 電子發燒友App
電子發燒友App


前言
在操作系統課程的學習中,很多人對進程線程有大體的認識,但操作系統教材更偏向于理論敘述,本文會結合 Linux 系統實現分析,更加印象深刻。
同時,大部分人都接觸進程和線程比較多,對協程知之甚少,然而最近協程并發編程技術火熱起來,希望讀完本文你對協程也有一個基本的了解。
話不多說,我們馬上進入本文的學習。
進程
關于進程和內存管理我之前有一篇文章單獨講解過,感興趣的同學點這里《別再說你不懂Linux內存管理了,10張圖給你安排的明明白白!》 這里再挑選一部分和本文相關的內容學習,溫故而知新。
首先還是說下「程序」的概念,程序是一些保存在磁盤上的指令的有序集合,是靜態的。進程是程序執行的過程,包括了動態創建、調度和消亡的整個過程,進程是程序資源管理的最小單位。
進程與資源
那么進程都管理哪些資源呢?通常包括內存資源、IO資源、信號處理等部分。
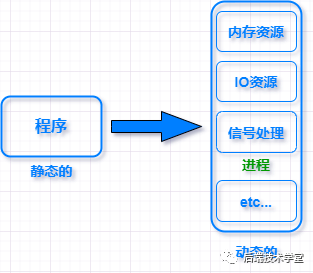
程序和進程
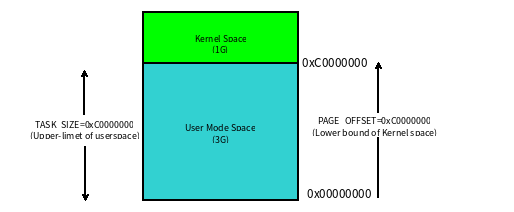
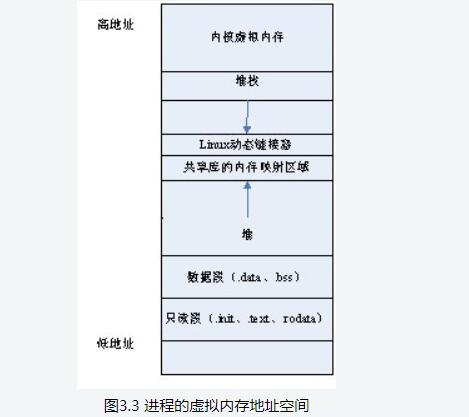
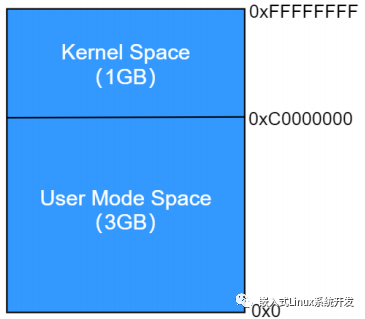
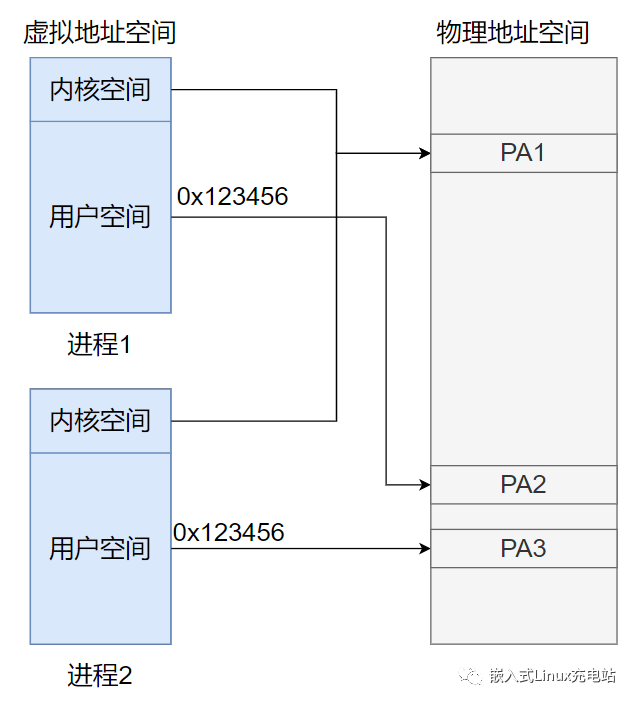
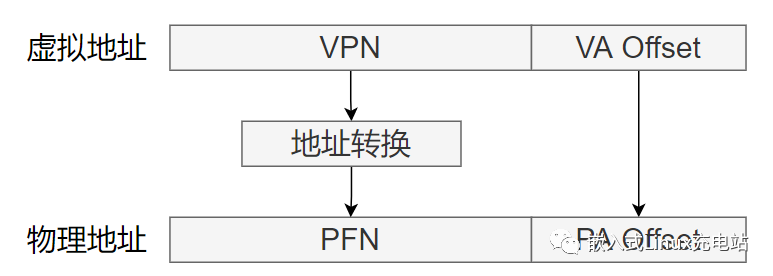
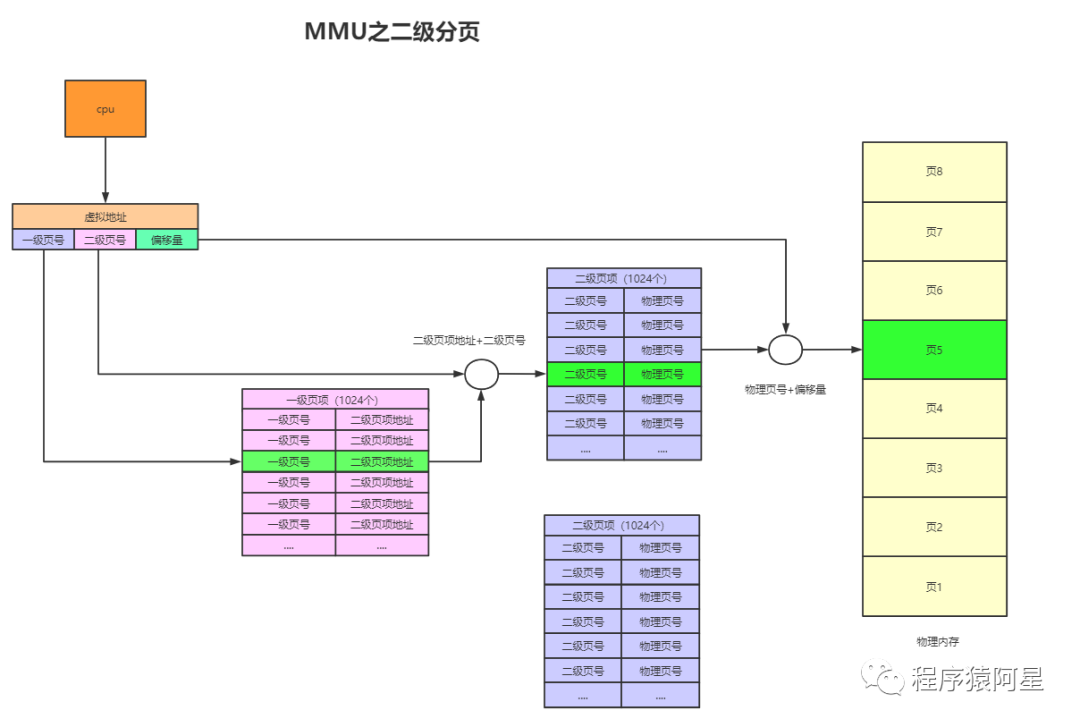
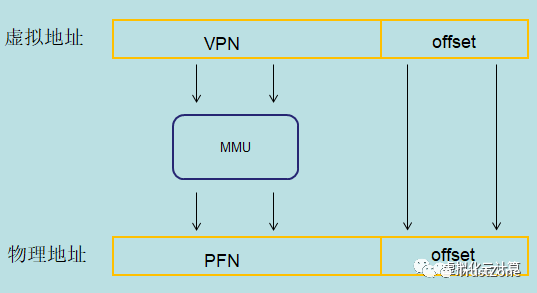
篇幅有限著重說一下內存管理,進程運行起來必然會涉及到對內存資源的管理。內存資源有限,操作系統采用虛擬內存技術,把進程虛擬地址空間劃分成用戶空間和內核空間。
地址空間
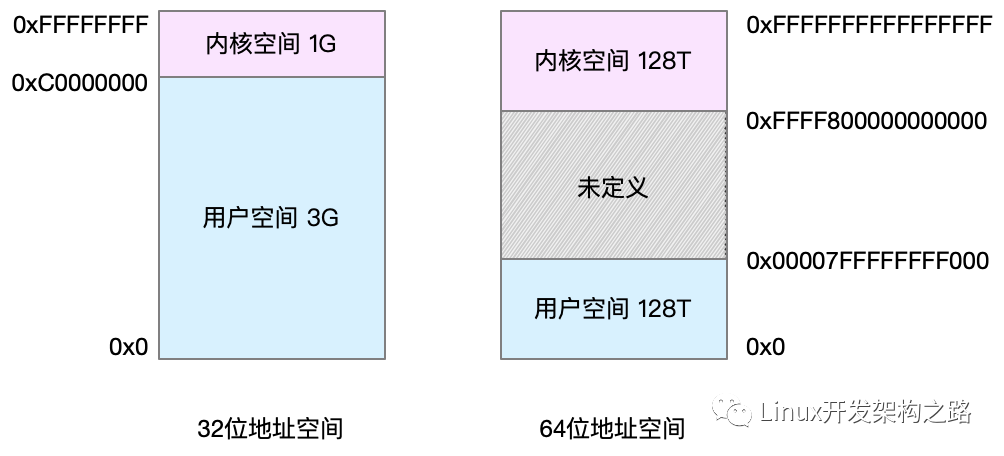
4GB 的進程虛擬地址空間被分成兩部分:用戶空間和內核空間
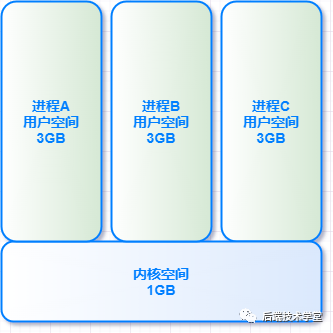
用戶空間內核空間
用戶空間
用戶空間按照訪問屬性一致的地址空間存放在一起的原則,劃分成 5個不同的內存區域。訪問屬性指的是“可讀、可寫、可執行等 。
代碼段
代碼段是用來存放可執行文件的操作指令,可執行程序在內存中的鏡像。代碼段需要防止在運行時被非法修改,所以只準許讀取操作,它是不可寫的。
數據段
數據段用來存放可執行文件中已初始化全局變量,換句話說就是存放程序靜態分配的變量和全局變量。
BSS段
BSS段包含了程序中未初始化的全局變量,在內存中 bss 段全部置零。
堆 heap
堆是用于存放進程運行中被動態分配的內存段,它的大小并不固定,可動態擴張或縮減。當進程調用malloc等函數分配內存時,新分配的內存就被動態添加到堆上(堆被擴張);當利用free等函數釋放內存時,被釋放的內存從堆中被剔除(堆被縮減)
棧 stack
棧是用戶存放程序臨時創建的局部變量,也就是函數中定義的變量(但不包括 static 聲明的變量,static意味著在數據段中存放變量)。除此以外,在函數被調用時,其參數也會被壓入發起調用的進程棧中,并且待到調用結束后,函數的返回值也會被存放回棧中。由于棧的先進后出特點,所以棧特別方便用來保存/恢復調用現場。從這個意義上講,我們可以把堆棧看成一個寄存、交換臨時數據的內存區。
上述幾種內存區域中數據段、BSS 段、堆通常是被連續存儲在內存中,在位置上是連續的,而代碼段和棧往往會被獨立存放。堆和棧兩個區域在 i386 體系結構中棧向下擴展、堆向上擴展,相對而生。
程序內存分段
你也可以再 linux 下用size 命令查看編譯后程序的各個內存區域大小:
[lemon ~]# size /usr/local/sbin/sshd
text data bss dec hex filename
1924532 12412 426896 2363840 2411c0 /usr/local/sbin/sshd
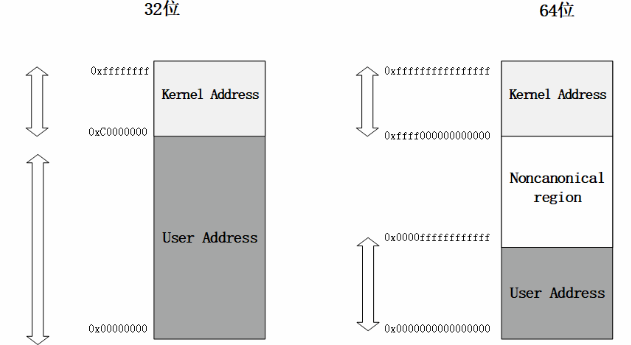
內核空間
在 x86 32 位系統里,Linux 內核地址空間是指虛擬地址從 0xC0000000 開始到 0xFFFFFFFF 為止的高端內存地址空間,總計 1G 的容量, 包括了內核鏡像、物理頁面表、驅動程序等運行在內核空間 。
內核空間地址映射
線程
線程是操作操作系統能夠進行運算調度的最小單位。線程被包含在進程之中,是進程中的實際運作單位,一個進程內可以包含多個線程,線程是資源調度的最小單位。
多線程程序模型
線程資源和開銷
同一進程中的多條線程共享該進程中的全部系統資源,如虛擬地址空間,文件描述符文件描述符和信號處理等等。但同一進程中的多個線程有各自的調用棧、寄存器環境、線程本地存儲等信息。
線程創建的開銷主要是線程堆棧的建立,分配內存的開銷。這些開銷并不大,最大的開銷發生在線程上下文切換的時候。
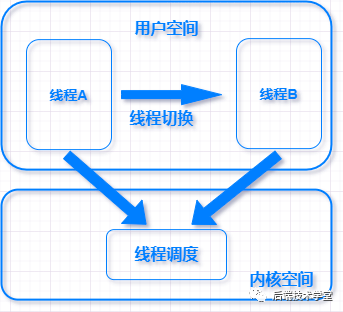
線程切換
線程分類
還記得剛開始我們講的內核空間和用戶空間概念嗎?線程按照實現位置和方式的不同,也分為用戶級線程和內核線程,下面一起來看下這兩類線程的差異和特點。
用戶級線程
實現在用戶空間的線程稱為用戶級線程。用戶線程是完全建立在用戶空間的線程庫,用戶線程的創建、調度、同步和銷毀全由用戶空間的庫函數完成,不需要內核的參與,因此這種線程的系統資源消耗非常低,且非常的高效。
特點
用戶線級線程只能參與競爭該進程的處理器資源,不能參與全局處理器資源的競爭。
用戶級線程切換都在用戶空間進行,開銷極低。
用戶級線程調度器在用戶空間的線程庫實現,內核的調度對象是進程本身,內核并不知道用戶線程的存在。
用戶線程圖解
缺點
如果觸發了引起阻塞的系統調用的調用,會立即阻塞該線程所屬的整個進程。
系統只看到進程看不到用戶線程,所以只有一個處理器內核會被分配給該進程 ,也就不能發揮多核 CPU 的優勢 。
內核級線程
內核線程建立和銷毀都是由操作系統負責、通過系統調用完成,內核維護進程及線程的上下文信息以及線程切換。
特點
內核級線級能參與全局的多核處理器資源分配,充分利用多核 CPU 優勢。
每個內核線程都可被內核調度,因為線程的創建、撤銷和切換都是由內核管理的。
一個內核線程阻塞與他同屬一個進程的線程仍然能繼續運行。
內核線程圖解
缺點
內核級線程調度開銷較大。調度內核線程的代價可能和調度進程差不多昂貴,代價要比用戶級線程大很多。
線程表是存放在操作系統固定的表格空間或者堆棧空間里,所以內核級線程的數量是有限的。
Linux 線程實現
Linux 并沒有為線程準備特定的數據結構,因為 Linux只有task_struct這一種描述進程的結構體。在內核看來只有進程而沒有線程,線程調度時也是當做進程來調度的。Linux所謂的線程其實是與其他進程共享資源的輕量級進程。
為什么說是輕量級呢?在于它只有一個最小的執行上下文和調度程序所需的統計信息,它只帶有進程執行相關的信息,與父進程共享進程地址空間 。
輕量級進程
輕量級線程 Light-weight Process簡稱LWP ,是一種由內核支持的用戶線程,每一個輕量級進程都與一個特定的內核線程關聯。
它是基于內核線程的高級抽象,系統只有先支持內核線程才能有 LWP。每一個進程有一個或多個 LWPs ,每個LWP 由一個內核線程支持,在這種實現的操作系統中 LWP 就是用戶線程。
輕量級進程
輕量級進程最早在Linux 內核 2.0.x 版本就已實現,應用程序通過一個統一的 clone() 系統調用接口,用不同的參數指定創建的進程是輕量進程還是普通進程。
特點和缺點
由于輕量輕量級進程基于內核線程實現,因此它的特點和缺點就是內核線程的缺點,這里不再贅述。
查看 LWP 信息
輕量級線程也沒什么神秘的,還記得我在這篇文章《資深程序員總結:分析Linux進程的6個方法,我全都告訴你》教你的方法嗎?我們用 Linux 的 pstack 命令可以查看進程的輕量級線程 LWP 信息。下圖的黃色字體就是打印出的輕量級線程 ID ,以及該線程的調用堆棧信息,從最新的棧幀開始往下排列。
用法示例:pstack pid
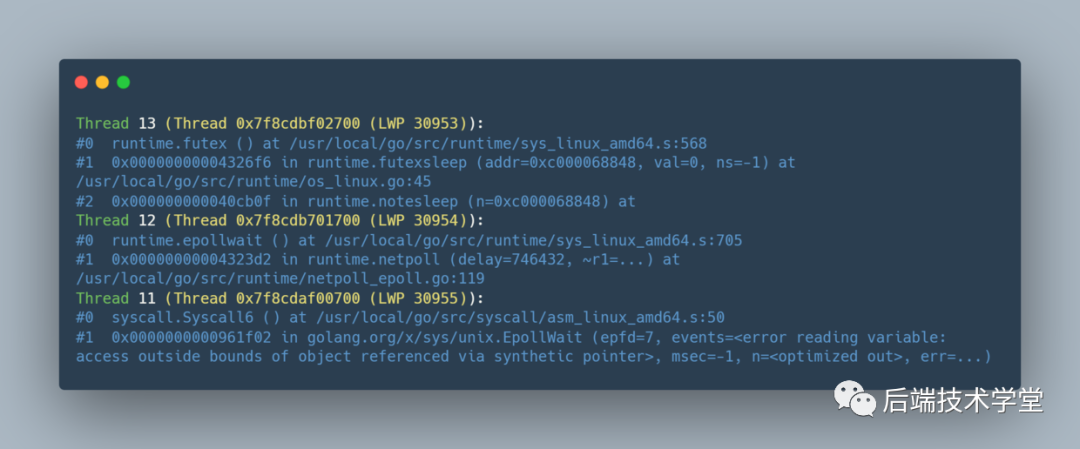
pstack查看lwp
協程
協程的知名度好像不是很高,在以前我們談論高并發,大部分人都知道利用多線程和多進程部署服務,提高服務性能,但一般不會提到協程。其實協程的概念出來的比線程還早,只不過最近才被人們更多的提起。
協程之所以最近被大家熟知,個人覺得是 Python 和 Go 從語言層面提供了對協程更好的支持,尤其是以 Goroutine 為代表的 Go 協程實現,很大程度上降低了協程使用門檻,可以說是后起之秀了!
why 協程
當今無數的 Web 服務和互聯網服務,本質上大部分都是 IO 密集型服務,什么是 IO 密集型服務?意思是處理的任務大多是和網絡連接或讀寫相關的高耗時任務,高耗時是相對 CPU 計算邏輯處理型任務來說,兩者的處理時間差距不是一個數量級的。
IO 密集型服務的瓶頸不在 CPU 處理速度,而在于盡可能快速的完成高并發、多連接下的數據讀寫。
以前有兩種解決方案:
如果用多線程,高并發場景的大量 IO 等待會導致多線程被頻繁掛起和切換,非常消耗系統資源,同時多線程訪問共享資源存在競爭問題。
如果用多進程,不僅存在頻繁調度切換問題,同時還會存在每個進程資源不共享的問題,需要額外引入進程間通信機制來解決。
協程出現給高并發和 IO 密集型服務開發提供了另一種選擇。
當然,世界上沒有技術銀彈。在這里我想把協程這把鑰匙交到你手中,但是它也不是萬能鑰匙,最好的解決方案是貼合自身業務類型做出最優選擇,不一定就選擇一種模型,有時候是幾種模型的組合,比如多線程搭配協程是常見的組合。
什么是協程
那什么是協程呢?協程 Coroutines 是一種比線程更加輕量級的微線程。類比一個進程可以擁有多個線程,一個線程也可以擁有多個協程,因此協程又稱微線程和纖程。
協程圖解
可以粗略的把協程理解成子程序調用,每個子程序都可以在一個單獨的協程內執行。
協程子程序模型
調度開銷
線程是被內核所調度,線程被調度切換到另一個線程上下文的時候,需要保存一個用戶線程的狀態到內存,恢復另一個線程狀態到寄存器,然后更新調度器的數據結構,這幾步操作設計用戶態到內核態轉換,開銷比較多。
線程切換
協程的調度完全由用戶控制,協程擁有自己的寄存器上下文和棧,協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧,直接操作用戶空間棧,完全沒有內核切換的開銷。
協程切換
動態協程棧
協程擁有自己的寄存器上下文和棧,協程調度切換時將寄存器上下文和棧保存下來,在切回來的時候,恢復先前保存的寄存器的上下文和棧。
Goroutine 是 Golang 的協程實現。Goroutine 的棧只有 2KB大小,而且是動態伸縮的,可以按需調整大小,最大可達 1G 相比線程來說既不浪費又靈活了很多,可以說是相當的nice了!
線程也都有一個固定大小的內存塊來做棧,一般會是 2MB 大小,線程棧會用來存儲線程上下文信息。2MB 的線程棧和協程棧相比大了很多。
線程和協程棧對比
協程實現
Python協程實現
python 2.5 中引入 yield/send 表達式用于實現協程,但這種通過生成器的方式使用協程不夠優雅。
python 3.5 之后引入async/await ,簡化了協程的使用并且更加便于理解。
Go語言協程實現
Golang 在語言層面實現了對協程的支持,Goroutine 是協程在 Go 語言中的實現, 在 Go 語言中每一個并發的執行單元叫作一個 Goroutine ,Go 程序可以輕松創建成百上千個協程并發執行。
Go 協程調度器有三個重要數據結構:
G 表示 Goroutine ,它是一個待執行的任務;
M 表示操作系統的線程,它由操作系統的調度器調度和管理;
P 表示處理器 Processor,它可以被看做運行在線程上的本地調度器;
協程調度
Go 調度器最多可以創建 10000 個線程,但可以通過設置 GOMAXPROCS 變量指能夠正常運行的線程數, 這個變量的默認值 等于 CPU 個數,也就是線程數等于 CPU 核數,這樣不會觸發操作系統的線程調度和上下文切換,所有的調度由 Go 語言調度器觸發,都是在用戶態,減少了非常多的調用開銷。
總結
這篇文章講解和對比了進程、線程的概念,同時通過進程窺探到操作系統內存管理的冰山一角,另外還講解了具體到 Linux 系統下線程的實現現狀,順勢引出了輕量級進程的概念。最后著重說明了大部分同學不太了解的協程,通過對比不同的服務模型,帶你了解協程的特點。
? ? ? ?責任編輯:pj












 工商網監
工商網監
評論