 電子發(fā)燒友App
電子發(fā)燒友App


因?yàn)閘eft_eye_center_x要和right_eye_center_x換位置,我們記錄(0,2),同樣left_eye_center_y要和right_eye_center_y換位置,我們記錄元組(1,3),以此類推。最后,我們獲得元組集合如下:
flip_indices = [
(0, 2), (1, 3),
(4, 8), (5, 9), (6, 10), (7, 11),
(12, 16), (13, 17), (14, 18), (15, 19),
(22, 24), (23, 25),
]
# Let's see if we got it right:
df = read_csv(os.path.expanduser(FTRAIN))
for i, j in flip_indices:
print("# {} -> {}".format(df.columns[i], df.columns[j]))
# this prints out:
# left_eye_center_x -> right_eye_center_x
# left_eye_center_y -> right_eye_center_y
# left_eye_inner_corner_x -> right_eye_inner_corner_x
# left_eye_inner_corner_y -> right_eye_inner_corner_y
# left_eye_outer_corner_x -> right_eye_outer_corner_x
# left_eye_outer_corner_y -> right_eye_outer_corner_y
# left_eyebrow_inner_end_x -> right_eyebrow_inner_end_x
# left_eyebrow_inner_end_y -> right_eyebrow_inner_end_y
# left_eyebrow_outer_end_x -> right_eyebrow_outer_end_x
# left_eyebrow_outer_end_y -> right_eyebrow_outer_end_y
# mouth_left_corner_x -> mouth_right_corner_x
# mouth_left_corner_y -> mouth_right_corner_y
我們的批處理迭代器的實(shí)現(xiàn)將會(huì)從BachIterator類派生,重載transform()方法。把這些東西組合到一起,看看完整的代碼:
from nolearn.lasagne import BatchIterator
class FlipBatchIterator(BatchIterator):
flip_indices = [
(0, 2), (1, 3),
(4, 8), (5, 9), (6, 10), (7, 11),
(12, 16), (13, 17), (14, 18), (15, 19),
(22, 24), (23, 25),
]
def transform(self, Xb, yb):
Xb, yb = super(FlipBatchIterator, self).transform(Xb, yb)
# Flip half of the images in this batch at random:
bs = Xb.shape[0]
indices = np.random.choice(bs, bs / 2, replace=False)
Xb[indices] = Xb[indices, :, :, ::-1]
if yb is not None:
# Horizontal flip of all x coordinates:
yb[indices, ::2] = yb[indices, ::2] * -1
# Swap places, e.g. left_eye_center_x -> right_eye_center_x
for a, b in self.flip_indices:
yb[indices, a], yb[indices, b] = (
yb[indices, b], yb[indices, a])
return Xb, yb
使用上述批處理迭代器進(jìn)行訓(xùn)練,需要把它作為batch_iterator_train參數(shù)傳遞給NeuralNet。讓我們來(lái)定義net3,一個(gè)和net2非常相似的網(wǎng)絡(luò)。僅僅是在網(wǎng)絡(luò)的最后添加了這些行:
net3 = NeuralNet(
# ...
regression=True,
batch_iterator_train=FlipBatchIterator(batch_size=128),
max_epochs=3000,
verbose=1,
)
現(xiàn)在我們已經(jīng)采用了最新的翻轉(zhuǎn)技巧,但同時(shí)我們將迭代次數(shù)增長(zhǎng)了三倍。因?yàn)槲覀儾](méi)有真正改變訓(xùn)練集合的總數(shù),所以每個(gè)epoch仍然使用和剛剛一樣多的樣本個(gè)數(shù)。事實(shí)證明,采用了新技巧后,每個(gè)訓(xùn)練epoch還是比剛剛多用了一些時(shí)間。這次我們的網(wǎng)絡(luò)學(xué)到的東西更具一般性,理論上來(lái)講學(xué)習(xí)更一般性的規(guī)律比學(xué)出過(guò)擬合總是要更難一些。
這次網(wǎng)絡(luò)將花費(fèi)一小時(shí)的訓(xùn)練時(shí)間,我們要確保在訓(xùn)練之后,把得到的模型保存起來(lái)。然后就可以去喝杯茶或者做做家務(wù)活,洗衣服也是不錯(cuò)的選擇。
net3.fit(X, y)
import cPickle as pickle
with open('net3.pickle', 'wb') as f:
pickle.dump(net3, f, -1)
1
2
3
4
5
1
2
3
4
5
$ python kfkd.py
...
Epoch | Train loss | Valid loss | Train / Val
--------|--------------|--------------|----------------
...
500 | 0.002238 | 0.002303 | 0.971519
...
1000 | 0.001365 | 0.001623 | 0.841110
1500 | 0.001067 | 0.001457 | 0.732018
2000 | 0.000895 | 0.001369 | 0.653721
2500 | 0.000761 | 0.001320 | 0.576831
3000 | 0.000678 | 0.001288 | 0.526410
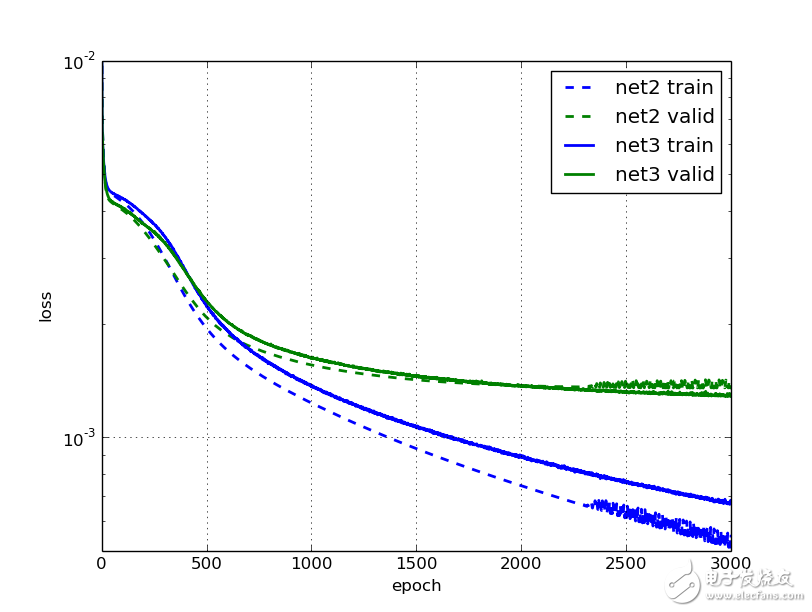
讓我們畫出學(xué)習(xí)曲線和net2對(duì)比。應(yīng)該看到3000次迭代后的效果,net3比net2的驗(yàn)證損失要小了5%。我們看到在2000次迭代之后,net2已經(jīng)停止學(xué)習(xí)了,并且曲線變得不光滑;但是net3的效果卻在一直改進(jìn),盡管進(jìn)展緩慢。












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論