完善資料讓更多小伙伴認(rèn)識你,還能領(lǐng)取20積分哦,立即完善>
電子發(fā)燒友網(wǎng)技術(shù)文庫為您提供最新技術(shù)文章,最實(shí)用的電子技術(shù)文章,是您了解電子技術(shù)動(dòng)態(tài)的最佳平臺。
GPU和深度學(xué)習(xí)的結(jié)合對于使人工智能更快、更高效地升級也至關(guān)重要。GPU可以同時(shí)處理大量數(shù)據(jù),從而實(shí)現(xiàn)更快的訓(xùn)練和推理。...
OpenRAN技術(shù)路線理論上可行,產(chǎn)品能夠正常運(yùn)行,但實(shí)際表現(xiàn)仍然不如華為產(chǎn)品,成本也更高。華為通過有機(jī)的系統(tǒng)設(shè)計(jì)路線,將設(shè)備前后級融為一體,實(shí)現(xiàn)了效能的最大化,同時(shí)降低了成本。...

基于多尺度變換(MST)的偏振圖像融合方法研究開始較早且應(yīng)用廣泛。2016年,中北大學(xué)提出一種紅外偏振與強(qiáng)度圖像融合算法,融合結(jié)果能夠保留紅外強(qiáng)度圖像的全部特征和大部分偏振圖像的特征。...

研究者們提出了一個(gè)框架來描述LLMs在處理多語言輸入時(shí)的內(nèi)部處理過程,并探討了模型中是否存在特定于語言的神經(jīng)元。...

Al算力對高效電源提出新需求,背面供電技術(shù)蓄勢待發(fā):越來越高度化的集成會造成針對加速芯片的電源解決方案越來越復(fù)雜,方案需要不同電壓、不同路的多路輸入,這種情況下電壓軌會越來越多。...

更多帶寬 – 隨著需要移動(dòng)大量數(shù)據(jù),我們目睹了所有 DRAM 類型繼續(xù)競相提高數(shù)據(jù)速率以提供更多內(nèi)存帶寬。...
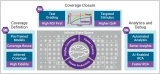
本質(zhì)是讓設(shè)計(jì)人員聚焦于修復(fù)BUG,而不是花時(shí)間發(fā)現(xiàn)BUG。將需要大量人力的工作交給AI,極大的推動(dòng)了覆蓋率收斂的速度。...
傳統(tǒng)的雷達(dá)目標(biāo)檢測方法,主要圍繞雷達(dá)回波信號的統(tǒng)計(jì)特性進(jìn)行建模,進(jìn)而在噪聲和雜波的背景下對目標(biāo)存在與否進(jìn)行判決,常用的典型算法如似然比檢測(LRT)、檢測前跟蹤(TBD)以及恒虛警(CFAR)等。...

循環(huán)神經(jīng)網(wǎng)絡(luò) (RNN) 是一種深度學(xué)習(xí)結(jié)構(gòu),它使用過去的信息來提高網(wǎng)絡(luò)處理當(dāng)前和將來輸入的性能。RNN 的獨(dú)特之處在于該網(wǎng)絡(luò)包含隱藏狀態(tài)和循環(huán)。...
ASR 是自然語言中一項(xiàng)頗具挑戰(zhàn)性的任務(wù),它由語音分割、聲學(xué)建模和語言建模等一系列子任務(wù)組成,根據(jù)噪聲和未分割的輸入數(shù)據(jù)形成預(yù)測(標(biāo)簽序列)。...

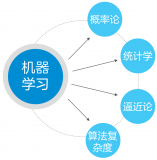
人工智能是由約翰·麥卡錫(John McCarthy)于1956年提出來的,當(dāng)時(shí)的定義是“制造智能機(jī)器的科學(xué)與工程”。 現(xiàn)在的人工智能是指“研究、開發(fā)用于模擬、延伸和擴(kuò)展人的智能的理論、方法、技術(shù)及應(yīng)用系統(tǒng)的一門新的技術(shù)科學(xué)”。...
有監(jiān)督學(xué)習(xí)通常是利用帶有專家標(biāo)注的標(biāo)簽的訓(xùn)練數(shù)據(jù),學(xué)習(xí)一個(gè)從輸入變量X到輸入變量Y的函數(shù)映射。Y = f (X),訓(xùn)練數(shù)據(jù)通常是(n×x,y)的形式,其中n代表訓(xùn)練樣本的大小,x和y分別是變量X和Y的樣本值。...
在人工智能領(lǐng)域,谷歌可以算是開源的鼻祖。今天幾乎所有的大語言模型,都基于谷歌在 2017 年發(fā)布的 Transformer 論文;谷歌的發(fā)布的 BERT、T5,都是最早的一批開源 AI 模型。...

那關(guān)于LLM的長文本能力,目前業(yè)界通常都是怎么做的?有哪些技術(shù)點(diǎn)或者方向?今天我們就來總結(jié)一波,供大家快速全面了解。...
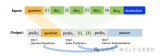
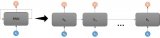
門控網(wǎng)絡(luò)或路由: 這個(gè)部分用于決定哪些令牌 (token) 被發(fā)送到哪個(gè)專家。例如,在下圖中,“More”這個(gè)令牌可能被發(fā)送到第二個(gè)專家,而“Parameters”這個(gè)令牌被發(fā)送到第一個(gè)專家。...
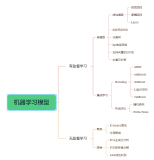
大模型:即基礎(chǔ)模型,在海量數(shù)據(jù)和計(jì)算資源的基礎(chǔ)上通過預(yù)先訓(xùn)練出來的,具有大參數(shù)規(guī)模的深度學(xué)習(xí)模型 >狹義多指大語言模型,廣義還包括CV、多模態(tài)等各種模型類型...
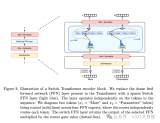
大模型的核心技術(shù)是自然語言處理(NLP)和深度學(xué)習(xí)。具體而言,它基于Transformer架構(gòu),使用了大規(guī)模無監(jiān)督學(xué)習(xí)方法,例如自回歸語言建模和掩碼語言建模,來訓(xùn)練一個(gè)龐大的神經(jīng)網(wǎng)絡(luò)模型。...
圖神經(jīng)網(wǎng)絡(luò)直接應(yīng)用于圖數(shù)據(jù)集,您可以訓(xùn)練它們以預(yù)測節(jié)點(diǎn)、邊緣和與圖相關(guān)的任務(wù)。它用于圖和節(jié)點(diǎn)分類、鏈路預(yù)測、圖聚類和生成,以及圖像和文本分類。...
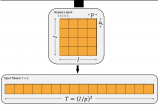
LDM 就是 Stable Diffusion 使用的模型架構(gòu)。擴(kuò)散模型的一大問題是計(jì)算需求大,難以擬合高分辨率圖像。為了解決這一問題,實(shí)現(xiàn) LDM時(shí),會先訓(xùn)練一個(gè)幾乎能無損壓縮圖像的自編碼器,能把 512x512 的真實(shí)圖像壓縮成 64x64 的壓縮圖像并還原。...
自然語言處理領(lǐng)域存在著一個(gè)非常有趣的現(xiàn)象:在多語言模型中,不同的語言之間似乎存在著一種隱含的對齊關(guān)系。...
關(guān)注我們的微信

下載發(fā)燒友APP

電子發(fā)燒友觀察

版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號手機(jī)智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1




