 電子發燒友App
電子發燒友App


“No PP,No WAY”這是個眼見為實的世界,這是個視覺構成的信息洪流的世界。大腦處理視覺內容的速度比文字內容快6萬倍,而隨著智能手機的普及,圖片、視頻的產生和分享已經是人們在社交平臺上的基本交流方式。用戶通過手機、平板、電腦上傳和分享自己的圖片,而且這個趨勢是每年都在增長(參見圖1)。
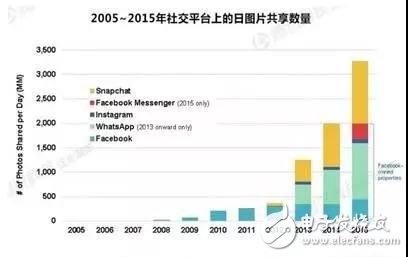
圖1. 2016年KPCB統計報告
每天QQ相冊、微信朋友圈上,用戶上傳的圖片數量有上億張,這些圖片被后臺服務器存儲下來,再通過網絡分發出去。如果每張圖片可以進行壓縮,使得圖片存儲和傳輸分發的數據量越少,既節省了用戶帶寬,也提高了用戶下載圖片的速度,用戶體驗更好。那么圖片是可以進行壓縮的么?1948年,信息論學說的奠基人香農曾經論證:不論是語音或者圖片,由于其信號中包含很多的冗余信息,所以可以對其進行壓縮。圖像壓縮算法有:JPEG、WEBP、H264(幀內壓縮)、HEVC(幀內壓縮),壓縮能力是:JPEG < WEBP/H264(幀內壓縮) < HEVC(幀內壓縮),這個壓縮能力是通過計算復雜度的提高來實現,其中WEBP、HEVC的計算復雜度是 JPEG 壓縮的 10 倍以上。目前在社交平臺上用戶上傳的大量圖片是JPEG格式,通過后臺服務器用更加復雜的算法如WEBP、HEVC(幀內壓縮),進一步壓縮以節省存儲和帶寬,所以對圖像的壓縮,從本質上是通過提高計算算力來降低存儲和帶寬。同時更加復雜的算法也帶來計算算力的大量消耗和處理延時的增加。
從業務角度來看,對于離線業務,可以通過業務在波峰和波谷之間閑置的計算算力進行圖片轉碼處理;但對于在線業務,圖片轉碼處理對于處理延時的要求就會有較高要求,為了滿足處理延時的要求,有時候會先進行圖片轉碼處理,把轉碼好的圖片存儲下來,當用戶需要的時候直接傳輸,這樣通過消耗存儲資源為代價來解決處理延時的要求。但是這又帶來一個新問題,用戶查看圖片的智能終端屏幕大小不一,如果都傳同樣大小的圖片,顯然不是最優。最優處理方法還是能夠通過計算算力,實時進行圖片轉碼處理。
在數據中心里面,計算算力通常由x86 CPU來提供,以前的x86 CPU性能每18個月就能翻倍(眾所周知的“摩爾定律”),但目前工業界的發展方向是摩爾定律已經走到終點。例如,2016年3月24日,英特爾宣布正式停用“工藝年-架構年(Tick-Tock)”處理器研發模式,未來研發周期將從兩年周期向三年期轉變。而國際半導體技術發展路線圖(International Technology Roadmap for Semiconductors,簡寫 ITRS)在維持了數十年,每兩年更新一次,為全世界半導體行業提供建議和規劃指南,也在2016年宣布不再做進一步的更新。
一方面處理器性能再無法按照摩爾定律進行增長,另一方面數據增長對計算性能要求超過了按“摩爾定律”增長的速度。處理器本身無法滿足高性能計算(HPC:High Performance Compute)應用軟件的性能需求,導致需求和性能之間出現了缺口(參見圖2)。
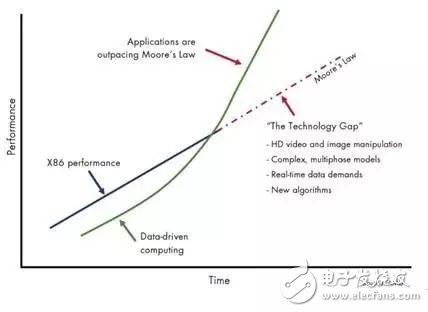
圖 2. 計算需求和計算能力的缺口發展形式
圖像處理解決方案
圖片服務支持的能力豐富多樣,基礎功能包括多種縮略剪裁方式、文字圖片水印、格式轉換、斷點續傳、鏡像存儲、防盜鏈等。我們結合當前圖文時代的用戶需求,提供圖片的上傳、存儲、處理、分發的全方位一體化的解決方案。目前,互聯網圖片服務的解決方案中落地存儲和下載大部分圖片格式還是JPEG/WEBP,但隨著新的編碼標準HEVC的出現,在同等圖像質量下,HEVC的壓縮效率會比JPEG/WEBP好30%~70%,可以節省大量的存儲和帶寬,但是HEVC的算法復雜度高導致CPU的編碼延遲和吞吐在線上環境中無法滿足,因此,我們開發了基于FPGA的新的解決方案。FPGA圖像處理方案可以很好的解決線上環境的需求,當然,FPGA圖像處理解決方案也兼容當前用戶線上系統的WEBP等其他圖像轉碼格式,可以很好的適應不同用戶的需求,提供低延遲,高吞吐,低成本的解決方案。
我們以HEVC FPGA 圖像處理為例,來說明在互聯網業務中圖片上傳,存儲,處理和下載的架構。
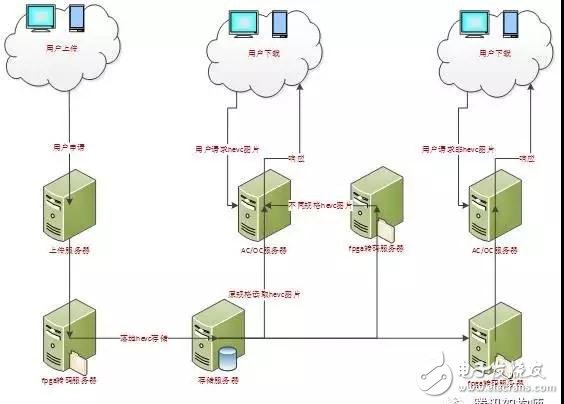
圖3. HEVC FPGA 圖片上傳存儲,處理,下載解決方案
如圖3所示,圖片HEVC FPGA轉碼的部署主要是落地存儲前以及下載前的轉碼服務器,使用FPGA做轉碼主要有以下優勢:
FPGA轉碼落地存儲HEVC,可有效節省存儲成本。
1. FPGA轉碼服務器和CPU轉碼相比可以降低服務器成本。
FPGA轉碼HEVC圖片和CPU相比吞吐量可以大大提高。
在下載時實時生成HEVC圖片,使用FPGA進行圖片轉碼加速,會大大降低轉碼延遲,提高用戶體驗。
圖像編碼算法分析
在圖像和視頻編解碼算法中,各個模塊都是基于像素級運算或者基于塊操作,而且針對各個像素或者圖像塊的操作是相同和重復的。早期的圖片壓縮標準JPEG和JPEG200,原始圖像首先經過基于塊的DCT變換或者小波變換,變換后的系數經過量化后再進行熵編碼(包括Huffman編碼或者自適應算術編碼),進而輸出壓縮后的碼流信息。在解碼端,通過反向操作,可將碼流信息進行解碼。在JPEG2000中,DCT變換被小波變換替代,可以更好的消除圖像塊內的冗余性,而且量化后的系統按照比特位平面進行自適應算術編碼,可以達到更好的壓縮性能。
除了JPEG這類對原始圖像直接變換的方法,還有一種是基于塊預測的方法。也就是對一個圖像塊先進行預測,原始圖像塊和預測塊的殘差再進行變換,量化和編碼。比較典型標準就是從H.264的幀內預測發展而來的WebP。隨著新一代視頻編碼標準HEVC/H.265的推出,其幀內編碼的壓縮性能,較上一代標準提升接近一倍[2]。因此,將HEVC的幀內編碼用于圖像壓縮也成為一種趨勢。HEVC的幀內編碼過程如圖4所示。
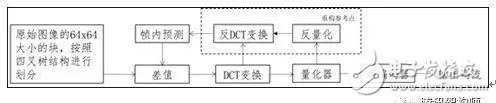
圖4. HEVC幀內編碼的過程
在HEVC中,塊劃分的方式是基于非完全四叉樹結構,這更適用于不同的圖像場景。每一個最終確定大小的塊只需要一個獨立的預測模式。圖5是HEVC圖片編碼中塊劃分和預測模式的一個例子。可以看出當一個塊可以通過單獨的某一個角度進行預測的時候,則不需要劃分為更小的塊。而場景信息較為復雜區域則需要劃分為較小的塊。編碼器的一項重要任務,就是尋找最佳的塊劃分方式和最優的預測角度。

圖5. HEVC圖片編碼塊劃分及預測模式
圖6(a) 就是根據最終的塊劃分方式和預測模式得到的預測圖片。預測圖片和原始圖片的差值(殘差)通過DCT變換,量化之后,最終通過熵編碼器輸出。圖片預測的殘差如圖6(b)所示。在解碼器中,根據得到的殘差數據,并進行和編碼器相同的預測,可以得到最終的重構圖片,圖6(c)所示的就是重構數據。由于編碼過程需要用到重構數據作為參考數據,因此在編碼器也需要進行重構的過程。原始圖片如圖6(d)所示,可以看出,重構的圖片和原始圖片損失非常小。

圖6. HEVC圖片編碼過程中的預測,殘差,重構以及原始數據
在HEVC的幀內編碼中,由于要進行最佳編碼模式的搜索,造成編碼器的計算復雜度高。傳統的CPU無法達到理想的吞吐量。現在的GPU雖然也大量應用的圖片和視頻領域,然而GPU的并行化更適用的是各個像素點進行相同操作,完成之后再進行下一步的并行化操作。這并不利于HEVC圖片編碼各個模塊控制較為復雜的情況。在Nvidia的GPU中,圖片和視頻編解碼也采用的專用的芯片來處理。而FPGA可以實現各個不同的模塊的流水化運算,實現時間上的并行。同時,由于只是進行幀內編碼,不同圖像之間是相互獨立的,在FPGA中也可以設計多路的編碼器,對不同的圖片進行并行的編碼壓縮。
當然,對于基于塊預測的圖像編碼方法,也存在一些限制FPGA并行化實現因素。但是,這些受到限制的部分,也可以通過FPGA設計的特點來解決。例如,如圖4所示,幀內預測的參考點需要通過重構的方法得到,這就增加了不同塊之間的依賴性,限制了塊之間的并行化,和流水化設計。在實際的FPGA設計中,可以在進行預測模式初選時,用原始數據替代重構數據作為參考,而在最終編碼時用重構數據在作為參考數據[3]。在FPGA的實現過程中,也可以更改掃描順序,優先處理那些有依賴關系的像素點。此外,在自適應熵編碼部分,由于存在更新碼表和更新概率估計的過程,部分比特數據進行熵編碼時,也存在依賴關系。在實際的FPGA設計過程中,可以通過將這些需要進行編碼的數據進行分組,將沒有依賴關系的數據分為一組,同時,通過數據緩存,可以預先判斷接下來的數據是否存在依賴關系,從而提高熵編碼的吞吐量[4]。
HEVC圖像編碼算法的FPGA實現
FPGA圖像編碼架構
目前,我們圖片業務已經實現WEBP和HEVC格式的FPGA硬件加速,下面以HEVC I幀圖像硬件加速舉例,說明圖像編碼在FPGA中是如何實現的。
FPGA的邏輯架構主要包括平臺部分和HEVC編碼器IP部分,其中FPGA平臺主要包括PCIE DMA以及DDR總線相關邏輯,這部分邏輯主要實現和host CPU的數據通信以及和FPGA板卡上的DDR通信。如圖7所示,FPGA架構上實例化了4個HEVC core(具體幾個是和FPGA資源有關),每一個HEVC core完成HEVC編碼算法的完整處理,這里4核心并行工作,也就是同一時刻,4個編碼任務可以并行工作,同時輸出4條HEVC碼流。
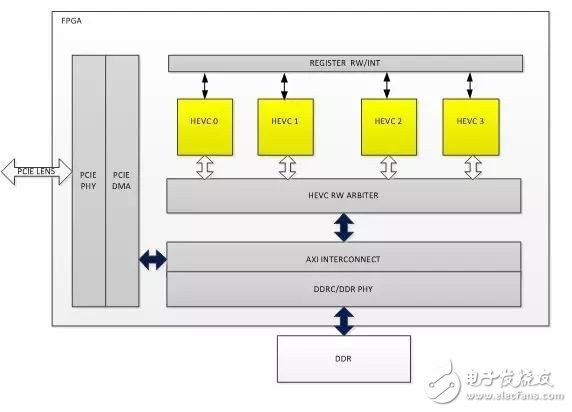
圖7. FPGA內部邏輯架構
FPGA內部邏輯主要包括:
HEVC CORE 0-3:H265編碼器IP,實現HEVC的編碼算法;
PCIE/DMA:實現和host CPU進行通信;
REGISTER RW/INT:寄存器讀寫以及中斷處理;
HEVC RW ARBITER:總線讀寫仲裁模塊;
AXI INTERCONNECT/DDRC/DDRY: 總線控制訪問DDR邏輯;
FPGA圖像編碼流程
FPGA HEVC core內部算法處理流程如圖8所示:分為當前圖像載入,intra預測初選,intra預測精選,CABAC編碼,碼流輸出。
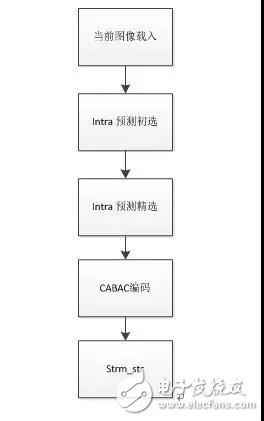
圖8. HEVC core內部算法處理流程
那么如何設計HEVC core實現算法功能呢?這里,編碼器模塊流水線設計成四級流水,如圖9所示,四級流水CURLD/PINTRA/SEL/CABAC處理性能設計接近,并行起來后,平均處理每個LCU需要8400個周期,如果按照1080p圖片一共510個LCU計算,單核理論上編碼可以達到編46 幀/s (FPGA電路實現頻率200M),這樣4核并行能達到184幀/s。
具體來說,CURLD完成當前圖像的載入邏輯,PINTRA完成intra預測初選35種模式的遍歷,得到最優的預測模式,這級流水算法上做了優化,預測參考像素沒有像傳統方式選擇重構像素,而是選擇當前像素做參考像素,這樣優化,使得intra預測初選可以單獨劃分為一級流水,和intra預測精選分開,使得編碼器整體處理性能增加一倍。SEL完成幀內預測模式精選以及RDO模式選擇,預測塊大小支持32/16/8,由于涉及到變換量化等運算量大的邏輯,這一級流水是整個編碼器的資源消耗大戶,設計上在算法上以及邏輯資源消耗上做了權衡;CABAC模塊完成頭信息的碼流生成以及每個LCU的語法元素和殘差的編碼,并完成碼流的打包輸出,這一級流水的主要問題在于CABAC的性能是否足夠快,從而應對QP比較小編碼更多bin的處理及時。
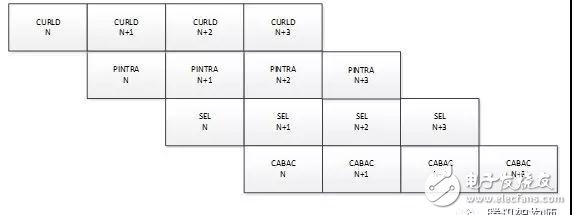
圖9. 運算模塊流水線
性能和收益
用FPGA完成JPEG格式圖片轉成HEVC格式圖片,圖片分辨率大小為1920x1080,FPGA處理延時相比CPU降低7倍,FPGA處理性能是CPU機器的10倍,FPGA機型單位性能成本是CPU機型的1/3(參見圖10)。
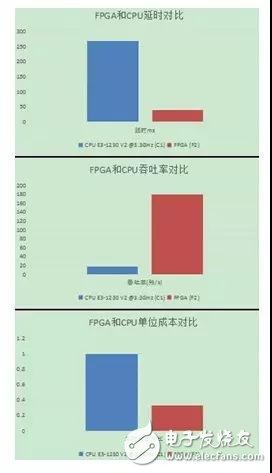
圖10.圖片轉碼FPGA和CPU對比
總之,圖片算法的FPGA實現,如果不考慮FPGA資源、硬件實現架構和處理性能,CPU圖像壓縮算法可以完全在FPGA進行“復制”實現,FPGA算法壓縮性能可以完全等同CPU。但是現實沒那么理想,FPGA算法實現要統一考慮FPGA性能,資源,算法實現復雜度等要素,只有聯合設計才能設計出最優秀的方案,為了發揮FPGA硬件實現的速度優勢,算法進行優化是必須要做的,綜合考慮各方面,我們在實際應用中,往往FPGA的算法實現要做一些“讓步”。另外,某種型號的FPGA一旦被選定,它的運算以及布線資源往往有個理論值,算法的實現同時要考慮FPGA資源的利用情況,如何能在相同的FPGA資源上實現最好的壓縮算法成為設計的難點。我們用FPGA進行算法實現的目標-----實現算法性能盡量接近CPU,圖片處理吞吐量,以及處理延遲讓CPU望其項背。
參考文獻:
[1]. KPCB:瑪麗·米克爾“互聯網女皇”-2016年互聯網趨勢報告
[2]. G. J. Sullivan, J. R. Ohm, W. J. Han and T. Wiegand, "Overview of the High Efficiency Video Coding (HEVC) Standard," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649-1668, Dec. 2012.
[3].G. Pastuszak and A. Abramowski, "Algorithm and Architecture Design of the H.265/HEVC Intra Encoder," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 26, no. 1, pp. 210-222, Jan. 2016.
[4].D. Zhou, J. Zhou, W. Fei and S. Goto, "Ultra-High-Throughput VLSI Architecture of H.265/HEVC CABAC Encoder for UHDTV Applications," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 25, no. 3, pp. 497-507, March 2015.





















 工商網監
工商網監
評論