 電子發(fā)燒友App
電子發(fā)燒友App


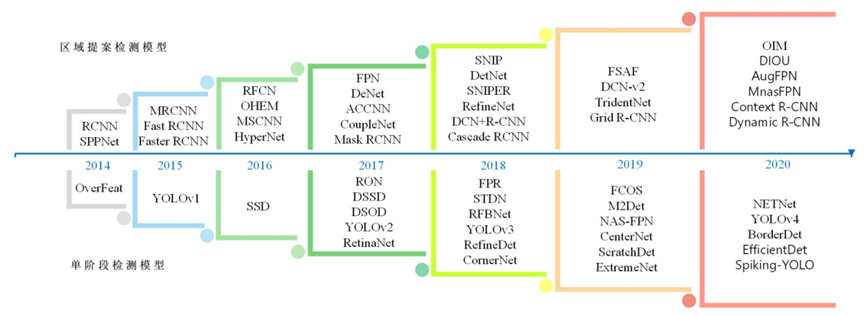
目標(biāo)檢測(cè)是計(jì)算機(jī)視覺領(lǐng)域內(nèi)的熱點(diǎn)課題,在機(jī)器人導(dǎo)航、智能視頻監(jiān)控及航天航空等領(lǐng)域都有廣泛的應(yīng)用.本文首先綜述了目標(biāo)檢測(cè)的研究背景、意義及難點(diǎn),接著對(duì)基于深度學(xué)習(xí)目標(biāo)檢測(cè)算法的兩大類進(jìn)行綜述,即基于候選區(qū)域和基于回歸算法.對(duì)于第一類算法,先介紹了基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)(Region with Convolutional Neural Network,R-CNN)系列算法,然后從四個(gè)維度綜述了研究者在R-CNN系列算法基礎(chǔ)上所做的研究:對(duì)特征提取網(wǎng)絡(luò)的改進(jìn)研究、對(duì)感興趣區(qū)域池化層的改進(jìn)研究、對(duì)區(qū)域提取網(wǎng)絡(luò)的改進(jìn)研究、對(duì)非極大值抑制算法的改進(jìn)研究.對(duì)第二類算法分為YOLO(You Only Look Once)系列、SSD(Single Shot multibox Detector)算法及其改進(jìn)研究進(jìn)行綜述.最后根據(jù)當(dāng)前目標(biāo)檢測(cè)算法在發(fā)展更高效合理的檢測(cè)框架的趨勢(shì)下,展望了目標(biāo)檢測(cè)算法未來(lái)在無(wú)監(jiān)督和未知類別物體檢測(cè)方向的研究熱點(diǎn).
1 引言
目標(biāo)檢測(cè)的主要任務(wù)是從輸入圖像中定位感興趣的目標(biāo),然后準(zhǔn)確地判斷每個(gè)感興趣目標(biāo)的類別.當(dāng)前目標(biāo)檢測(cè)技術(shù)已經(jīng)廣泛應(yīng)用于日常生活安全、機(jī)器人導(dǎo)航、智能視頻監(jiān)控、交通場(chǎng)景檢測(cè)及航天航空等領(lǐng)域.同時(shí)目標(biāo)檢測(cè)是行為理解、場(chǎng)景分類和視頻內(nèi)容檢索等其他高級(jí)視覺問(wèn)題的基礎(chǔ).但是,由于同一類物體的不同實(shí)例間可能存在很大的差異性,而不同類物體間可能非常相似,以及不同的成像條件和環(huán)境因素會(huì)對(duì)物體的外觀產(chǎn)生巨大的影響[1],使得目標(biāo)檢測(cè)具有很大的挑戰(zhàn)性.
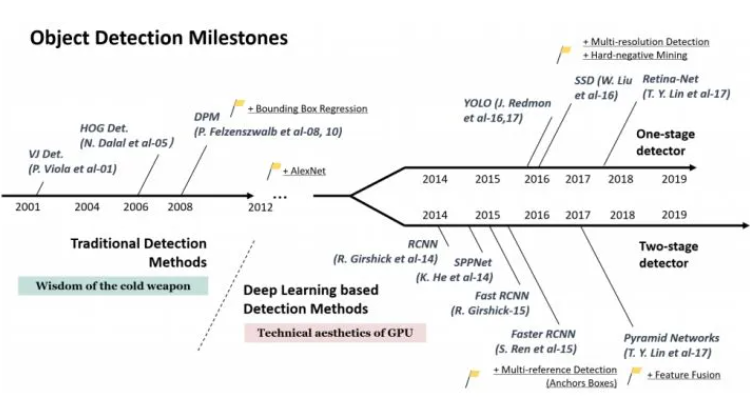
傳統(tǒng)的目標(biāo)檢測(cè)算法采用類似窮舉的滑動(dòng)窗口方式或圖像分割技術(shù)來(lái)生成大量的候選區(qū)域,然后對(duì)每一個(gè)候選區(qū)域提取圖像特征(包括HOG[2]、SIFT[3]、Haar[4]等),并將這些特征傳遞給一個(gè)分類器(如SVM[5]、Adaboost[6]和Random Forest[7]等)用來(lái)判斷該候選區(qū)域的類別.由于傳統(tǒng)方法提取的特征存在局限性,產(chǎn)生候選區(qū)域的方法需要大量的計(jì)算開銷,檢測(cè)的精度和速度遠(yuǎn)遠(yuǎn)達(dá)不到實(shí)際應(yīng)用的要求,這使得傳統(tǒng)目標(biāo)檢測(cè)技術(shù)研究陷入了瓶頸[8].
近些年基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法形成兩大類別:基于候選區(qū)域和基于回歸.基于候選區(qū)域的目標(biāo)檢測(cè)算法也稱為二階段方法,將目標(biāo)檢測(cè)問(wèn)題分成兩個(gè)階段:一是生成候選區(qū)域(region proposal),二是把候選區(qū)域放入分類器中進(jìn)行分類并修正位置.基于回歸的目標(biāo)檢測(cè)算法只有一個(gè)階段,直接對(duì)預(yù)測(cè)的目標(biāo)物體進(jìn)行回歸.
Sharma等人[9,10]僅僅綜述了傳統(tǒng)的目標(biāo)檢測(cè)算法,Chahal等人[11]對(duì)基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法從算法實(shí)現(xiàn)的角度進(jìn)行了綜述,Kemal等人[12]從目標(biāo)檢測(cè)算法中不平衡問(wèn)題的角度進(jìn)行了綜述,Zhao等人[13]從檢測(cè)框架和檢測(cè)子任務(wù)兩個(gè)角度進(jìn)行了綜述.與以上研究綜述不同的是,本文從一個(gè)新穎的角度歸類綜述了近些年目標(biāo)檢測(cè)領(lǐng)域的經(jīng)典算法.在將其分為基于候選區(qū)域和基于回歸兩大類的前提下,對(duì)基于候選區(qū)域的目標(biāo)檢測(cè)算法,介紹基于區(qū)域的卷積神經(jīng)網(wǎng)絡(luò)(Region with Convolutional Neural Network,R-CNN)系列算法的發(fā)展史后,根據(jù)對(duì)不同模塊的改進(jìn)研究進(jìn)行歸類綜述:特征提取網(wǎng)絡(luò)、感興趣區(qū)域池化(Region of Interesting Pooling,ROI Pooling)層、區(qū)域提取網(wǎng)絡(luò)(Region Proposal Networks,RPN)、非極大值抑制(Non Maximum Suppression,NMS).對(duì)基于回歸的目標(biāo)檢測(cè)算法,介紹YOLO(You Only Look Once)系列和SSD(Single Shot Multibox Detector)算法后,對(duì)基于SSD算法的改進(jìn)研究進(jìn)行細(xì)分論述:基于Anchor-based的改進(jìn)研究和基于Anchor-free的改進(jìn)研究.隨后介紹目標(biāo)檢測(cè)領(lǐng)域流行的數(shù)據(jù)集.最后展望未來(lái)目標(biāo)檢測(cè)研究的發(fā)展方向.
2 基于候選區(qū)域的目標(biāo)檢測(cè)算法綜述
本節(jié)主要將近年來(lái)基于候選區(qū)域的目標(biāo)檢測(cè)算法分為五個(gè)部分進(jìn)行綜述,首先介紹了Faster R-CNN[14]框架的發(fā)展歷程,然后綜述了對(duì)Faster R-CNN算法的四個(gè)重要組成部分(特征提取網(wǎng)絡(luò)、ROI Pooling層、RPN、NMS算法)的改進(jìn)研究.
2.1 R-CNN系列基礎(chǔ)框架的發(fā)展史
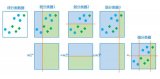
2014年,Girshick等人[15]成功將卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN[16])運(yùn)用在目標(biāo)檢測(cè)領(lǐng)域中,提出了R-CNN算法,它將AlexNet[17]與選擇性搜索[18](selective search)算法相結(jié)合,把目標(biāo)檢測(cè)任務(wù)分解為若干個(gè)獨(dú)立的步驟(如圖1所示),首先采用選擇性搜索算法提取2000個(gè)候選區(qū)域,然后對(duì)每個(gè)候選區(qū)域進(jìn)行歸一化,并逐個(gè)輸入CNN中提取特征,最后對(duì)特征進(jìn)行SVM分類和區(qū)域回歸.
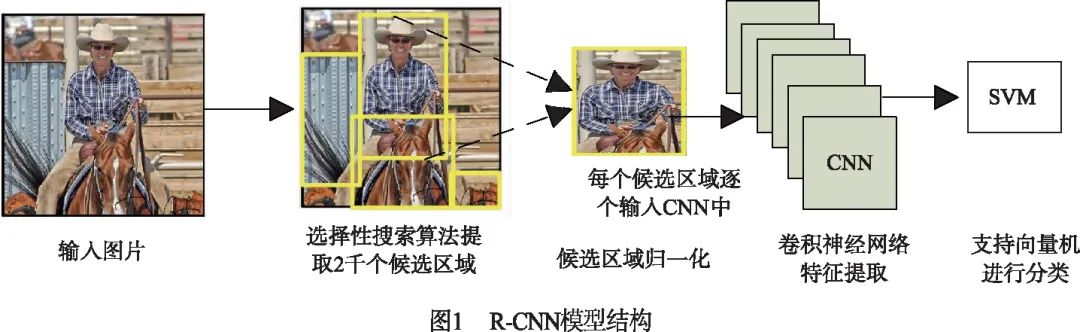
R-CNN[15]算法在PASCAL VOC2007[19]數(shù)據(jù)集上的檢測(cè)精度達(dá)到了58.5%,相較于傳統(tǒng)的目標(biāo)檢測(cè)算法取得了跨越性的進(jìn)展.但還存在非常多的改進(jìn)空間,如:對(duì)于單張圖像提取的2000個(gè)候選區(qū)域需要逐個(gè)輸入CNN中,導(dǎo)致計(jì)算開銷十分巨大,嚴(yán)重影響了檢測(cè)速度;而且候選區(qū)域輸入CNN前,必須剪裁或縮放至固定大小,這會(huì)使候選區(qū)域發(fā)生形變且丟失較多的信息,導(dǎo)致網(wǎng)絡(luò)檢測(cè)精度下降.
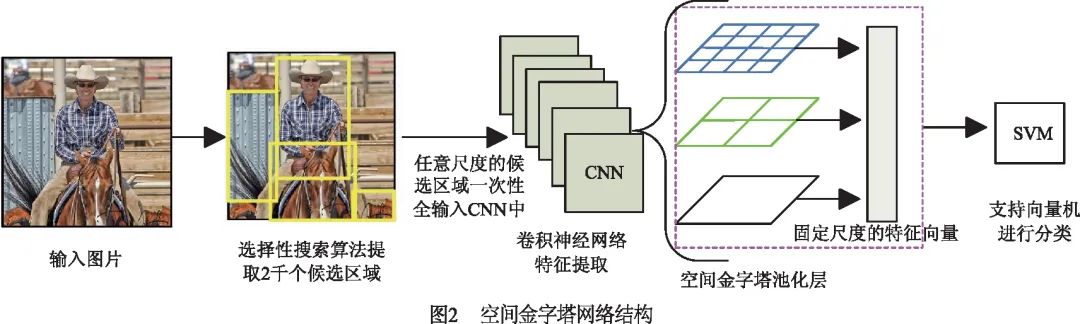
2014年He等人[20]提出了空間金字塔網(wǎng)絡(luò)(Spatial Pyramid Pooling Network,SPP-Net)檢測(cè)算法,它在CNN最后一層卷積層和全連接層之間加入SPP層(如圖2所示),使得網(wǎng)絡(luò)能夠輸入任意尺度的候選區(qū)域,從而每張輸入圖片只需一次CNN運(yùn)算,就能得到所有候選區(qū)域的特征,這使得計(jì)算量大大減少.SPP-Net的檢測(cè)速率比R-CNN快了24~102倍,并打破了固定尺寸輸入的束縛.
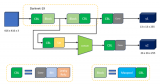
2015年,Girshick等人[21]提出了Fast R-CNN算法(如圖3所示),他們受到SPP-Net算法的啟發(fā),將SPP層簡(jiǎn)化成單尺度的ROI Pooling層以統(tǒng)一候選區(qū)域特征的大小,而且進(jìn)一步提出了多任務(wù)損失函數(shù)思想,將分類損失和邊界框回歸損失統(tǒng)一訓(xùn)練學(xué)習(xí),使得分類和定位任務(wù)不僅可以共享卷積特征,還可以相互促進(jìn)提升檢測(cè)效果.
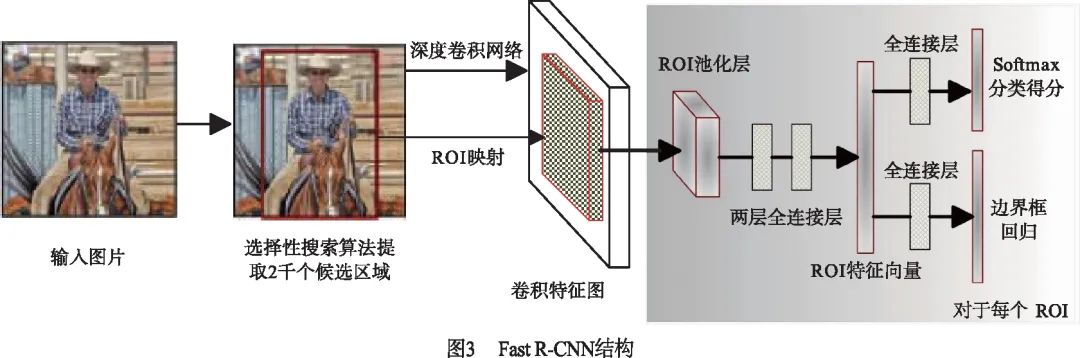
雖然Fast R-CNN有效地加快了檢測(cè)速率,但仍然依賴于選擇性搜索算法[18]來(lái)產(chǎn)生候選區(qū)域.有研究表明,卷積神經(jīng)網(wǎng)絡(luò)的卷積層具有良好的定位目標(biāo)的能力,只是這種能力在全連接層被削弱了.因此,2015年Ren等人[14]提出了Faster R-CNN算法框架(結(jié)構(gòu)如圖4所示),設(shè)計(jì)了輔助生成樣本的RPN取代選擇性搜索算法.RPN是一種全卷積神經(jīng)網(wǎng)絡(luò)(Fully Convolutional Network,F(xiàn)CN[22])結(jié)構(gòu),它將任意大小的特征圖作為輸入,經(jīng)過(guò)卷積操作后產(chǎn)生一系列可能包含目標(biāo)的候選區(qū)域,使算法實(shí)現(xiàn)了端到端的訓(xùn)練,極大提高了檢測(cè)速度.
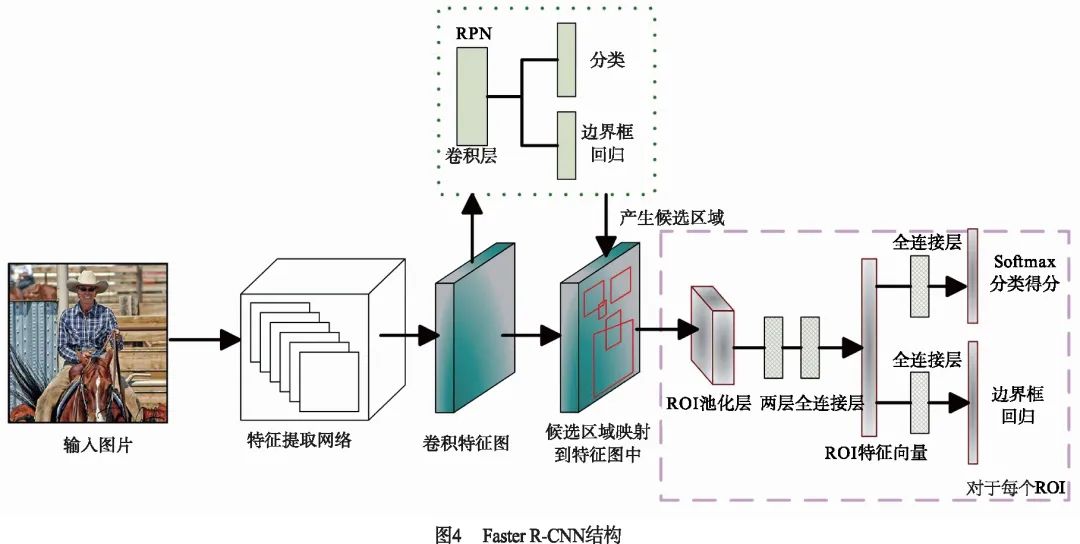
2.2 基于Faster R-CNN的改進(jìn)研究
Faster R-CNN[14]算法在檢測(cè)的精度和速度上都取得了不錯(cuò)的效果.它主要由四個(gè)模塊組成:特征提取網(wǎng)絡(luò)用于提取圖像特征;ROI Pooling層將不同大小的候選區(qū)域特征進(jìn)行歸一化輸出;RPN根據(jù)圖像特征生成目標(biāo)的候選區(qū)域;NMS[23]算法用于去除冗余檢測(cè)框.本小節(jié)綜述了在這四個(gè)功能模塊上的改進(jìn)研究.
2.2.1 對(duì)特征提取網(wǎng)絡(luò)的改進(jìn)研究
深度卷積神經(jīng)網(wǎng)絡(luò)的淺層特征具有豐富的幾何信息,但對(duì)語(yǔ)義信息不敏感,不利于目標(biāo)分類;而高層具有豐富的語(yǔ)義信息,但分辨率太低,不利于目標(biāo)定位.僅利用最后一層卷積層的特征進(jìn)行不同尺度目標(biāo)的預(yù)測(cè),效果顯然是不理想的,所以Faster R-CNN算法對(duì)于小目標(biāo)的檢測(cè)精度較低.針對(duì)這個(gè)問(wèn)題,有許多研究是通過(guò)融合多個(gè)卷積層的特征來(lái)提高小尺度目標(biāo)的檢測(cè)效果.
2016年Kong等人[24]提出了HyperNet算法,通過(guò)融合多層卷積層的特征圖,得到具有多尺度信息的Hyper特征,該特征結(jié)合了卷積層高層的強(qiáng)語(yǔ)義信息、中層的輔助信息以及淺層的幾何信息.同年,Huang等人[25]采用多尺度思想,在特征提取網(wǎng)絡(luò)的高層和低層中提取多個(gè)不同尺度的特征分別進(jìn)行預(yù)測(cè).
2017年Lin等人[26]提出了特征金字塔網(wǎng)絡(luò)(Feature Pyramid Network,F(xiàn)PN),FPN構(gòu)造了一種自頂向下帶有橫向連接的層次結(jié)構(gòu),提取多個(gè)不同尺度特征用于檢測(cè),每個(gè)尺度特征都是高層特征與淺層特征融合所得,不僅具有較強(qiáng)的語(yǔ)義信息,還具有較豐富的幾何信息.
2018年Bharat等人[27]提出了圖像金字塔的尺度歸一化方法(Scale Normalization for Image Pyramids,SNIP).他們借鑒多尺度訓(xùn)練思想,使用圖像金字塔網(wǎng)絡(luò)將圖像生成三種不同分辨率的輸入圖像,高分辨率圖像只用于小目標(biāo)檢測(cè),中等分辨率圖像只進(jìn)行中等目標(biāo)檢測(cè),低分辨率圖像只進(jìn)行大目標(biāo)檢測(cè).
2.2.2 對(duì)感興趣區(qū)域池化層的改進(jìn)研究
ROI Pooling,即感興趣區(qū)域池化是將候選區(qū)域?qū)?yīng)的特征圖劃分成固定數(shù)量的空間小塊,再對(duì)每個(gè)空間小塊進(jìn)行最大池化或者平均池化操作,這樣就實(shí)現(xiàn)了不同尺度的候選區(qū)域能夠輸出同樣大小的特征圖.近年來(lái)的改進(jìn)研究旨在更好保留或融合空間位置信息到ROI池化中,以提高檢測(cè)效果.
2016年Dai等人[28]提出了基于區(qū)域的全卷積神經(jīng)網(wǎng)絡(luò)(Region-based Fully Convolutional Network,R-FCN),他們考慮到目標(biāo)檢測(cè)任務(wù)是由分類任務(wù)和定位任務(wù)組成,分類任務(wù)要求目標(biāo)特征具有平移不變性,而定位任務(wù)要求目標(biāo)特征具有平移敏感性.為了緩解這兩者間的矛盾,提出了位置敏感ROI池化,可以編碼每個(gè)候選區(qū)域的相對(duì)空間位置信息,使得特征具有了對(duì)位置的敏感性.在此基礎(chǔ)上,Zhu等人[29]提出了CoupleNet算法,設(shè)計(jì)了由兩個(gè)分支組成的耦合模塊,一個(gè)分支采用位置敏感ROI池化獲取對(duì)象的局部信息,另一分支則使用兩個(gè)ROI池化分別獲取對(duì)象的全局信息和上下文信息,然后有效的結(jié)合候選區(qū)域的局部信息、全局信息和上下文信息進(jìn)行檢測(cè).
2017年Dai等人[30,31]提出了形變卷積網(wǎng)絡(luò)(Deformation Convolution Network,DCN),設(shè)計(jì)了可形變卷積和可形變ROI池化層.它們的感受野不再是一成不變的正方形,而是和物體的實(shí)際形狀相匹配,緩解了物體形變問(wèn)題,使網(wǎng)絡(luò)學(xué)習(xí)了更多的空間位置信息,增強(qiáng)了定位能力.
2017年He等人[32]提出了Mask R-CNN算法,為了解決特征圖和原始圖像上的感興趣區(qū)域出現(xiàn)不對(duì)準(zhǔn)問(wèn)題提出了ROI Align層,并且增加了Mask預(yù)測(cè)分支,可以并行實(shí)現(xiàn)像素級(jí)的語(yǔ)義分割任務(wù).而2018年Jiang等人[33]進(jìn)一步改進(jìn)了ROI Pooling提出了精準(zhǔn)的感興趣區(qū)域池化(Precise ROI Pooling,PrROI Pooling).ROI Pooling采用的是最近鄰插值方法,它在將ROI映射到特征圖時(shí)和將ROI劃分池化區(qū)域時(shí)都存在取整近似運(yùn)算,會(huì)丟失部分空間位置信息;ROI Align則取消了所有的取整運(yùn)算,采用雙線性插值的方法計(jì)算每個(gè)空間塊的值,但只考慮N個(gè)插值點(diǎn)的值,而且N的大小是預(yù)定義的,不能根據(jù)空間塊的大小進(jìn)行調(diào)整;而PrROI Pooling是采用二階積分的方法對(duì)空間塊進(jìn)行池化操作,使感興趣區(qū)域保持更多的空間位置信息,實(shí)現(xiàn)更精準(zhǔn)定位.
2.2.3 對(duì)區(qū)域提取網(wǎng)絡(luò)的改進(jìn)研究
RPN是Faster R-CNN算法的主要?jiǎng)?chuàng)新點(diǎn),它主要基于Anchor機(jī)制來(lái)產(chǎn)生大量目標(biāo)候選區(qū)域.近年來(lái)的改進(jìn)研究旨在產(chǎn)生更精確的候選區(qū)域,以提高檢測(cè)效果.
2017年,Zhao等人[34]提出了Cascade R-CNN算法,通過(guò)級(jí)聯(lián)三個(gè)區(qū)域交并比(Intersection Over Union,IOU)閾值遞增的R-CNN[15]檢測(cè)模型,對(duì)RPN產(chǎn)生的候選區(qū)域進(jìn)行篩選,留下高IOU值的候選區(qū)域,有效提高了模型的檢測(cè)精度.與此不同,2018年Chen等人[35]在RPN階段引入上下文信息對(duì)候選區(qū)域進(jìn)行微調(diào),使得網(wǎng)絡(luò)定位的更加準(zhǔn)確.
針對(duì)RPN中的Anchor機(jī)制需要人工預(yù)先設(shè)定尺度大小和長(zhǎng)寬比等超參數(shù)的問(wèn)題,2019年,Wang等人[36]提出了Guided-Anchoring方法,通過(guò)圖像特征來(lái)指導(dǎo)Anchor的生成.它由Anchor生成模塊和特征自適應(yīng)模塊組成,其中Anchor生成模塊采用兩個(gè)分支分別預(yù)測(cè)Anchor的位置和形狀:位置預(yù)測(cè)分支預(yù)測(cè)出哪些區(qū)域作為中心點(diǎn)來(lái)生成Anchors;形狀預(yù)測(cè)分支則是根據(jù)位置預(yù)測(cè)分支得到的中心點(diǎn)來(lái)預(yù)測(cè)Anchor最佳的長(zhǎng)和寬.特征自適應(yīng)模塊根據(jù)生成的Anchor的形狀,使用一個(gè)3×3的可形變卷積來(lái)修正特征圖,以適應(yīng)Anchor的形狀.
2.2.4 對(duì)NMS的改進(jìn)研究
NMS算法首先人工設(shè)定一個(gè)IOU閾值,將同一類的所有檢測(cè)框按照分類置信度排序,選取分類置信度得分最高的檢測(cè)結(jié)果,去除那些與之IOU值超過(guò)閾值的相鄰結(jié)果,使網(wǎng)絡(luò)模型在召回率和精度之間取得較好的平衡.
NMS算法采用單一的IOU閾值會(huì)導(dǎo)致漏檢情況發(fā)生,為了解決這個(gè)問(wèn)題,2017年,Bodla等人[37]提出了Soft NMS算法,它不是直接去除那些超過(guò)IOU閾值的相鄰結(jié)果,而是采用線性或者高斯加權(quán)的方式衰減它的置信度值,再選取合適的置信度閾值進(jìn)行檢測(cè)框去重,對(duì)模型的漏檢有了很好的改善.在此基礎(chǔ)上,He等人[38]提出了Softer NMS算法,不是直接選取分類置信度得分最高的檢測(cè)框作為最終檢測(cè)結(jié)果,而是將與分類置信度最高的檢測(cè)框的交并比值大于一定閾值的所有檢測(cè)框的坐標(biāo)進(jìn)行加權(quán)平均,作為最終檢測(cè)結(jié)果,從而能夠更準(zhǔn)確的定位物體.
2018年,Hu等人[39]提出目標(biāo)關(guān)系模塊(Relation Module,RM)替代了NMS算法來(lái)對(duì)目標(biāo)的檢測(cè)框進(jìn)行去除冗余操作.RM借鑒了文獻(xiàn)[40]的思想對(duì)不同目標(biāo)間的關(guān)系進(jìn)行建模,并引入了注意力機(jī)制來(lái)優(yōu)化檢測(cè)效果.同年,Jiang等人[33]發(fā)現(xiàn)檢測(cè)結(jié)果中存在分類置信度和定位準(zhǔn)確度之間不匹配問(wèn)題,所以提出了IOU-guided NMS[33]方法.他們將預(yù)測(cè)的檢測(cè)框與真值間的IOU值作為定位置信度,每一類根據(jù)定位置信度進(jìn)行排序,從而改進(jìn)了NMS過(guò)程,保留了定位更準(zhǔn)確的檢測(cè)框.
針對(duì)常用的邊界框回歸損失函數(shù)(L1范數(shù)或L2范數(shù))與IOU沒有強(qiáng)相關(guān)性,不能很好度量檢測(cè)框準(zhǔn)確性的問(wèn)題,2019年Hamid等人[41]提出了GIOU作為邊界框回歸損失函數(shù),在計(jì)算檢測(cè)框與真值框IOU的基礎(chǔ)上,添加了對(duì)這兩個(gè)框的最小閉包區(qū)域面積的計(jì)算,通過(guò)IOU減去兩框非重疊區(qū)域占最小閉包區(qū)域的比重得到GIOU,其保留了IOU的原始性質(zhì)的同時(shí)弱化了它的缺點(diǎn),對(duì)邊界框的定位能力上有了大幅度的提升.
3 基于回歸的目標(biāo)檢測(cè)算法綜述
基于回歸的目標(biāo)檢測(cè)算法不需要候選區(qū)域生成分支,對(duì)給定輸入圖像,直接在圖像的多個(gè)位置回歸出目標(biāo)的候選框和類別.本文將分成兩大系列來(lái)綜述基于回歸的目標(biāo)檢測(cè)算法:YOLO[42]系列和SSD[43]系列.
3.1 YOLO系列目標(biāo)檢測(cè)算法
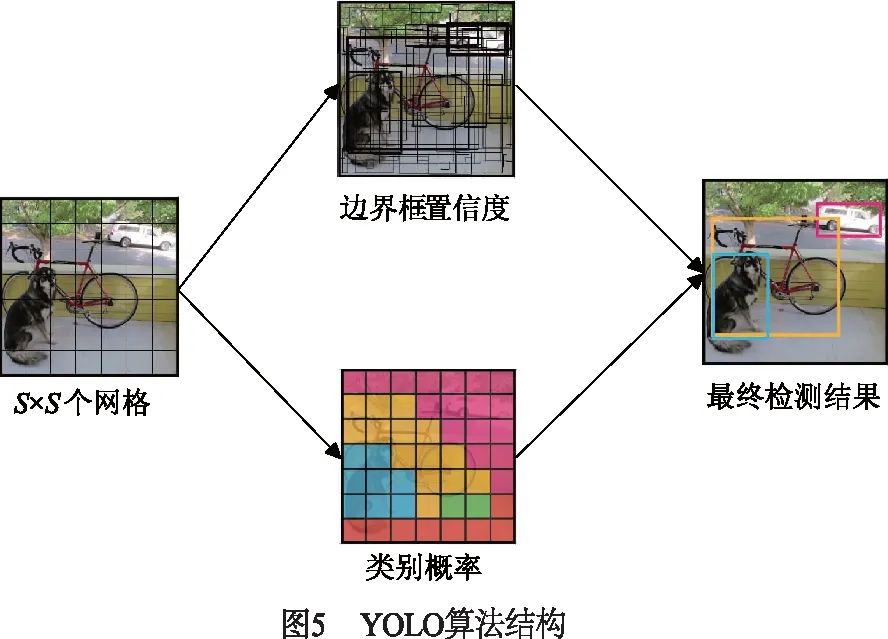
2015年Redmon等人[42]提出了YOLO算法,將分類、定位、檢測(cè)功能融合在一個(gè)網(wǎng)絡(luò)當(dāng)中,輸入圖像只需要經(jīng)過(guò)一次網(wǎng)絡(luò)計(jì)算,就可以直接得到圖像中目標(biāo)的邊界框和類別概率.如圖5所示,YOLO算法將整張輸入圖像劃分成S×S的網(wǎng)格圖,每個(gè)網(wǎng)格只負(fù)責(zé)物體中心落在該網(wǎng)格的目標(biāo)物體以及只預(yù)測(cè)B個(gè)邊界框信息,然后選擇合適的置信度閾值去除那些存在目標(biāo)可能性低的邊界框.雖然YOLO算法完全舍棄了候選區(qū)域生成步驟,極大提高了檢測(cè)速率,能滿足實(shí)時(shí)目標(biāo)檢測(cè)的速度要求,但由于其網(wǎng)絡(luò)設(shè)計(jì)比較粗糙,遠(yuǎn)遠(yuǎn)達(dá)不到實(shí)時(shí)目標(biāo)檢測(cè)的精度要求,而且存在目標(biāo)不能精準(zhǔn)定位、容易漏檢,小目標(biāo)和多目標(biāo)檢測(cè)效果不好等問(wèn)題.
2017年Redmon等人[44]提出了YOLOv2算法,對(duì)YOLO算法進(jìn)行了一系列改進(jìn),重點(diǎn)解決召回率低和定位精度差的問(wèn)題.它借鑒了Faster R-CNN算法的Anchor機(jī)制,移除了網(wǎng)絡(luò)中的全連接層,使用卷積層預(yù)測(cè)檢測(cè)框的位置偏移量和類別信息.而且不同于原Anchor機(jī)制的手工設(shè)計(jì),它利用K-Means聚類方式在訓(xùn)練集中學(xué)習(xí)最佳的初始Anchor模板.不僅如此,YOLOv2添加了一個(gè)pass-through層,將淺層的特征圖連接到深層的特征圖,使網(wǎng)絡(luò)具有了細(xì)粒度特征.此外,YOLOv2可以采用多種數(shù)據(jù)集聯(lián)合優(yōu)化訓(xùn)練的方式,利用WordTree方法在ImageNet[45]分類數(shù)據(jù)集和MS COCO[46]檢測(cè)數(shù)據(jù)集上同步訓(xùn)練,實(shí)現(xiàn)超過(guò)9000個(gè)目標(biāo)類別的實(shí)時(shí)檢測(cè)任務(wù).
2018年Redmon等人[47]提出了YOLOv3算法,它借鑒殘差網(wǎng)絡(luò)中跳躍連接的思路,構(gòu)建了名為DarNet-53的53層基準(zhǔn)網(wǎng)絡(luò),該網(wǎng)絡(luò)只采用3×3和1×1的卷積層,具有與ResNet-152[48]相仿的分類準(zhǔn)確率,但大大減少了計(jì)算量;為了處理多尺度目標(biāo),采用了3種不同尺度的特征圖來(lái)進(jìn)行目標(biāo)檢測(cè),每個(gè)特征圖都是高層與淺層特征圖融合所得;在預(yù)測(cè)類別時(shí),使用Logistic回歸方法代替Softmax方法,使得每個(gè)候選框可以預(yù)測(cè)多個(gè)類別,支持檢測(cè)具有多個(gè)標(biāo)簽的對(duì)象.YOLOv3算法能滿足實(shí)時(shí)檢測(cè)任務(wù)的精度與速率的要求,成為了當(dāng)前工程界首選的目標(biāo)檢測(cè)算法之一.
3.2 SSD系列目標(biāo)檢測(cè)算法
3.2.1 SSD算法
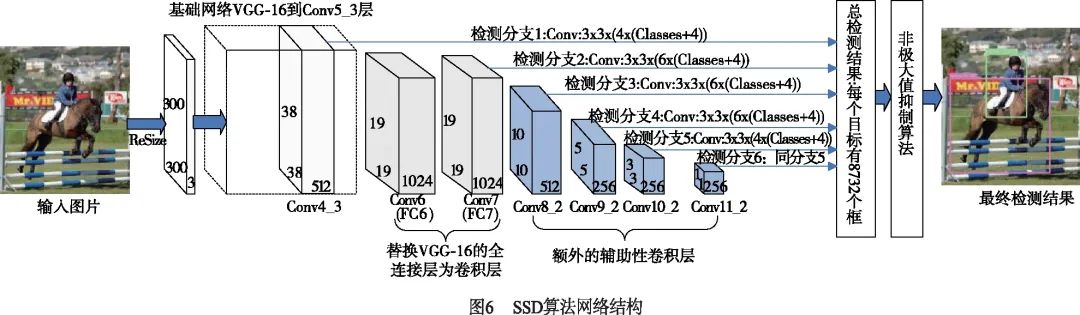
2016年Liu等人[43]提出了SSD算法,在回歸思想的基礎(chǔ)上,有效結(jié)合多尺度檢測(cè)的思想,提取多個(gè)不同尺度的特征圖進(jìn)行檢測(cè),遵循較大的特征圖用來(lái)檢測(cè)相對(duì)較小的目標(biāo),較小的特征圖檢測(cè)較大目標(biāo)的策略,顯著提高了對(duì)大目標(biāo)的檢測(cè)效果,對(duì)小目標(biāo)檢測(cè)也有一定的提升.同時(shí)借鑒Faster R-CNN算法的Anchor機(jī)制,對(duì)提取的特征圖的每個(gè)位置上都預(yù)設(shè)固定數(shù)量的不同尺度和長(zhǎng)寬比的先驗(yàn)框(default boxes),網(wǎng)絡(luò)可以直接在特征圖上進(jìn)行密集采樣提取候選框進(jìn)行預(yù)測(cè),在保持實(shí)時(shí)檢測(cè)速度的同時(shí),提高了模型的定位準(zhǔn)確度.如圖6所示,SSD網(wǎng)絡(luò)是基于全卷積網(wǎng)絡(luò)結(jié)構(gòu),它將基礎(chǔ)網(wǎng)絡(luò)VGG16[49]的全連接層替換為了卷積層,并在VGG16[49]網(wǎng)絡(luò)末端添加了幾個(gè)使特征圖尺寸逐漸減小的輔助性卷積層,用于提取不同尺度的特征圖,而且直接采用卷積操作對(duì)不同尺度的特征圖進(jìn)行檢測(cè).
SSD算法在檢測(cè)的速度和精度上都超越了Faster R-CNN算法,但SSD算法提取的不同卷積層特征獨(dú)立輸入各自的檢測(cè)分支,容易出現(xiàn)同一個(gè)物體被不同大小的邊界框同時(shí)檢測(cè)出來(lái)的情況,即重復(fù)檢測(cè)問(wèn)題.而且每層的檢測(cè)分支僅關(guān)注自己分支上特定尺度的目標(biāo),沒有考慮到不同層、不同尺度目標(biāo)間的關(guān)聯(lián)性,所以對(duì)小目標(biāo)檢測(cè)效果一般.
3.2.2 基于Anchor-based方式的改進(jìn)
2017年Jisoo等人[50]提出了RSSD算法,其在SSD[43]算法的基礎(chǔ)上,對(duì)提取的不同尺度的特征采用了特殊的特征融合方式:對(duì)于每個(gè)特定的尺度特征,分別將比其大的尺度特征進(jìn)行池化操作,比其小的尺度特征進(jìn)行反卷積操作,然后將這些特征進(jìn)行串接融合形成新的特定尺度特征.這種融合方式使得每個(gè)尺度的特征都具有其他尺度的信息,增加了不同層特征圖之間的聯(lián)系,避免了同一目標(biāo)重復(fù)檢測(cè)的問(wèn)題.同年,Cheng等人[51]提出了DSSD算法,將VGG16[49]替換為ResNet101[48],增強(qiáng)了網(wǎng)絡(luò)特征提取能力,并設(shè)計(jì)了兩個(gè)特殊的模塊:預(yù)測(cè)模塊和反卷積模塊.預(yù)測(cè)模塊的結(jié)構(gòu)類似殘差模塊,通過(guò)跳躍連接實(shí)現(xiàn)不同層特征之間的融合,從而提高特征的表征能力.反卷積模塊則是采用反卷積操作建立了一個(gè)Top-to-Down路徑,得到新的不同尺度的特征圖,這些特征圖融合了高層與淺層特征,引入了豐富的空間上下文信息,使得DSSD算法在檢測(cè)精度上有了大幅度的提升,但檢測(cè)速度有較大犧牲.在此基礎(chǔ)上,Lin等人[52]提出了RetinaNet算法,針對(duì)SSD算法因密集采樣導(dǎo)致的難易樣本嚴(yán)重失衡問(wèn)題,提出了Focal Loss函數(shù),其是在交叉熵?fù)p失函數(shù)的基礎(chǔ)上添加了兩個(gè)平衡因子,抑制了簡(jiǎn)單樣本的梯度,將更多的注意力放在難分的樣本上.受Focal Loss的啟發(fā),Li等人[53]提出了梯度協(xié)調(diào)機(jī)制(Gradient Harmonizing Mechanism,GHM)來(lái)解決樣本失衡問(wèn)題,這種機(jī)制可以同時(shí)嵌入分類和回歸損失中來(lái)平衡訓(xùn)練樣本的梯度,不僅減少了易分樣本的關(guān)注,而且避免了特別難分樣本對(duì)模型的負(fù)面影響.
2018年Liu等人[54]提出了RFB-Net算法,通過(guò)模擬人類視覺感受野,設(shè)計(jì)了感受野模塊(Receptive Field Block,RFB)增加網(wǎng)絡(luò)的特征提取能力.RFB結(jié)構(gòu)借鑒了Inception[55]的思想,引入三個(gè)不同擴(kuò)張率的3×3卷積層增大感受野,并且將這三個(gè)卷積的輸出以串接方式進(jìn)行特征融合.此外,Zhang等人[56]提出了RefineDet算法,結(jié)合了一階段和二階段檢測(cè)算法的優(yōu)點(diǎn),設(shè)計(jì)了兩個(gè)模塊:物體檢測(cè)模塊和Anchor微調(diào)模塊,前者對(duì)密集的Anchors進(jìn)行篩選去除一些不包含物體的負(fù)樣本,同時(shí)粗調(diào)篩選后的Anchors位置和尺寸,后者對(duì)物體檢測(cè)模塊輸出的Anchors進(jìn)一步回歸,這使得網(wǎng)絡(luò)進(jìn)行了兩次回歸任務(wù),有效提升了網(wǎng)絡(luò)定位能力,并且樣本的篩選有效緩解了正負(fù)樣本不均衡問(wèn)題.
SSD最新的改進(jìn)研究[57~61]更加關(guān)注于合理和高效的運(yùn)用FPN結(jié)構(gòu),提取具有豐富上下文信息和空間信息的多尺度特征,解決目標(biāo)尺度變化問(wèn)題.Ghaisi等人[58]受到神經(jīng)結(jié)構(gòu)搜索(Neural Architecture Search,NAS)的啟發(fā),提出了NAS-FPN算法,該網(wǎng)絡(luò)模型自動(dòng)搜索設(shè)計(jì)最優(yōu)的FPN結(jié)構(gòu),實(shí)現(xiàn)跨尺度的特征融合,在網(wǎng)絡(luò)性能上超越了Mask R-CNN,但模型的訓(xùn)練需要大量的GPU支持.此外,Zhao等人[59]提出了多層特征金字塔網(wǎng)絡(luò)(Multi-Level Feature Pyramid Network,MLFPN),通過(guò)級(jí)聯(lián)多個(gè)小型的FPN子網(wǎng)絡(luò),形成不同層級(jí)的不同尺度特征,并對(duì)特征進(jìn)行充分的重利用和融合,使網(wǎng)絡(luò)性能和小目標(biāo)檢測(cè)都有很大的提升.
3.2.3 基于Anchor-free方式的改進(jìn)
雖然SSD算法借鑒Anchor機(jī)制的思想大幅度提高了網(wǎng)絡(luò)的定位能力.但Anchor機(jī)制中存在兩個(gè)人工設(shè)計(jì)的超參數(shù):尺度大小和長(zhǎng)寬比.這不僅需要較強(qiáng)的先驗(yàn)知識(shí),而且提取的候選區(qū)域太多,增加了計(jì)算開銷,還引起正負(fù)樣本不均衡問(wèn)題,所以有些研究者提出了Anchor-free的改進(jìn)方法.
2018年,Hei Law等人[62]提出了CornerNet算法,借鑒了文獻(xiàn)[63]對(duì)關(guān)鍵點(diǎn)檢測(cè)的思想,采用Hourglass104網(wǎng)絡(luò)[63]作為特征提取網(wǎng)絡(luò),直接預(yù)測(cè)物體的左上角點(diǎn)和右下角點(diǎn)來(lái)得到檢測(cè)框,將目標(biāo)檢測(cè)問(wèn)題當(dāng)作關(guān)鍵點(diǎn)檢測(cè)問(wèn)題來(lái)解決.在此基礎(chǔ)上,Zhou等人[64]提出了ExtremeNet算法,在關(guān)鍵點(diǎn)選取和關(guān)鍵點(diǎn)組合方式上做出了創(chuàng)新,通過(guò)選取物體上下左右四個(gè)極值點(diǎn)和一個(gè)中心點(diǎn)作為關(guān)鍵點(diǎn),更加直接關(guān)注物體邊緣和內(nèi)部信息,使得檢測(cè)更加穩(wěn)定.Duan等人[65]發(fā)現(xiàn)ConerNet只使用左右角點(diǎn)會(huì)造成大量的誤檢,為了解決這個(gè)問(wèn)題,提出了CenterNet算法,它在CornerNet的基礎(chǔ)上添加了中心點(diǎn)預(yù)測(cè)分支,使得組成一個(gè)物體檢測(cè)框的要求不僅僅是左右角點(diǎn)能夠匹配,而且檢測(cè)框的中心點(diǎn)也要有對(duì)應(yīng)的中心點(diǎn)匹配.
上述的Anchor-free的方法都是基于人體關(guān)鍵點(diǎn)檢測(cè)的思想,使用非常龐大的Hourglass-104[63]網(wǎng)絡(luò)作為特征提取網(wǎng)絡(luò),與此不同的是,Zhi等人[66]提出了基于全卷積的一階段目標(biāo)檢測(cè)器(Fully Convolutional One-Stage object detection,F(xiàn)COS),借鑒語(yǔ)義分割任務(wù)的思想,采用逐像素預(yù)測(cè)方式解決目標(biāo)檢測(cè)問(wèn)題,完全避免了與Anchor相關(guān)的復(fù)雜計(jì)算和超參數(shù)設(shè)計(jì),同時(shí)使用FPN結(jié)構(gòu)實(shí)現(xiàn)多尺度目標(biāo)的預(yù)測(cè),每個(gè)預(yù)測(cè)分支中添加了中心點(diǎn)損失來(lái)抑制中心點(diǎn)偏差大的檢測(cè)框,保證每個(gè)檢測(cè)框盡可能靠近目標(biāo)中心,提高了模型定位能力.
4 相關(guān)數(shù)據(jù)集綜述
當(dāng)前通用目標(biāo)檢測(cè)任務(wù)中流行的數(shù)據(jù)集有:PASCAL VOC2007[19]、PASCAL VOC2012[67]、MS COCO[46]、ImageNet[45]、Open Images[68]、LIVS[69]等.
PASCAL VOC[19,67]數(shù)據(jù)集主要用于圖像分類和目標(biāo)檢測(cè)任務(wù),主要流行的有PASCAL VOC2007[19]數(shù)據(jù)集和PASCAL VOC2012[67]數(shù)據(jù)集.它們包含了20個(gè)常見的類別,每張圖片都有與之對(duì)應(yīng)的XML文件標(biāo)注了每個(gè)待檢測(cè)目標(biāo)的位置和類別.
MS COCO[46]數(shù)據(jù)集用于目標(biāo)檢測(cè)、語(yǔ)義分割、人體關(guān)鍵點(diǎn)檢測(cè)和字幕生成等任務(wù),對(duì)于目標(biāo)檢測(cè)任務(wù),它是挑戰(zhàn)性最大的數(shù)據(jù)集之一.該數(shù)據(jù)集中的目標(biāo)大部分來(lái)自于自然場(chǎng)景,包含日常復(fù)雜場(chǎng)景的圖像,而且在進(jìn)行評(píng)估時(shí)使用更加嚴(yán)格的評(píng)估標(biāo)準(zhǔn),要求算法具有更精確的定位能力.該數(shù)據(jù)集使用JSON格式的標(biāo)注文件給出每張圖片中目標(biāo)像素級(jí)別的分割信息,而且數(shù)據(jù)集中共包含80個(gè)對(duì)象類別的待檢測(cè)目標(biāo),目標(biāo)間的尺度變化大,具有較多的小目標(biāo)物體.
ImageNet[45]數(shù)據(jù)集用于圖像分類、目標(biāo)檢測(cè)和場(chǎng)景分類等任務(wù),包含約1420萬(wàn)張圖片,2.2萬(wàn)個(gè)類別,其中約103萬(wàn)張圖片擁有明確的類別標(biāo)注和物體的位置標(biāo)注.對(duì)于目標(biāo)檢測(cè)任務(wù),它是具有200個(gè)對(duì)象類別的重要數(shù)據(jù)集,每張圖片的批注都以PASCAL VOC數(shù)據(jù)格式保存在XML文件中.
Open Images[68]數(shù)據(jù)集是對(duì)圖像分類、目標(biāo)檢測(cè)、視覺關(guān)系檢測(cè)和實(shí)例分割等任務(wù)具有統(tǒng)一注釋的單個(gè)數(shù)據(jù)集,對(duì)于目標(biāo)檢測(cè)任務(wù),它總共包含190萬(wàn)張圖片和針對(duì)600個(gè)對(duì)象類別的1600萬(wàn)個(gè)邊界框,是具有對(duì)象位置注釋的最大現(xiàn)有數(shù)據(jù)集.
LIVS[69]數(shù)據(jù)集是2019年提出的大型實(shí)例分割數(shù)據(jù)集,包含了1000多個(gè)類別,164000張圖像,220萬(wàn)個(gè)高質(zhì)量的實(shí)例分割掩碼,這是即將應(yīng)用于目標(biāo)檢測(cè)領(lǐng)域的全新數(shù)據(jù)集,而且LIVS數(shù)據(jù)集中每個(gè)對(duì)象類別的訓(xùn)練樣本很少,旨在用于目標(biāo)檢測(cè)在低樣本數(shù)量條件下的研究.
5 總結(jié)和展望
目標(biāo)檢測(cè)是一個(gè)十分重要的研究領(lǐng)域,具有廣泛的應(yīng)用前景.本文將近些年涌現(xiàn)的基于深度學(xué)習(xí)的目標(biāo)檢測(cè)算法分為基于候選區(qū)域和基于回歸的前提下,對(duì)這兩類算法從發(fā)展及不同方向的改進(jìn)研究角度進(jìn)行了詳細(xì)的綜述.并介紹了目前目標(biāo)檢測(cè)領(lǐng)域流行的數(shù)據(jù)集.雖然當(dāng)前目標(biāo)檢測(cè)算法在實(shí)際生活中得到了廣泛應(yīng)用,但依然存在許多挑戰(zhàn),未來(lái)目標(biāo)檢測(cè)算法在以下幾個(gè)方面值得進(jìn)一步研究:
一是如何有效的結(jié)合上下文信息,解決小目標(biāo)和被遮擋目標(biāo)在復(fù)雜現(xiàn)實(shí)場(chǎng)景的檢測(cè);二是探索更優(yōu)的或?qū)iT為檢測(cè)任務(wù)設(shè)計(jì)的特征提取網(wǎng)絡(luò),以及更優(yōu)的檢測(cè)框選定方法;三是現(xiàn)在的目標(biāo)檢測(cè)算法都是基于監(jiān)督學(xué)習(xí),現(xiàn)實(shí)中存在海量沒有標(biāo)注的數(shù)據(jù),所以研究如何采用弱監(jiān)督學(xué)習(xí)的目標(biāo)檢測(cè)算法是非常有價(jià)值的;四是探索如何從已知類別的目標(biāo)檢測(cè),結(jié)合有效語(yǔ)義信息,遷移到未知類別的目標(biāo)檢測(cè)也是一個(gè)值得研究的方向.
編輯:黃飛














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論