 電子發燒友App
電子發燒友App


目前機器學習是研究車輛網絡入侵檢測技術的熱門方向,通過引入機器學習算法來識別車載總線上的網絡報文,可實現對車輛已知/未知威脅的入侵檢測。這種基于機器學習的異常檢測技術普適性較強,無需對適配車型進行定制化開發,但存在異常樣本采集數量大和訓練難度高的問題。本文將結合個人經驗對基于機器學習的汽車CAN總線異常檢測方法展開具體介紹。
01
車載異常檢測流程
基于機器學習的車載異常檢測的整體流程如圖1所示,其中關鍵環節包括輸入數據、數據預處理、訓練及測試算法、評估及優化。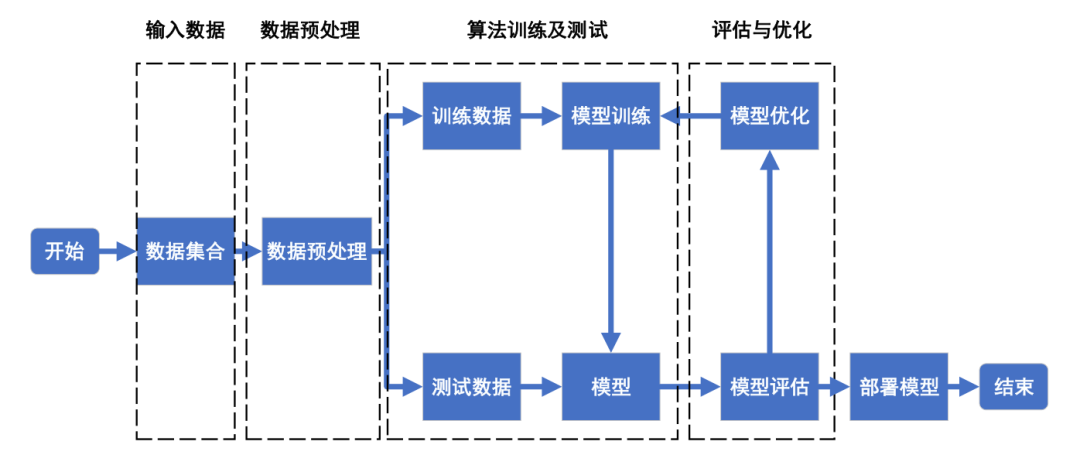
圖1 基于機器學習的車載異常檢測整體流程
02
數據源
針對特定車型進行數據的采集,形成有特點的定制化數據集,并用此數據集進行智能算法的訓練與驗證。在實際應用中,工程師可以直接采用公開數據集作為模型訓練的數據,也可以通過實際采集車輛真實數據來獲取數據集。
公開數據集:公開數據集CAR-HACKING DATASET[1]中提供了汽車黑客數據,如圖2所示,其中包括 DoS 攻擊、模糊攻擊、驅動齒輪欺騙攻擊和RPM儀表欺騙攻擊四種類別的數據。該數據集是通過在執行消息注入攻擊時利用真實車輛的OBD-II端口記錄CAN流量來構建的。
其數據集特征包括Timestamp,CAN ID,DLC(數據長度碼),data(CAN數據字段),Flag(T或R,T代表注入信息,R代表正常信息)。公開數據集一般是經過公開驗證的,更具有通用性和代表性,便于進行不同算法異常檢測效果的比對。
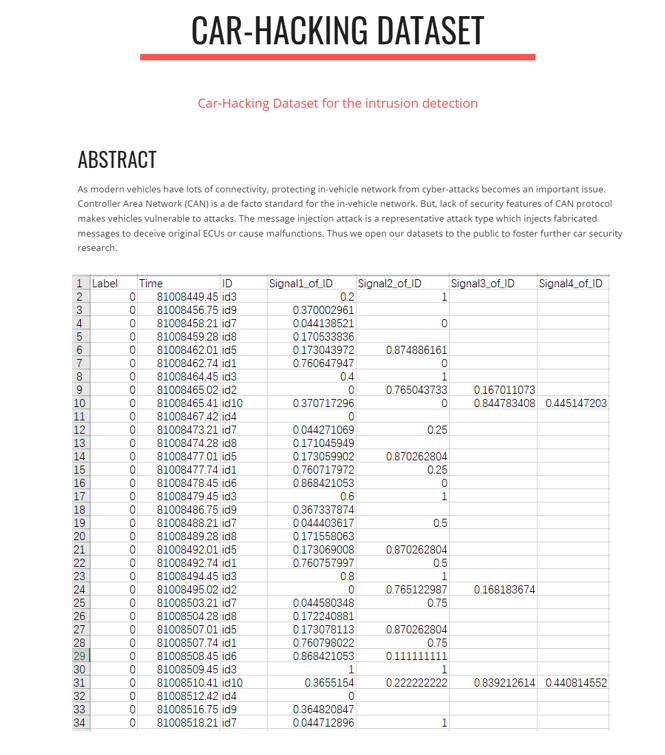
圖2??CAR-HACKING DATASET[1]
實車數據集:數據源還可以通過實車采集的方式獲取,通過向車內注入特定的攻擊,并使用CAN采集工具對實車數據中的報文數據進行采集,采集時需要注意采集時間要盡可能平均。由此得到的實車數據集更加真實,其中可能包含一些公開數據集無法覆蓋的異常場景。此外,實車數據采集得到的數據集通常還需要進行預處理工作。
2.1?數據預處理
機器學習算法模型的質量很大程度取決于數據的質量。原始數據往往不利于模型的訓練,因此需要進行數據預處理以提高數據的質量,使其更好地適用模型。數據預處理過程一般包括特征選取、數據標準化及特征編碼,如圖3所示。在實際車載異常檢測應用中,最終選用的數據預處理方法通常會根據智能算法的不同而有所差異。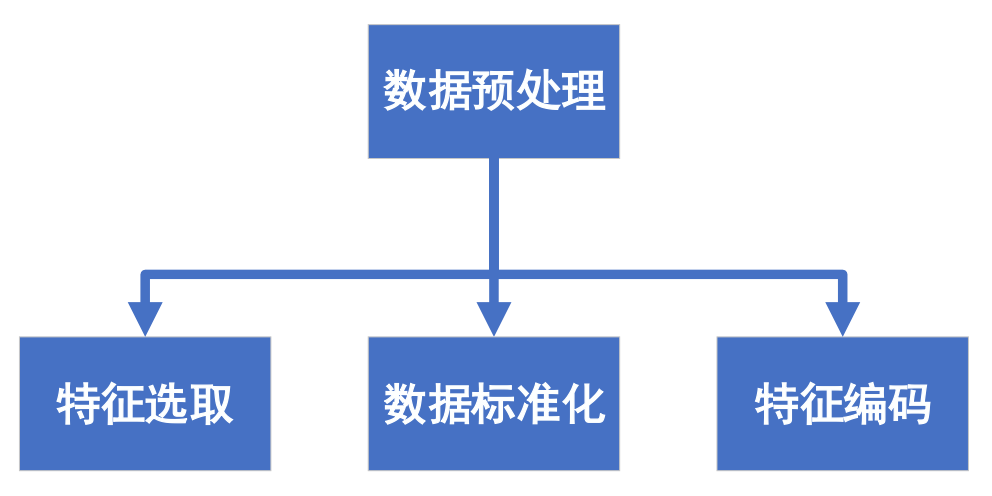
圖3 數據處理過程
2.2?特征選取
CAN報文的特征及描述如表1所示。記錄每一條數據的時間標識Time,每一條報文的序號為CAN ID,相同CAN ID報文出現的時間間隔為period。Payload部分通常將十六進制的信息轉換為十進制,根據CAN報文的特點,將payload劃分為8個特征位(byte0,byte1, byte2, byte3, byte4, byte5, byte6, byte7),它們全部分布在0~255之間。 一般輸入數據格式為Dataframe格式,對應的特征是Dataframe的列名稱。在進行不同算法的訓練時,選取包含指定特征值(某些列)的Dataframe進行后續數據標準化的操作。
表1 CAN報文特征
2.3?數據標準化
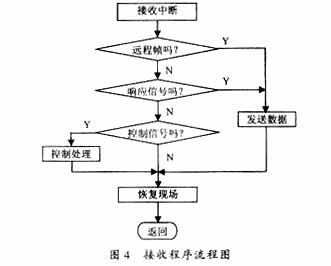
車載網絡報文的數據信號(數據payload部分)具有不同的量綱和取值范圍,通過標準化,在不改變樣本數據分布的同時,使得這些數值信號能夠進行比較。對于利用梯度下降的模型,數值型數據進行標準化可以削弱不同特征對模型的影響差異,使得梯度下降能更快地找到最優解,同時結果更可靠。對于決策樹這類不通過梯度下降而利用信息增益比的算法,則不需要進行數據標準化,整體流程如圖4所示。
標準化對樣本的payload特征分別進行計算使其滿足正態分布,Z=? (x- μ)/σ。一般情況下,標準化與數據分布相關,具有更強的統計意義,在車載入侵檢測數據的處理上更加通用合適。對于需要數據標準化的算法,使用Scikit-learn中preprocessing.StandardScaler(df)函數,df為需要標準化的數據(只含有payload部分的Dataframe),得到標準化后的數據特征編碼或直接進行訓練。

圖4 數據標準化流程
2.4?特征編碼
車載網絡報文中,數據場以外還存在一部分報文內容,如CAN ID。對于很多機器學習算法,分類器往往默認數據是連續的,并且是有序的,因此需要對此類特征進行編碼。對于維度較低的特征可以直接使用獨熱編碼。對于維度較高的特征,可以使用二進制編碼。 獨熱編碼是用等同于狀態數量的維度進行編碼,每種狀態下的獨熱編碼只有其中一位為1,其余均為0。編碼后的特征互斥,每次只有一個激活,有利于模型處理數據。 輸入數據集,如CAN ID經過one_hot(df)函數,將輸入數據進行one-hot編碼。一個CAN ID將變為16*3的向量,如圖5所示。該向量將作為訓練模型的輸入,進行后續的模型訓練工作。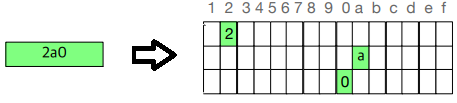
圖5 CAN ID 特征編碼[1]
03
算法訓練及測試
3.1?數據集劃分
輸入數據集以71.5的比例劃分成訓練集、驗證集和測試集。訓練集數據只用來訓練模型,其數據不出現在算法測試中。驗證集主要是用來反映訓練得到模型的相關效果,也會在其上進行算法模型的優化與調試,反復驗證直到達到最佳效果。測試集主要表現模型的最終效果,測試集數據也是用來評價模型的數據,測試集數據不出現在算法訓練中。
數據集劃分流程如圖6所示,首先輸入數據采用Scikit-learn中model_selection.train_test_split()函數,此函數可以將數據集先劃分成7:3的訓練集和測試數據,然后再將測試數據集劃分成5:5的驗證集與測試集。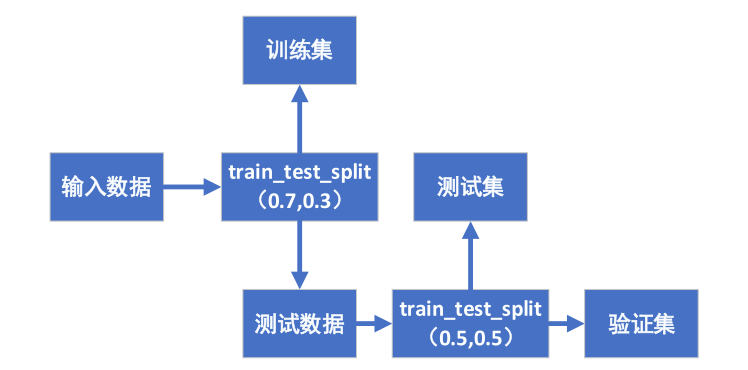
圖6 數據集劃分流程
3.2?SMOTE采樣
對于采集到的車載網絡數據,攻擊報文數量遠少于正常報文,造成了樣本類別不平衡。機器學習中往往假定訓練樣本各類別是同等數量,即各類樣本數目是均衡的。一般來說,不平衡樣本會導致訓練模型側重樣本數目較多的類別,而“輕視”樣本數目較少類別,這樣模型在測試數據上的泛化能力就會受到影響。通過SMOTE[2](合成少數類過采樣技術),在少數類別樣本之間進行插值生成新的樣本,如圖7。相比隨機過采樣,SMOTE大大降低了過擬合的可能。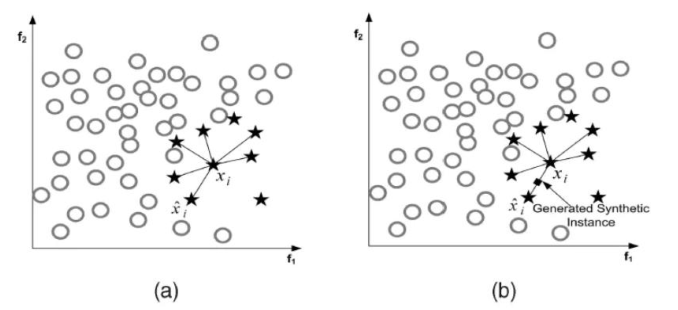
圖7 SMOTE采樣原理?[2]
在訓練模型前對各類別的訓練數據進行SMOTE過采樣的操作,SMOTE過采樣流程如圖8。使用imblearn.over_sampling中的SMOTE().fit_resample(X,Y)函數,其中X為輸入需要訓練的報文集合,Y為X中每一條報文的類別。經過SMOTE處理,各類別的報文數量會變得一樣多,可以進行下一步的操作。
圖8 SMOTE采樣流程
3.3?模型訓練
模型訓練是從標簽化訓練數據集中推斷出函數的機器學習任務。常用的模型訓練算法包括RNN(Recurrent Neural Network,循環神經網絡)、LSTM(Long Short-Term Memory,長短期記憶網絡)、GRU(Gated Recurrent Units,門控循環神經網絡)、DCNN(Dynamic Convolution Neural Network,深度卷積神經網絡)、SVM(Support Vector Machine,支持向量機)、DT(Decision Tree,決策樹)、RF(Random Forest,隨機森林)、XGBoost(Extreme Gradient Boosting,極端梯度提升)、Stacking(集成學習算法)、Clustering(聚類)等。
04
評估與優化
模型的總體優化流程如圖9所示,對模型測試的結果進行評估,根據評估的結果進一步優化模型。下面詳細闡述評估指標和優化方式。
4.1?評估指標
方案使用平均準確率、P-R曲線、F-score對模型進行評價。平均準確率是判斷入侵檢測算法優劣的最直觀的評價標準。P-R曲線和F-score能更加直觀地反映入侵檢測模型在特定數據集上的表現。本方案選擇平均準確率作為模型在驗證集上的評價指標,在超參數調優時,根據平均準確率選擇更優超參數組合。本方案選擇F-score作為模型在測試集上的評價指標,評價最終的模型效果。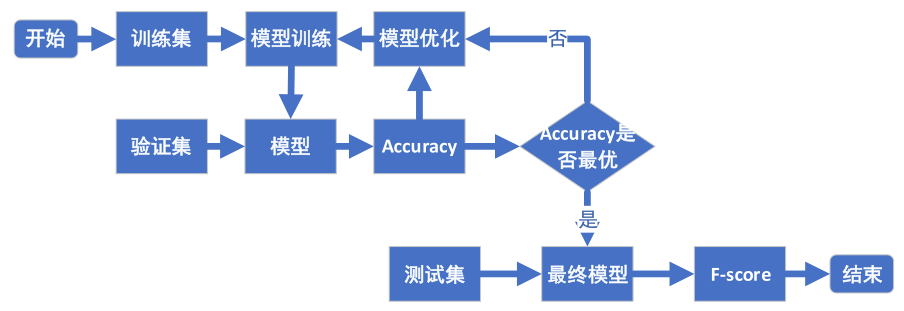
圖9 模型優化流程
a)準確率 Accuracy
準確率公式為: Accuracy = (TP + TN) / (TP + TN + FP + FN) 其中,TP(true positive)是正例,代表被模型正確地預測為正類別的樣本。例如,模型推斷出某條報文是攻擊報文,而該報文確實是攻擊報文。TN(true negative)為假正例,代表被模型正確地預測為負類別的樣本。例如,模型推斷出某條報文不是攻擊報文,而該報文確實不是攻擊報文。FN (false negative)是假負例,代表被模型錯誤地預測為負類別的樣本。例如,模型推斷出某條報文不是攻擊報文(負類別),但該條報文其實是攻擊報文。
FP(false positive)為假正例,代表被模型錯誤地預測為正類別的樣本。例如,模型推斷出某條報文是攻擊報文(正類別),但該條報文其實不是攻擊報文。 準確率是指分類正確的樣本占總樣本個數的比例。在不同類別的樣本比例非常不均衡時,占比大的類別將成為影響準確率的主要因素。導致模型整體準確率很高,但是不代表對小占比類別的分類效果很好。
因此,使用平均準確率,即每個類別下的樣本準確率的算術平均作為模型評估的指標。 在超參數選擇階段,算法會根據各個超參數的準確率Accuracy,進行選擇。選擇準確率最高的超參數作為模型使用的超參數。
b)P-R曲線和F-score?
精確率P = TP / (TP+FP),指分類正確的正樣本個數占分類器判定為正樣本的樣本個數的比例。召回率R = TP / (TP+FN),指分類正確的正樣本個數占真正的正樣本個數的比例。通過F-score進行定量分析,同時考慮了精確率和召回率。? F-score =(1+β^2 )*P*R/(β^2*P+R) 智能分析使用F1-score作為指標,評價最終模型在測試集上的表現效果。
4.2?模型優化
入侵檢測使用到的機器學習和神經網絡模型包含大量的超參數,超參數直接影響了模型的優劣,尋找超參數的最優取值是至關重要的問題。通過超參數優化方法和K折交叉驗證,找到最優的超參數,使模型能夠準確地判斷報文類型。
a)K折交叉驗證
K折交叉驗證用于模型調優,測試模型預測未用于估計的新數據的能力,找到使得模型泛化性能最優的超參值。具體原理如圖10,將訓練數據分成K份,用其中的(K-1)份訓練模型,剩余的1份數據用于評估模型。循環迭代K次,并對得到的K個評估結果取平均值,得到最終的結果。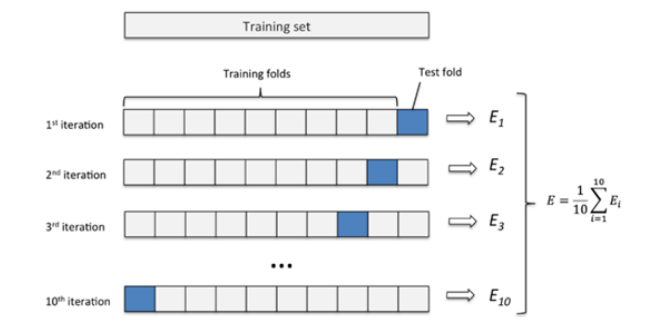
圖10 K折交叉驗證原理[3]
K值越小,模型越偏差越低、方差越高,容易出現過擬合。K值越大,則偏差提高,方差降低,且計算開銷增大。在訓練中我們一般選擇k=5。使用下面函數進行K折交叉驗證劃分,sklearn.model_selection.KFold(n_splits=5,shuffle=True,random_state=999).split(df),其中n_splits為交叉驗證的折數,shuffle表示是否打亂數據,random_state為隨機種子,df為訓練數據。
b)超參數優化 超參數優化方法主要有:網格搜索和貝葉斯優化。
網格搜索:以窮舉的方式遍歷所有可能的參數組合,網格搜索在1維、2維、3維的搜索空間表現相對來說不錯,很容易覆蓋到空間的大部分,而且耗時不大。使用sklearn.model_selection中的GridSearchCV ()進行超參數選擇和交叉驗證。
貝葉斯優化:網格搜索和隨機搜索沒有利用已搜索點的信息,使用這些信息指導搜索過程可以提高結果的質量以及搜索的速度。貝葉斯優化利用之前已搜索點的信息確定下一個搜索點,用于求解維數不高的黑盒優化問題。它的本質其實是一種回歸模型,即利用回歸模型預測的函數值來選擇下一個搜索點。使用hyperopt中的fmin()函數進行貝葉斯優化,給出最優模型參數。 以訓練集的交叉驗證結果作為性能度量。根據模型的超參數數量、取值范圍、性能影響等因素,選擇不同的超參數優化方法,對模型進行參數優化。
05
小結
面向智能網聯汽車無線通信系統、車載娛樂系統、駕駛輔助系統以及典型智能網聯場景,機器學習作為車載網絡入侵檢測中至關重要的一項技術,可實現對已知/未知攻擊行為的特征識別檢測,最終助力車端和云端安全聯動,保障車載網絡的信息安全。
?
審核編輯:劉清



















 工商網監
工商網監
評論