 PB級分析型數據庫ClickHouse的應用場景和特性等分享
PB級分析型數據庫ClickHouse的應用場景和特性等分享
在百花齊放的交互式分析領域,ClickHouse 絕對是后起之秀,它雖然年輕,卻有非常大的發展空間。本文將分享 PB 級分析型數據庫 ClickHouse 的應用場景、整體架構、眾多核心特性等,幫助理解 ClickHouse 如何實現極致性能的存儲引擎,希望與大家一起交流。
一、交互式分析之 ClickHouse
1. 交互式分析簡介
交互式分析,也稱 OLAP(Online Analytical Processing),它賦予用戶對海量數據進行多維度、交互式的統計分析能力,以充分利用數據的價值進行量化運營、輔助決策等,幫助用戶提高生產效率。
交互式分析主要應用于統計報表、即席查詢(Ad Hoc)等領域,前者查詢模式較固定,后者即興進行探索分析。代表場景例如:移動互聯網中 PV、UV、活躍度等典型實時報表;互聯網內容領域中人群洞察、關聯分析等即席查詢。
交互式分析是數據分析的一種重要方式,與離線分析、流式分析、檢索分析一起,共同組成完整的數據分析解決方案,在互聯網、物聯網快速發展的背景下,從不同維度滿足用戶對海量數據的全方位分析需求。 相比專注于事務處理的傳統關系型數據庫,交互式分析解決了 PB 級數據分析帶來的性能、擴展性問題。 相比離線分析長達 T + 1 的時效性、流式分析較為固定的分析模式、檢索分析受限的分析性能,交互式分析的分鐘級時效性、靈活多維度的分析能力、超高性能的掃描分析性能,可以大幅度提高數據分析的效率,拓展數據分析的應用范圍。
從數據訪問特性角度來看,交互式分析場景具有如下典型特點:
大多數訪問是讀請求。
寫入通常為追加寫,較少更新、刪除操作。
讀寫不關注事務、強一致等特性。
查詢通常會訪問大量的行,但僅部分列是必須的。
查詢結果通常明顯小于訪問的原始數據,且具有可理解的統計意義。
2. 百花齊放下的 ClickHouse
近十年,交互式分析領域經歷了百花齊放式的發展,大量解決方案爆發式涌現,尚未有產品達到類似 Oracle / MySQL 在關系型數據庫領域中絕對領先的狀態。 業界提出的開源或閉源的交互式解決方案,主要從大數據、NoSQL 兩個不同的方向進行演進,以期望提供用戶最好的交互式分析體驗。下圖所示是不同維度下的代表性解決方案,供大家參考了解:
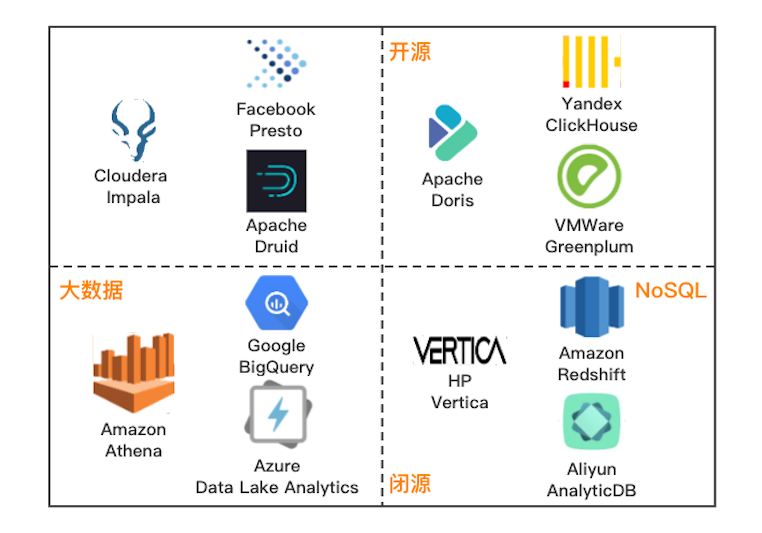
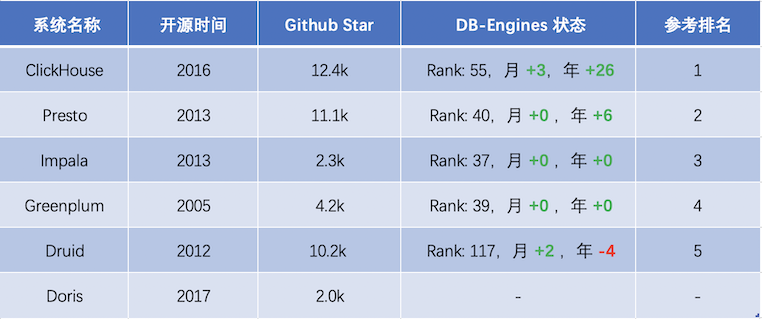
其中,ClickHouse 作為一款 PB 級的交互式分析數據庫,最初是由號稱 “ 俄羅斯 Google ” 的 Yandex 公司開發,主要作為世界第二大 Web 流量分析平臺 Yandex.Metrica(類 Google Analytic、友盟統計)的核心存儲,為 Web 站點、移動 App 實時在線的生成流量統計報表。 自 2016 年開源以來,ClickHouse 憑借其數倍于業界頂尖分析型數據庫的極致性能,成為交互式分析領域的后起之秀,發展速度非常快,Github 上獲得 12.4K Star,DB-Engines 排名近一年上升 26 位,并獲得思科、Splunk、騰訊、阿里等頂級企業的采用[1]。下面是 ClickHouse 及其他開源 OLAP 產品的發展趨勢統計:
性能是衡量 OLAP 數據庫的關鍵指標,我們可以通過 ClickHouse 官方測試結果[2] 感受下 ClickHouse 的極致性能,其中綠色代表性能最佳,紅色代表性能較差,紅色越深代表性能越弱。 從測試結果看,ClickHouse 幾乎在所有場景下性能都最佳,并且從所有查詢整體看,ClickHouse 領先圖靈獎得主 Michael Stonebraker 所創建的 Vertica 達 6 倍,領先 Greenplum 達到 18 倍。
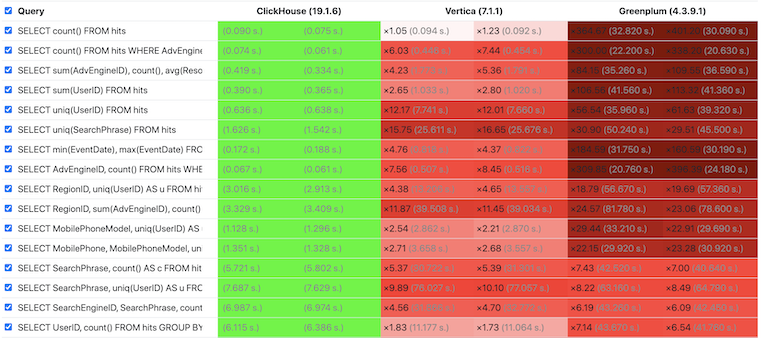
更多測試結果可參考 OLAP 系統第三方評測[3] ,盡管該測試使用了無索引的表引擎(或稱表類型),ClickHouse 仍然在單表模式下體現了強勁的領先優勢。
二、ClickHouse 架構
1. 集群架構
ClickHouse 采用典型的分組式的分布式架構,具體集群架構如下圖所示:
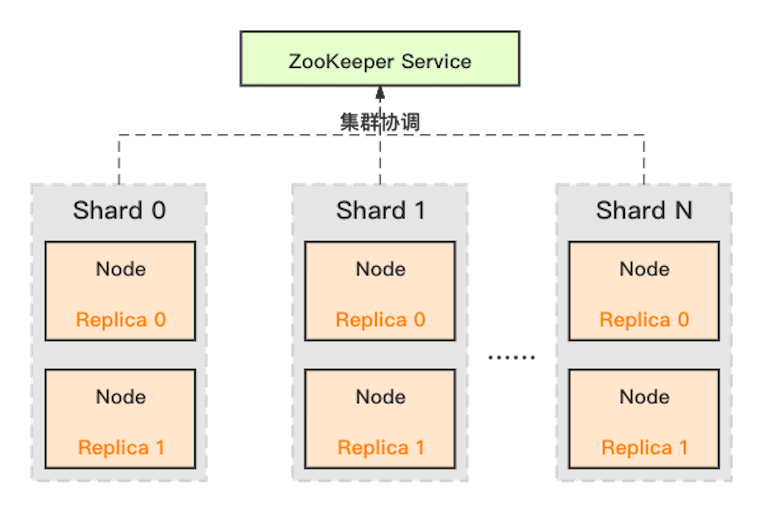
Shard :集群內劃分為多個分片或分組(Shard 0 … Shard N),通過 Shard 的線性擴展能力,支持海量數據的分布式存儲計算。
Node :每個 Shard 內包含一定數量的節點(Node,即進程),同一 Shard 內的節點互為副本,保障數據可靠。ClickHouse 中副本數可按需建設,且邏輯上不同 Shard 內的副本數可不同。
ZooKeeper Service :集群所有節點對等,節點間通過 ZooKeeper 服務進行分布式協調。
2. 數據模型
ClickHouse 采用經典的表格存儲模型,屬于結構化數據存儲系統。我們分別從面向用戶的邏輯數據模型和面向底層存儲的物理數據模型進行介紹。
(1)邏輯數據模型
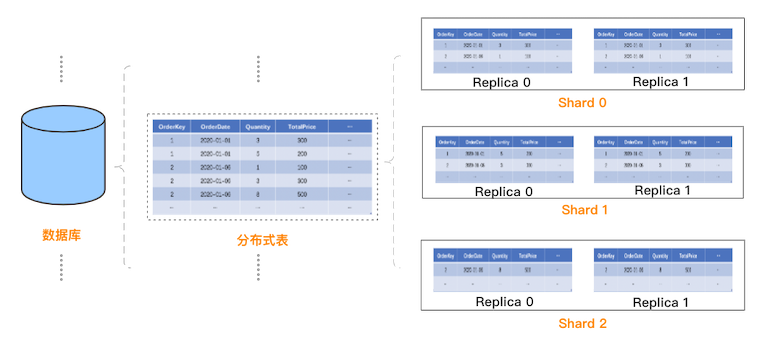
從用戶使用角度看,ClickHouse 的邏輯數據模型與關系型數據庫有一定的相似:一個集群包含多個數據庫,一個數據庫包含多張表,表用于實際存儲數據。 與傳統關系型數據庫不同的是,ClickHouse 是分布式系統,如何創建分布式表呢?ClickHouse 的設計是:先在每個 Shard 每個節點上創建本地表(即 Shard 的副本),本地表只在對應節點內可見;然后再創建分布式表,映射到前面創建的本地表。這樣用戶在訪問分布式表時,ClickHouse 會自動根據集群架構信息,把請求轉發給對應的本地表。創建分布式表的具體樣例如下:
# 首先,創建本地表CREATE TABLE table_local ON CLUSTER cluster_test( OrderKey UInt32, # 列定義 OrderDate Date, Quantity UInt8, TotalPrice UInt32, ……)ENGINE = MergeTree() # 表引擎PARTITION BY toYYYYMM(OrderDate) # 分區方式ORDER BY (OrderDate, OrderKey); # 排序方式SETTINGS index_granularity = 8192; # 數據塊大小 # 然后,創建分布式表CREATE TABLE table_distribute ON CLUSTER cluster_test AS table_localENGINE = Distributed(cluster_test, default, table_local, rand()) # 關系映射引擎 其中部分關鍵概念介紹如下,分區、數據塊、排序等概念會在物理存儲模型部分展開介紹:
MergeTree :ClickHouse 中使用非常多的表引擎,底層采用 LSM Tree 架構,寫入生成的小文件會持續 Merge。
Distributed :ClickHouse 中的關系映射引擎,它把分布式表映射到指定集群、數據庫下對應的本地表上。
更直觀的,ClickHouse 中的邏輯數據模型如下:
(2)物理存儲模型
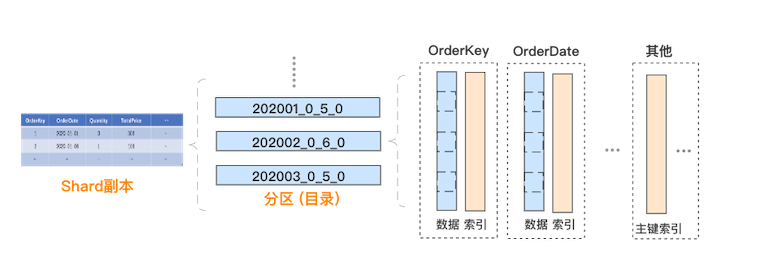
接下來,我們來介紹每個分片副本內部的物理存儲模型,具體如下:
數據分區:每個分片副本的內部,數據按照 PARTITION BY 列進行分區,分區以目錄的方式管理,本文樣例中表按照時間進行分區。
列式存儲:每個數據分區內部,采用列式存儲,每個列涉及兩個文件,分別是存儲數據的 .bin 文件和存儲偏移等索引信息的 .mrk2 文件。
數據排序:每個數據分區內部,所有列的數據是按照 ORDER BY 列進行排序的。可以理解為:對于生成這個分區的原始記錄行,先按 ORDER BY 列進行排序,然后再按列拆分存儲。
數據分塊:每個列的數據文件中,實際是分塊存儲的,方便數據壓縮及查詢裁剪,每個塊中的記錄數不超過 index_granularity,默認 8192。
主鍵索引:主鍵默認與 ORDER BY 列一致,或為 ORDER BY 列的前綴。由于整個分區內部是有序的,且切割為數據塊存儲,ClickHouse 抽取每個數據塊第一行的主鍵,生成一份稀疏的排序索引,可在查詢時結合過濾條件快速裁剪數據塊。
三、ClickHouse核心特性
ClickHouse 為什么會有如此高的性能,獲得如此快速的發展速度?下面我們來從 ClickHouse 的核心特性角度來進一步介紹。
1. 列存儲
ClickHouse 采用列存儲,這對于分析型請求非常高效。一個典型且真實的情況是:如果我們需要分析的數據有 50 列,而每次分析僅讀取其中的 5 列,那么通過列存儲,我們僅需讀取必要的列數據,相比于普通行存,可減少 10 倍左右的讀取、解壓、處理等開銷,對性能會有質的影響。
這是分析場景下,列存儲數據庫相比行存儲數據庫的重要優勢。這里引用 ClickHouse 官方一個生動形象的動畫,方便大家理解:
行存儲:從存儲系統讀取所有滿足條件的行數據,然后在內存中過濾出需要的字段,速度較慢:
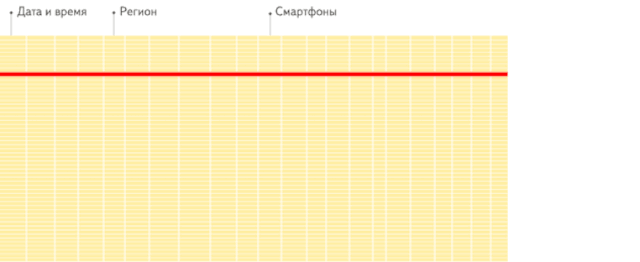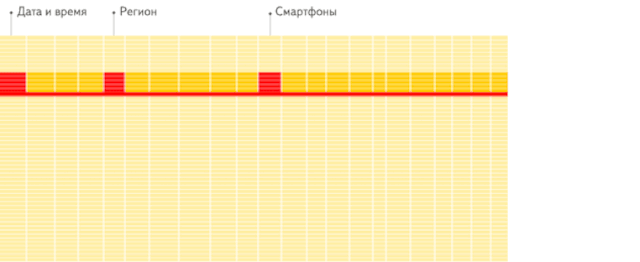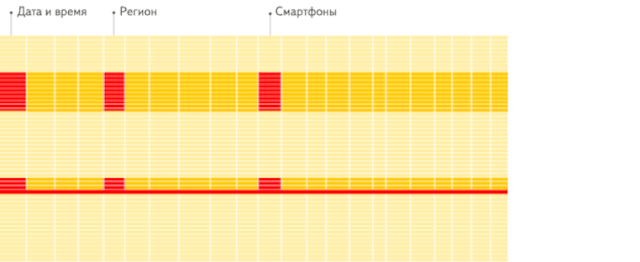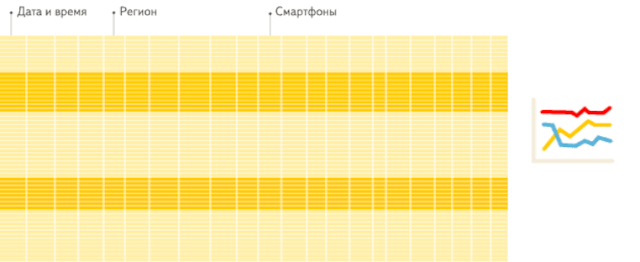
列存儲:僅從存儲系統中讀取必要的列數據,無用列不讀取,速度非常快:
2. 向量化執行
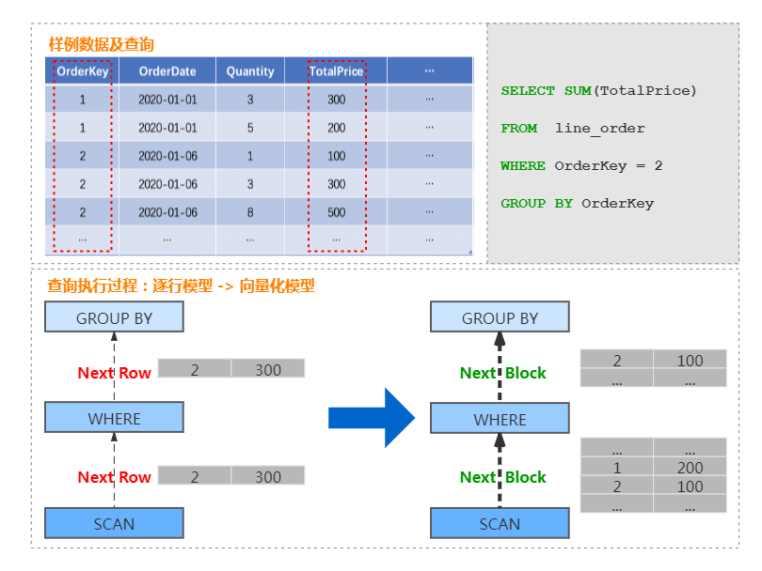
在支持列存的基礎上,ClickHouse 實現了一套面向向量化處理 的計算引擎,大量的處理操作都是向量化執行的。 相比于傳統火山模型中的逐行處理模式,向量化執行引擎采用批量處理模式,可以大幅減少函數調用開銷,降低指令、數據的 Cache Miss,提升 CPU 利用效率。并且 ClickHouse 可利用 SIMD 指令進一步加速執行效率。這部分是 ClickHouse 優于大量同類 OLAP 產品的重要因素。 以商品訂單數據為例,查詢某個訂單總價格的處理過程,由傳統的按行遍歷處理的過程,轉換為按 Block 處理的過程,具體如下圖:
3. 編碼壓縮
由于 ClickHouse 采用列存儲,相同列的數據連續存儲,且底層數據在存儲時是經過排序的,這樣數據的局部規律性非常強,有利于獲得更高的數據壓縮比。 此外,ClickHouse 除了支持 LZ4、ZSTD 等通用壓縮算法外,還支持 Delta、DoubleDelta、Gorilla 等專用編碼算法[4],用于進一步提高數據壓縮比。 其中 DoubleDelta、Gorilla 是 Facebook 專為時間序數據而設計的編碼算法,理論上在列存儲環境下,可接近專用時序存儲的壓縮比,詳細可參考 Gorilla 論文[5]。

在實際場景下,ClickHouse 通常可以達到 10 : 1 的壓縮比,大幅降低存儲成本。同時,超高的壓縮比又可以降低存儲讀取開銷、提升系統緩存能力,從而提高查詢性能。
4. 多索引
列存用于裁剪不必要的字段讀取,而索引則用于裁剪不必要的記錄讀取。ClickHouse 支持豐富的索引,從而在查詢時盡可能的裁剪不必要的記錄讀取,提高查詢性能。 ClickHouse 中最基礎的索引是主鍵索引。前面我們在物理存儲模型中介紹,ClickHouse 的底層數據按建表時指定的 ORDER BY 列進行排序,并按 index_granularity 參數切分成數據塊,然后抽取每個數據塊的第一行形成一份稀疏的排序索引。 用戶在查詢時,如果查詢條件包含主鍵列,則可以基于稀疏索引進行快速的裁剪。這里通過下面的樣例數據及對應的主鍵索引進行說明:

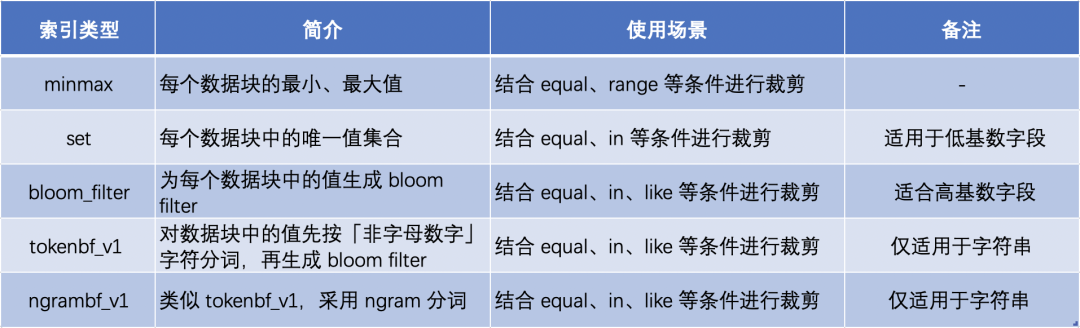
樣例中的主鍵列為 CounterID、Date,這里按每 7 個值作為一個數據塊,抽取生成了主鍵索引 Marks 部分。當用戶查詢 CounterID equal ‘h’ 的數據時,根據索引信息,只需要讀取 Mark number 為 6 和 7 的兩個數據塊。 ClickHouse 支持更多其他的索引類型,不同索引用于不同場景下的查詢裁剪,具體匯總如下,更詳細的介紹參考 ClickHouse 官方文檔[6]:
5. 物化視圖(Cube/Rollup)
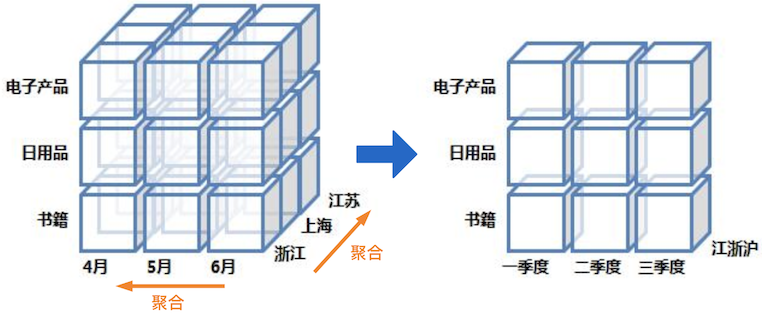
OLAP 分析領域有兩個典型的方向:一是 ROLAP,通過列存、索引等各類技術手段,提升查詢時性能。 另一是 MOLAP,通過預計算提前生成聚合后的結果數據,降低查詢讀取的數據量,屬于計算換性能方式。 前者更為靈活,但需要的技術棧相對復雜;后者實現相對簡單,但要達到的極致性能,需要生成所有常見查詢對應的物化視圖,消耗大量計算、存儲資源。物化視圖的原理如下圖所示,可以在不同維度上對原始數據進行預計算匯總:
ClickHouse 一定程度上做了兩者的結合,在盡可能采用 ROLAP 方式提高性能的同時,支持一定的 MOLAP 能力,具體實現方式為 MergeTree系列表引擎[7] 和 MATERIALIZED VIEW[8]。 事實上,Yandex.Metrica 的存儲系統也經歷過使用純粹 MOLAP 方案的發展過程,具體參考 ClickHouse的發展歷史[9]。 用戶在使用時,可優先按照 ROLAP 思路進行調優,例如主鍵選擇、索引優化、編碼壓縮等。當希望性能更高時,可考慮結合 MOLAP 方式,針對高頻查詢模式,建立少量的物化視圖,消耗可接受的計算、存儲資源,進一步換取查詢性能。
6. 其他特性
除了前面所述,ClickHouse 還有非常多其他特性,抽取列舉如下,更多詳細內容可參考 ClickHouse官方文檔[10]。
SQL 方言:在常用場景下,兼容 ANSI SQL,并支持 JDBC、ODBC 等豐富接口。
權限管控:支持 Role-Based 權限控制,與關系型數據庫使用體驗類似。
多機多核并行計算:ClickHouse 會充分利用集群中的多節點、多線程進行并行計算,提高性能。
近似查詢:支持近似查詢算法、數據抽樣等近似查詢方案,加速查詢性能。
Colocated Join:數據打散規則一致的多表進行 Join 時,支持本地化的 Colocated Join,提升查詢性能。 ……
四、ClickHouse 的不足
前面介紹了大量 ClickHouse 的核心特性,方便讀者了解 ClickHouse 高性能、快速發展的背后原因。當然,ClickHouse 作為后起之秀,遠沒有達到盡善盡美,還有不少需要待完善的方面,典型代表如下:
1. 分布式管控
分布式系統通常包含 3 個重要組成部分:存儲引擎、計算引擎、分布式管控層。ClickHouse 有一個非常突出的高性能存儲引擎,但在分布式管控層顯得較為薄弱,使得運營、使用成本偏高。主要體現在: (1)分布式表 ClickHouse 對分布式表的抽象并不完整,在多數分布式系統中,用戶僅感知集群和表,對分片和副本的管理透明,而在 ClickHouse 中,用戶需要自己去管理分片、副本,例如前面介紹的建表過程:用戶需要先創建本地表(分片的副本),然后再創建分布式表,并完成分布式表到本地表的映射。 (2)彈性伸縮 ClickHouse 集群自身雖然可以方便的水平增加節點,但并不支持自動的數據均衡。例如,當包含 6 個節點的線上生產集群因存儲 或 計算壓力大,需要進行擴容時,我們可以方便的擴容到 10 個節點,但是數據并不會自動均衡,需要用戶給已有表增加分片 或者 重新建表,再把寫入壓力重新在整個集群內打散,而存儲壓力的均衡則依賴于歷史數據過期。ClickHouse在彈性伸縮方面的不足,大幅增加了業務在進行水平伸縮時運營壓力。 基于 ClickHouse 的當前架構,實現自動均衡相對復雜,導致相關問題的根因在于 ClickHouse 分組式的分布式架構:同一分片的主從副本綁定在一組節點上,更直接的說,分片間數據打散是按照節點進行的,自動均衡過程不能簡單的搬遷分片到新節點,會導致路由信息錯誤。而創建新表并在集群中進行全量數據重新打散的方式,操作開銷過高。
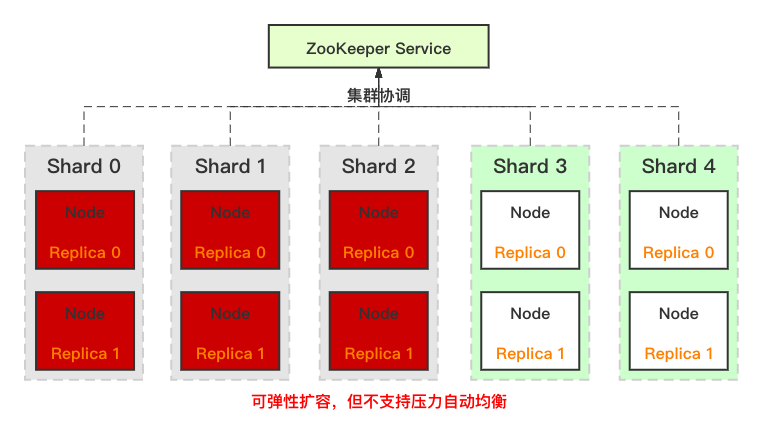
(3)故障恢復 與彈性伸縮類似,在節點故障的情況下,ClickHouse 并不會利用其它機器補齊缺失的副本數據。需要用戶先補齊節點后,然后系統再自動在副本間進行數據同步。
2. 計算引擎
雖然 ClickHouse 在單表性能方面表現非常出色,但是在復雜場景仍有不足,缺乏成熟的 MPP 計算引擎 和 執行優化器,例如:多表關聯查詢、復雜嵌套子查詢等場景下查詢性能一般,需要人工優化;缺乏 UDF 等能力,在復雜需求下擴展能力較弱等。這也和 OLAP 系統第三方評測 的結果相符。這對于性能如此出眾的存儲引擎來說,非常可惜。
3. 實時寫入
ClickHouse 采用類 LSM Tree 架構,并且建議用戶通過批量方式進行寫入,每個批次不少于 1000 行 或 每秒鐘不超過一個批次,從而提高集群寫入性能,實際測試情況下,32 vCPU & 128G 內存的情況下,單節點寫性能可達 50 MB/s ~ 200 MB/s,對應 5w ~ 20w TPS。 但 ClickHouse 并不適合實時寫入,原因在于 ClickHouse 并非典型的 LSM Tree 架構,它沒有實現 Memory Table 結構,每批次寫入直接落盤作為一棵 Tree(如果單批次過大,會拆分為多棵 Tree),每條記錄實時寫入會導致底層大量的小文件,影響查詢性能。 這使得 ClickHouse 不適合有實時寫入需求的業務,通常需要在業務和 ClickHouse 之間引入一層數據緩存層,實現批量寫入。
五、結語
本文重點分享了 ClickHouse 的整體架構及眾多核心特性,分析了 ClickHouse 如何實現極致性能的存儲引擎,從而成為 OLAP 領域的后起之秀。 ClickHouse 仍然年輕,雖然在某些方面存在不足,但極致性能的存儲引擎,使得 ClickHouse 成為一個非常優秀的存儲底座。 后續我們會在不斷拓展業務的同時,優先從分布式管控層和計算引擎層著手,持續優化 ClickHouse 的易用性、性能,打造業界領先的 OLAP 分析數據庫。同時,我們會持續輸出內核優化、最佳實踐等經驗,歡迎更多技術愛好者們一起探索、交流。
原文標題:交互式分析領域,為何 ClickHouse 能夠殺出重圍?
文章出處:【微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
數據
+關注
關注
8文章
7079瀏覽量
89165 -
數據庫
+關注
關注
7文章
3822瀏覽量
64506
原文標題:交互式分析領域,為何 ClickHouse 能夠殺出重圍?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
云數據庫是哪種數據庫類型?
ClickHouse:強大的數據分析引擎

射頻分析儀的技術原理和應用場景
多維表格數據庫Teable的適用場景?
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

NFC協議分析儀的技術原理和應用場景
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

恒訊科技分析:云數據庫rds和redis區別是什么如何選擇?
供應鏈場景使用ClickHouse最佳實踐
恒訊科技分析:sql數據庫怎么用?
鴻蒙開發接口數據管理:【@ohos.data.rdb (關系型數據庫)】


【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例





 工商網監
工商網監
評論