 谷歌Transformer大進化 機翻最強王者上線
谷歌Transformer大進化 機翻最強王者上線
谷歌Evolved Transformer通過AutoML技術進行特定任務定制,在編碼器和解碼器模塊底部的卷積層以分支模式運行,提高了語言建模的性能,目前在機器翻譯領域可以達到最先進的結果。
Transformer是一種AI架構,最早是在2017年Google的科學家合著的論文《Attention Is All You Need》中介紹的,它比較擅長撰寫散文和產品評論、合成聲音、以古典作曲家的風格制作和聲。
但是,谷歌的一個研究小組認為它可以更進一步使用AutoML技術,根據特定任務進行定制翻譯。在一篇新發表的論文和博客中,研究人員描述了工作成果:與原始的Transformer相比,現在的Transformer既達到了最先進的翻譯結果,也提高了語言建模的性能。
目前,他們已經發布了新的模型Evolved Transformer——開放源代碼的AI模型和數據集庫,來作為Tensor2Tensor(谷歌基于tensorflow新開源的深度學習庫,該庫將深度學習所需要的元素封裝成標準化的統一接口,在使用其做模型訓練時可以更加的靈活)的一部分。
一般意義上,AutoML方法是從控制器訓練和評估質量的隨機模型庫開始,該過程重復數千次,每次都會產生新的經過審查的機器學習架構,控制器可以從中學習。最終,控制器開始為模型組件分配高概率,以便這些組件在驗證數據集上更加準確,而評分差的區域則獲得較低的概率。
研究人員稱,使用AutoML發現Evolved Transformer需要開發兩種新技術,因為用于評估每種架構性能的任務WMT'14英德語翻譯的計算成本很高。
第一種是通過暖啟動(warm starting)的方式,將初始模型填充為Transformer架構進行播種,而不采用隨機模型,有助于實現搜索。第二種漸進式動態障礙(PDH)則增強了搜索功能,以便將更多的資源分配給能力最強的候選對象,若模型“明顯不良”,PDH就會終止評估,重新分配資源。
通過這兩種技術,研究人員在機器翻譯上進行大規模NAS,最終找到了Evolved Transformer。
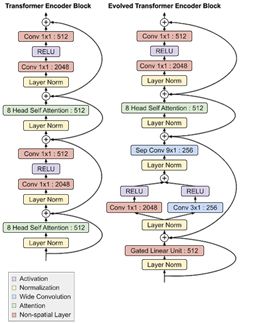
(Evolved Transformer架構)
那么Evolved Transformer有什么特別之處呢?
與所有深度神經網絡一樣,Evolved Transformer包含神經元(函數),這些神經元從輸入數據中傳輸“信號,并緩慢調整每個連接的突觸強度(權重),這是模型提取特征和學習進行預測的方式。此外,Evolved Transformer還能使每個輸出元件連接到每個輸入元件,并且動態地計算它們之間的權重。
與大多數序列到序列模型一樣,Evolved Transformer包含一個編碼器,它將輸入數據(翻譯任務中的句子)編碼為嵌入(數學表示)和一個解碼器,同時使用這些嵌入來構造輸出(翻譯)。
但研究人員也指出,Evolved Transformer也有一些部分與傳統模型不同:在編碼器和解碼器模塊底部的卷積層以分支模式運行,即在合并到一起時,輸入需要通過兩個單獨的的卷積層。
雖然最初的Transformer僅僅依賴于注意力,但Evolved Transformer是一種利用自我關注和廣泛卷積的優勢的混合體。
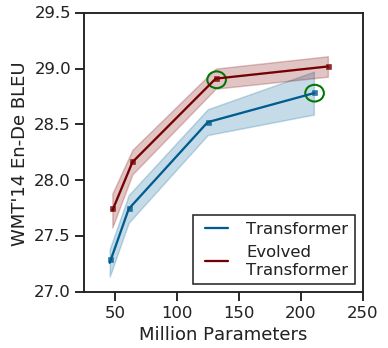
(原始Transforme與Evolved Transformer的性能對比)
在測試中,研究人員將Evolved Transformer與原始Transformer在模型搜索期間使用的英德翻譯任務進行了比較,發現前者在BLEU(評估機器翻譯文本質量的算法)和Perplexity(衡量概率分布預測樣本的程度)上性能更好。
在較大的數據中,Evolved Transformer達到了最先進的性能,BLEU得分為29.8分。在涉及不同語言對和語言建模的翻譯實驗中,Evolved Transformer相比于原始Transformer的性能提升了兩個Perplexity。
-
谷歌
+關注
關注
27文章
6173瀏覽量
105637 -
AI
+關注
關注
87文章
31155瀏覽量
269483 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14915 -
Transformer
+關注
關注
0文章
144瀏覽量
6025
原文標題:谷歌Transformer大進化,機翻最強王者上線
文章出處:【微信號:Aiobservation,微信公眾號:人工智能觀察】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
transformer專用ASIC芯片Sohu說明

AI眼鏡形態席卷可穿戴市場!谷歌眼鏡幾次“流產”,將靠AI翻盤

磁翻板液位計怎么用磁鐵校正
Transformer能代替圖神經網絡嗎
Transformer語言模型簡介與實現過程
使用PyTorch搭建Transformer模型
谷歌SGE生成搜索引擎存在惡意網站推薦問題
新火種AI|谷歌深夜炸彈!史上最強開源模型Gemma,打響新一輪AI之戰

谷歌大型模型終于開放源代碼,遲到但重要的開源戰略

基于Transformer模型的壓縮方法

谷歌發布全球最強開源大模型Gemma
谷歌Gemini 1.5深夜爆炸上線,史詩級多模態硬剛GPT-5!最強MoE首破100萬極限上下文紀錄






 工商網監
工商網監
評論