

01 什么是神經網絡?
在介紹卷積神經網絡之前,我們先回顧一下神經網絡的基本知識。就目前而言,神經網絡是深度學習算法的核心,我們所熟知的很多深度學習算法的背后其實都是神經網絡。
神經網絡由節點層組成,通常包含一個輸入層、一個或多個隱藏層和一個輸出層,我們所說的幾層神經網絡通常指的是隱藏層的個數,因為輸入層和輸出層通常是固定的。節點之間相互連接并具有相關的權重和閾值。
如果節點的輸出高于指定的閾值,則激活該節點并將數據發送到網絡的下一層。否則,沒有數據被傳遞到網絡的下一層。關于節點激活的過程有沒有覺得非常相似?沒錯,這其實就是生物的神經元產生神經沖動的過程的模擬。
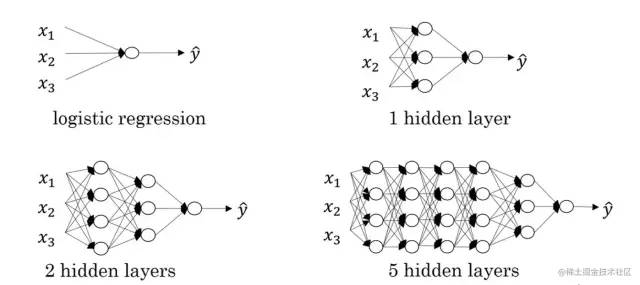
神經網絡類型多樣,適用于不同的應用場景。例如,循環神經網絡(RNN)通常用于自然語言處理和語音識別,而卷積神經網絡(ConvNets或CNN)則常用于分類和計算機視覺任務。
在CNN產生之前,識別圖像中的對象需要手動的特征提取方法。現在,卷積神經網絡為圖像分類和對象識別任務提供了一種更具可擴展性的方法,它利用線性代數的原理,特別是矩陣乘法,來識別圖像中的模式。
但是,CNN的計算要求很高,通常需要圖形處理單元 (GPU) 來訓練模型,否則訓練速度很慢。
02
什么是卷積神經網絡
卷積神經網絡是一種基于卷積計算的前饋神經網絡。與普通的神經網絡相比,它具有局部連接、權值共享等優點,使其學習的參數量大幅降低,且網絡的收斂速度也更快。
同時,卷積運算能更好地提取圖像的特征。卷積神經網絡的基本組件有卷積層、池化層和全連接層。卷積層是卷積網絡的第一層,其后可以跟著其他卷積層或池化層,最后一層是全連接層。越往后的層識別圖像越大的部分,較早的層專注于簡單的特征,例如顏色和邊緣。
隨著圖像數據在CNN的各層中前進,它開始識別物體的較大元素或形狀,直到最終識別出預期的物體。
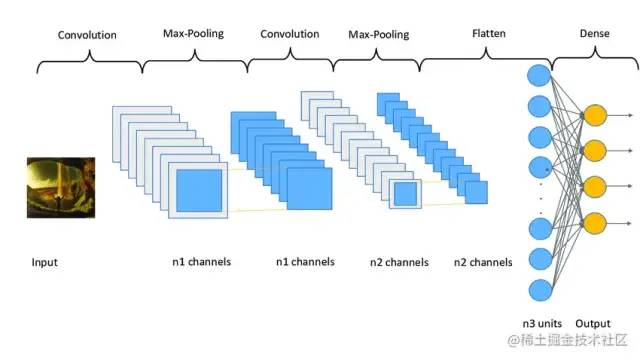
下面將簡單介紹這幾種基本組件的相關原理和作用。
卷積層
卷積層是CNN的核心組件,其作用是提取樣本的特征。它由三個部分組成,即輸入數據、過濾器和特征圖。在計算機內部,圖像以像素矩陣的形式存儲。若輸入數據是一個RGB圖像,則由 3D 像素矩陣組成,這意味著輸入將具有三個維度——高度、寬度和深度。
過濾器,也叫卷積核、特征檢測器,其本質是一個二維(2-D)權重矩陣,它將在圖像的感受野中移動,檢查特征是否存在。
卷積核的大小不一,但通常是一個 3x3 的矩陣,這也決定了感受野的大小。不同卷積核提取的圖像特征也不同。
從輸入圖像的像素矩陣的左上角開始,卷積核的權重矩陣與像素矩陣的對應區域進行點積運算,然后移動卷積核,重復該過程,直到卷積核掃過整個圖像。這個過程就叫做卷積。卷積運算的最終輸出就稱為特征圖、激活圖或卷積特征。
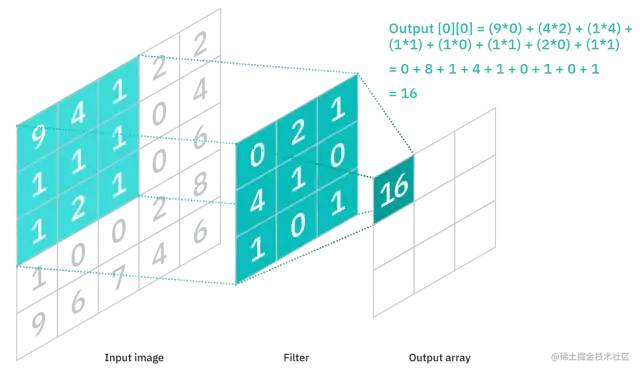
如上圖所示,特征圖中的每個輸出值不必連接到輸入圖像中的每個像素值,它只需要連接到應用過濾器的感受野。由于輸出數組不需要直接映射到每個輸入值,卷積層(以及池化層)通常被稱為“部分連接”層。
這種特性也被描述為局部連接。當卷積核在圖像上移動時,其權重是保持不變的,這被稱為權值共享。一些參數,如權重值,是在訓練過程中通過反向傳播和梯度下降的過程進行調整的。在開始訓練神經網絡之前,需要設置三個影響輸出體積大小的超參數:
過濾器的數量:影響輸出的深度。例如,三個不同的過濾器將產生三個不同的特征圖,從而產生三個深度。
步長(Stride):卷積核在輸入矩陣上移動的距離或像素數。雖然大于等于 2 的步長很少見,但較大的步長會產生較小的輸出。
零填充(Zero-padding):通常在當過濾器不適合輸入圖像時使用。這會將輸入矩陣之外的所有元素設置為零,從而產生更大或相同大小的輸出。有三種類型的填充:
Valid padding:這也稱為無填充。在這種情況下,如果維度不對齊,則丟棄最后一個卷積。
Same padding:此填充確保輸出層與輸入層具有相同的大小。
Full padding:這種類型的填充通過在輸入的邊界添加零來增加輸出的大小。
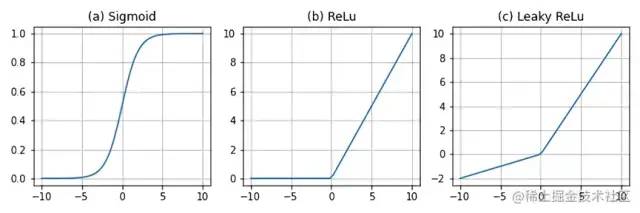
在每次卷積操作之后,CNN的特征圖經過激活函數(Sigmoid、ReLU、Leaky ReLU等)的變換,從而對輸出做非線性的映射,以提升網絡的表達能力。
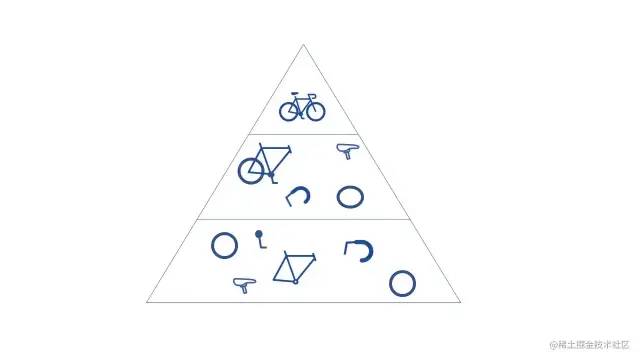
當CNN 有多個卷積層時,后面的層可以看到前面層的感受野內的像素。例如,假設我們正在嘗試確定圖像是否包含自行車。
我們可以把自行車視為零件的總和,即由車架、車把、車輪、踏板等組成。自行車的每個單獨部分在神經網絡中構成了一個較低級別的模式,各部分的組合則代表了一個更高級別的模式,這就在 CNN 中創建了一個特征層次結構。
池化層
為了減少特征圖的參數量,提高計算速度,增大感受野,我們通常在卷積層之后加入池化層(也稱降采樣層)。池化能提高模型的容錯能力,因為它能在不損失重要信息的前提下進行特征降維。
這種降維的過程一方面使得模型更加關注全局特征而非局部特征,另一方面具有一定的防止過擬合的作用。池化的具體實現是將感受域中的值經過聚合函數后得到的結果作為輸出。池化有兩種主要的類型:
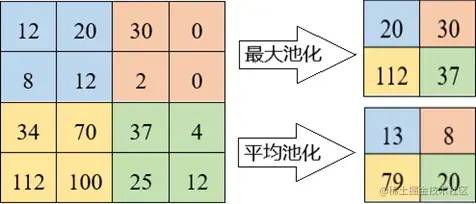
最大池化(Max pooling):當過濾器在輸入中移動時,它會選擇具有最大值的像素發送到輸出數組。與平均池化相比,這種方法的使用頻率更高。
平均池化(Average pooling):當過濾器在輸入中移動時,它會計算感受域內的平均值以發送到輸出數組。
全連接層
全連接層通常位于網絡的末端,其結構正如其名。如前所述,輸入圖像的像素值在部分連接層中并不直接連接到輸出層。但是,在全連接層中,輸出層中的每個節點都直接連接到前一層中的節點,特征圖在這里被展開成一維向量。
該層根據通過前幾層提取的特征及其不同的過濾器執行分類任務。雖然卷積層和池化層傾向于使用ReLu函數,但 FC 層通常用Softmax激活函數對輸入進行適當分類,產生[0, 1]之間的概率值。自定義卷積神經網絡進行手寫數字識別
導包
import time import numpy as np import torch import torch.nn.functional as F from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader if torch.cuda.is_available(): torch.backends.cudnn.deterministic = True
設置參數 & 加載數據集
##########################
### SETTINGS
##########################
# Device
device = torch.device("cuda:3" if torch.cuda.is_available() else "cpu")
# Hyperparameters
random_seed = 1
learning_rate = 0.05
num_epochs = 10
batch_size = 128
# Architecture
num_classes = 10
##########################
### MNIST DATASET
##########################
# Note transforms.ToTensor() scales input images
# to 0-1 range
train_dataset = datasets.MNIST(root='data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='data',
train=False,
transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
break
模型定義
##########################
### MODEL
##########################
class ConvNet(torch.nn.Module):
def __init__(self, num_classes):
super(ConvNet, self).__init__()
# calculate same padding:
# (w - k + 2*p)/s + 1 = o
# => p = (s(o-1) - w + k)/2
# 28x28x1 => 28x28x8
self.conv_1 = torch.nn.Conv2d(in_channels=1,
out_channels=8,
kernel_size=(3, 3),
stride=(1, 1),
padding=1) # (1(28-1) - 28 + 3) / 2 = 1
# 28x28x8 => 14x14x8
self.pool_1 = torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2),
padding=0) # (2(14-1) - 28 + 2) = 0
# 14x14x8 => 14x14x16
self.conv_2 = torch.nn.Conv2d(in_channels=8,
out_channels=16,
kernel_size=(3, 3),
stride=(1, 1),
padding=1) # (1(14-1) - 14 + 3) / 2 = 1
# 14x14x16 => 7x7x16
self.pool_2 = torch.nn.MaxPool2d(kernel_size=(2, 2),
stride=(2, 2),
padding=0) # (2(7-1) - 14 + 2) = 0
self.linear_1 = torch.nn.Linear(7*7*16, num_classes)
for m in self.modules():
if isinstance(m, torch.nn.Conv2d) or isinstance(m, torch.nn.Linear):
m.weight.data.normal_(0.0, 0.01)
m.bias.data.zero_()
if m.bias is not None:
m.bias.detach().zero_()
def forward(self, x):
out = self.conv_1(x)
out = F.relu(out)
out = self.pool_1(out)
out = self.conv_2(out)
out = F.relu(out)
out = self.pool_2(out)
logits = self.linear_1(out.view(-1, 7*7*16))
probas = F.softmax(logits, dim=1)
return logits, probas
torch.manual_seed(random_seed)
model = ConvNet(num_classes=num_classes)
model = model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
模型訓練
def compute_accuracy(model, data_loader):
correct_pred, num_examples = 0, 0
for features, targets in data_loader:
features = features.to(device)
targets = targets.to(device)
logits, probas = model(features)
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
start_time = time.time()
for epoch in range(num_epochs):
model = model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 50:
print ('Epoch: %03d/%03d | Batch %03d/%03d | Cost: %.4f'
%(epoch+1, num_epochs, batch_idx,
len(train_loader), cost))
model = model.eval()
print('Epoch: %03d/%03d training accuracy: %.2f%%' % (
epoch+1, num_epochs,
compute_accuracy(model, train_loader)))
print('Time elapsed: %.2f min' % ((time.time() - start_time)/60))
print('Total Training Time: %.2f min' % ((time.time() - start_time)/60))
模型評估
with torch.set_grad_enabled(False): # save memory during inference
print('Test accuracy: %.2f%%' % (compute_accuracy(model, test_loader)))
輸出如下
Test accuracy: 97.97%
審核編輯:劉清
-
RGB
+關注
關注
4文章
803瀏覽量
59379 -
過濾器
+關注
關注
1文章
436瀏覽量
20057 -
卷積神經網絡
+關注
關注
4文章
369瀏覽量
12113 -
rnn
+關注
關注
0文章
89瀏覽量
7031
原文標題:看完這篇我就不信還有人不懂卷積神經網絡!
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是卷積神經網絡?卷積神經網絡對人工智能和機器學習的意義
詳解深度學習、神經網絡與卷積神經網絡的應用

循環神經網絡卷積神經網絡注意力文本生成變換器編碼器序列表征





 工商網監
工商網監

評論