 電子發燒友App
電子發燒友App


機器學習的基本步驟及實現方式比較
機器學習(Machine Learning)是計算機科學與人工智能的重要分支領域,也是大數據時代的一個重要技術。機器學習的基本思路是模仿人類的學習行為過程,該技術主要采用的算法包括聚類、分類、決策樹、貝葉斯、神經網絡、深度學習等。總體而言,機器學習是讓計算機在大量數據中尋找數據規律,并根據數據規律對未知或主要數據趨勢進行最終預測。在機器學習中,機器學習的效率在很大程度上取決于它所提供的數據集,數據集的大小和豐富程度也決定了最終預測的結果質量。目前在算力方面,量子計算能超越傳統二進制的編碼系統,利用量子的糾纏與疊加特性拓展其對大量數據的運算處理能力,從而能得出更準確的模型參數以解決一些或工業或網絡的現實問題。
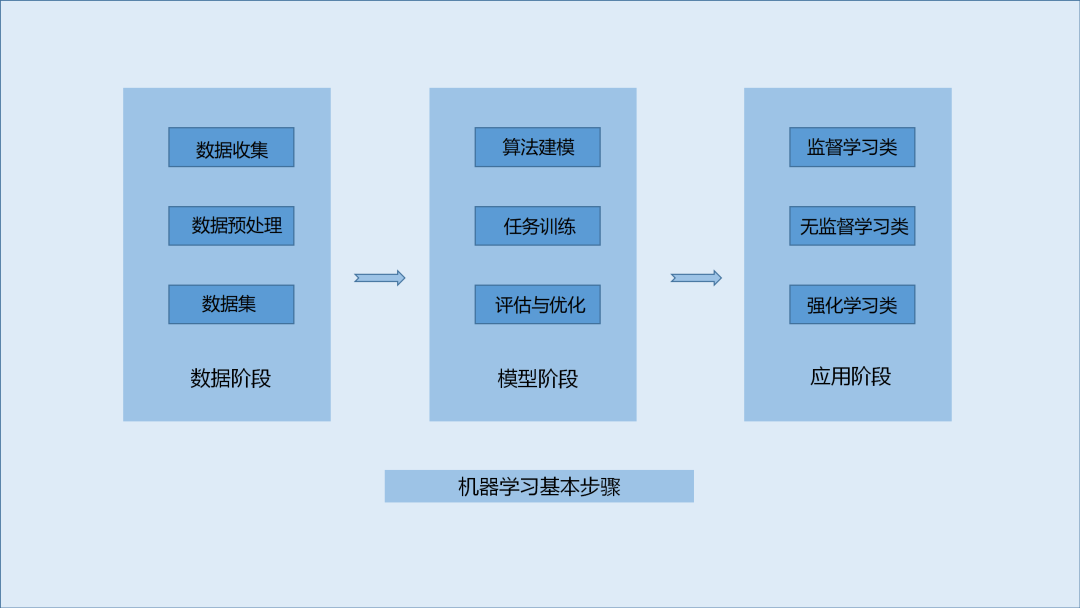
1.數據階段
1.1數據收集與預處理
互聯網時代,每分每秒中都有大量的數據信息產生。大量的數據如同養料一般,沒有源源不斷地數據供應,以數據為基礎發展起來的各種技術如同無源之水缺少發展的活力。數據采集技術已經有了階段性的發展,成熟度相對較高。因此,在提及機器學習、深度學習、自然語言處理等人工智能技術時,數據采集常常被忽略。
數據采集技術也造就了許多以采集數據為主要業務的產品與應用,如作為Hadoop的組件的Flume、開源的數據收集架構Fluentd、Python的爬蟲架構Scrapy等。還有一些數據收集服務平臺如百度統計、阿里云、大數據采集工具八爪魚。
盡管數據時代不缺少數據,但有價值信息的數據即有效數據還需要對大量無序的數據進行數據預處理。未經過數據處理的數據往往存在以下問題:
數據不完整:缺少屬性值或僅僅包含聚集數據;
數據含噪聲:大量數據中包含錯誤或偏離期望的離群值;
數據標簽規則不一:對于數據的分類規則與標準不一致,導致最終收集的數據不屬于同類數據。
數據預處理的方法主要有以下幾種:
數據清洗:對數據進行清洗,以去除噪聲、無關數據、完整性及其欠缺的數據、補充輕微缺損的數據;
數據集成:數據集成多為數據分析的一個環節,數據集成將多個數據源中的數據結合、存放在一個一致的數據存儲,如數據倉庫中,這些數據源可能包括多個數據庫、數據方或一般文件;
數據規約:數據歸約技術可以用來得到數據集的歸約表示,可以盡可能保持原數據的完整性,因而在歸約后的數據集上挖掘將更有效,并產生幾乎相同的分析結果。
1.2數據集準備
數據集準備是使用TensorFlow、Paddle Quantum等進行機器學習的入門基礎。在實際練習或使用過程中,企業的數據相對而言獲取渠道固定、有較清晰的分類,因此在準備數據集時,做好分類后只需要將數據文件轉為機器學習可識別的文件即可。個人練習過程中,數據獲取難度較大,可參考KDnuggets上發表的一篇文章,作者總結了七十多個免費的數據集(http://t.cn/RQJhwSi)。
經處理后的數據制備為數據集。數據集一般可以分為訓練集、驗證集、測試集。其中,訓練集主要用于訓練模型;驗證集主要用于選擇模型,通常在訓練過程中使用訓練集確定一些超參數;測試集主要用于判斷網絡性能的好壞。
數據集的劃分方法一般也為三種,即留出法、交叉驗證法、自助法。留出法是指將數據集 D 劃分成兩份互斥的數據集,一份作為訓練集 S,一份作為測試集 T,在 S 上訓練模型,在 T 上評估模型效果。留出法的優點是簡單好實現,但訓練集和測試集數據分布不一致時易引入偏差,最終影響數據模型評估結果。交叉驗證法是將數據集D劃分為n個互斥的子集。然后每次選用一份數據子集作為測試集,其余的 n-1 份數據子集作為訓練集,迭代n輪得到n個模型,最后將n次的評估結果匯總求平均值得到最終的評估結果。自助法使用有放回的重復采樣方式進行訓練集、測試集的構建。自助采樣即確定所獲取的訓練集樣本數n后,從數據集D中有放回的采樣n次,得到n條樣本的訓練集,最后將未出現過的樣本作為測試集。
2.模型階段
2.1機器學習算法建模
機器學習可為監督學習、無監督學習和強化學習三類。監督學習是指有標簽數據、可進行直接反闊并預測結果的一種學習方式,其主要目標是從有標簽的訓練數據中學習模型,從而對未知的數據做出預測。無監督學習是指數據沒有標簽且數據結構不明確或無數據結構的。無監督學習技術主要目的是在沒有已知結果變量或獎勵函數的指導下,探索數據結構、提取有價值的信息。強化學習的主要目的是開發一個系統,然后通用該系統與環境之間發生交互產生的數據信息提高系統性能。強化學習(RL)分反饋是通過獎勵函數對行動度量的結果,常見的強化學習場景如國際象棋、制造機器人、管理生產規劃、企業決策、物流、電路設計、控制自動駕駛汽車、控制無人機等等。
2.2模型訓練
模型訓練需要進行多輪迭代,每輪迭代需要遍歷一次訓練數據集并從中獲取小批量樣本。獲取樣本后將樣本數據輸入模型中得到預測值,對比預測值與真實值之間的損失函數(loss)。在得到損失函數以后,開始執行梯度反向傳播并根據設置的優化算法更新模型參數。最后模型的訓練效果可通過損失函數值的變化來判斷,當損失函數呈減小趨勢,模型訓練效果越顯著。以spam數據集為例:
將數據分為訓練集和測試集并擬合模型
##codes from https://cloud.tencent.com/developer/article/1787782 library(caret) library(kernlab) data(spam) inTrain <- createDataPartition(y = spam$type, p = 0.75, list = FALSE) training <- spam[inTrain, ] testing <- spam[-inTrain, ] modelFit <- train(type ~., data = training, method="glm")
查看選項:metric選項設置算法評價,連續變量結果為均方根誤差RMSE;R^2^(從回歸模型獲得)分類變量結果為準確性;Kappa系數(用于一致性檢驗,也可以用于衡量分類精度)
##codes from https://cloud.tencent.com/developer/article/1787782 args(train.default) function(x, y, method = "rf", preProcess = NULL, ..., weights = NULL, metric = ifelse(is.factor(y), "Accuracy", "RMSE"), maximize = ifelse(metric == "RMSE", FALSE, TRUE), trControl = trainControl(), tuneGrid = NULL, tuneLength = 3) NULL args(trainControl) function (method = "boot", number = ifelse(grepl("cv", method), 10, 25), repeats = ifelse(grepl("[d_]cv$", method), 1, NA), p = 0.75, search = "grid", initialWindow = NULL, horizon = 1, fixedWindow = TRUE, skip = 0, verboseIter = FALSE, returnData = TRUE, returnResamp = "final", savePredictions = FALSE, classProbs = FALSE, summaryFunction = defaultSummary, selectionFunction = "best", preProcOptions = list(thresh = 0.95, ICAcomp = 3, k = 5, freqCut = 95/5, uniqueCut = 10, cutoff = 0.9), sampling = NULL, index = NULL, indexOut = NULL, indexFinal = NULL, timingSamps = 0, predictionBounds = rep(FALSE, 2), seeds = NA, adaptive = list(min = 5, alpha = 0.05, method = "gls", complete = TRUE), trim = FALSE, allowParallel = TRUE) NULL
trainControl控制訓練方法:設置重抽樣方法,boot:bootstrapping自舉法,boot632:調整的自舉法,cv:交叉驗證 repeatedcv:重復交叉驗證,LOOCV:留一交叉驗證;number選項設置交叉驗證或自舉重抽樣的次數;repeats選項設置重復交叉驗證的重復次數;seed選項設置隨機數種子,可以設置全局隨機數種子,也可為每次重抽樣設置隨機數種子。
##codes from https://cloud.tencent.com/developer/article/1787782 set.seed(1235) modekFit2 <- train(type ~., data = training, method = "glm") modekFit2 Generalized Linear Model 3451 samples 57 predictor 2 classes: 'nonspam', 'spam' No pre-processing Resampling: Bootstrapped (25 reps) Summary of sample sizes: 3451, 3451, 3451, 3451, 3451, 3451, ... Resampling results: Accuracy Kappa 0.9156324 0.8229977
2.3模型評估與優化
在機器學習的算法模型中,參數包括兩類分別為模型參數和超參數。其中模型參數不能人為預先設置,而是通過模型訓練過程中自動生成與更新。另一類參數為超參數。超參數在模型訓練之前就可認為設定,是控制模型結構、功能、效率的一個調節入口。模型訓練過程中產生的損失函數是進行模型評估的一個指標,在模型訓練過程結束后,可根據得到的各指標值對模型進行評估與優化。模型優化中涉及到一個超參數概念,是指在建模時將一些與模型無關的未知量設置為固定參數。常見超參數有學習效率、迭代次數(epoches)、隱層數目、隱層單元數、激活函數、優化器等。
2.4預測或推理
機器學習的預測即在模型中輸入一個預測值,通過模型計算可以得到對應的輸出值,該值即為模型的預測結果。簡單的模型如一般簡單線性回歸y=kx+b。真實值分布在線性模型兩側,輸入一個對應的x值即得到一個對應的y值。
3.SVM算法示例
SVM是一類有監督的分類算法,該算法思想主要為:首先假設樣本空間上有兩類樣本點,SVM算法核心是希望找到一個超平面將兩類樣本分開;在尋找劃分超平面時應盡可能使得兩類樣本到超平面距離最短。
首先,導入依賴,準備算法運行環境
import qiskit import matplotlib.pyplot as plt import numpy as np from qiskit.ml.datasets import ad_hoc_data from qiskit import BasicAer from qiskit.aqua import QuantumInstance from qiskit.circuit.library import ZZFeatureMap from qiskit.aqua.algorithms import QSVM from qiskit.aqua.utils import split_dataset_to_data_and_labels, map_label_to_class_name
?
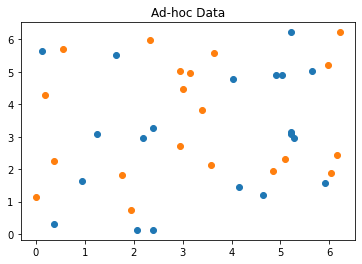
其次,加載并查看數據
feature_dim = 2
training_dataset_size = 20
testing_dataset_size = 10
random_seed = 10598
shot = 10000
sample_Total, training_input, test_input, class_labels = ad_hoc_data(training_size=training_dataset_size,
test_size=testing_dataset_size,
gap=0.3,
n=feature_dim,
plot_data=True)
datapoints, class_to_label = split_dataset_to_data_and_labels(test_input)
print(class_to_label)
?
?
方式一:采用量子后端的方式運行SVM算法
#getting my backend
backend = BasicAer.get_backend('qasm_simulator')
feature_map = ZZFeatureMap(feature_dim, reps=2)
svm = QSVM(feature_map,training_input,test_input,None)
svm.random_seed = random_seed
quantum_instance = QuantumInstance(backend,shots=shot,seed_simulator=random_seed, seed_transpiler=random_seed)
result = svm.run(quantum_instance)
打印訓練中的核心矩陣
print("kernel matrix during the training:")
kernel_matrix = result['kernel_matrix_training']
img = plt.imshow(np.asmatrix(kernel_matrix),interpolation='nearest',origin='upper',cmap='bone_r')

?
?
獲得預測及其精度
predicted_labels = svm.predict(datapoints[0])
predicted_classes = map_label_to_class_name(predicted_labels,svm.label_to_class)
print('ground truth: {}'.format(datapoints[1]))
print('prediction: {}'.format(predicted_labels))
print('testing success ratio: ', result['testing_accuracy'])
輸出預測結果
ground truth: [0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1] prediction: [0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1] testing success ratio: 1.0
由以上輸出可看出,采用量子方式運算SVM算法的精度結果為100%。
方式二:采用經典方式運行SVM算法
使用qiskit中的一個類似Scikit-learn實現
from qiskit.aqua.algorithms import SklearnSVM svm_classical = SklearnSVM(training_input, test_input) result_classical = svm_classical.run()
打印經典方式訓練中的kernel matrix
print("kernel matrix during the training:")
kernel_matrix_classical = result['kernel_matrix_training']
img = plt.imshow(np.asmatrix(kernel_matrix_classical),interpolation='nearest',origin='upper',cmap='bone_r')
?
?
打印預測結果及精度
predicted_labels_classical = svm_classical.predict(datapoints[0])
predicted_classes_classical = map_label_to_class_name(predicted_labels,svm.label_to_class)
print('ground truth: {}'.format(datapoints[1]))
print('prediction: {}'.format(predicted_labels_classical))
print('testing success ratio: ', result_classical['testing_accuracy'])
采用經典方式的SVM算法輸出結果如下:
ground truth: [0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1] prediction: [1. 0. 0. 1. 0. 0. 0. 0. 1. 0. 1. 1. 1. 0. 0. 0. 0. 1. 1. 1.] testing success ratio: 0.65
由以上輸出可看出,采用經典方式運算SVM算法的精度結果為65%。
在SVM算法的分類中,尋找可劃分兩類樣本的超平面通常只能在更高維度上進行,這就涉及到計算高維空間中的樣本點與平面之間的距離。因此,當維度非常大時,樣本點與超劃分平面的距離計算耗費將很大。而內核計算可以獲取數據點后返回一個距離,并可以通過優化內核使樣本點到超平面的距離最大化。這時,量子計算的高效率的計算模式就體現出其優越性,該示例在一定程度上說明了QSVM優于SVM。
編輯:黃飛
?














 工商網監
工商網監
評論