 CPU場景下的TLB相關細節
CPU場景下的TLB相關細節
一、前言
進程切換是一個復雜的過程,本文不準備詳細描述整個進程切換的方方面面,而是關注進程切換中一個小小的知識點:TLB的處理。為了能夠講清楚這個問題,我們在第二章描述在單CPU場景下一些和TLB相關的細節,第三章推進到多核場景,至此,理論部分結束。在第二章和第三章,我們從基本的邏輯角度出發,并不拘泥于特定的CPU和特定的OS,這里需要大家對基本的TLB的組織原理有所了解,具體可以參考本站的《TLB操作》一文。再好的邏輯也需要體現在HW block和SW block的設計中,在第四章,我們給出了linux4.4.6內核在ARM64平臺上的TLB代碼處理細節(在描述tlb lazy mode的時候引入部分x86架構的代碼),希望能通過具體的代碼和實際的CPU硬件行為加深大家對原理的理解。
二、單核場景的工作原理
1、block diagram
我們先看看在單核場景下,和進程切換相關的邏輯block示意圖:
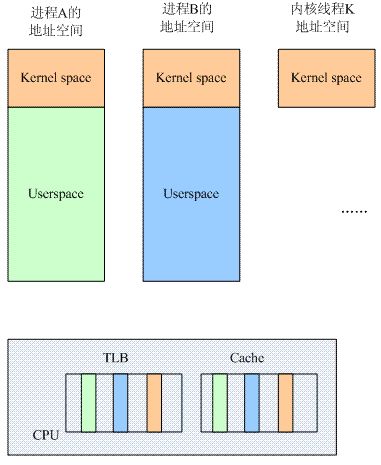
CPU上運行了若干的用戶空間的進程和內核線程,為了加快性能,CPU中往往設計了TLB和Cache這樣的HW block。Cache為了更快的訪問main memory中的數據和指令,而TLB是為了更快的進行地址翻譯而將部分的頁表內容緩存到了Translation lookasid buffer中,避免了從main memory訪問頁表的過程。
假如不做任何的處理,那么在進程A切換到進程B的時候,TLB和Cache中同時存在了A和B進程的數據。對于kernel space其實無所謂,因為所有的進程都是共享的,但是對于A和B進程,它們各種有自己的獨立的用戶地址空間,也就是說,同樣的一個虛擬地址X,在A的地址空間中可以被翻譯成Pa,而在B地址空間中會被翻譯成Pb,如果在地址翻譯過程中,TLB中同時存在A和B進程的數據,那么舊的A地址空間的緩存項會影響B進程地址空間的翻譯,因此,在進程切換的時候,需要有tlb的操作,以便清除舊進程的影響,具體怎樣做呢?我們下面一一討論。
2、絕對沒有問題,但是性能不佳的方案
當系統發生進程切換,從進程A切換到進程B,從而導致地址空間也從A切換到B,這時候,我們可以認為在A進程執行過程中,所有TLB和Cache的數據都是for A進程的,一旦切換到B,整個地址空間都不一樣了,因此需要全部flush掉(注意:我這里使用了linux內核的術語,flush就是意味著將TLB或者cache中的條目設置為無效,對于一個ARM平臺上的嵌入式工程師,一般我們會更習慣使用invalidate這個術語,不管怎樣,在本文中,flush等于invalidate)。
這種方案當然沒有問題,當進程B被切入執行的時候,其面對的CPU是一個干干凈凈,從頭開始的硬件環境,TLB和Cache中不會有任何的殘留的A進程的數據來影響當前B進程的執行。當然,稍微有一點遺憾的就是在B進程開始執行的時候,TLB和Cache都是冰冷的(空空如也),因此,B進程剛開始執行的時候,TLB miss和Cache miss都非常嚴重,從而導致了性能的下降。
3、如何提高TLB的性能?
對一個模塊的優化往往需要對該模塊的特性進行更細致的分析、歸類,上一節,我們采用進程地址空間這樣的術語,其實它可以被進一步細分為內核地址空間和用戶地址空間。對于所有的進程(包括內核線程),內核地址空間是一樣的,因此對于這部分地址翻譯,無論進程如何切換,內核地址空間轉換到物理地址的關系是永遠不變的,其實在進程A切換到B的時候,不需要flush掉,因為B進程也可以繼續使用這部分的TLB內容(上圖中,橘色的block)。對于用戶地址空間,各個進程都有自己獨立的地址空間,在進程A切換到B的時候,TLB中的和A進程相關的entry(上圖中,青色的block)對于B是完全沒有任何意義的,需要flush掉。
在這樣的思路指導下,我們其實需要區分global和local(其實就是process-specific的意思)這兩種類型的地址翻譯,因此,在頁表描述符中往往有一個bit來標識該地址翻譯是global還是local的,同樣的,在TLB中,這個標識global還是local的flag也會被緩存起來。有了這樣的設計之后,我們可以根據不同的場景而flush all或者只是flush local tlb entry。
4、特殊情況的考量
我們考慮下面的場景:進程A切換到內核線程K之后,其實地址空間根本沒有必要切換,線程K能訪問的就是內核空間的那些地址,而這些地址也是和進程A共享的。既然沒有切換地址空間,那么也就不需要flush 那些進程特定的tlb entry了,當從K切換會A進程后,那么所有TLB的數據都是有效的,從大大降低了tlb miss。此外,對于多線程環境,切換可能發生在一個進程中的兩個線程,這時候,線程在同樣的地址空間,也根本不需要flush tlb。
4、進一步提升TLB的性能
還有可能進一步提升TLB的性能嗎?有沒有可能根本不flush TLB?
當然可以,不過這需要我們在設計TLB block的時候需要識別process specific的tlb entry,也就是說,TLB block需要感知到各個進程的地址空間。為了完成這樣的設計,我們需要標識不同的address space,這里有一個術語叫做ASID(address space ID)。原來TLB查找是通過虛擬地址VA來判斷是否TLB hit。有了ASID的支持后,TLB hit的判斷標準修改為(虛擬地址+ASID),ASID是每一個進程分配一個,標識自己的進程地址空間。TLB block如何知道一個tlb entry的ASID呢?一般會來自CPU的系統寄存器(對于ARM64平臺,它來自TTBRx_EL1寄存器),這樣在TLB block在緩存(VA-PA-Global flag)的同時,也就把當前的ASID緩存在了對應的TLB entry中,這樣一個TLB entry中包括了(VA-PA-Global flag-ASID)。
有了ASID的支持后,A進程切換到B進程再也不需要flush tlb了,因為A進程執行時候緩存在TLB中的殘留A地址空間相關的entry不會影響到B進程,雖然A和B可能有相同的VA,但是ASID保證了硬件可以區分A和B進程地址空間。
三、多核的TLB操作
1、block diagram
完成單核場景下的分析之后,我們一起來看看多核的情況。進程切換相關的TLB邏輯block示意圖如下:
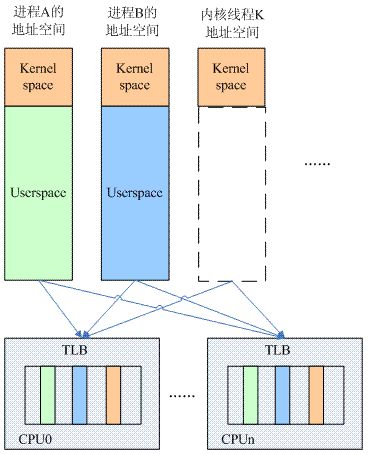
在多核系統中,進程切換的時候,TLB的操作要復雜一些,主要原因有兩點:其一是各個cpu core有各自的TLB,因此TLB的操作可以分成兩類,一類是flush all,即將所有cpu core上的tlb flush掉,還有一類操作是flush local tlb,即僅僅flush本cpu core的tlb。另外一個原因是進程可以調度到任何一個cpu core上執行(當然具體和cpu affinity的設定相關),從而導致task處處留情(在各個cpu上留有殘余的tlb entry)。
2、TLB操作的基本思考
根據上一節的描述,我們了解到地址翻譯有global(各個進程共享)和local(進程特定的)的概念,因而tlb entry也有global和local的區分。如果不區分這兩個概念,那么進程切換的時候,直接flush該cpu上的所有殘余。這樣,當進程A切出的時候,留給下一個進程B一個清爽的tlb,而當進程A在其他cpu上再次調度的時候,它面臨的也是一個全空的TLB(其他cpu的tlb不會影響)。當然,如果區分global 和local,那么tlb操作也基本類似,只不過進程切換的時候,不是flush該cpu上的所有tlb entry,而是flush所有的tlb local entry就OK了。
對local tlb entry還可以進一步細分,那就是了ASID(address space ID)或者PCID(process context ID)的概念了(global tlb entry不區分ASID)。如果支持ASID(或者PCID)的話,tlb操作變得簡單一些,或者說我們沒有必要執行tlb操作了,因為在TLB搜索的時候已經可以區分各個task上下文了,這樣,各個cpu中殘留的tlb不會影響其他任務的執行。在單核系統中,這樣的操作可以獲取很好的性能。比如A---B--->A這樣的場景中,如果TLB足夠大,可以容納2個task的tlb entry(現代cpu一般也可以做到這一點),那么A再次切回的時候,TLB是hot的,大大提升了性能。
不過,對于多核系統,這種情況有一點點的麻煩,其實也就是傳說中的TLB shootdown帶來的性能問題。在多核系統中,如果cpu支持PCID并且在進程切換的時候不flush tlb,那么系統中各個cpu中的tlb entry則保留各種task的tlb entry,當在某個cpu上,一個進程被銷毀,或者修改了自己的頁表(也就是修改了VA PA映射關系)的時候,我們必須將該task的相關tlb entry從系統中清除出去。這時候,你不僅僅需要flush本cpu上對應的TLB entry,還需要shootdown其他cpu上的和該task相關的tlb殘余。而這個動作一般是通過IPI實現(例如X86),從而引入了開銷。此外PCID的分配和管理也會帶來額外的開銷,因此,OS是否支持PCID(或者ASID)是由各個arch代碼自己決定(對于linux而言,x86不支持,而ARM平臺是支持的)。
四、進程切換中的tlb操作代碼分析
1、tlb lazy mode
在context_switch中有這樣的一段代碼:
if (!mm) {
next->active_mm = oldmm;
atomic_inc(&oldmm->mm_count);
enter_lazy_tlb(oldmm, next);
} else
switch_mm(oldmm, mm, next);
這段代碼的意思就是如果要切入的next task是一個內核線程(next->mm == NULL )的話,那么可以通過enter_lazy_tlb函數標記本cpu上的next task進入lazy TLB mode。由于ARM64平臺上的enter_lazy_tlb函數是空函數,因此我們采用X86來描述lazy TLB mode。
當然,我們需要一些準備工作,畢竟對于熟悉ARM平臺的嵌入式工程師而言,x86多少有點陌生。
到目前,我們還都是從邏輯角度來描述TLB操作,但是在實際中,進程切換中的tlb操作是HW完成還是SW完成呢?不同的處理器思路是不一樣的(具體原因未知),有的處理器是HW完成,例如X86,在加載cr3寄存器進行地址空間切換的時候,hw會自動操作tlb。而有的處理是需要軟件參與完成tlb操作,例如ARM系列的處理器,在切換TTBR寄存器的時候,HW沒有tlb動作,需要SW完成tlb操作。因此,x86平臺上,在進程切換的時候,軟件不需要顯示的調用tlb flush函數,在switch_mm函數中會用next task中的mm->pgd加載CR3寄存器,這時候load cr3的動作會導致本cpu中的local tlb entry被全部flush掉。
在x86支持PCID(X86術語,相當與ARM的ASID)的情況下會怎樣呢?也會在load cr3的時候flush掉所有的本地CPU上的 local tlb entry嗎?其實在linux中,由于TLB shootdown,普通的linux并不支持PCID(KVM中會使用,但是不在本文考慮范圍內),因此,對于x86的進程地址空間切換,它就是會有flush local tlb entry這樣的side effect。
另外有一點是ARM64和x86不同的地方:ARM64支持在一個cpu core執行tlb flush的指令,例如tlbi vmalle1is,將inner shareablity domain中的所有cpu core的tlb全部flush掉。而x86不能,如果想要flush掉系統中多有cpu core的tlb,只能是通過IPI通知到其他cpu進行處理。
好的,至此,所有預備知識都已經ready了,我們進入tlb lazy mode這個主題。雖然進程切換伴隨tlb flush操作,但是某些場景亦可避免。在下面的場景,我們可以不flush tlb(我們仍然采用A--->B task的場景來描述):
(1)如果要切入的next task B是內核線程,那么我們也暫時不需要flush TLB,因為內核線程不會訪問usersapce,而那些進程A殘留的TLB entry也不會影響內核線程的執行,畢竟B沒有自己的用戶地址空間,而且和A共享內核地址空間。
(2)如果A和B在一個地址空間中(一個進程中的兩個線程),那么我們也暫時不需要flush TLB。
除了進程切換,還有其他的TLB flush場景。我們先看一個通用的TLB flush場景,如下圖所示:
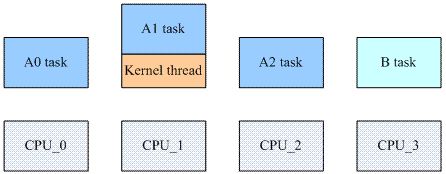
一個4核系統中,A0 A1和A2 task屬于同一個進程地址空間,CPU_0和CPU_2上分別運行了A0和A2 task,CPU_1有點特殊,它正在運行一個內核線程,但是該內核線程正在借用A1 task的地址空間,CPU_3上運行不相關的B task。
當A0 task修改了自己的地址翻譯,那么它不能只是flush CPU_0的tlb,還需要通知到CPU_1和CPU_2,因為這兩個CPU上當前active的地址空間和CPU_0是一樣的。由于A1 task的修改,CPU_1和CPU_2上的這些緩存的TLB entry已經失效了,需要flush。同理,可以推廣到更多的CPU上,也就是說,在某個CPUx上運行的task修改了地址映射關系,那么tlb flush需要傳遞到所有相關的CPU中(當前的mm等于CPUx的current mm)。在多核系統中,這樣的通過IPI來傳遞TLB flush的消息會隨著cpu core的增加而增加,有沒有辦法減少那些沒有必要的TLB flush呢?當然有,也就是上圖中的A1 task場景,這也就是傳說中的lazy tlb mode。
我先回頭看看代碼。在代碼中,如果next task是內核線程,我們并不會執行switch_mm(該函數會引起tlb flush的動作),而是調用enter_lazy_tlb進入lazy tlb mode。在x86架構下,代碼如下:
static inline void enter_lazy_tlb(struct mm_struct *mm, struct task_struct *tsk)
{
#ifdef CONFIG_SMP
if (this_cpu_read(cpu_tlbstate.state) == TLBSTATE_OK)
this_cpu_write(cpu_tlbstate.state, TLBSTATE_LAZY);
#endif
}
在x86架構下,進入lazy tlb mode也就是在該cpu的cpu_tlbstate變量中設定TLBSTATE_LAZY的狀態就OK了。因此,進入lazy mode的時候,也就不需要調用switch_mm來切換進程地址空間,也就不會執行flush tlb這樣毫無意義的動作了。enter_lazy_tlb并不操作硬件,只要記錄該cpu的軟件狀態就OK了。
切換之后,內核線程進入執行狀態,CPU_1的TLB殘留進程A的entry,這對于內核線程的執行沒有影響,但是當其他CPU發送IPI要求flush TLB的時候呢?按理說應該立刻flush tlb,但是在lazy tlb mode下,我們可以不執行flush tlb操作。這樣問題來了:什么時候flush掉殘留的A進程的tlb entry呢?答案是在下一次進程切換中。因為一旦內核線程被schedule out,并且切入一個新的進程C,那么在switch_mm,切入到C進程地址空間的時候,所有之前的殘留都會被清除掉(因為有load cr3的動作)。因此,在執行內核線程的時候,我們可以推遲tlb invalidate的請求。也就是說,當收到ipi中斷要求進行該mm的tlb invalidate的動作的時候,我們暫時沒有必要執行了,只需要記錄狀態就OK了。
2、ARM64中如何管理ASID?
和x86不同的是:ARM64支持了ASID(類似x86的PCID),難道ARM64解決了TLB Shootdown的問題?其實我也在思考這個問題,但是還沒有想明白。很顯然,在ARM64中,我們不需要通過IPI來進行所有cpu core的TLB flush動作,ARM64在指令集層面支持shareable domain中所有PEs上的TLB flush動作,也許是這樣的指令讓TLB flush的開銷也沒有那么大,那么就可以選擇支持ASID,在進程切換的時候不需要進行任何的TLB操作,同時,由于不需要IPI來傳遞TLB flush,那么也就沒有特別的處理lazy tlb mode了。
既然linux中,ARM64選擇支持ASID,那么它就要直面ASID的分配和管理問題了。硬件支持的ASID有一定限制,它的編址空間是8個或者16個bit,最大256或者65535個ID。當ASID溢出之后如何處理呢?這就需要一些軟件的控制來協調處理。我們用硬件支持上限為256個ASID的情景來描述這個基本的思路:當系統中各個cpu的TLB中的asid合起來不大于256個的時候,系統正常運行,一旦超過256的上限后,我們將全部TLB flush掉,并重新分配ASID,每達到256上限,都需要flush tlb并重新分配HW ASID。具體分配ASID代碼如下:
static u64 new_context(struct mm_struct *mm, unsigned int cpu)
{
static u32 cur_idx = 1;
u64 asid = atomic64_read(&mm->context.id);
u64 generation = atomic64_read(&asid_generation);
if (asid != 0) {-------------------------(1)
u64 newasid = generation | (asid & ~ASID_MASK);
if (check_update_reserved_asid(asid, newasid))
return newasid;
asid &= ~ASID_MASK;
if (!__test_and_set_bit(asid, asid_map))
return newasid;
}
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, cur_idx);---(2)
if (asid != NUM_USER_ASIDS)
goto set_asid;
generation = atomic64_add_return_relaxed(ASID_FIRST_VERSION,----(3)
&asid_generation);
flush_context(cpu);
asid = find_next_zero_bit(asid_map, NUM_USER_ASIDS, 1); ------(4)
set_asid:
__set_bit(asid, asid_map);
cur_idx = asid;
return asid | generation;
}
(1)在創建新的進程的時候會分配一個新的mm,其software asid(mm->context.id)初始化為0。如果asid不等于0那么說明這個mm之前就已經分配過software asid(generation+hw asid)了,那么new context不過就是將software asid中的舊的generation更新為當前的generation而已。
(2)如果asid等于0,說明我們的確是需要分配一個新的HW asid,這時候首先要找一個空閑的HW asid,如果能夠找到(jump to set_asid),那么直接返回software asid(當前generation+新分配的hw asid)。
(3)如果找不到一個空閑的HW asid,說明HW asid已經用光了,這是只能提升generation了。這時候,多有cpu上的所有的old generation需要被flush掉,因為系統已經準備進入new generation了。順便一提的是這里generation變量已經被賦值為new generation了。
(4)在flush_context函數中,控制HW asid的asid_map已經被全部清零了,因此,這里進行的是new generation中HW asid的分配。
3、進程切換過程中ARM64的tlb操作以及ASID的處理
代碼位于arch/arm64/mm/context.c中的check_and_switch_context:
void check_and_switch_context(struct mm_struct *mm, unsigned int cpu)
{
unsigned long flags;
u64 asid;
asid = atomic64_read(&mm->context.id); -------------(1)
if (!((asid ^ atomic64_read(&asid_generation)) >> asid_bits) ------(2)
&& atomic64_xchg_relaxed(&per_cpu(active_asids, cpu), asid))
goto switch_mm_fastpath;
raw_spin_lock_irqsave(&cpu_asid_lock, flags);
asid = atomic64_read(&mm->context.id);
if ((asid ^ atomic64_read(&asid_generation)) >> asid_bits) { ------(3)
asid = new_context(mm, cpu);
atomic64_set(&mm->context.id, asid);
}
if (cpumask_test_and_clear_cpu(cpu, &tlb_flush_pending)) ------(4)
local_flush_tlb_all();
atomic64_set(&per_cpu(active_asids, cpu), asid);
raw_spin_unlock_irqrestore(&cpu_asid_lock, flags);
switch_mm_fastpath:
cpu_switch_mm(mm->pgd, mm);
}
看到這些代碼的時候,你一定很抓狂:本來期望支持ASID的情況下,進程切換不需要TLB flush的操作了嗎?怎么會有那么多代碼?呵呵~~實際上理想很美好,現實很骨干,代碼中嵌入太多管理asid的內容了。
(1)現在準備切入mm變量指向的地址空間,首先通過內存描述符獲取該地址空間的ID(software asid)。需要說明的是這個ID并不是HW asid,實際上mm->context.id是64個bit,其中低16 bit對應HW 的ASID(ARM64支持8bit或者16bit的ASID,但是這里假設當前系統的ASID是16bit)。其余的bit都是軟件擴展的,我們稱之generation。
(2)arm64支持ASID的概念,理論上進程切換不需要TLB的操作,不過由于HW asid的編址空間有限,因此我們擴展了64 bit的software asid,其中一部分對應HW asid,另外一部分被稱為asid generation。asid generation從ASID_FIRST_VERSION開始,每當HW asid溢出后,asid generation會累加。asid_bits就是硬件支持的ASID的bit數目,8或者16,通過ID_AA64MMFR0_EL1寄存器可以獲得該具體的bit數目。
當要切入的mm的software asid仍然處于當前這一批次(generation)的ASID的時候,切換中不需要任何的TLB操作,可以直接調用cpu_switch_mm進行地址空間的切換,當然,也會順便設定active_asids這個percpu變量。
(3)如果要切入的進程和當前的asid generation不一致,那么說明該地址空間需要一個新的software asid了,更準確的說是需要推進到new generation了。因此這里調用new_context分配一個新的context ID,并設定到mm->context.id中。
(4)各個cpu在切入新一代的asid空間的時候會調用local_flush_tlb_all將本地tlb flush掉。
原文標題:郭健: 進程切換分析之——TLB處理
文章出處:【微信公眾號:Linuxer】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
cpu
+關注
關注
68文章
10898瀏覽量
212600
原文標題:郭健: 進程切換分析之——TLB處理
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華為支付-(可選)特定場景配置操作
如何限制容器可以使用的CPU資源

TAS6424E-Q1什么場景下bit4會置為1?
雙核cpu和單核cpu的區別
不同使用場景下的TLV320ADCx120和PCMx120-Q1功耗矩陣

單北斗定位終端的優勢在哪些場景下更加凸顯

FPGA與MCU的應用場景
如何在不同應用場景下構建音頻測試環境

TLB成功開發出CXL內存模塊PCB,并向三星和SK海力士提供首批樣品
CPU渲染和GPU渲染優劣分析

CS32F03X鋰電池供電場景下估算VDDA電壓
AI邊緣盒子助力安全生產相關等場景

緩存大小對CPU性能的影響解析






 工商網監
工商網監
評論