 電子發燒友App
電子發燒友App


高并發經常會發生在有大活躍用戶量,用戶高聚集的業務場景中,如:秒殺活動,定時領取紅包等。
為了讓業務可以流暢的運行并且給用戶一個好的交互體驗,我們需要根據業務場景預估達到的并發量等因素,來設計適合自己業務場景的高并發處理方案。
在工作這些年里,我有幸遇到了高并發各種坑,對如何設計高性能接口有一些經驗,其實無外乎滿足以下幾個特點:
靈敏性
伸縮性
容錯性
事件驅動/消息驅動
高性能接口設計準則
在引言里我也說了高性能設計的四個準則,現在具體對這四個準則做一些描述;
1. 靈敏性
應用程序應該盡可能快的對請求做出響應。
如果可以在順序獲取數據和并行獲取數據之間進行選擇的話,為了盡快向用戶返回響應,始終應該優先選擇并行獲取數據,可以同時請求互相沒有關聯的數據。當我們需要請求多個互相無關,沒有依賴的數據的時候,應該考慮是否能夠同時請求這些數據。
如果可能出現錯誤,應該立即返回,將問題通知用戶,不要讓用戶等待直到超時。
1.1 如何設計靈敏性
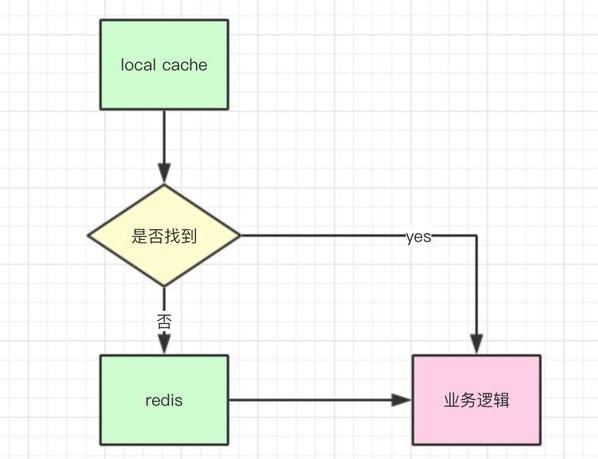
緩存前置
對于一些改變不頻繁的數據,應該放在分布式緩存中,例如redis,如果是一些元數據(例如,一些計數器的配置信息,變量的配置信息等)則應該啟用本地緩存,簡單流程如下:
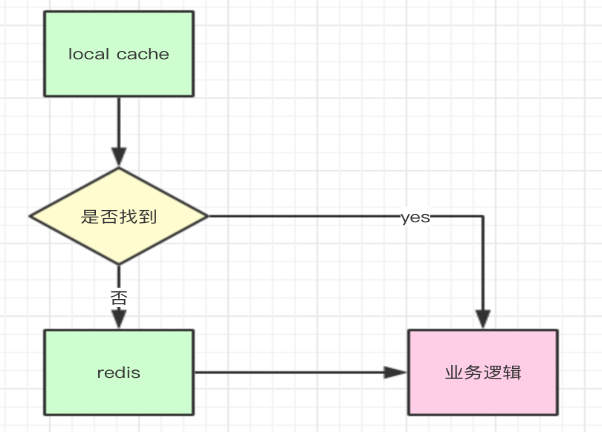
如果一些熱點數據不大的話,建議服務啟動的時候就應該提前加載到緩存中,這樣可以提高服務的性能。
讀寫拆分部署
如果你的服務既涉及到讀操作,也涉及到寫操作, 應該將讀寫隔離部署,這樣讀服務的壓力不會影響到寫服務,寫服務的壓力不會影響到讀服務。流程如下:
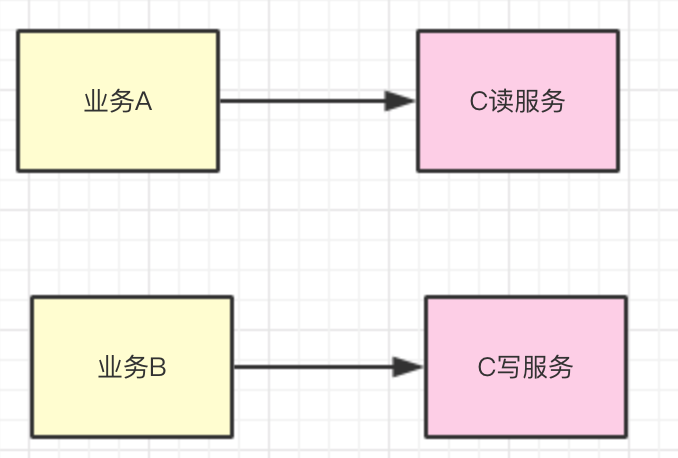
當然除了按照讀寫進行拆分部署外,還可以按照業務進行隔離部署。
對等設計、無狀態
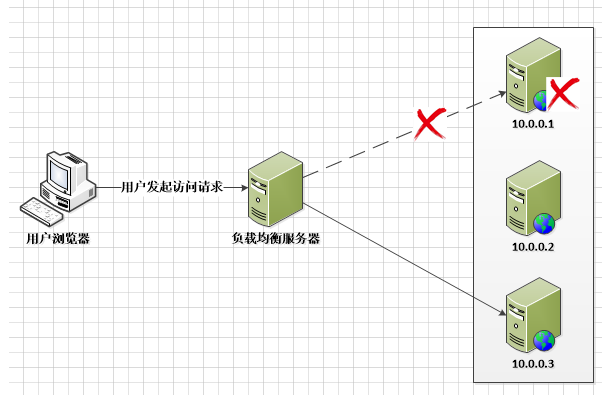
所謂無狀態是指應用服務器不保存業務的上下文信息,而僅根據每次請求提交的數據進行相應的業務邏輯處理,多個服務實例(服務器)之間完全對等,請求提交到任意服務器,處理結果是完全一樣的。
不保存狀態的應用給高可用的架構設計帶來了巨大便利,既然服務器不保存請求的狀態,那么所有的服務器完全對等,當任意一臺或多臺服務器宕機,請求提交給集群中的其他任意一臺可用機器處理,這樣對終端用戶而言,請求總是能夠成功的,整個系統依然可用。對于應用服務器集群,實現這種服務器可用狀態實時檢測、自動轉移失敗任務的機制就是負載均衡。
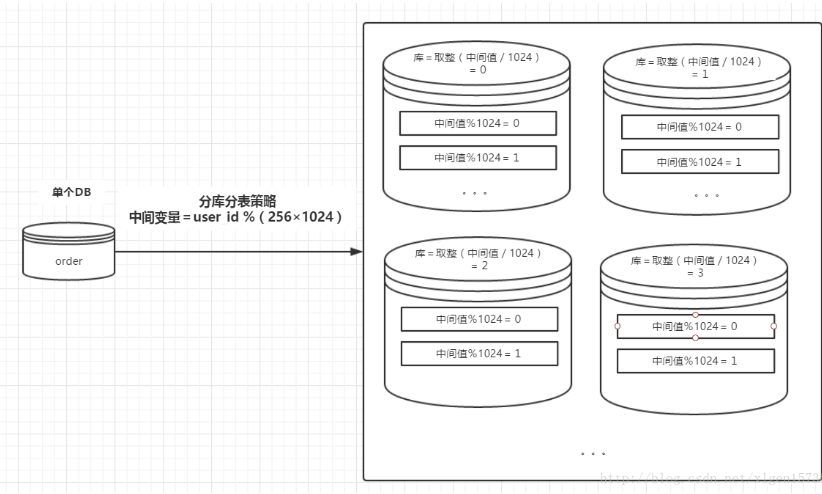
DB分庫分表,讀寫分離
對于數據層來說,如果數據量不大,db可以采用讀寫分離部署,對于讀多寫少的場景可以解決一部分壓力,從而提高我們接口的響應速度,如果寫的數據量和讀的數據量都很大,那么就必須要對db進行分庫分表外加讀寫分離了。
2. 伸縮性
應用程序應該能夠根據不同的工作負載進行伸縮擴展(尤其是通過增加計算資源來進行擴展)。為了提供伸縮性,系統應該努力消除瓶頸。
如果在虛擬機上運行內存數據庫,那么添加另一個虛擬幾點就可以將所有的查詢請求分布到兩臺虛擬服務器上,將可能的吞吐量增加至原來的兩倍。添加額外的節點應該能夠幾乎線性的提高系統的性能。
增加一個內存數據庫的節點后,還可以將數據分為兩半,并將其中的一半移至新的節點,這樣就能夠將內存容量提高至原來的兩倍。添加節點應該能夠幾乎線性的提高內存容量。
所以一般好的接口設計是可以通過水平擴展機器來達到提升性能的,這就要求我們設計接口的時候提現無狀態性。
3. 容錯性
應用程序應該考慮到錯誤發生的情況,并且從容的對錯誤情況做出響應。如果系統的某個組件發生錯誤,對與該組件無關的請求不應該產生任務影響。錯誤是難以避免的,因此應該將錯誤造成的影響限制在發生錯誤的組件之內。如果可能的話,通過對重要組件及數據的備份和冗余,這些組件發生錯誤時不應該對其外部行為有任何影響。
假設你的系統既使用了redis,也使用了mysql對數據進行處理,當redis或著mysql掛了的時候,程序應該可以繼續提供服務,而不是一味的報錯。流程如下:
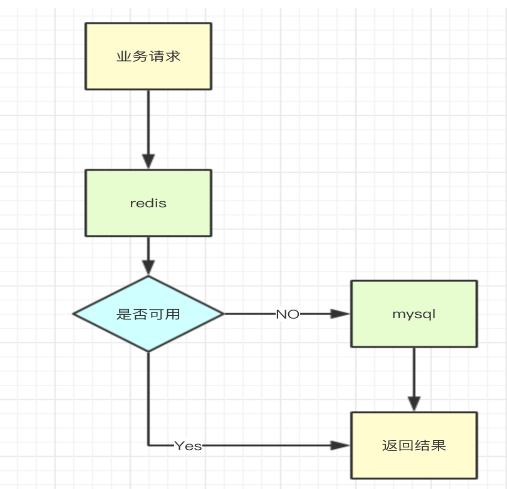
當一個組件不可用的時候,可以使用開關對某一個組件進行降級,常見的降級方式分為手動降級和自動降級,手動降級可以借助zookeeper進行,自動降級可以使用Hystrix。
4. 事件驅動/消息驅動
使用消息而不直接進行方法調用提供了一種幫助我們滿足另外3個高性能設計準則的方法。消息驅動的系統著重于控制何時、何地以及如何對請求做出響應,允許做出響應的組件進行路由以及負載均衡。
由于異步的消息驅動系統只在真正需要時才會消耗資源(比如線程),因此它對系統資源的利用更為高效。消息也可以被發送到遠程機器(位置透明)。
通常不是萬不得已,否則我們認為丟失一部分數據換取服務的高性能,這是值得的。如果能容忍數據的部分丟失(在可接受范圍內),比如保存數據到db,異步計算耗時的任務,通過消息隊列將是提升我們系統性能的比較好的方式。
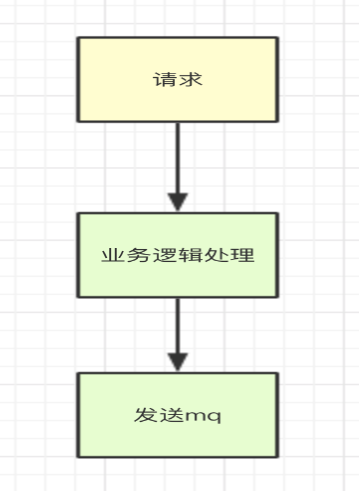
總結
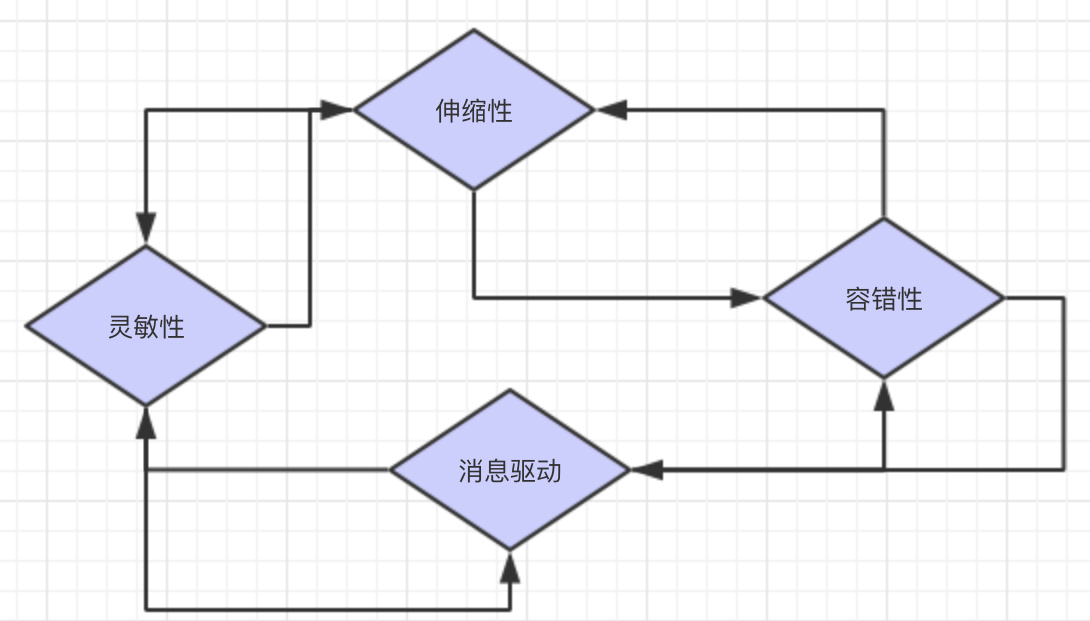
4個設計準則之間并不是完全獨立的。為了滿足某個準則而采取的方法通常也對滿足其他準備有所幫助。例如,如果發現某個服務響應速度較慢,我們可能會在短時間內停止再向該服務發送請求,等待其恢復正常,并立即向用戶返回錯誤信息。這樣做降低了響應慢的服務不堪重負直接崩潰的風險,因此也提高了系統的容錯性。除此之外,我們立即告知了用戶系統發生的問題,也就改善了系統的響應速度,如圖所示:
責任編輯人:CC





















 工商網監
工商網監
評論