 一個集檢測與檢索與一身的作品
一個集檢測與檢索與一身的作品
傳統的目標檢索任務旨在學習具有內部相似度和內部相異度的區分特征表示,它假設圖像中的對象是手動或自動精確裁剪的。但是,在許多現實世界中的搜索場景(例如,視頻監視)中,很少準確地檢測或標注對象(例如,人、車輛等)。因此,在沒有邊界框注釋的情況下,物體級檢索變得很棘手,這導致了一個新的但具有挑戰性的主題,即圖像搜索。
1、簡介
行人搜索是圖像搜索問題的第一個嘗試。在此之前,雖然對人的檢測和重識別做了大量的努力,但大多數都是獨立處理這兩個問題的。也就是說,傳統方法將行人搜索任務劃分為兩個獨立的子任務。
首先,利用行人檢測器從圖像中預測人物的邊界盒,然后根據預測的邊界盒的坐標對被檢測人物的矩形區域進行裁剪。其次,提取檢測框內行人的特征用于重新識別人物。
在一般的行人重識別(Re-ID)任務中,對行人圖像進行人工注釋和裁剪,然后用于訓練的鑒別特征表示網絡。一方面是因為在真實的視頻監控任務中,大多數檢測器不可避免地會出現誤檢和框選不準的情況,在一定程度上可能會導致ReID精度的性能顯著下降。另一方面,這兩個獨立的子任務似乎對實際應用程序中的最終Re-ID不太友好。

圖1 傳統ReID+檢索的過程和本文所提方法的對比圖
在本文中,為了解決圖像搜索問題,我們首先介紹一個端到端集成網(I-Net),它具有三個優點:
1)通過設計Siamese架構來進行在線匹配相似和不相似樣本對。
2)引入了新穎的在線配對(OLP)損失和動態特征字典,該字典通過自動生成多個負數對來限制正數,從而減輕了多任務訓練停滯問題。
3)提出了一種Hard example priority(HEP)的softmax損失,以通過選擇Hard類別來提高分類任務的魯棒性。
借助分而治之的理念,文章進一步提出了一種改進的I-Net,稱為DC-I-Net,它做出了兩個新的貢獻:
1)量身定制了兩個模塊以在集成框架中分別處理不同的任務,從而使任務規格得到保證。
2)提出了通過利用memory的類中心進行類中心指導的HEP Loss(),從而可以捕獲內部相似度和內部相似度以進行最終檢索。
在著名的面向圖像級搜索的基準數據集上的大量實驗表明,所提出的DC-I-Net優于最新的tasks-integrated和tasks-separated的圖像搜索模型。
2、本文方法
這篇論文是I-Net的一個實質性擴展,在網絡架構和損失函數方面做出了以下新貢獻:
2.1、I-Net
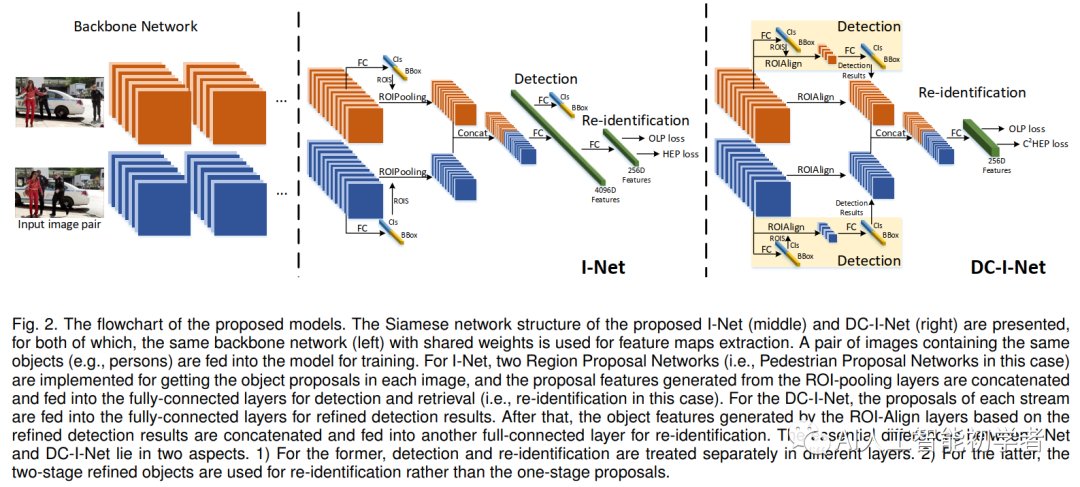
為了實現更好的圖像搜索任務,I-Net(Siamese I-Net)將行人檢測和行人重識別設計為端到端(End-to-End)的框架,如下圖:
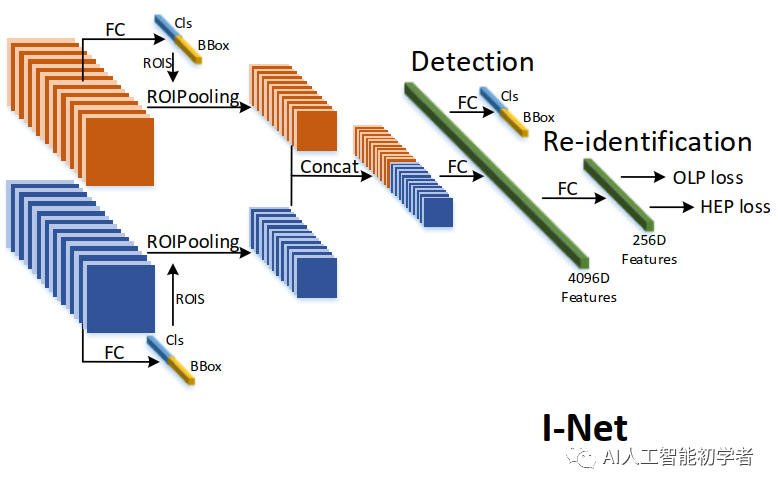
對于每一次迭代,包含相同身份id的圖像對將被輸入到Siamese I-Net中。利用骨干網絡進行初步特征的提取。然后,通過兩個RPN結構得到候選區域。再然后將這些候選區域特征輸入到ROIPooling中并輸出的特征圖,最后是兩個全連接層分別用于檢測任務和檢索檢索(即ReID)任務。同時該結構的提出的同時也提出了兩個損失函數,即OLP Loss和HEPLoss,用于學習與ReID相關的有效特征。
通過兩個RPN生成的候選區域,ROI池化層被集成到I-Net中。然后,兩個Stream匯集的特征被輸入到有4096個神經元的兩個FC中。為了消除行人候選區域的假陽性使用二值交叉熵損失區分訓練。(注意,對于一般的圖像搜索任務都會使用softmax分類器來進行目標檢測);除此之外L1損失用來約束候選框的位置,同時會有一對256-D的特征用通過OLP Loss和HEP Loss來訓練ReID Branch的模型。
2.2、On-line Pairing Loss (OLP Loss)
設計OLP損失函數主要從以下幾個角度考慮的:
1 減小類內差距、增加類間差距
2 由于輸入的圖像數量不足,且每幅圖像中目標的鎖定,容易出現容易對多而身份少的情況,會導致傳統度量損失(如Triplet Loss)的停滯問題,嚴重阻礙了模型的有效訓練。
OLP Loss的設計形式如下:
OLP損失可以按照如下步驟進行復現:
1.收集兩幅相同身份輸入圖像的特性,并構造成正樣本對。
2.為每個正樣本對特征中的和被設置為Anchor。負樣本特征存儲在特征字典中,與Anchor對配對,構建負樣本對。
3.計算OLP損失,然后計算OLP梯度,進行梯度反向傳播優化。
4.存儲輸入的特征,逐步更新特征字典。
2.3、Hard Example Priority Loss (HEP Loss)
OLP損失函數使正樣本對的余弦距離更小,負樣本對的余弦距離更大,這并不能直接對損失函數中的id標簽進行回歸。另外,傳統的基于softmax的分類器交叉損失訓練方法沒有考慮樣本在數據中的難易程度。基于上述考慮,提出了HEP Loss,目的是回歸具有高優先級的身份標簽。
在圖4中,Hard Example的選擇如下:
首先確定每個有身份的輸入圖像對的標簽索引,以確保groundtruth類。
對于每個子組,將距離最大的最上面r個負樣本的標簽索引存儲在優先級類池P中,使難例的優先級類得到集中。
如果池P的大小仍然小于預設的T,便隨機選擇幾個類填充池。
最后,利用傳統的基于softmax的交叉熵損失和選擇的優先級類,將提出的HEP損失函數表示為:
其中,表示分類器給出的第i個proposal的分數,j表示第j個類。在損失函數中,只使用選定的類別進行損失計算,進而使得損失函數集中在硬類別上。
2.4、Overall Loss of I-Net
I-Net是一種將檢測和重識別結合起來進行訓練的端到端模型。因此損失由兩部分組成:檢測損失()和重識別損失(和),表示如下:
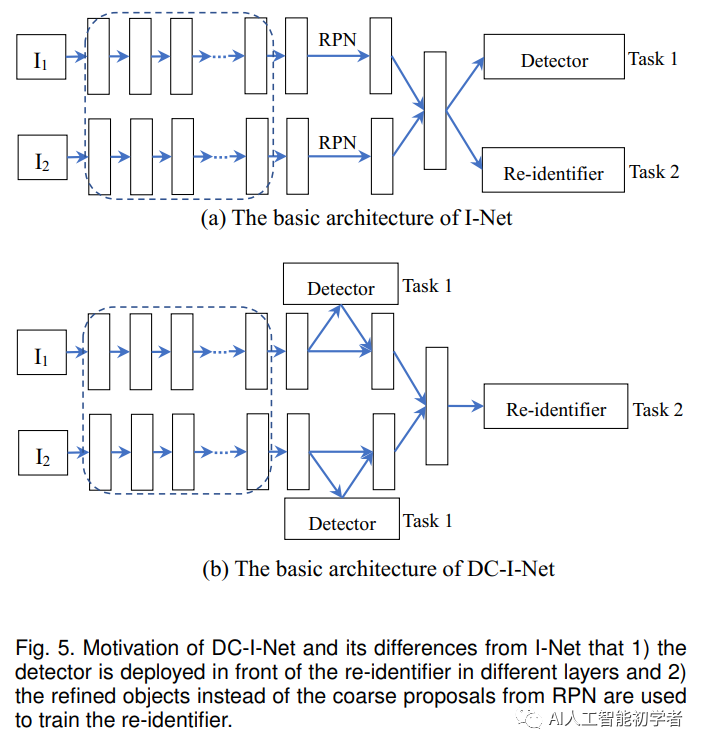
2.5、DC-I-NET
相較于I-Net,DC-I-NET:
1.通過使用來自不同層的特征,很好地考慮了檢測和重新識別的任務專注度;
2.利用ROI-Align模塊生成2級檢測器來提取refined目標以用于訓練度量損失;
3.提出了class-center引導困難樣本優先的()損失,用于訓練的id的分類損失。
Detector:在DC-I-Net中,檢測任務和行人重識別任務的特征是從不同網絡層次中提取的。經過分類損失和回歸損失監督的兩階段檢測,完成準確Bounding Boxes(即目標行人)的檢測。
Re-identifier:經過兩階段檢測后,將refined bounding Boxes的坐標輸入ROIAlign層,計算refined目標建議的特征,用于行人重識別。對于ReID任務,匯集的feature map的大小為7x14,其寬高比與person的邊框相似。然后將特征圖輸入全連通層,學習用于行人重識別的特征向量表示。最后,通過全連通層生成目標方案的256-D的經過L2歸一化后特征,并將其輸入到和中進行重識別模塊的訓練。
損失函數定義如下:
DC-I-Net總損失為:
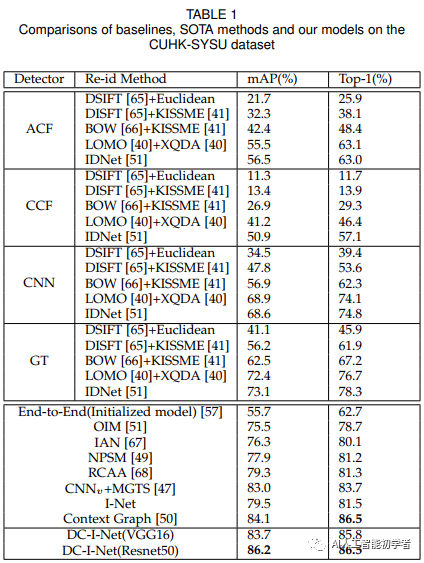
3、實驗結果
原文標題:【檢測+檢索】一個模型讓你不僅看得見也可以找得到,集檢測與檢索與一身的作品
文章出處:【微信公眾號:機器視覺CV】歡迎添加關注!文章轉載請注明出處。
責任編輯:haq
-
圖像采集
+關注
關注
2文章
301瀏覽量
41309 -
AI
+關注
關注
87文章
31490瀏覽量
269899
原文標題:【檢測+檢索】一個模型讓你不僅看得見也可以找得到,集檢測與檢索與一身的作品
文章出處:【微信號:Unfinished_coder,微信公眾號:機器視覺CV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
芯盾時代繼續深化中建科技統一身份認證平臺建設
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊

【「具身智能機器人系統」閱讀體驗】1.初步理解具身智能
【「具身智能機器人系統」閱讀體驗】+初品的體驗
ADS1230本身的data ready信號是100ms一個周期,為什么中間會有一段不是100ms為周期?
集性能與成本于一身的IMU,讓無人機飛行更穩定

手持多參數速測記錄儀:集多種測量功能于一體
名單公布!【書籍評測活動NO.51】具身智能機器人系統 | 了解AI的下一個浪潮!
天合光能榮獲日本G-mark設計獎
軟件系統的數據檢索設計





 工商網監
工商網監
評論