") 驅(qū)動云/邊緣側算力建設的高性能互聯(lián)接口方案
驅(qū)動云/邊緣側算力建設的高性能互聯(lián)接口方案
9月14-15日,2023全球AI芯片峰會(GACS 2023)在深圳正式舉行。奎芯科技應邀出席大會,副總裁王曉陽發(fā)表主題為《驅(qū)動云/邊緣側算力建設的高性能互聯(lián)接口方案》的演講。在演講中,王曉陽分享了AIGC產(chǎn)業(yè)算力需求引發(fā)的芯片互聯(lián)趨勢,并對算力芯片瓶頸進行了分析,提出了奎芯內(nèi)存互聯(lián)解決方案和Chiplet方案落地案例。
AIGC引爆的芯片互聯(lián)趨勢
最近幾年AI模型快速發(fā)展,模型規(guī)模每年差不多10倍速度增長,當令人驚訝的1750億參數(shù)的GPT3已成為過去式,迎來更大體量的萬億參數(shù)時代,AI系統(tǒng)算力需求也隨之增加,幾乎每季度翻倍增長。最近幾年體系結構討論最多的問題之一就是如何破解兩堵墻:內(nèi)存墻和I/O墻。多年來通過工藝進步,計算架構設計革新等方法,理論算力的增長速度是驚人的,但是內(nèi)存帶寬,互聯(lián)帶寬的增長卻相對緩慢,造成了巨大的落差,最近業(yè)界也在嘗試很多方法來縮小這些差距比如:增加緩存,多級緩存架構,堆疊緩存;盡量提高單節(jié)點算力減少互聯(lián)的overhead;用高速的芯片互聯(lián)和系統(tǒng)互聯(lián)的SerDes做芯片互聯(lián)等等。
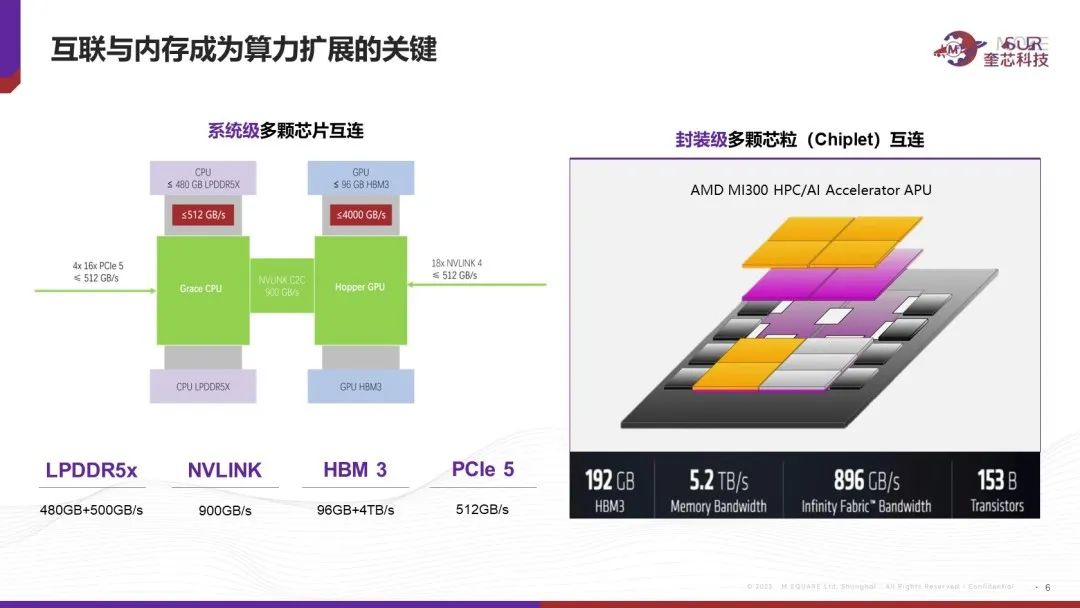
英偉達GH200非常重點的強調(diào)HBM帶寬,LPDDR容量,以及NVLINK的速度。AMD發(fā)布的MI300X對算力指標提都不提,只提內(nèi)存容量、內(nèi)存帶寬以及互聯(lián)帶寬。因此可以看到在LLM的游戲規(guī)則下,內(nèi)存容量、內(nèi)存帶寬以及互聯(lián)帶寬成了最核心的競爭力,而算力的重要性相對下降。
算力芯片瓶頸分析
目前主流AI大芯片采用HBM為主,它的價格相對其他內(nèi)存要貴,但單位帶寬成本較低。
HBM使用有諸多限制,其一是因為HBM的顆粒必須和SOC的Die要對齊,合封在一起,所以它是一個緊耦合的狀態(tài),會帶來如下限制:在HBM數(shù)量方面,SoC與HBM必須保持貼合,導致HBM顆粒數(shù)量受限于芯片邊緣長度;在熱管理方面,DRAM的溫度敏感性會限制SoC的工作頻率,從而影響性能,而SoC與HBM之間的熱交互對測試提出了更高的要求;在設計實施方面,HBM IP的布局和適配性相對不夠靈活;另外,工藝限制要求SoC與HBM HOST IP必須采用相同的工藝制程;最后,需要注意的是SoC的面積占用問題,在12納米工藝下每個HBM HOST IP大約占據(jù)30mm2,限制了計算單元的面積。
其二是主流HBM的應用還是以先進封裝為主,包括Silicon interposer 或者Silicon Bridge等,也帶來了不少限制:Interposer尺寸受限制,最大只能有3到4個曝光面積;2.5D封裝的成本較高,與標準封裝相比價格高出4倍,近期臺積電的CoWoS單價上漲了20%;采用uBump作為連接點時,測試覆蓋率有限,當封裝中包含超過6個HBM和2個ASIC時,良率明顯下降;最后,CoWoS產(chǎn)能有限,臺積電的CoWoS產(chǎn)能緊缺,國內(nèi)2.5D封裝技術還不夠成熟。
奎芯基于UCIe接口的HBM互聯(lián)方案
針對這些問題,奎芯科技打造一站式解決方案—M2LINK,用于將HBM和SoC解耦。基本做法是利用一顆Chiplet將HBM接口協(xié)議轉(zhuǎn)成UCIE接口協(xié)議,然后用RDL interposer 把Chiplet和HBM內(nèi)存封裝成一個標準模組,最后通過普通基板來和主SoC進行封裝。這樣主SoC和標準模組間距離預計可以拉遠到2.5cm,克服了原先主SoC和HBM緊耦合和綁定的限制,同時也無需受限于先進封裝的高成本和Si Interposer的有限尺寸。除此之外還有諸多好處,比如以UCIe IP取代HBM IP,節(jié)省了主芯片面積,主芯片成本降低;單位邊長可以連接更多的HBM標準模組,內(nèi)存容量和帶寬都可以得到提升等等。
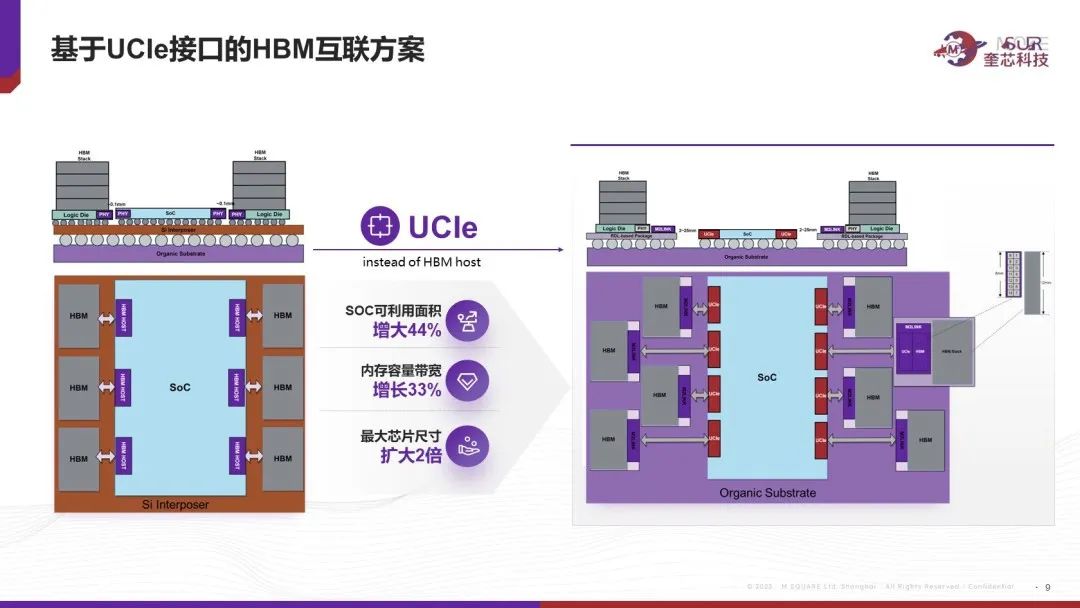
以目前主流芯片為例,SoC近HBM的邊長為30mm的話,可以擺放6個HBM顆粒,利用M2LINK方案的話,雙邊共可以擺放8個HBM模組,同等大小的SoC可利用面積增大44%,內(nèi)存容量帶寬增加1/3, 最大封裝面積可以增加一倍以上。
奎芯Chiplet落地解決方案
奎芯科技作為國內(nèi)領先的互聯(lián)IP產(chǎn)品及Chiplet產(chǎn)品供應商,國產(chǎn)自研內(nèi)存及互聯(lián)解決方案,奎芯LPDDR5X接口速率可達8533Mbps,業(yè)界領先。奎芯D2D接口則具有高速率、低功耗、低延遲等優(yōu)勢。而奎芯HBM接口可支持國產(chǎn)工藝 PHY+ Controller 全套方案,速率可達6.4Gbps。目前,奎芯已經(jīng)有70件知識產(chǎn)權申請,以及16件榮譽獎項。
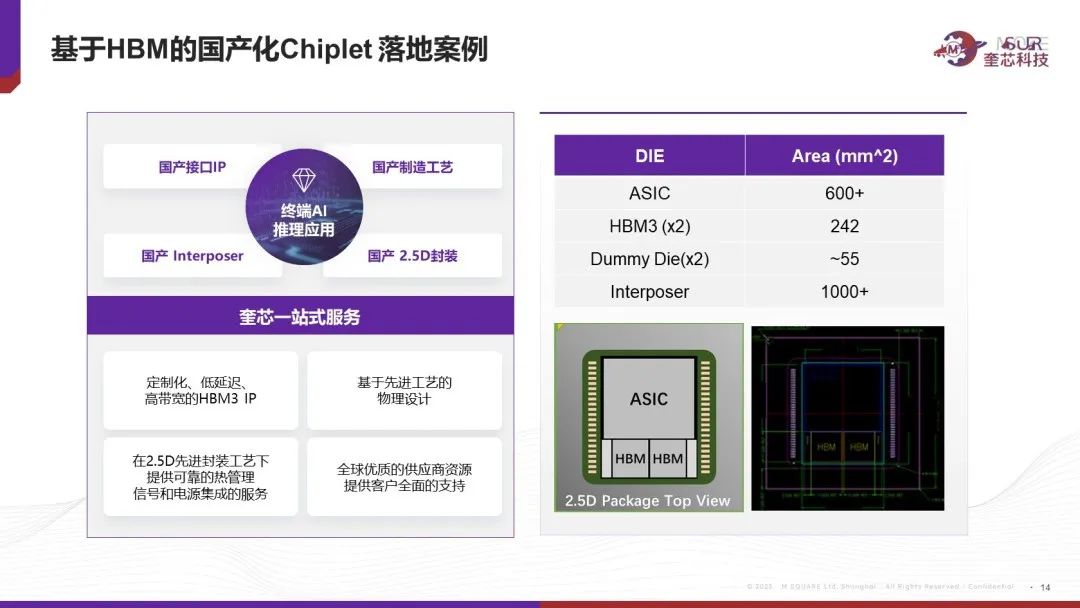
奎芯科技基于對于整個封裝供應鏈的整合能力,目前和客戶一起打造一款標準的帶HBM3的2.5D全國產(chǎn)封裝大芯片,將會提供包含HBM IP, interposer設計,2.5D封裝的設計的完整的turn key solution。
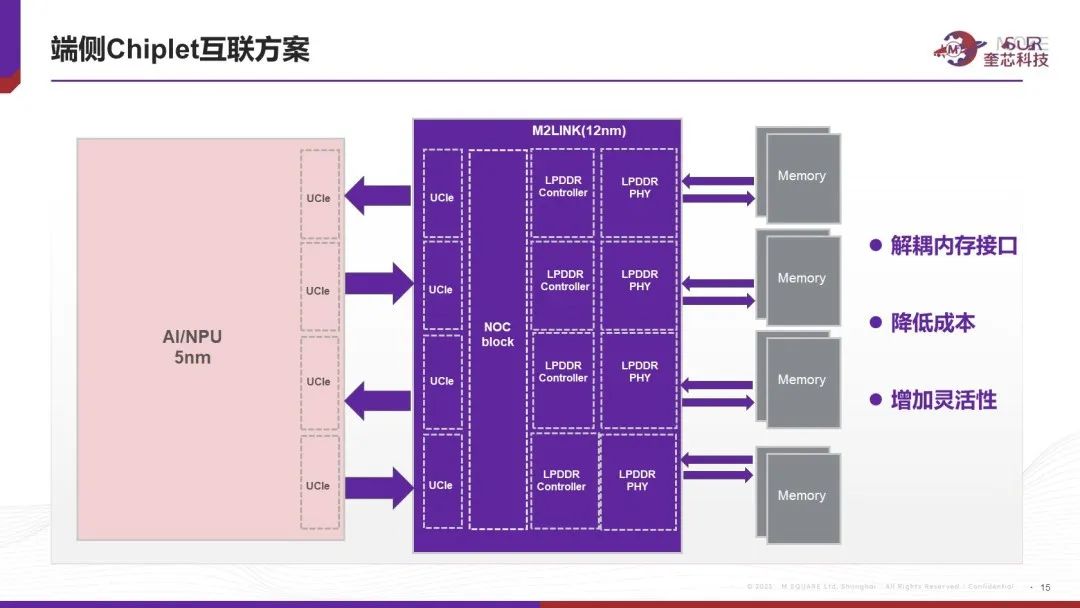
同時,奎芯科技基于D2D(UCIe)解耦SoC和HBM HOST的思路不僅適用于云端訓練和推理的大算力芯片,在端側已經(jīng)有具體實踐的案例,目前在給客戶打造的是一款低功耗計算產(chǎn)品的IO die。對于此場景,客戶希望計算部分用最先進的制程,考慮到昂貴的成本,客戶還是希望解耦內(nèi)存接口放到成熟工藝上實現(xiàn),因此我們給客戶打造一顆包含 LPDDR host 的完整IO die, 實現(xiàn)內(nèi)存接口解耦,降低成本,為客戶未來產(chǎn)品升級增加靈活性。
奎芯科技致力于建立開放生態(tài)的一站式Chiplet服務平臺,提供接口IP,Chiplet,系統(tǒng)設計和先進封裝設計等服務,配套強大的供應鏈資源及高效的系統(tǒng)整合服務,為客戶提供完整的一站式解決方案。
來源: 奎芯科技
審核編輯 黃宇
-
芯片
+關注
關注
459文章
51607瀏覽量
429961 -
AI芯片
+關注
關注
17文章
1927瀏覽量
35424 -
算力
+關注
關注
1文章
1045瀏覽量
15111 -
chiplet
+關注
關注
6文章
438瀏覽量
12688
發(fā)布評論請先 登錄
相關推薦
【一文看懂】什么是端側算力?

科技云報到:要算力更要“算利”,“精裝算力”觸發(fā)大模型產(chǎn)業(yè)新變局?
華為助力貴州氣象高性能算力項目建設
GPU算力租用平臺是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
米爾STM32MP2核心板首發(fā)新品上市!高性能+多接口+邊緣算力
ST系列-米爾STM32MP257核心板開發(fā)板-高性能+多接口+邊緣算力
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
廣和通端側AI解決方案驅(qū)動性能密集型場景商用型場景商用
廣和通端側AI解決方案驅(qū)動性能密集型場景商用型場景商用

名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
曙光攜手“算力互聯(lián)公共服務平臺”提高全國算力匹配效率
深度踐行“IaaS on DPU”理念,中科馭數(shù)正式發(fā)布“馭云”高性能云異構算力解決方案!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論