") 一種簡單高效的pipeline方法,在多個基準上獲得了新的SOTA結(jié)果
一種簡單高效的pipeline方法,在多個基準上獲得了新的SOTA結(jié)果
端到端關(guān)系抽取涉及兩個子任務(wù):命名實體識別和關(guān)系抽取。近期研究多采用 joint 方式建模兩個子任務(wù),而陳丹琦等人新研究提出一種簡單高效的 pipeline 方法,在多個基準上獲得了新的 SOTA 結(jié)果。
端到端關(guān)系抽取旨在識別命名實體,同時抽取其關(guān)系。近期研究大多采取 joint 方式建模這兩項子任務(wù),要么將二者統(tǒng)一在一個結(jié)構(gòu)化預(yù)測網(wǎng)絡(luò)中,要么通過共享表示進行多任務(wù)學(xué)習(xí)。 而近期來自普林斯頓大學(xué)的 Zexuan Zhong、陳丹琦介紹了一種非常簡單的方法,并在標準基準(ACE04、ACE05 和 SciERC)上取得了新的 SOTA 成績。該方法基于兩個獨立的預(yù)訓(xùn)練編碼器構(gòu)建而成,只使用實體模型為關(guān)系模型提供輸入特征。通過一系列精心檢驗,該研究驗證了學(xué)習(xí)不同的語境表示對實體和關(guān)系的重要性,即在關(guān)系模型的輸入層融合實體信息,并集成全局語境信息。 此外,該研究還提出了這一方法的高效近似方法,只需要在推斷時對兩個編碼器各執(zhí)行一次,即可獲得 8-16 倍的加速,同時準確率僅小幅下降。
論文鏈接:https://arxiv.org/pdf/2010.12812.pdf pipeline 方法重回巔峰? 從非結(jié)構(gòu)化文本中抽取實體及其關(guān)系是信息抽取中的基本問題。這個問題可以分解為兩個子任務(wù):命名實體識別和關(guān)系抽取。 早期研究采用 pipeline 方法:訓(xùn)練一個模型來抽取實體,另一個模型對實體之間的關(guān)系進行分類。而近期,端到端關(guān)系抽取任務(wù)已經(jīng)成為聯(lián)合建模子任務(wù)系統(tǒng)的天下。大家普遍認為,這種 joint 模型可以更好地捕獲實體與關(guān)系之間的交互,并有助于緩解誤差傳播問題。 然而,這一局面似乎被一項新研究打破。近期,普林斯頓大學(xué) Zexuan Zhong 和陳丹琦提出了一種非常簡單的方法,該方法可以學(xué)習(xí)基于深度預(yù)訓(xùn)練語言模型構(gòu)建的兩個編碼器,這兩個模型分別被稱為實體模型和關(guān)系模型。它們是獨立訓(xùn)練的,并且關(guān)系模型僅依賴實體模型作為輸入特征。實體模型基于 span-level 表示而構(gòu)建,關(guān)系模型則建立在給定 span 對的特定語境表示之上。 雖然簡單,但這一 pipeline 模型非常有效:在 3 個標準基準(ACE04、ACE05、SciERC)上,使用相同的預(yù)訓(xùn)練編碼器,該模型優(yōu)于此前所有的 joint 模型。 為什么 pipeline 模型能實現(xiàn)如此優(yōu)秀的性能呢?研究者進行了一系列分析,發(fā)現(xiàn):
實體模型和關(guān)系模型的語境表示本質(zhì)上捕獲了不同的信息,因此共享其表示會損害性能;
在關(guān)系模型的輸入層融合實體信息(邊界和類型)至關(guān)重要;
在兩個子任務(wù)中利用跨句(cross-sentence)信息是有效的;
更強大的預(yù)訓(xùn)練語言模型能夠帶來更多的性能收益。
研究人員希望,這一模型能夠引發(fā)人們重新思考聯(lián)合訓(xùn)練在端到端關(guān)系抽取中的價值。 不過,該方法存在一個缺陷:需要為每個實體對運行一次關(guān)系模型。為了緩解該問題,研究者提出一種新的有效替代方法,在推斷時近似和批量處理不同組實體對的計算。該近似方法可以實現(xiàn) 8-16 倍的加速,而準確率的下降卻很小(例如在 ACE05 上 F1 分數(shù)下降了 0.5-0.9%)。這使得該模型可以在實踐中快速準確地應(yīng)用。 研究貢獻 該研究的主要貢獻有:
提出了一種非常簡單有效的端到端關(guān)系抽取方法,該方法學(xué)習(xí)兩個獨立編碼器,分別用于實體識別和關(guān)系抽取的。該模型在三個標準基準上達到了新 SOTA,并在使用相同的預(yù)訓(xùn)練模型的時,性能超越了此前所有 joint 模型。
該研究經(jīng)過分析得出結(jié)論:對于實體和關(guān)系而言,相比于聯(lián)合學(xué)習(xí),學(xué)習(xí)不同的語境表示更加有效。
為了加快模型推斷速度,該研究提出了一種新穎而有效的近似方法,該方法可實現(xiàn) 8-16 倍的推斷加速,而準確率只有很小的降低。
方法 該研究提出的模型包括一個實體模型和一個關(guān)系模型。如下圖所示,首先將輸入句子饋入實體模型,該模型為每一個 span 預(yù)測實體類型;然后通過嵌入額外的 marker token 在關(guān)系模型中獨立處理每對候選實體,以突出顯示主語、賓語及其類型。
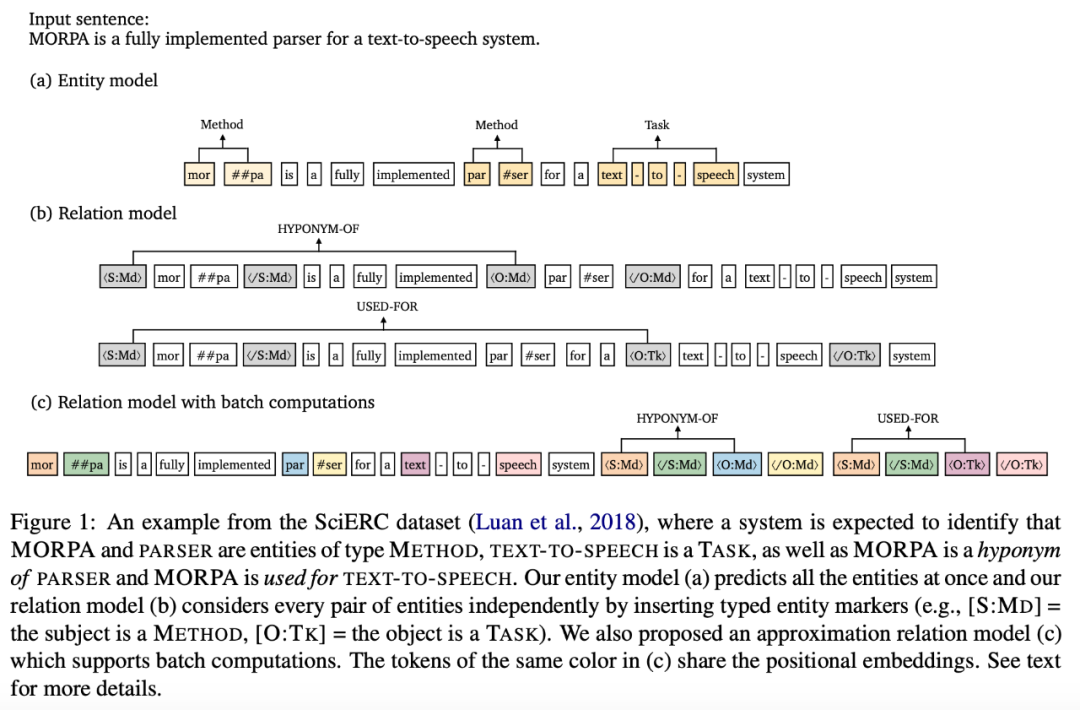
此外,研究者還介紹了該方法與 DYGIE++ 的區(qū)別(DYGIE++ 與該方法很接近,并且是最強的基線方法)。 1. 該研究提出的方法對實體模型和關(guān)系模型使用不同的編碼器,未使用多任務(wù)學(xué)習(xí);預(yù)測得到的實體標簽直接作為關(guān)系模型的輸入特征。 2. 關(guān)系模型中的語境表示特定于每個 span 對。 3. 該方法用額外的語境擴展輸入,從而納入跨句信息。 4. 該方法未使用束搜索或圖傳播層,因此,該模型要簡單得多。 有效的近似方法 該研究提出的方法較為簡潔有效,但是它的缺點是需要對每一個實體對運行一次關(guān)系模型。為此,研究者提出一種新型高效的替代性關(guān)系模型。核心問題在于,如何對同一個句子中的不同 span 對重用計算,在該研究提出的原始模型中這是不可能實現(xiàn)的,因為必須為每個 span 對分別嵌入特定的實體標記。因此,研究者提出了一種近似模型,該模型對原始模型做了兩個重要更改。 首先,該近似方法沒有選擇直接將實體標記嵌入原始句子,而是將標記的位置嵌入與對應(yīng) span 的開始和結(jié)束 token 聯(lián)系起來:
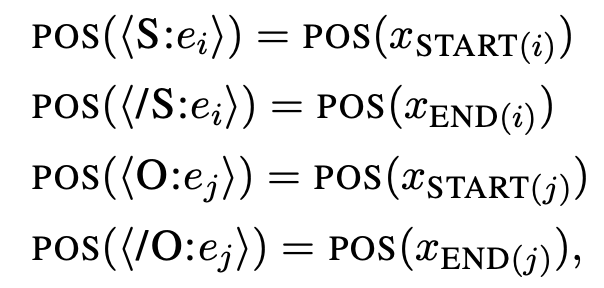
其次,近似方法為注意力層添加了約束:使文本 token 只注意文本 token 不注意標記 token,實體標記 token 則可以注意所有文本 token,4 個標記 token 全部與同一個 span 對關(guān)聯(lián)。 這兩項更改允許模型對所有文本 token 重用計算,因為文本 token 獨立于實體標記 token。因而,該方法可以在運行一次關(guān)系模型時批量處理來自同一個句子的多個 span 對。 實驗 研究人員在三個端到端關(guān)系抽取數(shù)據(jù)集 ACE04、ACE054 和 SciERC 上進行方法評估,使用 F1 分數(shù)作為評估度量指標。 下表 2 展示了不同方法的對比結(jié)果:
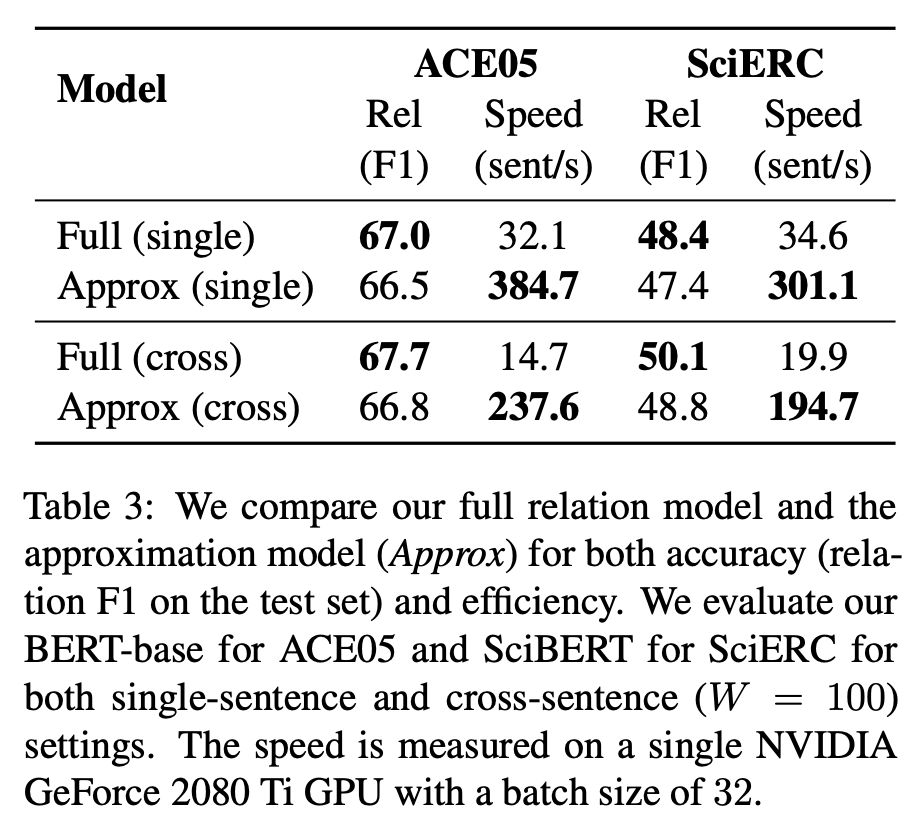
從圖中可以看出,該研究提出的 single-sentence 模型實現(xiàn)了強大的性能,而納入跨句語境后,性能結(jié)果得到了一致提升。該研究使用的 BERT-base(或 SciBERT)模型獲得了與之前工作類似或更好的結(jié)果,包括那些基于更大型預(yù)訓(xùn)練語言模型構(gòu)建的模型,使用較大編碼器 ALBERT 后性能得到進一步提升。 近似方法的性能 下表展示了完全關(guān)系模型和近似模型的 F1 分數(shù)與推斷速度。在兩個數(shù)據(jù)集上,近似模型的推斷速度顯著提升。
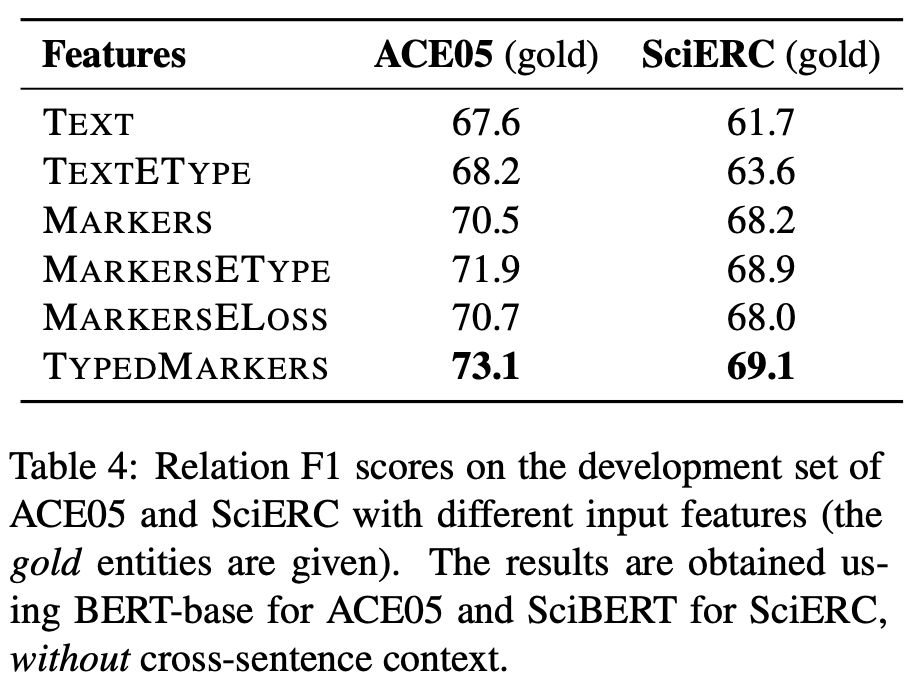
這個 pipeline 模型為什么超過了 joint 模型? 除了展示方法和性能以外,該研究還深入分析了這一 pipeline 模型取得如此優(yōu)秀性能的原因。 鍵入文本標記(typed text marker)的重要性 該研究認為,為不同 span 對構(gòu)建不同語境表示非常重要,早期融合實體類型信息可以進一步提升性能。 為了驗證鍵入文本標記的作用,研究者使用其不同變體在 ACE05 和 SciERC 數(shù)據(jù)集上進行實驗,包括 TEXT、TEXTETYPE、MARKERS、MARKERSETYPE、MARKERSELOSS、TYPEDMARKERS 六種。 下表 4 展示了這些變體的性能,從中可以看出不同的輸入表示確實對關(guān)系抽取的準確率產(chǎn)生影響。
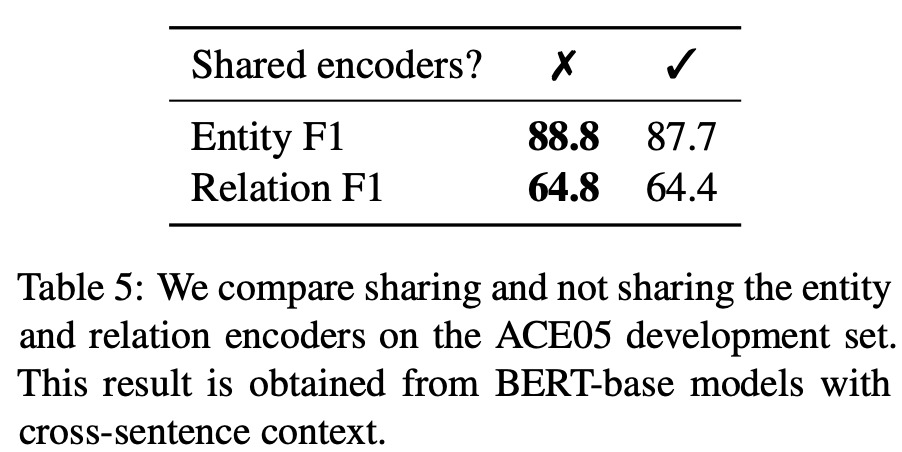
實體和關(guān)系如何交互 人們對 joint 模型的主要認知是,對兩個子任務(wù)之間交互的建模對彼此有所幫助。但這項研究并未采取這種方式,而是使用了兩個獨立的編碼器。 研究人員首先研究了共享兩個表示編碼器能否提升性能。如下表 5 所示,簡單地共享編碼器對實體 F1 和關(guān)系 F1 分數(shù)均有所損害。研究人員認為,其原因在于兩個任務(wù)具備不同的輸入格式,需要不同的特征來預(yù)測實體類型和關(guān)系,因此使用單獨的編碼器可以學(xué)得更好的任務(wù)特定特征。
該研究的分析結(jié)果顯示: 實體信息有助于預(yù)測關(guān)系,但實驗未表明關(guān)系信息可以大幅提升實體性能。 僅共享編碼器對該研究提出的方法無益。 如何緩解 pipeline 方式中的誤差傳播問題 pipeline 訓(xùn)練的一個主要缺陷是誤差傳播問題。使用 gold 實體(及其類型)進行關(guān)系模型訓(xùn)練,使用預(yù)測實體進行推斷,可能會導(dǎo)致訓(xùn)練和測試之間存在差異。 為此,研究人員首先探究在訓(xùn)練階段使用預(yù)測實體(而非 gold 實體)能否緩解這一問題。該研究采用 10-way jackknifing 方法,結(jié)果發(fā)現(xiàn)這一策略竟然降低了最終的關(guān)系性能。研究人員假設(shè)其原因在于訓(xùn)練階段引入了額外的噪聲。 在目前的 pipeline 方法中,如果在推斷階段 gold 實體沒有被實體模型識別出來,則關(guān)系模型無法預(yù)測與該實體相關(guān)的任何關(guān)系。于是,研究人員考慮在訓(xùn)練和測試階段,對關(guān)系模型使用更多 span 對。實驗結(jié)果表明,這無法帶來性能提升。 這些常識未能顯著提升性能,而該研究提出的簡單 pipeline 方法卻驚人的有效。研究者認為誤差傳播問題并非不存在或無法被解決,我們需要探索更好的解決方案。
責(zé)任編輯:lq
-
編碼器
+關(guān)注
關(guān)注
45文章
3663瀏覽量
135021 -
模型
+關(guān)注
關(guān)注
1文章
3294瀏覽量
49035 -
Pipeline
+關(guān)注
關(guān)注
0文章
28瀏覽量
9379
原文標題:陳丹琦新作:關(guān)系抽取新SOTA,用pipeline方式挫敗joint模型
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Mamba入局圖像復(fù)原,達成新SOTA
一種使用LDO簡單電源電路解決方案
AMD獲得一項玻璃基板技術(shù)專利
一種提升無人機小物體跟蹤精度的方法

一種創(chuàng)新的動態(tài)軌跡預(yù)測方法
一種簡單高效配置FPGA的方法
關(guān)于\"OPA615\"的SOTA的跨導(dǎo)大小的疑問求解
想了解一下場效應(yīng)管和電壓基準芯片是同一種元器件嗎
基于助聽器開發(fā)的一種高效的語音增強神經(jīng)網(wǎng)絡(luò)
NB81是否支持OneNet SOTA功能?應(yīng)該如何激活SOTA?
旋變位置不變的情況下,當(dāng)使能SOTA功能與關(guān)閉SOTA功能時,APP中DSADC采樣得到的旋變sin和cos兩者值不一樣,為什么?
一種利用光電容積描記(PPG)信號和深度學(xué)習(xí)模型對高血壓分類的新方法
什么是pipeline?Go中構(gòu)建流數(shù)據(jù)pipeline的技術(shù)
這屆CES展會上獲得了創(chuàng)新獎的工業(yè)AR產(chǎn)品長什么樣?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論