 JD和OPPO的研究人員們提出了一種姿勢引導的時尚圖像生成模型
JD和OPPO的研究人員們提出了一種姿勢引導的時尚圖像生成模型
時尚總在引領潮流。
在人工智能、增強現實、可穿戴、虛擬試妝等技術的加持下,時尚行業特別是在線時尚行業獲得了飛速的發展。為了吸引客戶更多的目光、更棒的視覺體驗、更好地展現商品,高清大圖、模特多角度擺拍已經成了服裝、箱包、鞋類、美妝等線上商家的宣傳標配。在網上購物時,大家都想看看模特衣服在各種角度姿勢下的樣子,但是越多越全面的姿勢擺拍也就意味著越大的投入。為了降低宣傳成本,很多研究開始聚焦于如何合成高質量的逼真圖像。
在這篇文章中來自北卡羅來納大學、JD和OPPO的研究人員們提出了一種姿勢引導的時尚圖像生成模型,可以基于模特當前姿勢,生成出其他各種不同姿勢下的相同著裝的新圖像!也許在這樣技術的幫助下,模特再也不用辛苦一分鐘拍二十個動作了~
生成新姿勢下的時尚圖像
研究人員的主要目的在于訓練一個生成模型,將模特在當前姿勢上的圖像遷移到其他的目標姿勢上去,實現對于衣著等商品的全面展示。
這一模型主要由生成器和判別器構成,與先前工作不同的是這一模型架構中包含了兩個不同的判別器!其中生成器由兩個編碼器構成,分別用于從圖像和對應的動作關鍵點特征圖進行編碼,而解碼器則用于從動作和衣著的特征中合成目標圖像。對于判別器來說,除了判定生成圖像是否逼真外、還需要判定動作與生成圖像的連續性以保證生成圖像動作的連續性和魯棒性。
模型的主要架構,生成器的編碼器包含了對于圖像的編碼器Ei和對動作的編碼器Ep,基于U-Net和bi-LSTM共同構建而成,而兩個判別器分別用于判定圖像的真偽并保證生成圖像與動作間的連續性。
時尚圖像生成器
生成器中主要包含了兩個編碼器和一個解碼器用于處理圖像和對應姿勢,生成器探索了輸入圖像的視覺語義特征和位姿信息,并生成對應姿勢下的新圖像。圖像編碼器:圖像編碼器的目標是從單張或多張圖像中湖區語義編碼信息。研究人員首先使用了ResNet作為主干網絡抽取不同尺度的特征,包括紋理、顏色、邊緣線條信息等。隨后將這些特征輸入到雙邊長短時記憶網絡(bc-LSTM)中用于從相同衣著不同視角的模特圖像中抽取共同的特征,將不同種類的圖像特征進行轉換,同時對不同特征下的背景和噪聲進行處理。最終得到了可以表達圖像視覺語義信息的編碼Ci,用于后續圖像的生成。位姿編碼器:模型同時需要位姿數據來為生成圖像進行引導,研究人員利用了18個關鍵點來表示人體位姿,用不同顏色的直線相連并以RGB的格式進行表示。通過U-Net的架構和3*3的卷積從位姿圖中抽取高層次語義特征Cp并在解碼過程中通過跳接層連接進行特征共享。解碼器:其主要目的是通過圖像編碼Ci 和動作編碼Cp重建出逼真的圖像。首先將圖像編碼與位姿編碼的編碼拼接在一起,并基于U-Net架構和跳接層將視覺語義信息與動作編碼信息匹配起來,進行有效的圖像生成。判別器:其主要目標是引導模型生成比先前模型更逼真圖像。在訓練過程中研究人員利用兩個判別器來同時進行對抗訓練,主要采用了與PatchGAN類似的實現。其中Di用于判別生成圖像是否逼真,與先前的模型類似;而Dp則用于判定生成圖像與對應動作的連續性。Dp的輸出是真實圖像與對應位姿和這一位姿下生成的圖像,用于判定圖像是否與位姿匹配,它對于生成與位姿對應的時尚圖像具有重要的作用,能幫助網絡生成更為復雜的動作姿勢,同時保持連續性和魯棒性。
結果展示
通過DeepFashion和Market-1501數據的訓練后研究人員得到了不錯的結果。
Deep Fasion 數據集
Market-1501數據集
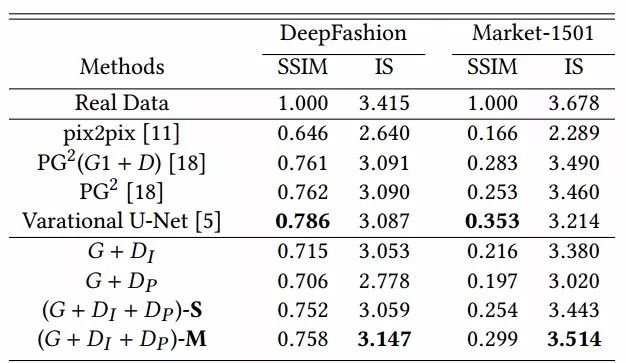
生成的結果與先前方法的比較,其中S和M代表了單張和多張圖像輸入的生成結果:
在數據集上的表現還不錯,從源圖像生成了新的姿勢:
-
解碼器
+關注
關注
9文章
1147瀏覽量
40869 -
圖像
+關注
關注
2文章
1089瀏覽量
40534 -
模型
+關注
關注
1文章
3298瀏覽量
49063
原文標題:從姿勢到圖像——基于人體姿勢引導的時尚圖像生成算法
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種圖像語義分層處理框架,可以實現像素級別的圖像語義理解和操縱
研究人員提出了一種柔性可拉伸擴展的多功能集成傳感器陣列
特倫托大學與Inria合作:使用GAN生成人體的新姿勢圖像
OpenAI的研究者們提出了一種新的生成模型,能快速輸出高清、真實的圖像
以色列研究人員開發出了一種能夠識別不同刺激的新型傳感系統
研究人員們提出了一系列新的點云處理模塊

Facebook的研究人員提出了Mesh R-CNN模型

研究人員推出了一種新的基于深度學習的策略
研究人員開發出了一種稱為LB-WayPtNav-DH的機器人導航新框架
研究人員開發了一種新穎的機器學習管道
微軟亞洲研究院的研究員們提出了一種模型壓縮的新思路
一種基于改進的DCGAN生成SAR圖像的方法






 工商網監
工商網監
評論