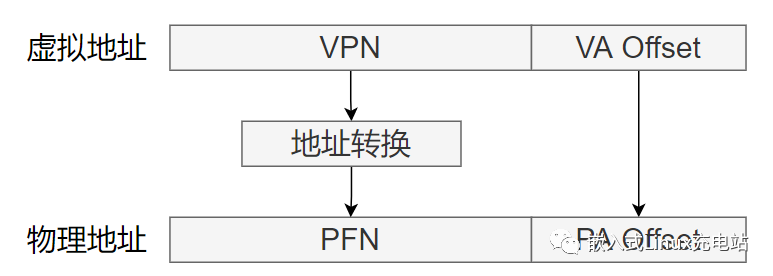
 虛擬內存到物理地址的轉換
虛擬內存到物理地址的轉換
處理器根據頁表基地址控制寄存器TTBCR和虛擬地址來判斷使用哪個頁表基地址寄存器,是TTBR0還是TTBR1。(一個基值是內核的,一個用戶態的)
頁表基地址寄存器中存放著一級頁表的基地址。
處理器根據虛擬地址的bit[31:20]作為索引值()4K頁表,在一級頁表中找到頁表項。一級頁表一共有4 096個頁表項。
第一級頁表的表項中存放有二級頁表的物理基地址。處理器將虛擬地址的
bit[19:12]作為索引值,在二級頁表中找到相應的頁表項。二級頁表有256個頁表項(2^12 * 2^8 * 4kb(2^12)==》32位)。
二級頁表的頁表項里存放有 4KB 頁的物理基地址,加上最后的VA 12位,因此處理器就完成了頁表的查詢和翻譯工作。(將整個4MB分成了4096份256份4KB) (這就是為什么內存越大,頁表項也得越大,不然頁表項的內存就變大的) (表項存的是基地址,而虛擬內存放的都是索引)

圖 7.4 所示為 4KB 映射的一級頁表的表項,bit[1:0]表示一個頁映射的表項,bit[31:10]指向二級頁表的物理基地址。
4KB是2^12
64位的ARM 一般常用的是48,那么只剩36位(其他的位干啥了呢,記住這個問題哈哈哈)
這里還是討論32位
一級頁表4KB頁表--》4GB/4KB---》2^20個頁表項---》32位地址4Byte--》那么這個頁表需要4MB的連續內存
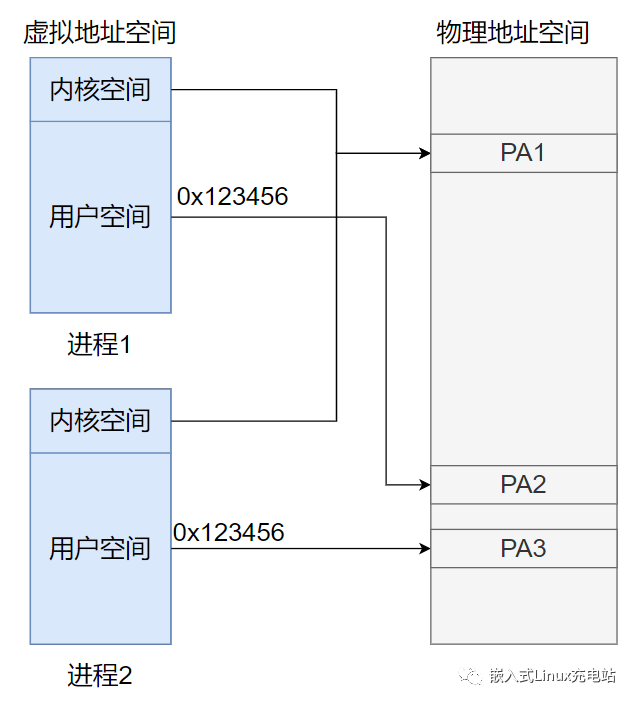
下圖展示兩個進程以及各自的頁表和物理內存的對應關系圖,這里假定頁大小是4K,32位地址總線進程地址空間大小為(2^32)4G,這時候頁表項有 4G /4K = 1048576個,每個頁表項為一個地址,占用4字節,1048576 * 4(B) /1024(M) =4M,也就是說一個程序啥都不干,頁表大小就得占用4M。
如果每個頁表項都存在對應的映射地址那也就算了,但是,絕大部分程序僅僅使用了幾個頁,也就是說,只需要幾個頁的映射就可以了,如下圖,進程1的頁表,只用到了0,1,1024三個頁,剩下1048573頁表項是空的,這就造成了巨大的浪費,為了避免內存浪費,計算機系統開發人員想出了一個方案,多級頁表。

我們先看下圖,這是一個兩級頁表,對應上圖中的進程1。先計算下兩級頁表的內存占用情況。
一級頁表占用= 1024 * 4 B= 4K,
2級頁表占用 = (1024 * 4 B) * 2 = 8K。
總共的占用情況是 12K,相比一級頁表 4M,節省了99.7%的內存占用。
我們來看下兩級頁表為啥能夠節省這么大的內存空間,相比于上圖單級頁表中一對一的關系,兩級頁表中的一級頁表項是一對多的關系,這里是1:1024,這樣就需要 1048576 / 1024 = 1024 個一級頁表項。相當于把上圖的單級頁表分成1024份。一級頁表項PTE0表示虛擬地址頁 0 1023,PTE1表示虛擬地址頁10242047。
如果對應的1024個虛擬地址頁存在任意一個真實的映射,則一級頁表項指向一個二級頁表項,二級頁表項和虛擬地址頁一一對應,在上圖中,進程1的虛擬頁0,1,1024存在映射,0,1虛擬頁屬于這里的PTE0,1024屬于PTE1。一級頁表項中如果為null,表示對應的1024個虛擬頁沒有使用,所以就不需要二級頁表了,節省了空間。
當然,如果虛擬地址頁完全映射的話,多級頁表的占用=一級頁表項(1024 * 4B) + 二級頁表項(1024 * 1024 * 4B) = 4M +4K,比單級映射多了4K,不過這種情況基本上沒有可能,因為進程的地址空間很少有完全映射的情況。正是因為省卻了大量未映射的頁表項使得頁表的空間大幅減少。

其實這個差異就是我以前一來就把全部的虛擬頁表和物理頁表建立了映射關系,那我這個頁表就需要4M。
現在我將這個4M的頁表分成了1024份,需要幾份就申請創建幾份頁表,而不是一來就把所有的頁表都和物理頁面掛上鉤。
然后分成了這1024個,我需要在抽象一層4kb的頁表去指向這1024個頁表各自的基地址。
因為從物理內存層面一層一層的提到最上層的時候,也方便我們對于這個虛擬地址的組成:
一級頁表索引+二級頁表索引+VA(每次頁表的內容都是下一基的基地址) (這個圖片稍微有點理想,一般都是4096 + 256的組合,而不是1014 +
1024的組合,不過大概這個道理就行)
那幾個特殊的位是內存的屬性。這個后面再補充。這個是ARM硬件架構上針對安全內存、設備內存的一些位。
-
處理器
+關注
關注
68文章
19343瀏覽量
230229 -
寄存器
+關注
關注
31文章
5357瀏覽量
120637 -
Linux
+關注
關注
87文章
11319瀏覽量
209832 -
內存
+關注
關注
8文章
3034瀏覽量
74137 -
物理地址
+關注
關注
0文章
7瀏覽量
6257
發布評論請先 登錄
相關推薦
鴻蒙內核源碼分析:物理地址的映射
PIC32在編寫匯編程序和自定義鏈接器文件時位置地址是物理地址還是虛擬地址?
物理內存和虛擬內存之間的轉換
虛擬內存與物理地址有哪些區別
物理地址到虛擬地址的轉換步驟
RT-Thread smart內存虛擬地址到物理地址的轉換是一個什么樣的流程
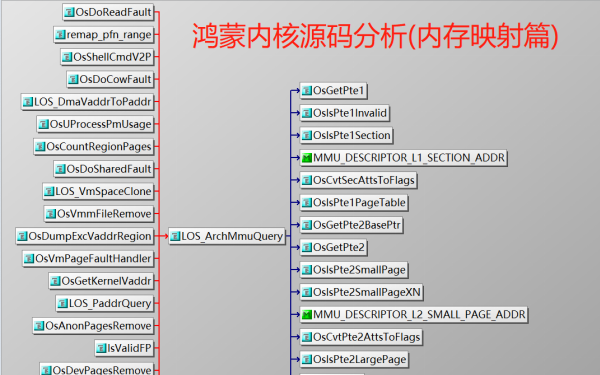
鴻蒙內核中虛擬地址與物理地址之間是如何映射的
Linux虛擬地址空間和物理地址空間的關系





 工商網監
工商網監
評論