超高速的bump連線,SiP是芯片級的封裝,是專業封裝廠的業務范疇,是錫球級別的。 小芯片的另一個名字叫MCM,Multi-Chip-Module。 2017年英偉達、德州大學、亞利桑那州立大學、巴塞羅那超算中心、加泰羅尼亞理工大學聯合出品一篇研究論文:MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability,對此有詳細的研究,在2017年加拿大多倫多ISCA上發表。
簡單地說就是用4個小芯片合成一個大芯片,英偉達稱為MCM技術。
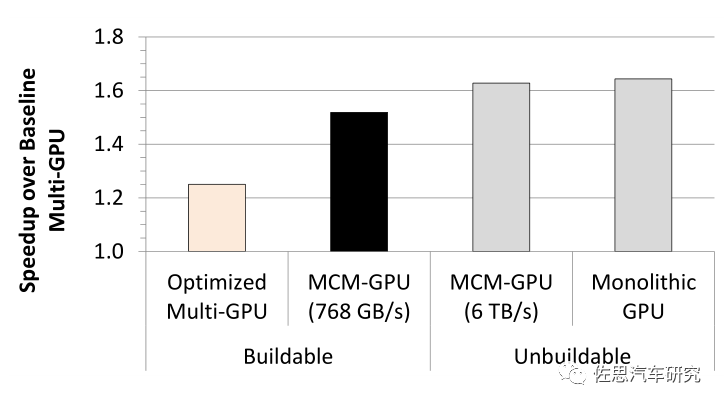
上圖為英偉達采用MCM-GPU和多GPU性能對比。英偉達在2019年VLSI大會上提出RC-18概念,采用36個小芯片。
不僅GPU或者說AI芯片可以這樣做,CPU也可以,這就是AMD在服務器領域崛起的關鍵,最典型的是AMD的32核(應該是32小芯片)EPYC,這種方式最大優點是成本低,如果將32核封裝到一塊芯片中成本是1,那它們的MCM方式只有0.59,換言之,節省了41%的成本。
把小芯片合成一個大芯片,貌似就是一個“膠水”大法,但實際門檻是很高的,能支持的只有臺積電CoWos和英特爾的EMIB工藝,英偉達一向不喜歡臺積電,更喜歡三星。和高通一樣,英偉達知道不能過分依賴臺積電,否則容易出現供應鏈問題,也就是后來英偉達基本放棄MCM路線。
回到Atlan,Atlan可能用了ARM V1提供的CXL小芯片,即內存擴展,減少內存于處理器間的物理距離是解決AI處理器內存瓶頸的最有效方式。CCIX比較復雜,可能下一代會用。
再來看Bluefield即DPU部分,2020年4月英偉達花70億美元收購了以色列芯片公司Mellanox Technologies, Ltd.(邁絡思科技有限公司),通過融合Mellanox的技術,新的NVIDIA將擁有從人工智能計算到網絡的端到端技術,以及從處理器到軟件的全堆棧產品,擁有足夠的規模去推進下一代的數據中心技術。
Mellanox的主要產品就是名為Bluefield的芯片,英偉達將其改名為DPU。其實際上是一個高級的網卡。DPU專門執行原本需要CPU處理的網絡、存儲和安全等任務。這就意味著如果在數據中心中采用了DPU,那么CPU的不少運算能力可以被釋放出來,按照英偉達的說法,一個DPU頂125個CPU的網絡處理能力。
英偉達計劃在2022年推出3代Bluefield。復雜一點的說法是DPU是一個可編程的電子部件,其處理數據流,數據可作為信息的復用包與組件傳輸。DPU具有中央處理單元(CPU)的通用性和可編程性,但專用于處理網絡數據包、存儲請求或分析請求上高效運行。DPU通過更大程度的并行性(可同時處理更多的數據),因而對比起CPU更勝一籌。
同時,DPU的MIMD架構相比圖形處理單元(GPU)的SIMD架構更為優秀,其每個請求都需要做出不同的決定并遵循不同的路徑通過芯片,從而使其區別于GPU 。也就是英偉達說的軟件定義網絡,Mellanox NVMe SNAP (軟件定義的網絡加速處理)技術可以為遠程存儲提供2.5M + IOPS讀/寫訪問,這是4KB塊大小時100Gb / s的線速性能。相比之下,入門級NVMe SSD可以提供帶有4 KB塊的300K IOPS。此外,BlueField-2 DPU毫不費力地以100 Gb / s的速度添加了IPSec加密和解密功能。
上圖為二代Bluefield,內含8個ARMA72,Atlan里的要處理數據帶寬遠小于傳統服務器,兩個A72足夠。Atlan里的DPU主要針對車載骨干以太網和外接的PCIe網絡,內置網絡控制器和PCIe交換,以太網可輕易支持到100G,PCIe則支持到第四代,也可以做數據采集車的網絡接口芯片,與超高速固態硬盤連接。不過物理層芯片還是繞不開Marvell、德州儀器和博通。
最后是功能安全隔離島,應該就是ARM發布的Cortex-R52。英偉達所說的功能安全島與ARM所說的安全島的宣傳詞都基本一致。R系列是ARM專門為實時性要求高的場合開發的內核,R52是R系列旗艦產品,之前英偉達芯片從未采用過R內核。
R52是ARM在2016年發布的專為自動駕駛安全市場供應的內核,Cortex-R52最高支持4核心鎖步技術,相比Cortex-R5,有35%的性能提升,上下文切換(亂序)提高14倍,入口搶占提高2倍,支持硬件虛擬化技術。 按照ARM的說法,簡單的中控系統可直接用Cortex-R52,但是像工業機器人和ADAS(先進輔助駕駛)系統則建議配合Cortex-A、MaliGPU等提升整體運算。另外,ARM Cortex-R52通過多項安全標準認證,包括有IEC 61508(工業)、ISO 26262(車用)、IEC60601(醫療)、EN 50129(車用)以及RTCA DO-254(工業)等。2021年3月還推出了R52+架構。可以最高支持8個核心鎖步。 R52包括三大功能,軟件隔離:通過硬件實現的軟件隔離,意味著軟件功能互不干擾。對于安全相關的任務,這也意味著需要認證的代碼更少,從而節省了時間、成本和工作量。
支持多個操作系統:借助虛擬化功能,開發人員能夠在單個CPU內,使用多個操作系統來整合應用。這樣可以簡化功能的添加,而無需增加電子控制單元的數量。
實時性能:Cortex-R52+的高性能多核集群可為確定性系統提供實時響應能力,且在所有Cortex-R產品中產生的延遲最低。
Atlan擁有多達1000TOPS的算力,是Orin的4倍,看其內部布局,仍然是12個安培GPU模塊,與Orin差不多,面積似乎也差不多,似乎還略微小了點,只不過Atlan的CPU die 面積遠比Orin的要大,Atlan能取得1000TOPS的成績,主要功勞應該是CPU、DPU和存儲的功勞,單Ampere架構的改進不大可能取得如此高的提升。 Atlan是針對服務器超大規模模型而設計的,而自動駕駛車載模型的趨勢是越來越小,精度越來越低,已經有人喊出1比特精度。Atlan反其道行之,特別支持服務器領域常見而自動駕駛領域少見的BFloat16精度。 顯然英特爾對車載領域的興趣度在逐漸下降,無論是CPU還是DPU,都是借服務器領域的,而非專為車載領域開發。
而在ARM服務器這個領域,依靠與ARM的深度合作與深厚的技術積累,英偉達能像英特爾筆記本電腦那樣每兩年就產品換代一次,不過一款車的生命周期至少是7-8年,車廠可不會認同這樣的更新頻率。但英偉達不在意,英偉達核心業務還是顯卡和數據中心處理器,車載只是順手做的,發揮CPUGPUDPU的余熱。 而Orin的ARM A78內核是專為自動駕駛引進的新內核,在英偉達其他產品見不到A78的身影,足見對A78的重視,而Atlan只能見到對數據中心的重視。英偉達的另一個用意是拉上對手做算力軍備競賽,在宣傳上大造聲勢,壓迫對手必須跟進算力游戲,直到拖垮對手。其他廠家恐怕不會跟進這種算力數字游戲,這脫離了實際需求。Orin恐怕將是英偉達未來數年的主力產品。
原文標題:詳解英偉達最新自動駕駛芯片-Atlan
文章出處:【微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
芯片
+關注
關注
456文章
51121瀏覽量
426011 -
英偉達
+關注
關注
22文章
3833瀏覽量
91644 -
自動駕駛
+關注
關注
784文章
13918瀏覽量
166779
原文標題:詳解英偉達最新自動駕駛芯片-Atlan
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
黃仁勛宣布:豐田與英偉達攜手打造下一代自動駕駛汽車
英偉達在華加大招聘,聚焦自動駕駛技術

Orin芯片的技術特點
科技看點:摩根大通詳解“英偉達芯片問題”馬斯克560億薪酬方案引爭議
FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
自動駕駛公司Wayve獲10.5億美元C輪融資,軟銀、英偉達加持
沃爾沃利用英偉達的SoC和AI來提升自動駕駛的安全性
英偉達參投英國自動駕駛初創公司10億美元融資
英偉達參投英國自動駕駛公司融資
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
比亞迪將搭載英偉達DRIVE Thor車機芯片,推進自動駕駛和智能工廠技術
高通自動駕駛靠軟件開發革新力壓英偉達自動駕駛芯片





 工商網監
工商網監
評論