") 一文解析HDFS架構(gòu)及讀取寫(xiě)入數(shù)據(jù)流程
一文解析HDFS架構(gòu)及讀取寫(xiě)入數(shù)據(jù)流程
Hadoop到目前為止發(fā)展已經(jīng)有10余年,版本經(jīng)過(guò)無(wú)數(shù)次的更新迭代,目前業(yè)內(nèi)大家把Hadoop大的版本分為Hadoop1.0、Hadoop2.0、Hadoop3.0 三個(gè)版本。
一、Hadoop 簡(jiǎn)介
Hadoop版本剛出來(lái)的時(shí)候是為了解決兩個(gè)問(wèn)題:一是海量數(shù)據(jù)如何存儲(chǔ)的問(wèn)題,一個(gè)是海量數(shù)據(jù)如何計(jì)算的問(wèn)題。Hadoop的核心設(shè)計(jì)就是HDFS和 Mapreduce.HDFS解決了海量數(shù)據(jù)如何存儲(chǔ)的問(wèn)題, Mapreduce解決了海量數(shù)據(jù)如何計(jì)算的問(wèn)題。HDFS的全稱:Hadoop Distributed File System。
二、分布式文件系統(tǒng)
![]()
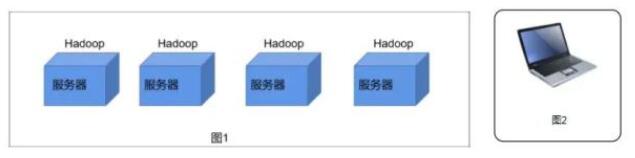
圖片 HDFS其實(shí)就可以理解為一個(gè)分布式文件系統(tǒng),可以看如圖1所示有4個(gè)服務(wù)器是不是都有他自己的文件系統(tǒng)都可以進(jìn)行存儲(chǔ)數(shù)據(jù),假設(shè)每個(gè)服務(wù)器的存儲(chǔ)空間存儲(chǔ)10G的數(shù)據(jù)。假設(shè)數(shù)據(jù)量很小的時(shí)候存儲(chǔ)10G的數(shù)據(jù)還是ok的當(dāng)數(shù)據(jù)量大于服務(wù)器的存儲(chǔ)空間時(shí)是不是單個(gè)服務(wù)器就沒(méi)法存儲(chǔ)了。 我們是不是可以在服務(wù)器中部署一個(gè)Hadoop這樣就能構(gòu)建出一個(gè)集群(超級(jí)大電腦)。這樣就存儲(chǔ) 4*10=40G的數(shù)據(jù)量,這樣我們面向用戶時(shí)是不是只有一臺(tái)超級(jí)大的電腦相當(dāng)于一個(gè)分布式文件系統(tǒng)。
HDFS是一個(gè)主從的架構(gòu)、主節(jié)點(diǎn)只有一個(gè)NemeNode。從節(jié)點(diǎn)有多個(gè)DataNode。
三、HDFS 架構(gòu)
![]()
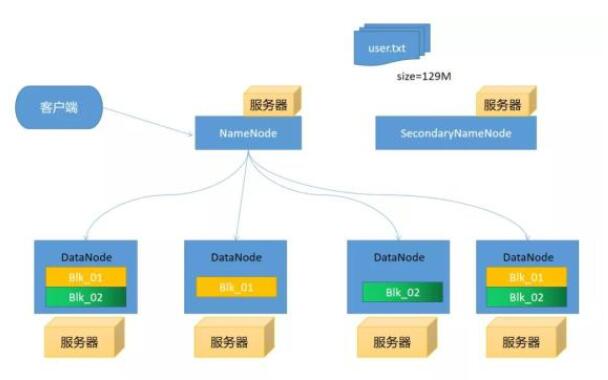
圖片 假設(shè)我們這里有5臺(tái)服務(wù)器每臺(tái)服務(wù)器都部署上Hadoop,我們隨便選擇一臺(tái)服務(wù)器部署上NameNode剩下服務(wù)器部署上DataNode。
客戶端上傳文件時(shí)假設(shè)文件大小為129MHDFS默認(rèn)切分的大小為128M這時(shí)就會(huì)產(chǎn)生出2個(gè)blkNameNode去通知DataNode上傳文件(這里有一定的策略),我們就假設(shè)就將這幾個(gè)文件分別存儲(chǔ)在4個(gè)服務(wù)器上。為什們要進(jìn)行分別存儲(chǔ)在,假設(shè)DataNode服務(wù)器有一天突然掛掉了我們是不是還可通過(guò)DataNode4或2和3進(jìn)行讀取數(shù)據(jù),這樣是不是就防止數(shù)據(jù)丟失。
NameNode
管理元數(shù)據(jù)信息(文件目錄樹(shù)):文件與Block塊,Block塊與DataNode主機(jī)關(guān)系 NameNode為快速響應(yīng)用戶操作,所以把元數(shù)據(jù)信息加載到內(nèi)存里
DataNode
存儲(chǔ)數(shù)據(jù),把上傳的數(shù)據(jù)劃分固定大小文件塊(Block)在Hadoop2.73之前是64M之后改為了128M 為了保證數(shù)據(jù)安全,每個(gè)文件默認(rèn)都是三個(gè)副本
SecondaryNamenode
周期性的到NameNode節(jié)點(diǎn)拉取Edtis和fsimage文件,將這兩個(gè)文件加入到內(nèi)存進(jìn)行 然后將這兩個(gè)文件加入到內(nèi)存中進(jìn)行合并產(chǎn)生新的fsimage發(fā)送給NameNode。
四、HDFS寫(xiě)入數(shù)據(jù)流程
客戶端會(huì)帶著文件路徑向NameNode發(fā)送寫(xiě)入請(qǐng)求通過(guò) RPC 與 NameNode 建立通訊, NameNode 檢查目標(biāo)文件,返回是否可以上傳; Client 請(qǐng)求第一個(gè) block 該傳輸?shù)侥男?DataNode 服務(wù)器上; NameNode 根據(jù)副本數(shù)量和副本放置策略進(jìn)行節(jié)點(diǎn)分配,返回DataNode節(jié)點(diǎn),如:A,B,C Client 請(qǐng)求A節(jié)點(diǎn)建立pipeline管道,A收到請(qǐng)求會(huì)繼續(xù)調(diào)用B,然后B調(diào)用C,將整個(gè)pipeline管道建立完成后,逐級(jí)返回消息到Client; Client收到A返回的消息之后開(kāi)始往A上傳第一個(gè)block塊,block塊被切分成64K的packet包不斷的在pepiline管道里傳遞,從A到B,B到C進(jìn)行復(fù)制存儲(chǔ) 當(dāng)一個(gè) block塊 傳輸完成之后,Client 再次請(qǐng)求 NameNode 上傳第二個(gè)block塊的存儲(chǔ)節(jié)點(diǎn),不斷往復(fù)存儲(chǔ) 當(dāng)所有block塊傳輸完成之后,Client調(diào)用FSDataOutputSteam的close方法關(guān)閉輸出流,最后調(diào)用FileSystem的complete方法告知NameNode數(shù)據(jù)寫(xiě)入成功
五、HDFS讀取數(shù)據(jù)流程
客戶端會(huì)先帶著讀取路徑向NameNode發(fā)送讀取請(qǐng)求,通過(guò) RPC 與 NameNode 建立通訊,NameNode檢查目標(biāo)文件,來(lái)確定請(qǐng)求文件 block塊的位置信息 NameNode會(huì)視情況返回文件的部分或者全部block塊列表,對(duì)于每個(gè)block塊,NameNode 都會(huì)返回含有該 block副本的 DataNode 地址 這些返回的 DataNode 地址,會(huì)按照集群拓?fù)浣Y(jié)構(gòu)得出 DataNode 與客戶端的距離,然后進(jìn)行排序,排序兩個(gè)規(guī)則:網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)中距離 Client 近的排靠前;心跳機(jī)制中超時(shí)匯報(bào)的 DN 狀態(tài)為 STALE,這樣的排靠后; Client 選取排序靠前的 DataNode 調(diào)用FSDataInputSteam的read方法來(lái)讀取 block塊數(shù)據(jù),如果客戶端本身就是DataNode,那么將從本地直接獲取block塊數(shù)據(jù) 當(dāng)讀完一批的 block塊后,若文件讀取還沒(méi)有結(jié)束,客戶端會(huì)繼續(xù)向NameNode 獲取下一批的 block 列表,繼續(xù)讀取 所有block塊讀取完成后,Client調(diào)用FSDataInputStream.close()方法,關(guān)閉輸入流,并將讀取來(lái)所有的 block塊合并成一個(gè)完整的最終文件
六、HDFS缺陷
注意:早期版本
單點(diǎn)問(wèn)題 內(nèi)存受限
總結(jié)
上述給大家講解了簡(jiǎn)單的HDFS架構(gòu),我在最后面留了一個(gè)小問(wèn)題,我會(huì)在下期通過(guò)畫(huà)圖的方式給大家講解,我在這里為大家提供大數(shù)據(jù)的資料需要的朋友可以去下面GitHub去下載,信自己,努力和汗水總會(huì)能得到回報(bào)的。
責(zé)任編輯:YYX
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7128瀏覽量
89364 -
存儲(chǔ)
+關(guān)注
關(guān)注
13文章
4344瀏覽量
86047 -
HDFS
+關(guān)注
關(guān)注
1文章
30瀏覽量
9623
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
影響25Q20D閃存芯片寫(xiě)入速度和使用壽命的因素有哪些?

適用于Oracle的SSIS數(shù)據(jù)流組件:提供快速導(dǎo)入及導(dǎo)出功能

芯片封測(cè)架構(gòu)和芯片封測(cè)流程
使用STM32的spi與AFE4400通信,每寫(xiě)入或讀取一個(gè)數(shù)據(jù)都需要等待幾百微秒后才能繼續(xù)操作否則讀取的數(shù)據(jù)都是0,為什么?
使用ads1219這款模數(shù)轉(zhuǎn)換器,讀寫(xiě)流程和使用single-shot模式和continuous的區(qū)別是什么?
請(qǐng)問(wèn)TLV320AIC3254EVM-K怎么讀取音頻數(shù)據(jù)流?
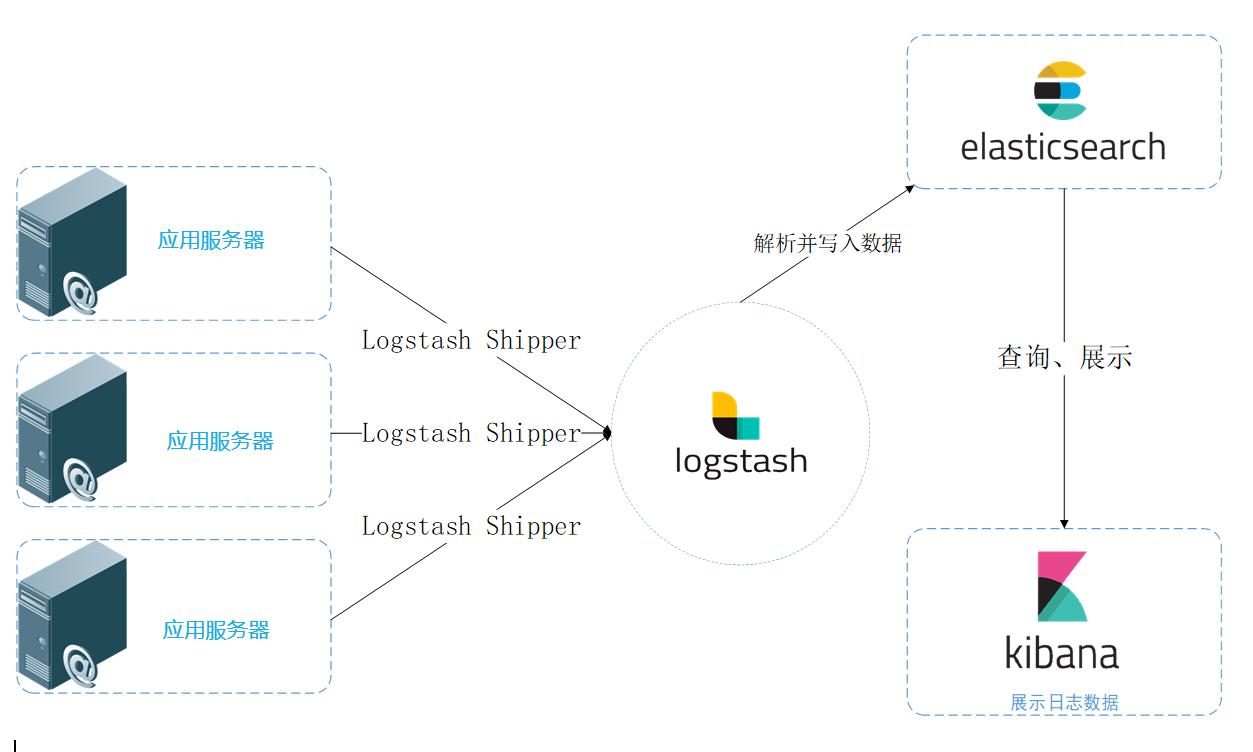
統(tǒng)一日志數(shù)據(jù)流圖
自動(dòng)售貨機(jī)MDB協(xié)議中文解析(六)MDB-RS232控制硬幣器的流程和解析

ESP32可以直接寫(xiě)入RX的高低電平,和直接讀取TX的高低電平嗎?
請(qǐng)問(wèn)如何從APPL_InputMapping和APPL_OutputMapping讀取數(shù)據(jù)?
STM32F030 FLASH存儲(chǔ),第二次或者多次寫(xiě)入或者擦除的時(shí)候讀取不到數(shù)據(jù)是為什么?
一文解析DARM工藝流程

交換芯片架構(gòu)設(shè)計(jì)
空指針區(qū)域寫(xiě)入數(shù)據(jù)會(huì)hardfault,為什么測(cè)試時(shí)讀取卻不會(huì)hardfault?
?PLC從HTTP服務(wù)端獲取JSON文件,解析數(shù)據(jù)到寄存器
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論