 電子發(fā)燒友App
電子發(fā)燒友App


關(guān)鍵詞: AutoML , AdaNet , 集成學(xué)習(xí) , 機(jī)器學(xué)習(xí) , 神經(jīng)網(wǎng)絡(luò)
來源:新智元
7 小時前 上傳
今天,谷歌宣布開源AdaNet,這是一個輕量級的基于TensorFlow的框架,可以在最少的專家干預(yù)下自動學(xué)習(xí)高質(zhì)量的模型。
這個項(xiàng)目基于Cortes等人2017年提出的AdaNet算法,用于學(xué)習(xí)作為子網(wǎng)絡(luò)集合的神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)。
谷歌AI負(fù)責(zé)人Jeff Dean表示,這是谷歌AutoML整體工作的一部分,并且,谷歌同時提供了AdaNet的開源版本和教程notebook。
該團(tuán)隊(duì)在介紹博客中表示:“AdaNet以我們最近的強(qiáng)化學(xué)習(xí)和基于進(jìn)化的AutoML研究為基礎(chǔ),在提供學(xué)習(xí)保證的同時實(shí)現(xiàn)了快速、靈活。重要的是,AdaNet提供了一個通用框架,不僅可以學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)架構(gòu),還可以學(xué)習(xí)集成,以獲得更好的模型。”
AdaNet提供以下特征:
Estimator API,可輕松訓(xùn)練、評估和服務(wù)AdaNet模型。
學(xué)習(xí)在TensorFlow中集成用戶定義的子網(wǎng)。
用于在單個 train() 調(diào)用中搜索子網(wǎng)架構(gòu)和參數(shù)的接口。
關(guān)于CPU和GPU的分布式訓(xùn)練(我們正在開發(fā)TPU支持)。
一流的TensorBoard integration。
提供理論學(xué)習(xí)。
基于集成學(xué)習(xí)的自動搜索工具
集成學(xué)習(xí)(Ensemble learning)是將不同機(jī)器學(xué)習(xí)(ML)模型預(yù)測結(jié)合起來的技術(shù),廣泛用于神經(jīng)網(wǎng)絡(luò),以實(shí)現(xiàn)最先進(jìn)的性能。得益于豐富的經(jīng)驗(yàn)和理論保證,集成學(xué)習(xí)在許多Kaggle競賽中取得了成功,例如Netflix Prize。
由于訓(xùn)練時間長,集成學(xué)習(xí)在實(shí)踐中使用不多,而且選擇哪個ML模型需要根據(jù)其領(lǐng)域?qū)I(yè)知識來。
但隨著計(jì)算能力和專用深度學(xué)習(xí)硬件(如TPU)變得更容易獲得,機(jī)器學(xué)習(xí)模型的一個趨勢是變得更大,集成(ensemble)也就變得更加重要。
現(xiàn)在,AdaNet就是這樣一個工具,可以自動搜索神經(jīng)網(wǎng)絡(luò)架構(gòu),并學(xué)會將最好的架構(gòu)組合成一個高質(zhì)量的模型。
AdaNet易于使用,并能創(chuàng)建高質(zhì)量的模型,為ML實(shí)踐者節(jié)省了用于選擇最佳神經(jīng)網(wǎng)絡(luò)架構(gòu)的時間,實(shí)現(xiàn)了一種將學(xué)習(xí)神經(jīng)架構(gòu)作為子網(wǎng)絡(luò)集合的自適應(yīng)算法。
AdaNet能夠添加不同深度和寬度的子網(wǎng)絡(luò),以創(chuàng)建多樣化的集合,并通過參數(shù)數(shù)量來改進(jìn)性能。
7 小時前 上傳
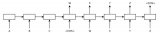
下載附件 (437.5 KB)AdaNet自適應(yīng)地產(chǎn)生了神經(jīng)網(wǎng)絡(luò)的集成。在每次迭代中,它測量每個候選對象的集成損失,并選擇最佳的一個,然后進(jìn)入下一次迭代。
快速且易于使用
AdaNet實(shí)現(xiàn)了TensorFlow Estimator接口,通過封裝訓(xùn)練、評估、預(yù)測和服務(wù)導(dǎo)出,大大簡化了機(jī)器學(xué)習(xí)編程。它集成了開源工具,如TensorFlow Hub模塊,TensorFlow Model Analysis和Google Cloud的Hyperparameter Tuner。分布式訓(xùn)練支持可顯著縮短訓(xùn)練時間,并可與可用的CPU和加速器(例如GPU)進(jìn)行線性擴(kuò)展。
7 小時前 上傳
下載附件 (24.66 KB)AdaNet在CIFAR-100上每個訓(xùn)練步驟(X軸)的精度(y軸)。藍(lán)線是訓(xùn)練集上的性能,紅線是測試集上的性能。每一百萬步開始訓(xùn)練一個新的子網(wǎng)絡(luò),并最終提高整體的性能。在添加新子網(wǎng)之前,灰線和綠線是集合的準(zhǔn)確度。
由于TensorBoard是用于在訓(xùn)練期間可視化模型性鞥的最佳TensorFlow功能之一,AdaNet可與其無縫集成,以監(jiān)控子網(wǎng)絡(luò)訓(xùn)練,集合組合和性能。當(dāng)AdaNet完成訓(xùn)練后,它會導(dǎo)出一個可以使用TensorFlow Serving部署的SavedModel。
學(xué)習(xí)保證
構(gòu)建神經(jīng)網(wǎng)絡(luò)集合面臨這么幾個挑戰(zhàn):要考慮的最佳子網(wǎng)架構(gòu)是什么?再此使用相同的架構(gòu)或鼓勵多樣性是不是最佳選擇?雖然具有更多參數(shù)的復(fù)雜子網(wǎng)將在訓(xùn)練集上表現(xiàn)更好,但由于其存在更強(qiáng)的復(fù)雜性,它們可能不會適用于未知數(shù)據(jù)。這些挑戰(zhàn)來自評估模型性能的過程。我們可以評估一個訓(xùn)練集子集的性能,但這樣做會減少可用于訓(xùn)練神經(jīng)網(wǎng)絡(luò)的示例數(shù)量。
相反,AdaNet的方法(在ICML 2017的“ AdaNet:人工神經(jīng)網(wǎng)絡(luò)的自適應(yīng)結(jié)構(gòu)學(xué)習(xí) ”一文中提出)是為了優(yōu)化一個對象,以平衡集合在訓(xùn)練集上的表現(xiàn)與其適用于未知數(shù)據(jù)的能力之間的權(quán)衡。集合這樣選擇子網(wǎng)絡(luò):只有當(dāng)候選子網(wǎng)絡(luò)改進(jìn)了總體的訓(xùn)練損失,而不是影響了整體的泛化能力時,才包含這個候選子網(wǎng)絡(luò)。這保證了:
1.集合的泛化誤差受到訓(xùn)練誤差和復(fù)雜性的限制。
2.通過優(yōu)化對象,我們可以直接將限制最小化。
優(yōu)化對象的一個實(shí)際好處是:它不需要保留集來選擇要添加到集合中的候選子網(wǎng)。這還將帶來另一個好處:我們可以使用更多的訓(xùn)練數(shù)據(jù)來訓(xùn)練子網(wǎng)。
可擴(kuò)展性
我們認(rèn)為,為滿足研究和生產(chǎn)制作AutoML框架的關(guān)鍵在于不僅要提供合理的默認(rèn)值,還要允許用戶嘗試自己子網(wǎng)及模型的定義。因此,機(jī)器學(xué)習(xí)研究人員、從業(yè)人員和愛好者均可報(bào)名定義自己的AdaNet adanet.subnetwork.Builder,通過使用高級別的TensorFlow API,如tf.layers。
已經(jīng)在其系統(tǒng)中集成TensorFlow模型的用戶可以輕松地將他們的TensorFlow代碼轉(zhuǎn)換為AdaNet子網(wǎng),并使用adanet.Estimator提高模型性能,同時獲得學(xué)習(xí)保證。AdaNet將探測他們定義的候選子網(wǎng)的搜索空間,并學(xué)習(xí)整合子網(wǎng)。例如,我們采用了NASNet-A CIFAR架構(gòu)的開源實(shí)現(xiàn)方式,將其轉(zhuǎn)換為子網(wǎng),并在八次AdaNet迭代后對CIFAR-10最先進(jìn)的結(jié)果進(jìn)行改進(jìn)。此外,我們的模型使用更少的參數(shù)實(shí)現(xiàn)了這一結(jié)果:
7 小時前 上傳
下載附件 (18.02 KB)











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論