 電子發燒友App
電子發燒友App


1. 概念
英文名:convolutional neural network
是一種前饋神經網絡,即表明沒有環路,普通神經網絡的 BP 算法只是用于方便計算梯度,也是前饋神經網絡。
是深度學習結構的一種,是一種深度、前饋神經網絡。
可以使用 BP 算法進行訓練
ConvNet architectures make the explicit assumption that the inputs are images, which allows us to encode certain properties into the architecture
卷積神經網絡的前提:輸入是二維結構或者三維結構,但起比較大作用的是空間維度(spacial),深度那一維并沒有太明顯的作用。
1.1 空間維度 spacial
是寬和高,不包含深度
1.2 什么是卷積
https://www.zhihu.com/question/22298352
這條知乎解釋得非常清楚!
卷積的離散和連續解釋,其實就是求和符號和積分符號換一下而已
CNN 中卷積的體現在于,在神經元的感受野里的輸入和權重濾波器做點積,然后權重濾波器對整個輸入在空間維度上一邊移動一邊做點積,然后求和,所以跟一般的卷積是在時間上移動不同的是,這里是在空間上移動。

這是二維離散卷積的表達方式,因為權重濾波器是在空間上移動,空間上是有高和寬兩個維度的
1.3 濾波器和輸出數據體
濾波器是權重濾波器,是待學習的參數
輸出數據體才是卷積層神經元
不同的濾波器的權重不同,表達的是對圖片要素的關注點不同,比如說如果某個濾波器對紅色敏感,即對于紅色的像素點會有正向輸出,那么掃描一張大部分是紅色的圖片的時候,該濾波器得到的 activation map 會有大面積的正向輸出。所以說,濾波器是不同的特征提取器。
1.4 卷積層的輸出
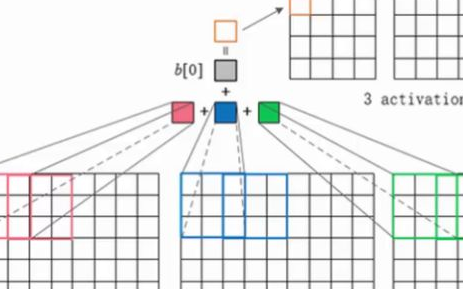
濾波器在輸入數據體空間上移動,得到一張 activation map,多個濾波器(個數是超參數)都與輸入數據體進行卷積,會得到多張在深度方向上堆疊在一起的 activation maps,然后呢,下一層的濾波器會把這些 activation maps 的結果相結合作為輸入,而不是把一個濾波器在空間移動后的點積結果相加,因為濾波器在掃描完整個輸入體之后,得到的是一張 activation map,而不是一個值哦!所謂卷積中移動求和的概念,應該是體現在把點積的結果匯聚成一張 activation map,這也算是求了個和吧!然后一個卷積層的輸出就是多個 maps 在深度方向上的疊加。
一張 activation map 其實就是濾波器權重參數與小塊輸入的點積+偏置,然后組在一起!
activation map 其實是這樣的:

如圖所示:28×28 個神經元的輸出,每個神經元都只看它的感受野的輸入,每個神經元的權重和偏置相同。神經元的輸出也是 wx+b
上面的圖只說明了一張 activation map,其實多張 activation maps 就是深度方向上堆疊在一起的神經元的輸出,只不過深度方向上的神經元不會共享權重和偏置,但深度方向上重疊的神經元的感受野是一樣的。
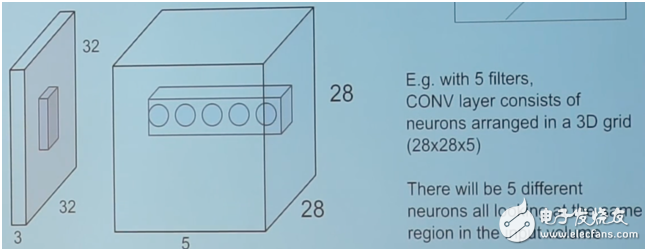
1.5 圖片的表達轉換
原始圖像假如是一個 32×32×3 的輸入數據體,經過一層卷積層的輸出(假設有 6 個 3×3×3 的濾波器 with pading1),則變成了一個 32326 的輸出數據體,也就是說,圖片的表達由原來的輸入數據體來表達,變成了現在的輸出數據體來表達。
1.6 參數的個數
每一個卷積層的參數個數是(濾波器的感受野×輸入深度+1)×濾波器個數,比如濾波器的感受野是 3×3×3,個數是 6,則這一層卷積層的參數個數是(9+1)×6=60 個,其中加的那個 1 是偏置,也就是說一個輸出數據體的整個深度切片上的神經元共享同一個權重向量,和同一個偏置,不同的深度切片的權重和偏置不同
1.7 卷積層總結
卷積層接受 W1×H1×D1 的輸入數據體(width, height, depth)
卷積層輸出 W2×H2×D2 的輸出數據體
需要 4 個超參數:K\F\S\P
K 代表濾波器個數,F 是神經元視野即濾波器大小,S 是 stride 步長,P 是 padding
根據超參數,可以由輸入數據體的大小,計算出輸出數據體的大小
W2=(W1-F+2P)/S+1
H2=(H1-F+2P)/S+1
D2=K
因為參數共享,因此總共有 F.F.D1.K 個權重和 K 個偏置參數
1.8 補充
sc231n 視頻中補充了一些可以進行卷積層計算的 API,其中提到一些計算框架
Torch 是一個科學計算框架,內置大量的機器學習算法,GPU first 特性。LuaJIT 語言接口,底層是 C/CUDA 實現。Torch – provides a Matlab-like environment for state-of-the-art machine learning algorithms in lua (from Ronan Collobert, Clement Farabet and Koray Kavukcuoglu)
Caffe 是一個深度學習框架,Caffe -Caffe is a deep learning framework made with expression, speed, and modularity in mind
Lasagne 是 Theano 中的一個輕量級的庫,用于建立和訓練神經網絡
Theano – CPU/GPU symbolic expression compiler in python (from MILA lab at University of Montreal)。Theano is a Python library that allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently
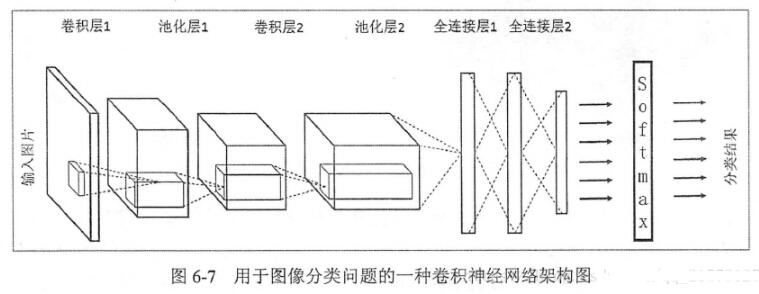
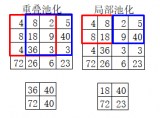
2. 池化層 pooling layer
max pooling 和 average pooling 是兩種常見的方法
輸入的數據體是 W1×H1×D1,輸出數據體是 W2×H2×D2
超參數有兩個 F/S,F 是 spacial extent,S 是 stride 即步長
W2=(W1-F)/S+1
H2=(H1-F)/S+1
D2=D1
沒有參數,因為 pooling layer 計算的是 a fixed function of the input
對 pooling layers,不常用 zero padding
3. full connecting layer
最后是一個 spacial size 減少,但深度依然是濾波器個數的全連接層,這一層的數據體會全部和輸出進行全連接
4. ReLU 層
無論是教學視頻還是學習資料里都提到了 ReLU 層,這其實讓人難以理解,至少給我帶來了困擾,因為 ReLU 只不過是一種神經元激活函數而已,后來經過和大家的討論,得出的結論是:其實就是卷積層的神經元的激活函數是 ReLU 函數而已,即 f(W×X+b) 中的 f,其中 W 和 X 之間是卷積而不是傳統 MLP 中的點積。
5. case study
AlexNet -> ZFNet -> VGGNet -> GoogLeNet -> ResNet
6. 趨勢
目前的趨勢是使用更小的 filter 和更深的結構
另外一個趨勢是拋棄 pooling 和 FC 層,只留下 CONV 層
7. 討論
根據另一個同學的學習結論,CNN 不但可以運用于圖像,還可以運用于 NLP 即自然語言處理,不過在卷積層的參數設置,以及池化層的參數設置上有些不同,如下圖所示。這是對自然語言語句進行二分類的 CNN 結構圖,論文是《ASensitiveAnalysisOfCNNForSentenceClassification》。

①濾波器的空間視野,寬度需要與詞向量的長度一致,高度可以自由調節,由高度的不同形成多個卷積層,同樣的高度下可以由濾波器個數這個超參數形成多個 activation maps
②圖中的步長為 1,因此綠色的高度為 3 的濾波器得到的 activation map 的高度就為 5,黃色的高度為 2 的濾波器得到的 activation map 的高度就為 6,這里的圖像可以認為是側面視角,寬度與濾波器寬度一致,看不到而已。
③池化層是 1-max pooling,即整張 activation map 中只選擇一個最大值!因此從 6 張 activation map 中就產生了一個一元的特征向量
④最后的 softmax 層就是把這個一元的特征向量作為輸入,用來得到句子的類別
除了這些參數外,論文中還提出了一些有趣的結論,這里不一一列舉,具體看論文:
①濾波器的視野(高度)選擇,最好選擇效果最好值的緊鄰值,比如說 7 效果最好,那么就沒有必要嘗試 2,應該嘗試 6 和 8 作為下一個卷積層的視野高度
















 工商網監
工商網監
評論