 一篇BERT用于推薦系統的文章
一篇BERT用于推薦系統的文章
今天給大家介紹一篇BERT用于推薦系統的文章,題目是《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》,文章作者都是出自阿里。
引用:Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1441-1450.
論文下載地址:https://arxiv.org/pdf/1904.06690.pdf
本文概覽:
1. BERT4Rec簡介
根據用戶歷史的行為,對用戶動態的偏好進行建模,對于推薦系統來說是有挑戰的和重要的。之前的算法使用序列神經網絡從左向右地編碼用戶的歷史交互信息為隱含表示,進而進行推薦,因此只利用了單向的信息進行建模。盡管它們是有效的,但由于存在以下限制,我們認為這種從左到右的單向模型是次優的:
單向結構限制了用戶行為序列中隱藏表示的能力;
之前的序列神經網絡經常采用嚴格有序的序列,這并不總是可行的;
為了解決這些限制,我們提出了一個稱為BERT4Rec的序列推薦模型,該模型采用深層的雙向自注意力來對用戶行為序列進行建模。為了避免信息泄漏并有效地訓練雙向模型,我們采用Cloze目標進行序列推薦,通過聯合item左右的上下文來預測序列中隨機masked item。用這種方式,我們學習了雙向表示模型,允許用戶歷史行為中的每個item融合左右兩側的信息來作出推薦。在四個基準數據集上進行的大量實驗表明,我們的模型始終優于各種最新的序列模型。
2. 背景
精確地捕捉用戶的興趣,是推薦系統的核心問題。在許多實際應用中,用戶當前的興趣本質上是動態變化的,受其歷史行為的影響。例如,盡管在正常情況下不會購買游戲機配件,但在購買Nintendo Switch之后,你可能會很快購買配件(例如Joy-Con控制器)。
為了捕捉用戶的偏好的動態變化,提出了許多根據用戶歷史交互信息的序列推薦算法,最早使用馬爾科夫對用戶序列進行建模,其中一些方法的強假設破壞了推薦系統的準確性。近期,一些序列神經網絡在序列推薦問題中取得了不俗的效果。最基本的思想就是將用戶的歷史序列自左向右編碼成一個向量,然后基于這個向量進行推薦。
盡管它們具有普遍性和有效性,但我們認為這樣從左到右的單向模型不足以學習用戶行為序列的最佳表示。主要因為這種單向模型限制了歷史序列中items的隱藏表示的功能,其中每個item只能編碼來自先前item的信息。另一個限制是,先前的單向模型最初是針對具有自然順序的序列數據(例如,文本和時間序列數據)引入的。他們經常對數據采用嚴格的順序排列,這對于現實應用程序中的用戶行為并不總是正確的。實際上,由于各種不可觀察的外部因素,用戶的歷史交互中的item選擇可能不會遵循嚴格的順序假設。在這種情況下,至關重要的是將兩個方向的上下文合并到用戶行為序列建模中。
為了解決上述限制,本篇文章的創新點:
提出了一種基于雙向self-attention和Cloze task的用戶行為序列建模方法。據我們所知,這是第一個將深度序列模型和Cloze task引入推薦系統的研究。
將我們的模型與最先進的方法進行了比較,并通過對四個基準數據集的定量分析,證明了本文算法的有效性。
我們進行了一項消融分析,分析了模型中關鍵部件的貢獻。
3. BERT4Rec模型介紹
3.1 問題定義
定義, 為用戶集合, 為物品集合,為用戶歷史行為序列。我們的目標是預測下一時刻用戶與每個候選物品交互的概率:
3.2 模型結構
如下圖(b)所示,含有L層的Transformer,每一層利用前一層所有的信息。相比于圖(d)基于RNN的推薦模型,self-attention可以捕獲任意位置的信息。相比于基于CNN的推薦模型,可以捕獲整個field的信息。相比于圖(c)和圖(d)的模型(都是left-to-right的單向模型),本文提出的雙向模型可以解決現有模型的問題。
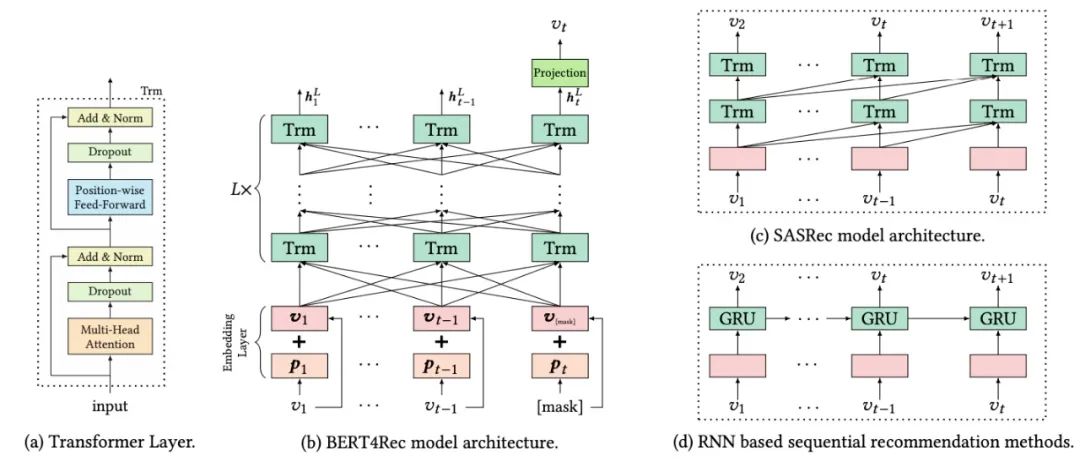
3.3 Transformer層
如圖(a)所示,Transformer由兩部分組成Multi-Head Self-Attention和Position-wise Feed-Forward network部分。
(1)Multi-Head Self-Attention
對于模型框架中的第 層Transformer,輸入為 ,首先是Multi-Head Self-Attention過程:
其次是Dropout和Add & Norm過程,這里的Add就是Skip Connection操作,目的是反向傳播時防止梯度消失的問題;而Norm是Layer Norm操作。
(2)Position-wise Feed-Forward Network
由于只有線性映射,為了使得模型具有非線性的性質,所以采用了Position-wise Feed-Forward Network。Position-wise的意思是說,每個位置上的向量分別輸入到前向神經網絡中,計算方式如下:
這里采用的激活函數是 Gaussian Error Linear Unit (GELU) ,而非RELU,其出自論文《Gaussian error linear units (gelus)》。GELU在RELU的基礎上加入了統計的特性,在論文中提到的多個深度學習任務中都取得了較好的實驗結果。
如果讀者對Transformer或BERT的原理不熟悉,可以看一下我之前對于這些模型的詳細解析:
Self-Attention與Transformer
從Transformer到BERT模型
BERT模型精講
3.4 Embedding層
在沒有任何RNN或CNN模塊的情況下,Transformer不知道輸入序列的順序。為了利用輸入的順序信息,我們在Transformer的Embedding層加入了位置嵌入,本文的位置向量是學到的,不是transformer中的正弦。位置向量矩陣可以給定任意位置的向量,但是要明確最大的長度,因此需要對輸入序列進行截斷。
對于給定的物品 ,其輸入表示 是通過將相應的物品和位置Embedding求和來構造的:
3.5 Output層
經過層的信息交換之后,我們得到輸入序列中所有items的最終輸出。如上圖(b)所示,我們在第 步掩蓋掉物品 ,然后基于 預測被掩蓋的物品 。這里使用兩層帶有GELU激活函數的前饋網絡得到最終的輸出:
這里需要注意,輸出層的公式是推薦場景特有的,因此我來詳細解釋一下。是前饋網絡的權重矩陣; 和 是偏置項; 是item集合的embedding矩陣。BERT4Rec模型在輸入層和輸出層用了共享的物品embedding矩陣,目的是減輕過擬合和減少模型大小。
3.6 模型訓練和預測
我們的目的是預測用戶下一個要交互的物品 ,對于傳統的序列推薦模型,如上圖(d)中的RNN模型,輸入是 ,轉換為對應的輸出為 ,那么我們自然可以拿最后一個時刻輸出的物品進行推薦。而在BERT4Rec中,由于是雙向模型,每一個item的最終輸出表示都包含了要預測物品的信息,這樣就造成了一定程度的信息泄漏。因此采用Cloze taske,也就是將輸入序列中的p%的物品進行masked,然后根據上下文信息預測masked的物品。
在訓練階段,為了提升模型的泛化能力,讓模型訓練到更多的東西,同時也能夠創造更多的樣本,借鑒了BERT中的Masked Language Model的訓練方式,隨機的把輸入序列的一部分掩蓋(即變為[mask]標記),讓模型來預測這部分蓋住地方對應的物品:

采用這種訓練方式,最終的損失函數為:
如上所述,我們在訓練過程和最終的序列預測推薦任務之間是不匹配的。因為Cloze task的目的是預測當前被masked的物品,而序列預測推薦的目的是預測未來。為了解決這個問題,在預測階段我們將masked附加到用戶行為序列的末尾,然后根據該masked的最終隱藏表示來預測下一項。
為了更好地匹配序列推薦任務(即,預測最后一項),在訓練過程中我們還生成了只mask輸入序列中最后一項的樣本。這個工作就像對序列推薦的微調一樣,可以進一步提高推薦性能。
4. 實驗
本論文的代碼已開源,地址:https://github.com/FeiSun/BERT4Rec 。讀者一定要親自把論文讀一遍,復現一下論文中的實驗。我把實驗部分總結如下:
首先,論文對比了BERT4Rec模型和一些Base模型在4個數據集上的表現,發現BERT4Rec模型相比于Base模型,其性能都有較大的提升。
其次,是對Embedding的長度、訓練時mask物品的比例和序列的最大長度等參數的對比。結論為:Embedding長度越長,模型的效果更好;對于不同的數據集,最佳mask的比例并不相同;對于不同的訓練集,最佳的序列長度也不相同。
最后,是對模型結構的一些對比實驗,主要有是否使用PE(positional embedding),是否使用PFFN(position-wise feed-forward network),是否使用LN(layer normalization),是否使用RC(即Add操作,residual connection),是否使用Dropout,以及Transformer Layer的層數和Multi-head Attention中head的個數。
5. 個人感悟
總之,BERT4Rec就是把BERT用在推薦系統中,知道用戶的播放(購買、點擊、...)序列 item1, item2, item3,預測下一個播放的item問題。訓練的時候使用Mask LM任務使用海量用戶行為序列進行訓練,模型評估時將序列的最后一個item進行masked,預測的時候在序列的最后插入一個“[mask]”,然后用“[mask]”增強后的embedding預測用戶接下來會觀看哪個item。整體來說,該篇論文為BERT在推薦系統領域的工業界落地提供了強有力的指導說明,但在推薦系統領域的學術界來說創新性就顯得不是很大。
BERT4Rec對于實際工作,可以成為一個思路上的參考,對于具體的算法落地我提出兩點思考:
BERT的訓練和預測耗時耗資源,如何提高BERT的在線服務能力?這里騰訊開源了一個叫TurboTransformers的工具,對Transformer推理過程起到了加速作用,讓線上推理引擎變得更加強大。開源地址:https://github.com/Tencent/TurboTransformers
論文中沒有使用物品、用戶屬性和場景的信息,只使用了行為信息,如何把額外的信息加入模型是值得重點探索的。
6. Reference
【1】Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1441-1450.
【2】Hendrycks D, Gimpel K. Gaussian error linear units (gelus)[J]. arXiv preprint arXiv:1606.08415, 2016.
【3】RS Meet DL(六十一)-[阿里]使用Bert來進行序列推薦,https://mp.weixin.qq.com/s/y23s_Y8Der12NMVw9y2NEA
【4】BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer,https://blog.csdn.net/luoxiaolin_love/article/details/93192601
【5】BERT4REC:使用Bert進行推薦 - 魏晉的文章 - 知乎 https://zhuanlan.zhihu.com/p/97123417
【6】BERT在美團搜索核心排序的探索和實踐,https://mp.weixin.qq.com/s/mFRhp9pJRa9yHwqc98FMbg
【7】微信也在用的Transformer加速推理工具 | 騰訊第100個對外開源項目,地址:https://mp.weixin.qq.com/s/3QBTccXceUhK47TlMcCllg
責任編輯:xj
原文標題:【推薦系統】BERT4Rec:使用Bert進行序列推薦
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
-
序列
+關注
關注
0文章
70瀏覽量
19584 -
推薦系統
+關注
關注
1文章
43瀏覽量
10088 -
自然語言
+關注
關注
1文章
290瀏覽量
13382
原文標題:【推薦系統】BERT4Rec:使用Bert進行序列推薦
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
迅為RK3568開發板篇OpenHarmony實操HDF驅動控制LED-編寫內核 LED HDF 驅動程序
一篇文章說清電子連接器

【「嵌入式系統設計與實現」閱讀體驗】+ 學習一個STM32的案例
請問ADS1299適用于腦電系統嗎?
迅為iTOP-RK3568開發板驅動開發指南-第十八篇 PWM
內置誤碼率測試儀(BERT)和采樣示波器一體化測試儀器安立MP2110A

如何設計出一套用于移動式綜合監測站管理的軟件系統
M8020A J-BERT 高性能比特誤碼率測試儀
AWG和BERT常見問題解答
【《大語言模型應用指南》閱讀體驗】+ 基礎篇

一篇搞定DCS系統相關知識點
構建系統思維:信號完整性,看這一篇就夠了!





 工商網監
工商網監
評論