 電子發(fā)燒友App
電子發(fā)燒友App


自電子交易問(wèn)世以來(lái),對(duì)速度的追逐無(wú)止境,時(shí)刻要求搭建速度最快、最智能的交易平臺(tái)。智能和高速就意味著金錢。能夠率先發(fā)現(xiàn)交易機(jī)會(huì)并在其上完成交易的交易平臺(tái)將占上風(fēng)。響應(yīng)時(shí)間已經(jīng)從“秒”一路降低到“毫秒”、“微秒”。要實(shí)現(xiàn)微秒和亞微秒響應(yīng)時(shí)間,憑借傳統(tǒng)的軟件架構(gòu)或簡(jiǎn)單的硬件架構(gòu)幾無(wú)可能,正是這一事實(shí)促使在超低時(shí)延系統(tǒng)中引入 FPGA 技術(shù)。但是,F(xiàn)PGA 編程要求使用 HDL機(jī)器語(yǔ)言開(kāi)發(fā)交易策略并將現(xiàn)有交易策略(主要用 C 語(yǔ)言和 C++ 語(yǔ)言編寫(xiě))移植到 HDL 機(jī)器語(yǔ)言中。這與使用標(biāo)準(zhǔn)的 C 和 C++ 編程在技能上有根本的不同,同時(shí)需要增加人員、工具和時(shí)間。
有現(xiàn)成的 C-to-HDL 編輯器工具可用,可將現(xiàn)有的 C 代碼移植到硬件描述語(yǔ)言 (HDL),比用 HDL 從頭開(kāi)發(fā)代碼速度快。但是,負(fù)責(zé)移植代碼工作的人員必須熟悉硬件編程,或者必須遵循具體指南,才能生成可接受的代碼。即便這樣,生成的代碼仍然可能會(huì)比用 HDL 直接開(kāi)發(fā)的代碼晦澀低效。
為了降低在 FPGA 以太網(wǎng)卡上直接開(kāi)發(fā) HDL 代碼所帶來(lái)的風(fēng)險(xiǎn),同時(shí)節(jié)省開(kāi)發(fā)時(shí)間,AdvancedIO 公司率先嘗試將 FPGA 框架用于 10G 以太網(wǎng) (10GE) 通信。我們的expressXG 開(kāi)發(fā)框架工具套件為保證金融業(yè)務(wù)的快速部署提供了必要的基礎(chǔ)設(shè)施, 可無(wú)縫移植到最新一代FPGA 卡上。該工具套件可集成并優(yōu)化應(yīng)用開(kāi)發(fā)所需的所有必要的核心功能,能夠最大程度地降低第三方許可成本,讓開(kāi)發(fā)周期縮短數(shù)月。開(kāi)發(fā)團(tuán)隊(duì)可隨后將 C-to-HDL 編譯器工具集成在框架中,從而為開(kāi)發(fā)應(yīng)用的不同部分提供多重選擇。
實(shí)際上兩種方法都在項(xiàng)目中有一席之地。在優(yōu)先考慮效率和代碼緊湊度,或組件在多個(gè)項(xiàng)目中使用的情況下,最好使用 expressXG 框架直接開(kāi)發(fā) HDL 組件。如果著重考慮產(chǎn)品上市時(shí)間和定制化,或者要求以 C 語(yǔ)言編寫(xiě)代碼的情況下,最好使用 C-to-HDL編譯器。這種方法可以克服眾多金融從業(yè)人員對(duì) FPGA 的畏懼,同時(shí)不會(huì)影響性能。
算法交易概覽
說(shuō)到證券、衍生品、期貨及其它金融工具的交易,總會(huì)讓人聯(lián)想起塞滿幾百人,叫嚷聲此起彼伏的交易大廳。人們或漫無(wú)目的地轉(zhuǎn)悠,或緊盯計(jì)算機(jī)屏幕。現(xiàn)實(shí)是,當(dāng)今美國(guó)有 70% 以上的交易是由運(yùn)行在計(jì)算機(jī)服務(wù)器上的算法完成的。在金融業(yè),速度就是一切。哪家公司能夠率先發(fā)現(xiàn)機(jī)遇并把握機(jī)遇,就能夠贏得豐厚的利潤(rùn)。對(duì)某些交易策略而言,率先進(jìn)入隊(duì)列就能贏得交易。這也就毫不奇怪眾多公司竭盡所能地確保自身相對(duì)競(jìng)爭(zhēng)對(duì)手的優(yōu)勢(shì),哪怕是僅僅 1 微秒。
在算法交易系統(tǒng) (ATS) 中,由運(yùn)行在高性能計(jì)算機(jī)上的算法處理交易,制定決策。這種系統(tǒng)運(yùn)用多種技術(shù)來(lái)最大程度的降低時(shí)延,贏得競(jìng)爭(zhēng)優(yōu)勢(shì)。具體包括與各個(gè)交易所共址、使用最短路徑網(wǎng)絡(luò),以及使用 10G E 來(lái)降低時(shí)延這一日益風(fēng)靡的做法。為在競(jìng)爭(zhēng)中贏得優(yōu)勢(shì),主要的交易公司同時(shí)采用上述所有技術(shù)。
證券市場(chǎng)上的交易僅限于經(jīng)紀(jì)人-交易員和屬于交易所成員的市場(chǎng)莊家機(jī)構(gòu)之間。部分這類機(jī)構(gòu)為其他交易公司提供服務(wù),使他們能夠通過(guò)他們的帳戶使用“電子式專屬線路下單(DMA)”給交易所下訂單。提供“電子式專屬線路下單”的機(jī)構(gòu)必須建立交易前風(fēng)險(xiǎn)控制制度,以限制財(cái)務(wù)風(fēng)險(xiǎn),滿足合規(guī)性要求。因此,他們必須采用配備有軟件的服務(wù)器,檢查所有經(jīng)手他們的賬戶的交易。這種檢查必須以線速進(jìn)行,因?yàn)槿魏窝舆t都會(huì)讓他們及其客戶處于不利境地。現(xiàn)有的基于軟件的交易前風(fēng)險(xiǎn)管理平臺(tái)需要數(shù)十微秒才能完成金融交易上要求的策略檢查。很明顯這對(duì)當(dāng)今的交易員來(lái)說(shuō)速度不能滿足要求。
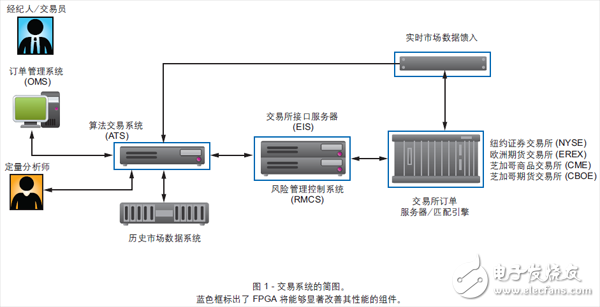
圖 1 顯示了簡(jiǎn)化交易系統(tǒng)的各個(gè)組件。實(shí)際上,ATS 可以更多的組件,比如用于執(zhí)行更復(fù)雜算法的服務(wù)器或計(jì)算云,這里我們不作討論。交易系統(tǒng)可以直接連接到交易所,也可以通過(guò)一個(gè)或多個(gè)交易所接口服務(wù)器、電子通信網(wǎng)絡(luò)或其它方式連接到交易所。另外,對(duì)穩(wěn)健可靠的交易基礎(chǔ)設(shè)施而言,防火墻和入侵檢測(cè)系統(tǒng)也是關(guān)鍵的組件。
?
基于軟件的解決方案的局限性
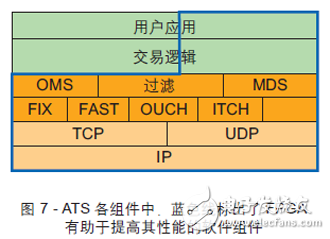
ATS 必須能夠接收多種市場(chǎng)饋入,解碼使用的不同協(xié)議(如 FIXFAST、ITCH 和 OUCH 等多種名字各異的協(xié)議),過(guò)濾需要的交易代碼并將其發(fā)送到預(yù)定義的“籃子”中,供交易算法 (TA) 分析。一旦交易算法判定必須執(zhí)行某項(xiàng)交易, 就向訂單管理系統(tǒng)(OMS) 發(fā)出交易請(qǐng)求,由訂單管理系統(tǒng)與交易所接口服務(wù)器或交易所本身通信,下訂單、接收交易確認(rèn)。ATS服務(wù)器還能用極其精確的時(shí)戳給輸入的數(shù)據(jù)加戳,然后將數(shù)據(jù)送去存檔。加蓋時(shí)戳和市場(chǎng)數(shù)據(jù)采集既可在同一服務(wù)器(讓數(shù)據(jù)經(jīng)內(nèi)部網(wǎng)絡(luò)進(jìn)入數(shù)據(jù)服務(wù)器)完成,也可兩個(gè)獨(dú)立的服務(wù)器上執(zhí)行。
ATS 能夠以超過(guò) 6Gbps 的總突發(fā)數(shù)據(jù)速率從多個(gè)交易所接收數(shù)據(jù)。近期納斯達(dá)克 (Nasdaq) 宣稱已準(zhǔn)備為自己的數(shù)據(jù)中心客戶提供 40Gbps 的連接,正等待監(jiān)管部門的批準(zhǔn)。數(shù)據(jù)速率的快速攀升給系統(tǒng)處理器帶來(lái)了巨大壓力,同時(shí)也從重要的交易數(shù)據(jù)分析和決策任務(wù)上分散了處理能力。根據(jù)使用商用 10GE 網(wǎng)絡(luò)接口卡對(duì)文件服務(wù)器測(cè)試的結(jié)果可以看出,在通過(guò)服務(wù)器自身的本地堆棧進(jìn)行 TCP 傳輸時(shí),僅處理 IP 協(xié)議就幾乎完全占用了2.2GHz 的處理器,且實(shí)現(xiàn)的數(shù)據(jù)速率不足 5Gbps。為應(yīng)對(duì)這種困局,出現(xiàn)了一種使用一個(gè)稱為 TCP 卸載引擎(TOE) 的硬件為網(wǎng)絡(luò)協(xié)議棧提速的方法。該方法能在一定程度上改善響應(yīng)時(shí)間。
即便在網(wǎng)卡上采用了 TOE,到達(dá)主處理器的數(shù)據(jù)量仍然相當(dāng)龐大,足以導(dǎo)致不可接受的延遲。為降低時(shí)延,有必要先在網(wǎng)卡上過(guò)濾相關(guān)數(shù)據(jù),然后再傳輸給主系統(tǒng)處理器。雖然所有的工作負(fù)荷都在 FPGA 層面完成,但響應(yīng)時(shí)間明顯加快。另外 FPGA 可提供與負(fù)荷水平無(wú)關(guān)的相同響應(yīng)時(shí)間。這對(duì)常規(guī)的處理器是無(wú)法實(shí)現(xiàn)的。在處理器輕載時(shí),響應(yīng)時(shí)間可以預(yù)測(cè),但在重載時(shí),響應(yīng)時(shí)間會(huì)延長(zhǎng),直至無(wú)法預(yù)測(cè)。
目前處理器和以太網(wǎng)卡之間通過(guò)PCI Express? 總線來(lái)通信。理論上 8信道的 PCI Express Gen 2 總線能提供4Gbps 的峰值吞吐量。但 PCI Express受器件驅(qū)動(dòng)程序和操作系統(tǒng)中斷處理內(nèi)在的時(shí)延的牽制。避免通過(guò) PCI Express 總線與主機(jī)處理器相連,在網(wǎng)卡上執(zhí)行金融計(jì)算,有著明顯優(yōu)勢(shì)。
FPGA 技術(shù)是金融應(yīng)用的理想選擇,因?yàn)樗軌驅(qū)崟r(shí)處理海量數(shù)據(jù),且時(shí)延低、一致性好。簡(jiǎn)言之,F(xiàn)PGA 能夠提供并行處理能力,這是通用處理器無(wú)法匹敵的。由于 FPGA 能夠給交易系統(tǒng)帶來(lái)更強(qiáng)勁的性能和極快的速度,設(shè)計(jì)人員都在努力將盡可能多的功能(比如與交易所通信的 OMS 和部分算法)集成到 FPGA 中,以降低響應(yīng)時(shí)間。圖 2 對(duì)基于 FPGA 和 CPU 的系統(tǒng)的響應(yīng)時(shí)間進(jìn)行了比較。FPGA 不僅速度明顯提高,而且性能隨負(fù)荷的增加保持穩(wěn)定,相比之下基于 CPU 的解決方案響應(yīng)時(shí)間隨負(fù)荷增大明顯延長(zhǎng)。

?
FPGA 技術(shù)的優(yōu)勢(shì)
FPGA 技術(shù)能夠提供最佳解決方案,輕松應(yīng)對(duì)高帶寬、實(shí)時(shí)、高計(jì)算強(qiáng)度金融交易應(yīng)用所面臨的各種難題,這是其他技術(shù)無(wú)法匹敵的。由 FPGA 在以太網(wǎng)卡上執(zhí)行交易的解決方案具有多重優(yōu)勢(shì):
? 在貼近網(wǎng)絡(luò)物理接口的 FPGA 上執(zhí)行交易可避免主機(jī)總線、主機(jī)處理器和操作系統(tǒng)帶來(lái)的時(shí)延。這樣可以顯著改善交易的響應(yīng)時(shí)間。
? FPGA 提供線速性能,能夠瞬時(shí)執(zhí)行算法中用于發(fā)現(xiàn)并把握交易機(jī)會(huì)的部分,不給他人察覺(jué)機(jī)遇的機(jī)會(huì)。
? FPGA 在運(yùn)行過(guò)程中可重新編程,便于修改參數(shù)、更新算法,保持領(lǐng)先于競(jìng)爭(zhēng)對(duì)手。
? FPGA 特別擅長(zhǎng)并行處理,能夠同時(shí)執(zhí)行多個(gè)交易。
超低時(shí)延金融應(yīng)用難以實(shí)現(xiàn)的原因在于它們必須在極高帶寬下以線速運(yùn)行,必須執(zhí)行復(fù)雜的算法。要實(shí)現(xiàn)卓越的高性能,必須針對(duì)應(yīng)用設(shè)計(jì)專門的架構(gòu)。這就必須考慮如何在高計(jì)算強(qiáng)度的算法和滿足交易的極快響應(yīng)速度要求之間進(jìn)行取舍,實(shí)現(xiàn)最佳平衡。設(shè)計(jì)人員必須想盡一切辦法消除瓶頸,最大限度地降低通信時(shí)延和處理時(shí)延。為避免與主機(jī)系統(tǒng)總線有關(guān)的時(shí)延,應(yīng)選用功能強(qiáng)大的 FPGA 來(lái)實(shí)現(xiàn)交易算法的關(guān)鍵部分,同時(shí)匹配大量的 SRAM 和 SDRAM 存儲(chǔ)器端口和低時(shí)延通信端口。
與為單核或多核處理器開(kāi)發(fā)軟件相比, 使用線程的硬件模塊編程FPGA 一般情況下工作量更大,而且要求具備專業(yè)技能。另外,還需要投入大量精力和資金學(xué)習(xí)實(shí)現(xiàn) FPGA 解決方案的有案可循和無(wú)案可循的微妙之處,尤其對(duì)極高速解決方案而言更是如此。這些特點(diǎn)可能會(huì)增大 FPGA的認(rèn)知風(fēng)險(xiǎn),延長(zhǎng)設(shè)計(jì)時(shí)間,導(dǎo)致部分項(xiàng)目經(jīng)理和開(kāi)發(fā)團(tuán)隊(duì)趨利避害,轉(zhuǎn)而尋求次優(yōu)的軟件實(shí)現(xiàn)方案。另外現(xiàn)有的交易算法幾乎都是清一色用 C 和C++ 編寫(xiě),將它們移植到 HDL 代碼中不是一件能一蹴而就的小事。
目前已有多種簡(jiǎn)化 FPGA 編程工作的方法,比如嵌入式硬核、軟件內(nèi)核和將 C 代碼移植到 HDL 語(yǔ)言中的各種工具等。雖然每種方法都有自己定位,存在一定的性能缺陷,但每種方案都能加快應(yīng)用的部署。C-to-HDL工具已成為簡(jiǎn)化 FPGA 應(yīng)用開(kāi)發(fā)的明確選擇。但是這些工具生成的代碼相當(dāng)晦澀,難以優(yōu)化。簡(jiǎn)言之,在目前沒(méi)有什么能夠取代直接 HDL 編程。
直接 HDL 編程與 C-TO-HDL 工具的對(duì)比
喬治華盛頓大學(xué)開(kāi)展了一項(xiàng)研究[1,2],對(duì)高性能可重配置計(jì)算機(jī)中用于為FPGA 生成 HDL 代碼的高級(jí)語(yǔ)言(HLL) 工具進(jìn)行了評(píng)估,并制定了相應(yīng)標(biāo)準(zhǔn)用于衡量各種工具相對(duì)于直接HDL 編程的效率和生產(chǎn)率。研究人員選擇了四種工作負(fù)荷,并邀請(qǐng)擁有不同經(jīng)驗(yàn)水平的用戶使用各種工具來(lái)實(shí)現(xiàn)代碼。結(jié)果顯示,各種 HLL-to-HDL工具無(wú)一例外地縮短了開(kāi)發(fā)時(shí)間,其中有的工具使開(kāi)發(fā)時(shí)間縮短了高達(dá)61%。但結(jié)果也顯示得到的代碼無(wú)一例外地比直接用 HDL 開(kāi)發(fā)的代碼低效,占用面積增加了 36% 之多,頻率下降達(dá) 50%。另外研究還發(fā)現(xiàn)在使用部分工具時(shí),吞吐量顯著下降。[2]而且這些工具生成的代碼相當(dāng)晦澀,難以進(jìn)行 HDL 層面的調(diào)試。
不過(guò)這里應(yīng)該說(shuō)明的是測(cè)試中使用的四種設(shè)計(jì)相對(duì)簡(jiǎn)單。某些金融算法和應(yīng)用要復(fù)雜得多,用 HDL 直接編程方法來(lái)實(shí)現(xiàn)也更艱難。我們預(yù)計(jì)隨著更復(fù)雜的算法用 FPGA 來(lái)實(shí)現(xiàn),使用 HLL-to-HDL 工具應(yīng)該能夠進(jìn)一步節(jié)省時(shí)間。已有現(xiàn)成的 C 語(yǔ)言算法,需要移植到 HDL 中的情況尤為如此,但需要先在 C 語(yǔ)言中編寫(xiě),然后移植的情況卻并非如此。
需要注意的是,C 語(yǔ)言和 HDL 有著根本性的差異,不是用 C 語(yǔ)言編寫(xiě)的一切內(nèi)容都能夠正確無(wú)誤地轉(zhuǎn)換為HDL。表1 所示的是廠商目前使用的幾種 C 語(yǔ)言變體或子集,現(xiàn)在正在嘗試在OpenGL 上實(shí)現(xiàn)標(biāo)準(zhǔn)化。OpenGL 是一種用于新型處理器跨平臺(tái)并行編程的開(kāi)放標(biāo)準(zhǔn),目前已在 FPGA 上使用。[3]
![表 1 - 從 HLL-to-HDL 工具與直接用 HDL 開(kāi)發(fā)的對(duì)比可以看出,雖然顯著節(jié)省了時(shí)間,但得到的代碼比用 HDL 直接創(chuàng)建的低效。[1]](/uploads/allimg/171122/1G92TJ0-2.png)
用 HDL 編寫(xiě)的 FPGA 開(kāi)發(fā)框架
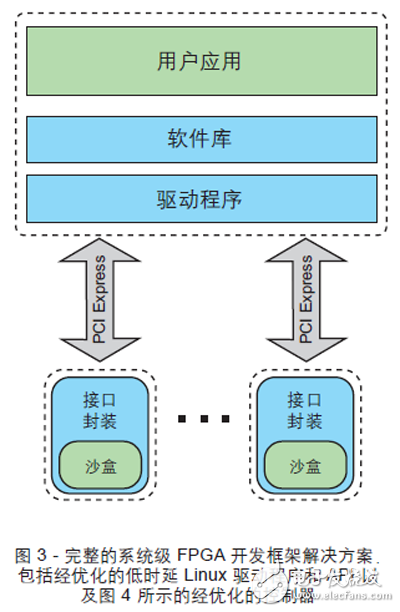
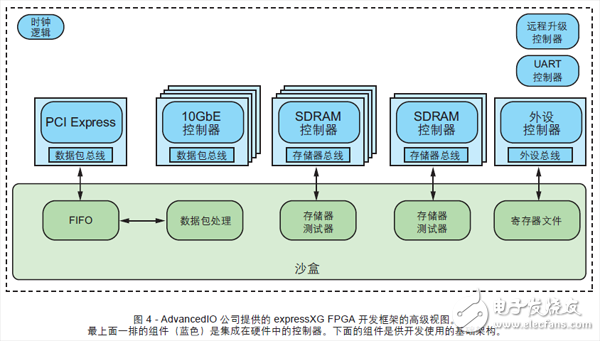
另一種簡(jiǎn)化 FPGA 開(kāi)發(fā)工作并縮短開(kāi)發(fā)周期的方法是使用用 HDL 直接編寫(xiě)的、對(duì)時(shí)延和性能進(jìn)行了高度優(yōu)化的框架(如圖 3 和圖 4 所示)。這種框架是以太網(wǎng)協(xié)議與接口、存儲(chǔ)器控制器以及主機(jī)架構(gòu)接口的深度抽象,故能減少實(shí)際人員為實(shí)現(xiàn)定制算法付出的精力和時(shí)間。這樣開(kāi)發(fā)人員能夠集中精力進(jìn)行應(yīng)用開(kāi)發(fā)和集成,不必?fù)?dān)心如何讓各種外部接口在 FPGA 卡上工作。合適的開(kāi)發(fā)框架應(yīng)保證應(yīng)用在 FPGA 器件系列直接的可移植性以及在同一系列FPGA 卡之間的可移植性。這樣可以顯著降低未來(lái)移植或升級(jí)的成本。
?
?
我們已在 AdvancedIO Systems 公司提供的各系列高性能 10GE 卡上實(shí)現(xiàn)并驗(yàn)證了我們的開(kāi)發(fā)框架。這些 10GE卡廣泛用于國(guó)防、金融和電信行業(yè)等多種市場(chǎng)應(yīng)用領(lǐng)域。
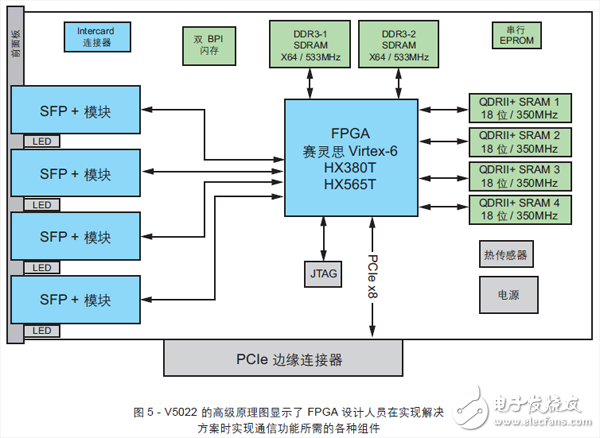
V5022 卡是專為金融交易優(yōu)化的產(chǎn)品, 采用賽靈思 Virtex?-6 HXTFPGA,擁有能夠?qū)崿F(xiàn)大容量、超低時(shí)延交易解決方案的應(yīng)用架構(gòu)所需的全部必要組件。Virtex-6 HXT 系列可為實(shí)現(xiàn)復(fù)雜算法提供大量邏輯資源。它擁有 2個(gè)高達(dá) 8GB 的獨(dú)立 Bank、533MHz DDR3 SDRAM 和 4 個(gè)高達(dá)144Mb 的獨(dú)立 Bank、350MHz QDRII+SRAM,是需要緩沖或超高速查找表的高級(jí)算法的理想選擇。V5022 卡有四個(gè) 10GE端口,能夠大幅降低從光纜到 FPGA 器件內(nèi)部的 MAC 接口(L2)的時(shí)延。
?
V5022 支持 PCI Express Gen2 主機(jī)接口,采用卡間高速端口確保系統(tǒng)中各卡之間的超高速通信,無(wú)需使用主機(jī)系統(tǒng)總線,可進(jìn)一步降低時(shí)延。這為實(shí)現(xiàn)更加復(fù)雜的交易算法提供了更強(qiáng)大的高速處理能力。
該開(kāi)發(fā)框架提供的主要功能必須集成在開(kāi)發(fā)板上,才能保障一切工作正常。說(shuō)采集、集成和優(yōu)化這樣的功能的邏輯是一件既費(fèi)時(shí)又費(fèi)錢的工作,應(yīng)該不算過(guò)分。因此這種開(kāi)發(fā)框架為項(xiàng)目經(jīng)理帶來(lái)了巨大的價(jià)值,有助于加速產(chǎn)品上市進(jìn)程。
AdvancedIP 投入了大量的精力,以確保其框架經(jīng)優(yōu)化后能夠提供最優(yōu)異的性能,空間占用小,運(yùn)行效率高。這樣可以讓 FPGA 的大部分資源用于應(yīng)用開(kāi)發(fā)。比如,當(dāng) V5022 使用賽靈思Virtex-6 HX565T 時(shí), 該框架占用FPGA 的資源不足 7.5%。這其中包括PCIe? 接口,四個(gè) 10GE 接口、兩個(gè)SDRAM 控制器和四個(gè) SRAM 控制器。
該開(kāi)發(fā)框架提供了一個(gè)“沙盒”供編程人員開(kāi)發(fā)自己的應(yīng)用。它有數(shù)個(gè)易于理解的對(duì)外接口,便于在 FPGA 卡上迅速集成應(yīng)用。另提供示例代碼和示例,展示如何開(kāi)箱即用地運(yùn)用接口,布置系統(tǒng)數(shù)據(jù)流,從而增強(qiáng)開(kāi)發(fā)人員的信心。
節(jié)省數(shù)月時(shí)間
為降低在 FPGA 器件上開(kāi)發(fā) HDL 代碼涉及的風(fēng)險(xiǎn),縮短開(kāi)發(fā)時(shí)間,我們的FPGA 開(kāi)發(fā)框架集成并優(yōu)化了在 FPGA卡上開(kāi)發(fā)應(yīng)用所需的全部控制器。這至少可以縮短項(xiàng)目數(shù)月的開(kāi)發(fā)時(shí)間。我們還建議將 C-to-HDL 編譯器工具集成在開(kāi)發(fā)框架中,因?yàn)檠芯拷Y(jié)果表明,雖然工具生成的代碼效率低于 HDL 直接編碼,但它能夠顯著縮短開(kāi)發(fā)時(shí)間。
在現(xiàn)實(shí)情況中,不存在一種能夠適應(yīng)各種情況的萬(wàn)靈丹式的方法。在權(quán)衡開(kāi)發(fā)方法時(shí),設(shè)計(jì)小組應(yīng)有許多工具和選項(xiàng)可供使用和選擇。在要求效率或緊湊代碼時(shí),或者在組件用于多個(gè)項(xiàng)目中時(shí),最佳方法是使用 FPGA開(kāi)發(fā)框架開(kāi)發(fā) HDL 組件。若優(yōu)先考慮產(chǎn)品上市時(shí)間,以及已經(jīng)有 C 語(yǔ)言代碼可用的情況下, 最佳方法是使用C-to-HDL 編譯器工具。最好是使用FPGA 開(kāi)發(fā)框架在 HDL 中開(kāi)發(fā) TCP/IP 和 UDP/IP堆棧等固定功能的模塊,同時(shí)需要經(jīng)常修改的算法可以使用賽靈思 AutoESL [4] 或 Impulse[5] 高層次綜合工具等高級(jí)語(yǔ)言工具來(lái)開(kāi)發(fā)。
金融交易系統(tǒng)的應(yīng)用
圖 7 是需要在很高水平上實(shí)現(xiàn)的算法交易系統(tǒng)的不同組成部分。ATS 必須具備讀取一個(gè)或多個(gè)市場(chǎng)數(shù)據(jù)饋入,過(guò)濾數(shù)據(jù)并發(fā)送到不同“籃子”中用于分析,制定交易決策以及與一個(gè)或者多個(gè)交易所通信的能力。
?
交易邏輯和策略組件會(huì)經(jīng)常變動(dòng),且不同的交易機(jī)構(gòu)有自己的一套做法。他們最好是使用 C-to-HDL 編譯器來(lái)實(shí)現(xiàn),以滿足產(chǎn)品上市時(shí)間要求,而且如果市場(chǎng)要求,可以在后期轉(zhuǎn)為使用效率更高的實(shí)現(xiàn)方式(使用 FPGA 開(kāi)發(fā)框架)。另一方面,網(wǎng)絡(luò)協(xié)議和金融協(xié)議不會(huì)經(jīng)常發(fā)生變化,用高效的方法實(shí)現(xiàn)這些協(xié)議會(huì)嚴(yán)重影響系統(tǒng)性能。因此我們建議使用 expressXG 開(kāi)發(fā)框架在 HDL 直接實(shí)現(xiàn)這些協(xié)議。
速度、響應(yīng)性和預(yù)測(cè)性
金融交易行業(yè),在速度和超低時(shí)延的推動(dòng)下,F(xiàn)PGA 技術(shù)不斷得到推廣和普及。這個(gè)行業(yè)的用戶面臨著諸多挑戰(zhàn),包括不熟悉 FPGA 設(shè)計(jì)、技能要求不同、有龐大的高級(jí)語(yǔ)言代碼庫(kù)等。我們的 expressXG FPGA 開(kāi)發(fā)平臺(tái)能夠簡(jiǎn)化在基于 FPGA 的高性能以太網(wǎng)PCI Express 卡上進(jìn)行的應(yīng)用開(kāi)發(fā)工作,并縮短應(yīng)用開(kāi)發(fā)時(shí)間。為便于移植現(xiàn)有的 C 語(yǔ)言代碼,或者在產(chǎn)品上市速度壓倒一切的情況下,我們建議將一個(gè) C-to-HDL 編譯器集成在該框架中。
我們認(rèn)為集成有 C-to-HDL 編譯器的 expressXG 有助于 FPGA 技術(shù)的采用,提高交易系統(tǒng)的速度、響應(yīng)能力和預(yù)測(cè)能力。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論