 電子發燒友App
電子發燒友App


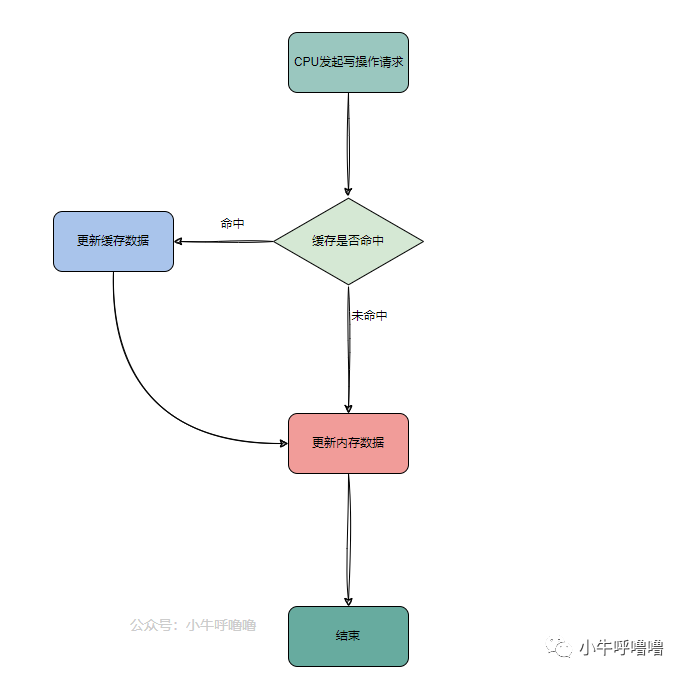
CPU Cache是CPU高速緩沖存儲器的簡稱,本文將其簡稱為"緩存"或者"Cache".
本篇首先從計算機的存儲層次出發介紹計算機的性能瓶頸,然后以Intel處理器為例介紹緩存的發展,隨后介紹緩存提升CPU性能的局部性原理,最后分析緩存大小對CPU性能的影響。
一、計算機性能的瓶頸
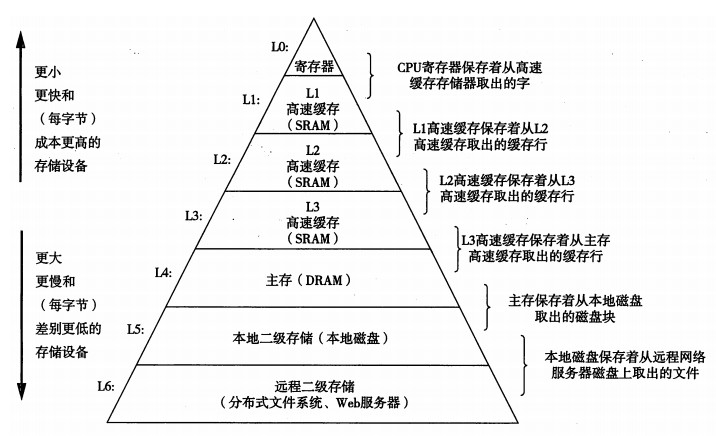
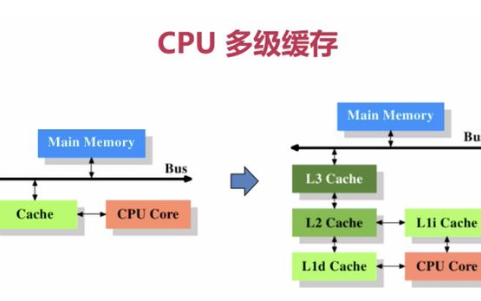
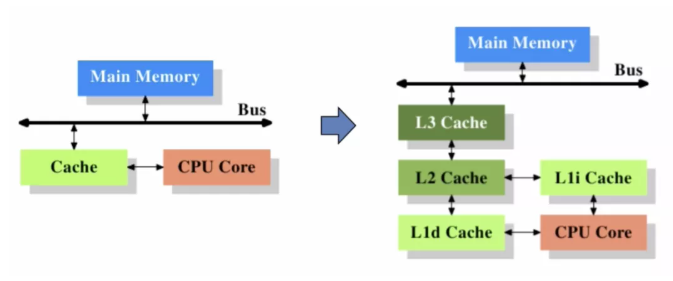
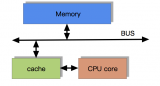
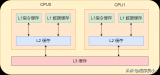
在馮諾依曼架構下,計算機存儲器是分層次的,存儲器的層次結構如下圖所示,是金字塔形狀。從上到下依次是寄存器、L1緩存、L2緩存,L3緩存主存(內存)、硬盤等等。
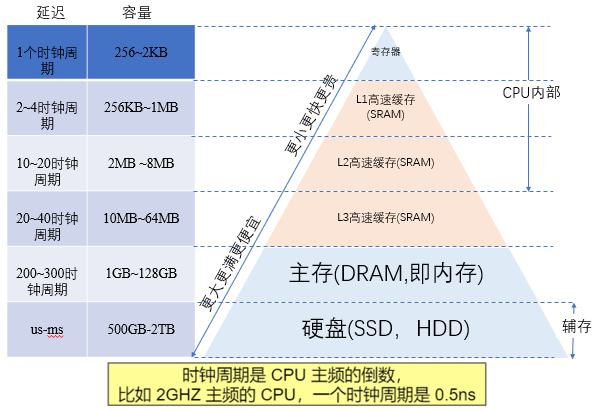
離CPU越近的存儲器,訪問速度越來越快,容量越來越小,每字節的成本也越來越昂貴。
如一個主頻為3.0GHZ的CPU,寄存器的速度最快,可以在1個時鐘周期內訪問,一個時鐘周期(CPU中基本時間單位)大約是0.3納秒,內存訪問大約需要120納秒,固態硬盤訪問大約需要50-150微秒,機械硬盤訪問大約需要1-10毫秒。
電子計算機剛出來的時候,其實CPU是沒有緩存Cache的,那個時候的CPU主頻很低,甚至沒有內存高,CPU都是直接讀寫內存的。隨著時代的發展,技術的革新,從1980年代開始,差距開始迅速擴大,CPU的速度遠遠超過內存的速度,在馮諾依曼架構下,CPU訪問內存的速度也就成了計算機性能的瓶頸!
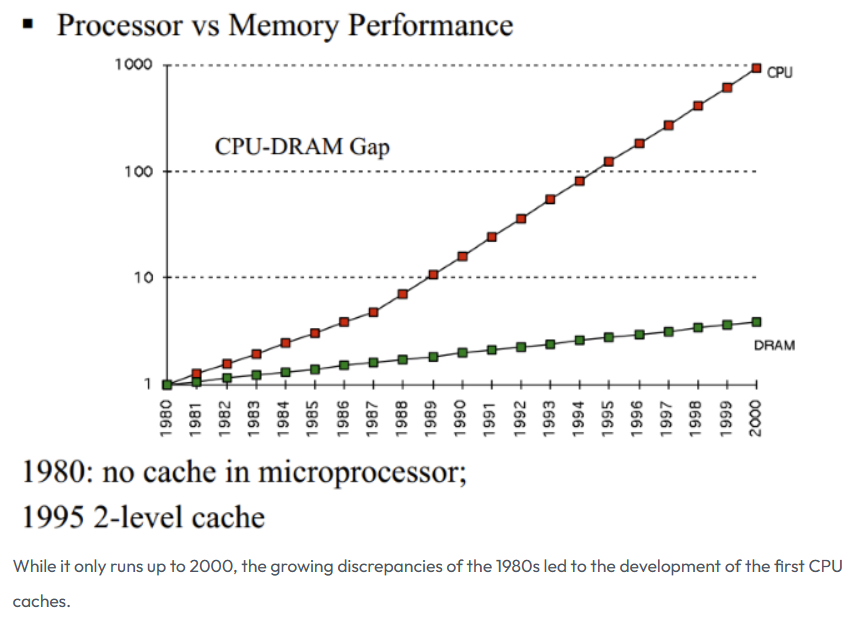
圖片來源于:How L1 and L2 CPU Caches Work, and Why They're an Essential Part of Modern Chips
為了彌補CPU與內存兩者之間的性能差異,也就是要加快CPU訪問內存的速度,就引入了緩存CPU Cache,緩存的速度僅次于寄存器,充當了CPU與內存之間的中間角色。
二、緩存及其發展歷史
緩存CPU?Cache用的是 SRAM(Static Random-Access Memory)存儲,也叫靜態隨機存儲器。其只要有電,數據就可以保持存在,而一旦斷電,數據就會丟失。
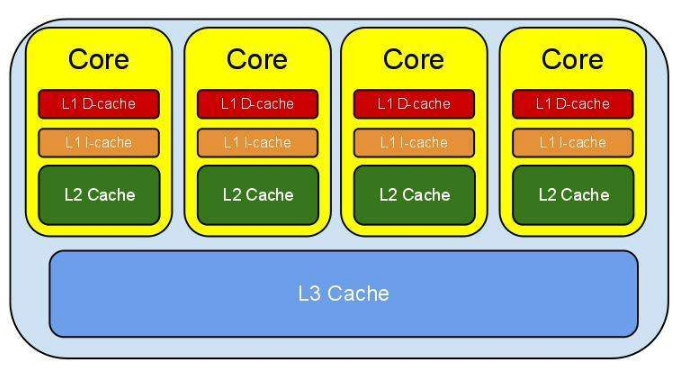
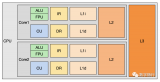
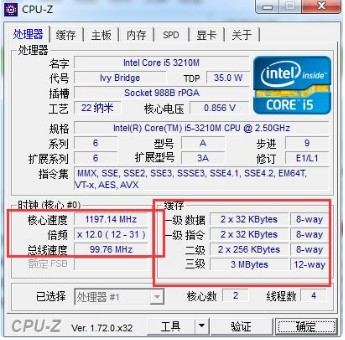
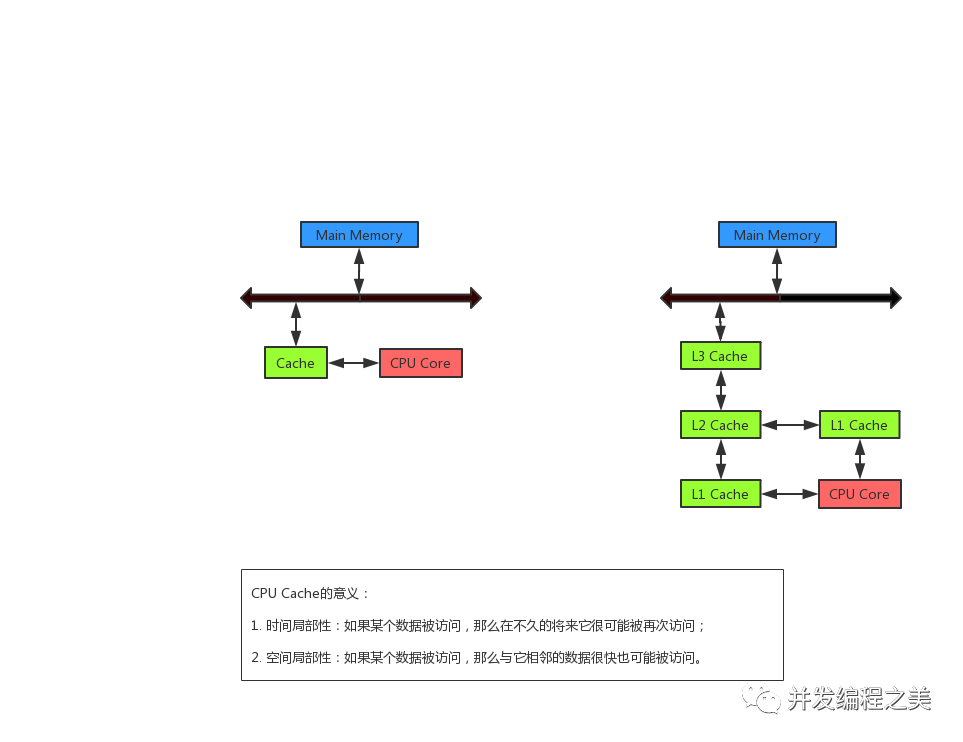
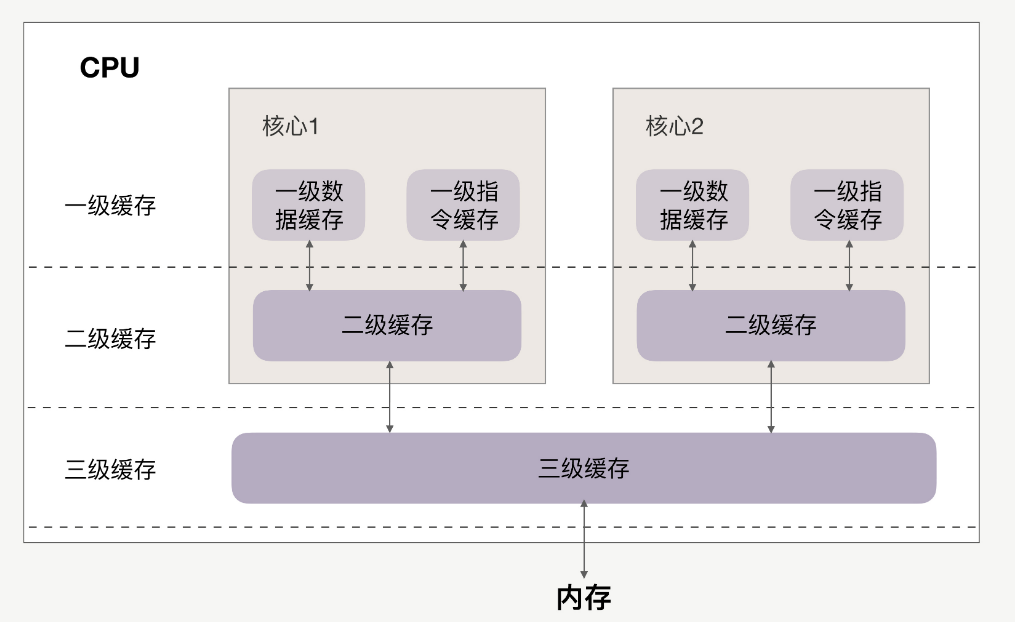
CPU Cache 通常分為大小不等的3級緩存,分別是 L1 Cache、L2 Cache 和 L3 Cache。常見的Cache典型分布圖如下:
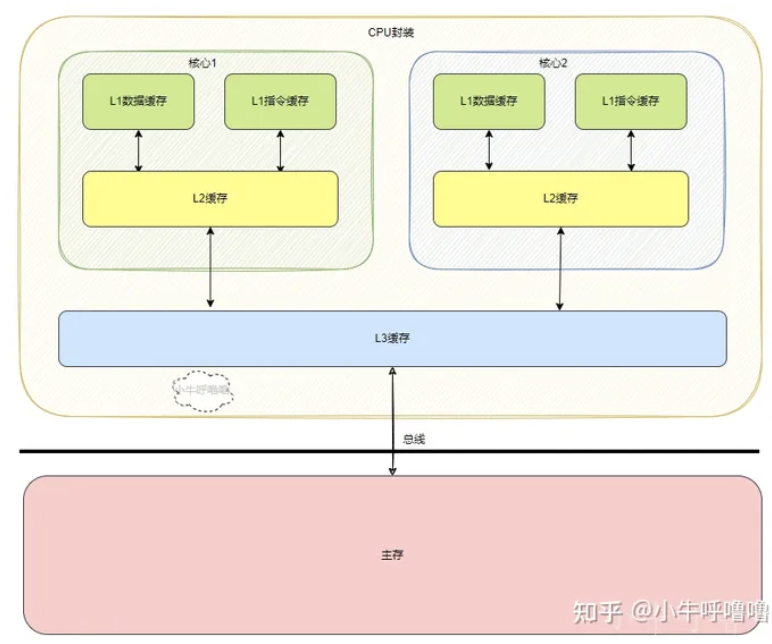
這里以intel系列為例,回顧Cache發展歷史。
在80286之前,那個時候是沒有緩存Cache的,那個時候的CPU主頻很低,甚至沒有內存高,CPU都是直接讀寫內存的。
從80386開始,這個CPU速度和內存速度不匹配問題已經開始展露,并且差距開始迅速擴大,慢速度的內存成為了計算機的瓶頸,無法充分發揮CPU的性能,為解決這個問題,Intel主板支持外部Cache,來配合80386運行。
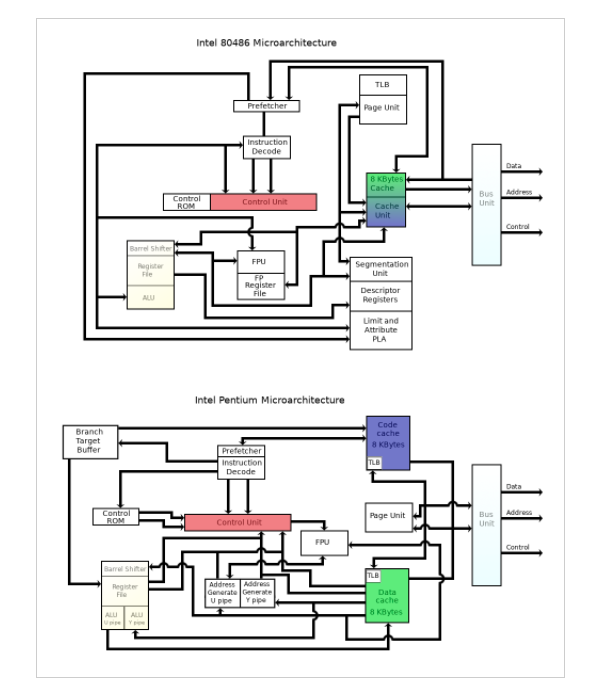
80486將L1 Cache(大小8KB)放到CPU內部,同時支持外接Cache,即L2 Cache(大小從128KB到256KB),但是不分指令和數據。雖然L1 Cache大小只有8KB,但其實對那時候CPU來說夠用了,我們來看一副緩存命中率與L1、L2大小的關系圖:
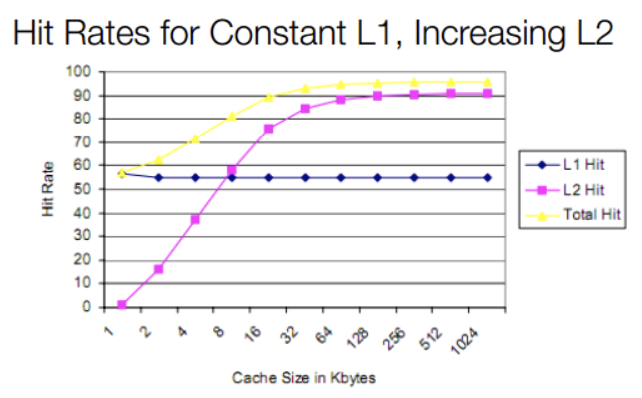
圖片來源于:How L1 and L2 CPU Caches Work, and Why They're an Essential Part of Modern Chips。
從上圖我們可以發現,增大L1 cache對于CPU來說好處不太明顯,緩存命中率并沒有顯著提升,成本還會更昂高,所以性價比不高。而隨著L2 cache 大小的增加,緩存總命中率會急劇上升,因此容量更大、速度較慢、更便宜的L2成為了更好的選擇。
等到Pentium-1/80586,也就是我們熟悉的奔騰系列,由于Pentium采用了雙路執行的超標量結構,有2條并行整數流水線,需要對數據和指令進行雙重的訪問,為了使得這些訪問互不干涉,于是L1 Cache被一分為二,分為指令Cache和數據Cache(大小都是8K)【將數據和指令分別存取的存取結構叫做哈佛結構,區別于混在一起的馮·諾伊曼結構】,此時的L2 Cache還是在主板上,再后來Intel推出了[Pentium Pro]/80686,為了進一步提高性能,L2 Cache被正式放到CPU內部。
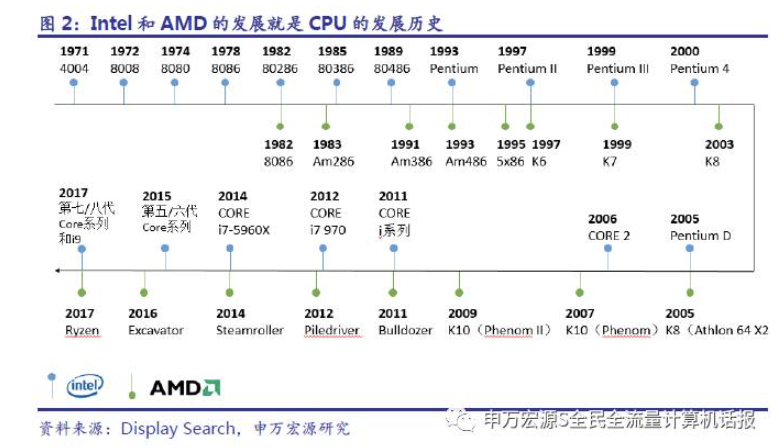
在CPU外面,DRAM內存還是那么一套內存,硬盤也是那么一套不區分指令和數據的硬盤。因而可以說x86 CPU是在內部采用哈佛結構、外部仍然是馮·諾伊曼結構。實際上除了少數單片機、DSP等設備,誰也不會最外層的存儲設備都區分數據和指令。所以這種內部哈佛,外部馮·諾伊曼結構的做法似乎已經成了業界共識。
后來CPU多核時代來臨,Intel的Pentium D、Pentium E系列,CPU內部每個核心都有自己的L1、L2 Cache,但他們并不共享,只能依靠總線來傳遞同步緩存數據。最后Core Duo酷睿系列的出現,L2 Cache變成多核共享模式,采用Intel的“Smart cache”共享緩存技術,到此為止,就確定了現代緩存的基本模式。
如今CPU Cache通常分為大小不等的3級緩存,分別是 L1 Cache、L2 Cache 和 L3 Cache,L3 高速緩存為多個 CPU 核心共用的,而L2則被每個核心單獨占據,另外現在有的CPU已經有了L4 Cache,未來可能會更多。
三、緩存如何彌補CPU與內存的性能差異?
緩存主要是利用局部性原理來提升計算機的整體性能。因為緩存的性能僅次于寄存器,而CPU與內存兩者之間的產生的分歧,主要是二者存取速度數量級的差距,盡可能多地讓CPU去存取緩存,同時減少CPU直接訪問主存的次數,這樣計算機的性能就自然而然地得到巨大的提升。
所謂局部性原理,主要分為空間局部性與時間局部性:
時間局部性:被引用過一次的存儲器位置在未來會被多次引用(通常在循環中)。
空間局部性:如果一個存儲器的位置被引用,那么將來它附近的位置也會被引用。
緩存會把CPU最近訪問主存(內存)中的指令和數據臨時儲存,因為根據局部性原理,這些指令和數據在較短的時間間隔內很可能會被以后多次使用到,其次是當從主存中取回這些數據時,會同時取回與其位置相鄰的主存單元的存放的數據臨時儲存到緩存中,因為該指令和數據附近的內存區域,在較短的時間間隔內也可能會被多次訪問。
當CPU去訪問指令和數據時,首先去訪問L1 Cache,如果命中,則會直接從對應的緩存中取數據,而不必每次去訪問主存,如果沒命中,會再去L2 Cache中找,依次類推,如果L3 Cache中不存在,就去內存中找。
四、L1緩存是不是越大越好?
L1增大,會提高L1的命中率,但L1緩存是不是越大越好?
4.1?增大L1對訪問延遲的影響
一個實際的例子: 從Intel Sunny Cove (Core第10代) 開始L1 cache從32K (指令) +32K(數據) 的組合變成了32K (指令) +48K (數據) 的組合。這樣的后果就是L1 cache的訪問性能下降,從4個cycle變成5個cycle。增大L1會提高命中率,同時延遲也增加了。那么這一升一降對平均訪問時間(AMAT)有什么影響呢?
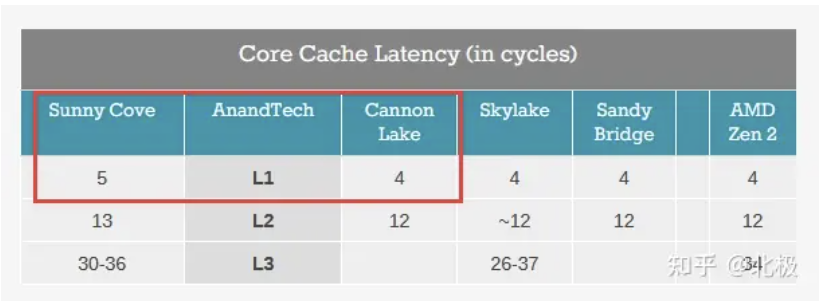
下面用一個簡單的例子來說明一下L1訪問時間對AMAT的影響。假設我們有三層的memory hierarchy (L1, L2, offchip RAM) ,其中L2訪問時間為10 cycle,off-chip RAM訪問時間為200 cycle。假設32KB L1-D的情況下L1,L2的hit rate大致為90%,9%,增加至48KB L1-D的Sunny Cove L1,L2 hit rate提升為95%,4%,那么對應的
Sunny Cove平均訪問時間約為?
0.95*5+0.04*10+0.01*200=7.15 cycle.
Sunny Cove之前的microarchitecture的平均訪問時間約為
0.90*4+0.09*10+0.01*200=6.5 cycle.
簡單的模型估算可以看出,即便增大L1 size可以提升L1 hit rate,然而L1訪問延時的增加,還是會使得平均內存訪問延時增加了~10%。這也是為什么L1 cache size長時間來沒有太大改動的原因。
綜上,L1大小將直接影響訪問時間,而訪問L1的時間又會直接影響到平均內存訪問時間(average memory access time - AMAT),對整個CPU的性能產生巨大影響。
4.2 限制L1訪問延時的原因是什么?
在系統啟動過程中,僅在很早期啟動階段CPU處于實模式,開啟paging之后,CPU接收的load/store指令對應的地址均為虛擬地址,在訪問L1 cache的時候還需要經過虛擬地址VA到物理地址PA的轉換。現代CPU通常采用virtual index physical tag的L1結構?。這種L1結構的一大好處就是可以在index cache set的時候同時訪問TLB (相當于隱藏了部分L1訪問延時),一個x64下的L1訪問示意圖如下所示。
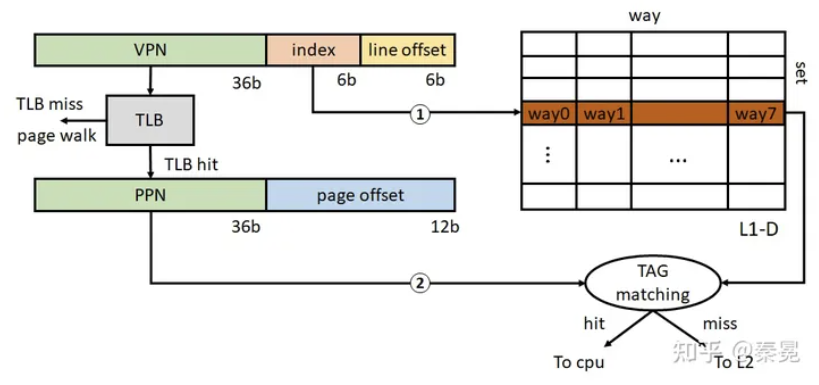
TLB:Translation lookaside buffer,即旁路轉換緩沖,或稱為頁表緩沖
對于4KB大小的page,共有12bit page offset,其中低6bit為cacheline offset (64B cachelinesize),剩余6bit作為L1 index bits,這也就意味著L1只能限制于64個cache set。對于32KB L1-D,也就意味著其每個set對應8 way (32KB/64/64 = 8) 。Sunny Cove的48KB L1-D對應每個set12 way。由上圖可以看出,L1訪問延時的關鍵路徑為TLB訪問以及TLB hit之后對相應L1 cache set的TAG matching,由于cache set是簡單的lookup,我們可以認為在TLB查詢結束得到PPN的時候立即可以進行TAG matching。(TLB也是一個小的set-associatative cache,也需要進行TAG matching。因此訪問時間要長于L1 set lookup)。因此,TLB的查詢時間和L1的associativity (即圖中的TAG matching)決定了L1的訪問延時。
為了保證L1訪問延時可以做的足夠低,通常需要設計L1的associativity盡量小。因此在Sunny Cove之前通常為8 way。這里Sunny Cove增加了一個cycle的L1訪問延時,不確定是由TLB的改動引起的還是L1 associativity由8 way增加到12 way。但是總的來說,我們可以看出L1為什么不能設計得很大,主要是由于virtual index physical tag的結構引起的。
另一方面,L1 cache 32kb 是算好能覆蓋整個4KB頁的,從第一代core到現在十代都是這么設計的。每個set有8個way,也就是說可以同時緩存8頁,加大容量一方面提高延遲的同時可能會導致很大一部分way在很多時候是閑置浪費性能。
總的來說,增加cache line的大小,但是相應的cache miss的延遲會大大增加,尤其是考慮到L1會緩存虛擬地址,一旦miss意味著penalty會增加更多。另外如果增加wayness或者sets,會造成尋址延遲增高,也是得不償失。
另外,L1 cache的替換以及prefetch策略都是很復雜的,這些也會導致延遲的提高對性能的影響會大于容量的提高。
4.3 蘋果M1的L1為什么會比X-86的L1大?
為什么蘋果的M1可以做到192KB的L1-I(128KB L1-D),同時保證3 cycle的訪問延時呢?
首先一點蘋果的最高主頻相對Intel/AMD的desktop/server line的CPU要低一些,因此在時序上約束相對放松一些(主要是tag matching的comparator路徑的關鍵路徑)。其次一點,也是最關鍵的M1對應的MacOS采用的是16KB page而非x86的4KB page。
由上圖可知如果擴大page size(16KB對應14bit),相當于增加了2bit的index bits,這樣的話L1 cache set數目可以增加4倍(在保持associativity的前提下),因此M1的L1-I正好是Sunny Cove的4倍(192KB/48KB = 4)。M1的L1-D大小是128KB(4倍于32KB)。
對于問題中的L1 cache來講,其實更多的是系統層面的取舍(page size增加也會導致內存浪費,內存碎片等問題,但是同時也會減輕頁表的壓力,增加TLB coverage)。不過也僅限于蘋果,其M1的產品只是MacBook一個設備,可以做更多的定制,對于x86來講,歷史包袱和眾多設備兼容性的問題,使其很難做到像蘋果這種更加靈活的架構設計。
審核編輯:黃飛
?













 工商網監
工商網監
評論