 基于FPGA的AIX語音識別解決方案
基于FPGA的AIX語音識別解決方案
AIX(artificial intelligence aXellerator)是韓國SK公司為語音識別提供的一個解決方案,應用于微軟的開源語音識別框架Kaldi。AIX使用了Xilinx的FPGA平臺,充分利用了FPGA能提供的外存訪問帶寬和DSP資源。在自動語言識別(ASR)中,在性能和功耗上超過了分別超過了最領先的CPU 10.2倍和流行的GPU20.1倍。
1. 硬件平臺和算法介紹
AIX使用了Xilinx Kintex Ultrascale KCU1500板卡,板卡包括一個KU115芯片,4塊4GB DDR4-2400的DRAM,每塊芯片有64個DQ引腳。最大可以支持76.8GB/s的帶寬。KU115芯片資源如下:
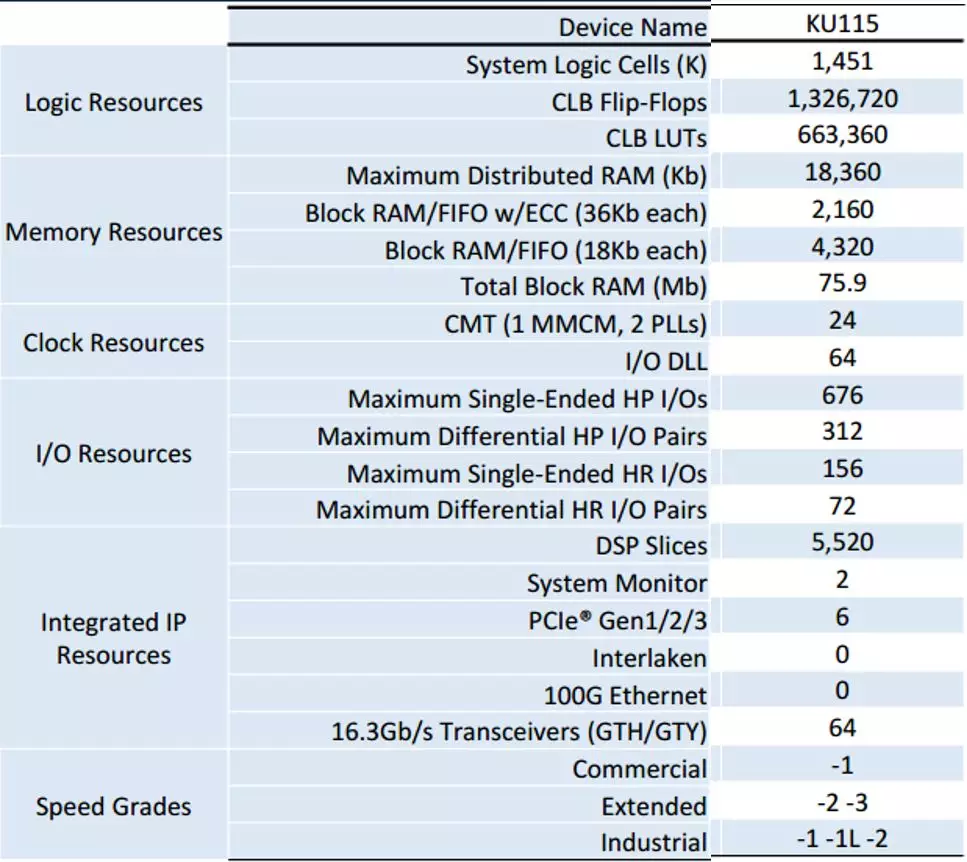
圖1.1 KU115資源
Kaldi是一個基于C++編寫的用于語音識別的開源工具,它依賴于兩個外部工具庫:一個是openFst,另外一個是線性計算,包括矩陣乘法,以及矩陣和向量的操作。openFst基于有限狀態轉換器算法,可以用于語音和語言識別中。所以在ASR中包含了大量的矩陣乘法運算。AIX主要的目的就是加速這些矩陣乘法運算。
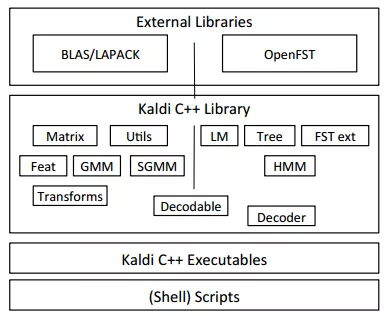
圖1.2 Kaldi庫
一個基本的語音識別算法過程如下:首先采集人的語音信號,將語音信號分割成一段段向量,每個向量會有一些重疊。將每段語音信號經過FFT等操作,轉換為MFCC或者倒譜,實際上就是做了一些向量的轉換操作。MFCC或者倒譜的表達能更好的提取語音特征。在論文中每個向量長度為120。為了能夠表現不同向量之間的關系,將每個Ci向量最近鄰的2n個向量組合為一個整體,然后送到MLP進行運算。通過MLP提取特征,在進行HMM操作進行分類處理。AIX就是加速MLP這部分操作,因為這部分占據了整個算法的大部分運算,涉及到大量矩陣運算。
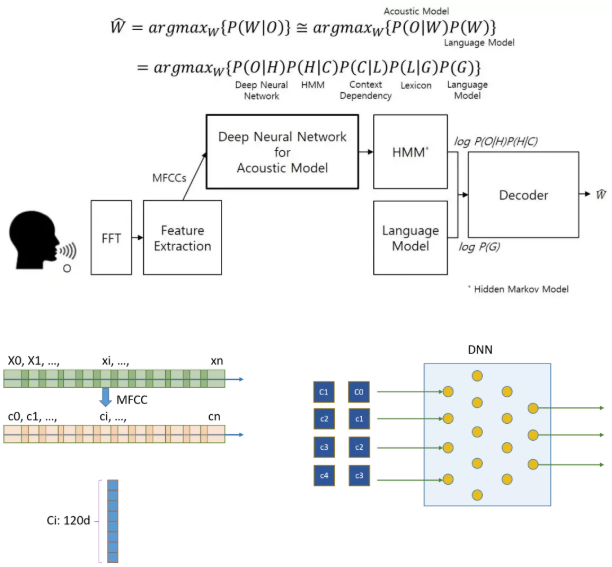
圖1.3 ASR算法過程
2. DNN硬件架構
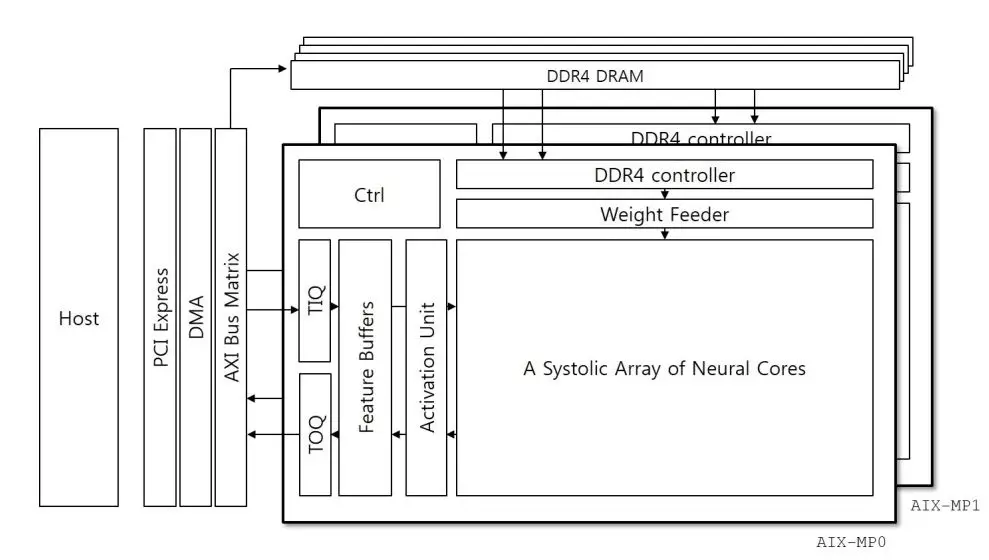
圖2.1 AIX硬件架構
在KU115上,AIX由兩個核組成,每個核的結構是一樣的。這兩個核分別分布在芯片的兩個die上。每個核使用兩個DDR4,每個提供38.4GB/s的帶寬。核心計算單元是脈動陣列結構,大小為64x40,總共使用了2560個DSP。語音向量從脈動陣列左側進入,權重數據從上邊脈動進入,然后在每個DSP進行乘法,每個DSP還進行累加。最后可以輸出一個64X40大小的矩陣。因此進入的語音向量,每次在緩存中獲得了40個120的語音向量后,進行轉置操作,得到120X40的向量組合,然后脈動送入陣列。完成矩陣乘法。這種算法在之前的文章《在DNN中FPGA都做了什么?》有詳細描述。這對語音向量的帶寬要求是一個FPGA時鐘周期40x16bit,權重為64x16bit。64的選擇可以適配DDR的帶寬38.4GB/s。這樣既充分利用了DSP資源,也更好的利用了DDR帶寬。這種方案適合處理矩陣乘矩陣,但是對于矩陣乘向量的DSP利用率就會很低了。因為權重的IO帶寬較低。
圖2.2 矩陣x矩陣計算陣列
這個板卡是通過PCIE和主機連接,主機完成DNN之外的HMM,decoder等操作。開始主機通過PCIE將一定量的權重存儲到板卡的DDR中,然后AIX主動去獲取權重數據。權重數據是不斷被復用的,因此初始時刻被加載到DDR中以后,就不需要再加載權重了。除非權重很多超過了DDR的存儲空間。主要更新的是語音向量,需要通過PCIE不斷下載到片上。當片上向量隊列存儲了40個后,就可以進行轉置送到脈動陣列進行運算。
對于網絡中的其他操作,比如sigmoid,tangent,leakyRelu等,都是通過查找表完成的。查找表的方式可以更靈活的用于這些雜七雜八的運算。這些運算數學公式復雜,直接計算會耗費很多邏輯,不如查找表簡潔。缺點就是需要較大的存儲空間,空間是和數據精度有關的,精度越高消耗存儲空間越大。
3. 軟件架構
為了能夠將AIX更好的融入到基于Kaldi的ASR計算中,需要很好的和數據中心的軟件端進行匹配。因此提出三種軟件模型來解決這個問題。
一個模型用于對AIX的配置,即在AIX計算前,需要準備好權重和偏置數據。這種準備工作是由NN converter軟件來做的,主要就是判定一個網絡中哪些層可以被AIX加速,然后將這部分權重發送給AIX。
另外一個是監測模型。為了保證AIX的穩定運行,需要進行大量的邊緣條件測試,因此監測軟件來檢測一些異常情況。主要包括:功耗,溫度,資源利用,設備狀態。
最后一個是用于處理語音向量的軟件。為了保證實時處理語音數據,每8個語音向量組成一個batch,然后一起寫入AIX。為了提高脈動陣列的利用效率,語音緩存盡可能收集更多向量,然后開始計算。為了減小收集時間,軟件端提供了多個服務通道,同時準備語音向量,并向AIX發送或者接收來自AIX的結果。由于處理不同語音向量是有順序的,為了保證結果也能夠保持順序不變。每個通道增加了鎖機制來保持向量的發送和接收順序。當需要向AIX寫的時候,就產生一個有wlock的寫進程,直到wlock被解鎖,這個進程才開始往AIX發送數據。同理讀進程也有一個rlock。這些鎖會保證進程間的依賴和同步。
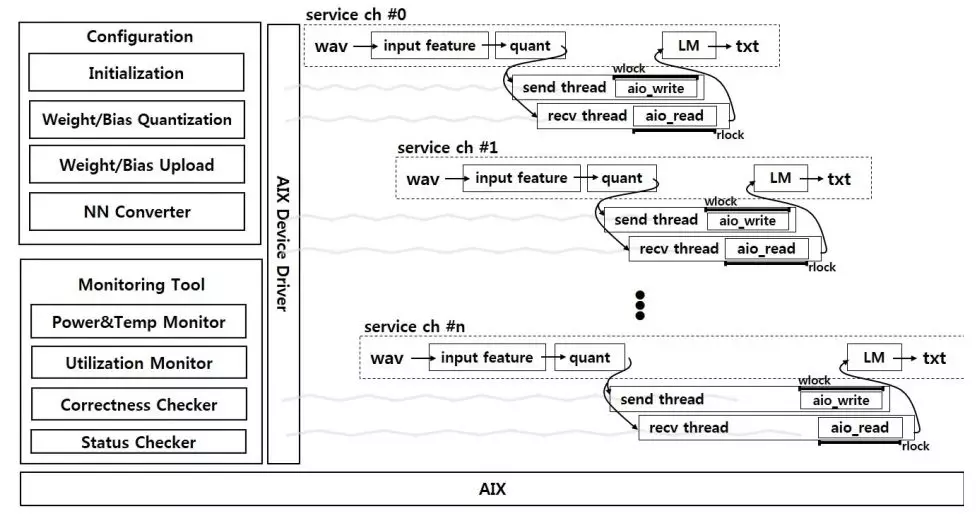
圖3.1 軟件架構
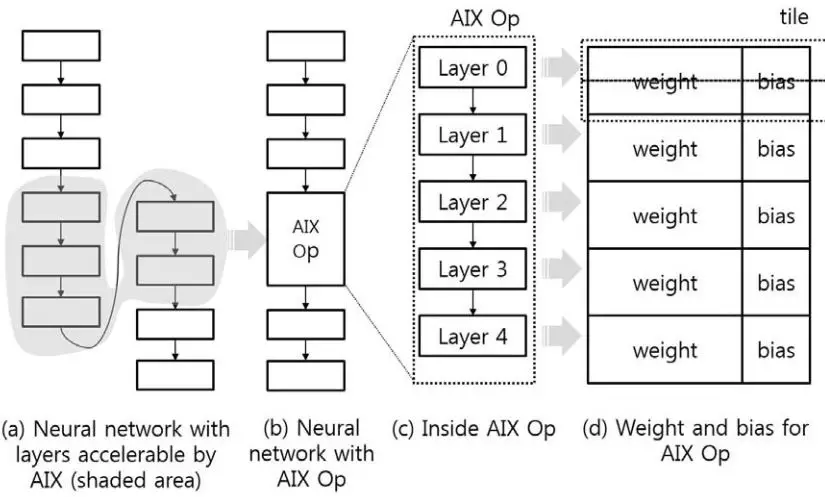
圖3.2 NN converter的作用
4. 結果
現在看資源利用率:

圖4.1 資源利用率
AIX的性能和Intel的E5-2620和Nvidia的P100 GPU進行了對比。同時考慮上功耗和語音識別時間,AIX都超過了CPU和GPU。
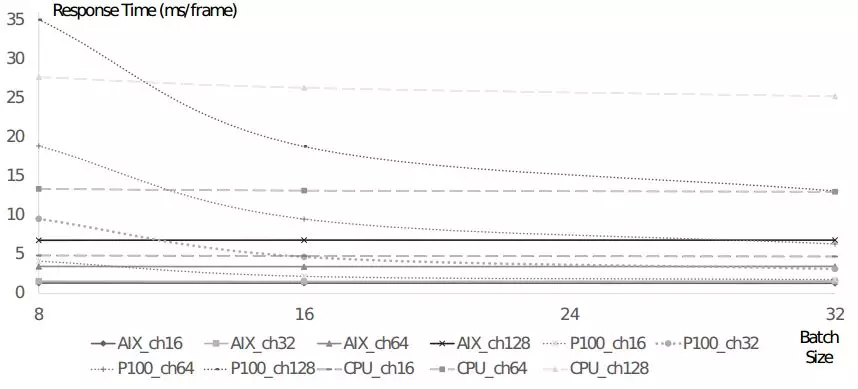
圖4.2 AIX和CPU以及GPU的性能對比
總結
AIX采用了脈動陣列的架構,充分利用了矩陣乘法中數據的復用率。能夠最大限度利用內存帶寬來獲得最大性能。
文獻
1. Minwook Ahn, S.J.H., Wonsub Kim, Seungrok Jung, Yeonbok Lee, Mookyoung Chung, Woohyung Lim, Youngjoon Kim, AIX A high performance and energy ef?cient inference accelerator on FPGA for a DNN-based commercial speech recognition. FPGA, 2019.
編輯:hfy
-
加速器
+關注
關注
2文章
806瀏覽量
38015 -
Xilinx
+關注
關注
71文章
2171瀏覽量
121922 -
語音識別
+關注
關注
38文章
1742瀏覽量
112821 -
AIX
+關注
關注
0文章
10瀏覽量
9862
發布評論請先 登錄
相關推薦
CEVA攜Sensory力推先進的語音識別解決方案

盲人閱讀器語音合成技術解決方案 #語音識別 #語音合成 #盲人閱讀器 #圖像識別#硬聲創作季
求一種基于LD332X的單芯片語音識別解決方案
方言離線語音控制場景解決方案
靈云遠場語音識別解決方案
華為云發布首款基于FPGA平臺語音識別加速解決方案
首款基于FPGA的原創深度學習語音識別加速解決方案面世,深鑒引領FPGA加速云市場
一種低功耗的語音識別解決方案
離線語音照明解決方案:讓你的照明更智能







 工商網監
工商網監
評論