 電子發燒友App
電子發燒友App


前言
目前的高端ASIC/ASSP/SoC器件開發商可考慮分為三大類:主流、早期采用者和技術領導者。在寫這篇文章的時候,主流開發商正致力于65納米技術節點設計,早期采用者開發商正專注于45/40納米節點設計,而技術領導者開發商正力求超越32/28納米及更小尺寸節點設計。隨著技術采用開發步伐的日益加快,下一代的早期采用者過渡到32/28納米節點的時間將不會很久,而他們的主流開發商同行也將緊隨其后。
進行32/28納米節點設計時會遇到許許多多的問題,包括:低功耗設計、串擾效應、工藝變異及操作模式和角點數量的顯著增加。本文首先會為您呈現微捷碼Talus?Vortex1.2物理實現流程的高層次視圖,接著將介紹32/28納米節點設計所包含的一些問題并描述TalusVortex1.2是如何解決的這些問題。
除了上述技術問題以外,32/28納米節點日益提高的設計規模和復雜性還造成了工程資源(在不擴大團隊規模的前提下取得更大成果,同時還保持甚至縮短現有時間表)、硬件資源(無須增加內存或購買全新設備,利用現有設備和服務器處理更大型設計)、滿足日益緊張的開發時間表等方面相關問題的增加。為了解決這些問題,本文還將描述通過TalusVortexFX創新性的DistributedSmartSync?(分布式智能同步)技術,TalusVortex顯著地提高了其容量和性能。TalusVortexFX提供了首款且唯一一款分布式布局布線解決方案。
TalusVortex1.2物理實現流程介紹
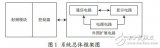
圖1所展示的是標準TalusVortex1.2物理流程的高層次視圖。從圖中,您不難觀察到它先假設了芯片級網表的存在,此網表可能已通過微捷碼或第三方的設計輸入和綜合工具而生成。

圖1.標準TalusVortex1.2流程高級視圖
第一步,準備好網表;這包括了各種任務,如:如確定輸入/輸出焊盤(I/Opad)及所有宏單元的位置。第二步,進行標準單元布局(這是與全局布線同時進行,因為布線可能影響到單元布局,而單元布局也會對布局造成影響)。
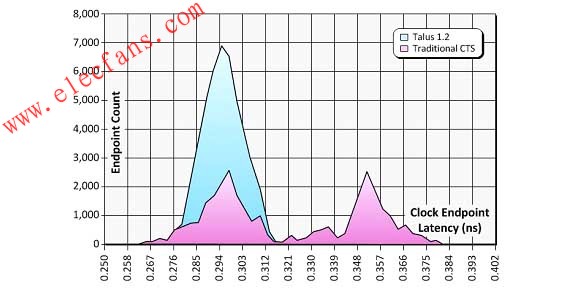
在完成初始單元布局之后,第三步是綜合時鐘樹,將其添加到設計中。多數時鐘樹綜合工具并非執行真正的多模多角(MMMC)時鐘樹實現,而是將時序環境分為best-case(最佳情況)和worst-case(最差情況)角點。但這種做法過于的悲觀,會導致性能一直處于“毫無起色”的狀態。在32/28納米節點,實現真正的MMMC時鐘樹勢在必行(另見后文32/28納米主題中“MMMC問題”部分)。因此Talus1.2的時鐘樹綜合部署了完整的MMMC分析,以平均10%的延遲性改善和10%的面積縮小實現了更為先進的魯棒性時鐘系統,如圖2所示
?
圖2.全MMMC時鐘樹綜合實現了更為先進的魯棒性時鐘系統
一旦時鐘樹添加成功,那么第四步是執行復雜的優化工作。而接下來的第五步則是進行詳細布線。Talus1.2流程的收斂特性確保了詳細布線結束時的時序可與流程早期所見到的時序密切吻合,甚至在考慮到串擾時也是如此(另見后文32/28納米主題中“串擾問題”部分)。
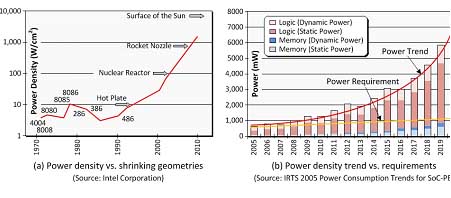
32/28納米低功耗問題
?
圖3.功耗是目前芯片設計最為關心的問題
工程師能夠部署各種各樣的技術來控制器件的動態(開關)功耗和漏電功耗。這些技術包括(但不限于)多開關閾值(multi-Vt)晶體管的使用、多電源多電壓(MSMV)、動態電壓與頻率縮放(DVFS)及電源關斷(PSO)。
在多開關閾值晶體管情況下,非關鍵時序路徑上的單元可由漏電量較低、功耗較少、開關速度較慢的高開關閾值(high-Vt)晶體管來組成;而關鍵時序路徑上的單元則可由漏電量較高、功耗較多、開關速度顯著加快的低開關閾值(low-Vt)晶體管來組成。
多電源多電壓(MSMV)所包括的芯片可分為不同區域(有時稱為“電壓島”或“電壓域),不同區域擁有不同的供電電壓。分配到較高電壓島的功能塊將擁有較高性能和較高功耗;而分配到較低電壓島的功能塊則將擁有較低性能和較低功耗。
動態電壓與頻率縮放(DVFS)技術的使用是通過改變一個或多個功能塊的相關電壓或頻率來優化性能與功耗間折衷權衡。例如:1.0V的額定電壓在功能塊活動率低時可降至0.8V以降低功耗,或在需要時它也可以提至1.2V以提高性能。同樣地,額定時鐘頻率可在功能塊活動率相對低時減至一半,或它也可增強一倍以滿足短時間爆發的高性能需求。
顧名思義,電源關斷(PSO)系指切斷選定的目前不在使用中的功能塊的電源。盡管這項技術在省電方面效果非常好,但它需要考慮到的問題真的很多,如:為避免造成電流浪涌,要按特殊順序給相關功能塊的供電和關電。
TalusVortex1.2提供了一款完整的集成化低功耗解決方案,包括一種自動化低功耗綜合方法,可與跨多電壓和頻率區域的并行分析與優化功能結合使用。Talus1.2不僅不會對所使用的不同晶體管開關閾值的數量進行限制,同時還支持無限的電壓、頻率和電源切斷區域。此外,Talus1.2完全支持通用功率格式(CPF)和統一功率格式(UPF)。這兩種格式讓設計團隊能夠先從功耗角度出發把握設計意圖,然后再推動下游規劃、實現和驗證策略(見側邊欄)。
32/28納米串擾問題
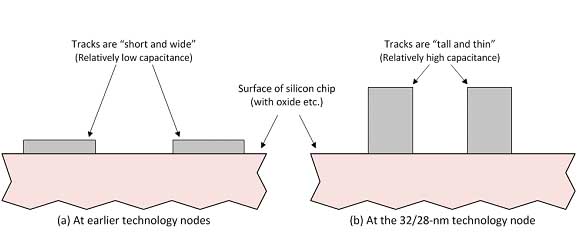
時鐘頻率的持續提高與供電電壓的日益降低意味著對串擾型延時變化、功能失效等信號完整性(SI)效應的敏感度在不斷提高。在32/28納米節點,由于更近的相鄰軌道、橫截面(32/28納米節點的軌道的高度可能大于其寬度,如圖4所示,它增大了相鄰軌道耦合電容)以及金屬化的軌道和通孔的電阻的提高(相對而言),因此這些效應也進一步增強。
?
圖4.32/28納米節點軌道的高度可能超過其寬度。
Talus1.2以基于軌道的復雜優化算法而著稱,它使得用戶在流程更早期的全局布線期間就可解決串擾問題。Talus1.2解決串擾相關問題的方式有很多,最基本的方式是使用最佳層分配和通過可用資源的擴散布線;它會有效管理這種擴散以避免對線長或通孔數量造成的顯著負面影響。此外,全局布線器自帶有多線程功能,可獲得超高的性能水平。
為了獲得高性能,所有全局布線器會先做假設。如:在“桶(bucket)”中放置導線,每個“桶”中的導線都設置于相互的頂部,因此一開始就可以直觀地看到。在多數環境中,流程下游的軌道的真正排序和布局工作是留待詳細布線器來完成。而解決流程下游的串擾問題要花費多上一個數量級的精力,而且按需修復(如:上調單元的尺寸會伴隨面積和漏電功耗的相應增加)可能不是最佳、乃至可完成的方法。
事實上,只有在知道軌道排序及其空間關系時才有可能精確評估潛在的串擾效應。因此Talus1.2將全局軌道區段轉換為空間上可布局的區段,然后再使用這一區段在流程更早期就對潛在的串擾問題進行評估;這樣通過在全局布線階段對線路的重新排序和設置,所有的串擾問題都可以在流程的更早階段得到解決。在全局布線階段所做的這些修改接下來還可用于為流程下游的詳細布線器提供指導,這樣便可以少得多的計算工作獲得更優的解決方案。
32/28納米工藝變異問題
對于以180納米及更高技術節點制造的硅芯片來說,所需的只是解決些少量晶圓間變異,即源自不同晶圓的晶粒在時序(性能)、功耗等特征方面的差異。這種差異可能是由于從一家代工廠到另一家代工廠的制程變異和儀器及操作環境微小差異所造成,如:爐溫、摻雜程度、蝕刻濃度、用以形成晶圓的光刻掩膜等等。
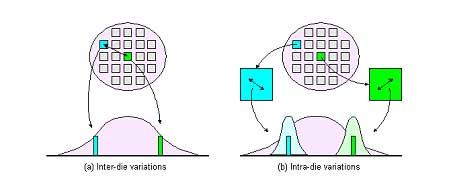
在較高技術節點時,所有晶粒間工藝變異(同一晶圓上各晶粒間差異)和晶粒內工藝變異(同一晶粒上各區域間差異)相對來說并沒那么重要。(晶粒間變異也被稱之為“全局”、“芯片到芯片”、“晶粒到晶粒”變異。)例如:如果一個芯片的核心電壓為2.5V,那么在多數情況下會假設整個晶粒擁有一致和穩定的2.5V電壓;同樣的也會假設整個晶粒上擁有統一的芯片溫度。
隨著尺寸越來越小的新技術節點浮出水面,晶粒間與晶粒內工藝變異變得日益重要。這些變異中有些是系統變異,這意味著它會隨著單元級電路功能而改變。例如:晶圓片中心附近所制造的芯片與朝向晶圓片邊緣所制造的芯片相比,其相關的某些參數可能會有所不同;在這種情況下,可以預測所有參數都將受到類似影響;而一些參數還會在隨機變異的情況下獨立地波動,據說這可能是基于區域的變異(相對于基于距離的變異)。
?
圖5.在32/28納米節點,晶粒間與晶粒內變異極為重要。
晶粒間與晶粒內工藝變異統稱為片上變異(OCV),在32/28納米節點變得極為重要。這是由于隨著每個新技術節點的推出,控制如晶體管結構的寬度和厚度、軌道和氧化層等關鍵尺寸變得更為困難,最終導致相對變異百分率(與某些中值相比較)會隨著每個新的技術節點而變得更大。
解決OCV的傳統方式是使用一階方案(first-orderapproach),包括在整個芯片上應用一攬子容限。不過在32/28納米節點,這種方法過于悲觀,會導致過度設計、設計性能降低和時序收斂周期變長。因此Talus1.2部署了復雜的高級OCV(AOCV)算法,基于單元和軌道的鄰近性(如:兩個相鄰單元與位于晶粒相反兩端的兩個單元相比較,相互間相關潛在變異會更少)來應用上下文特定的降額值。這種更為實際的模式可降低超額的容限,進而減少悲觀的時序違規并提高器件性能。
32/28納米多模多角(MMMC)問題
除了前文主題中所提及的制造工藝的變異以外,我們還必須解決芯片使用的環境條件(如:電壓和溫度)存在的潛在變異問題。所有這些變異均可歸入PVT(工藝、電壓和溫度)項目范圍。
對于以更早期技術節點所創建的器件來說,晶粒間與晶粒內PVT差異可以忽略不計。先做假設,然后基于整個芯片表面具有一致的工藝變異這一事實、基于整個晶粒上具有穩定的核心電壓和溫度等環境條件這一事實來簡化工作是有可能的。基于這些假設,通過采用一系列bese-case條件(最高允許電壓、最低允許溫度等),確定每條路徑bese-case(最小)延時會相對容易;同樣的,通過采用一系列worst-case條件(最低允許電壓、最高允許溫度等),確定每條路徑worst-case(最大)延時也會相對容易。
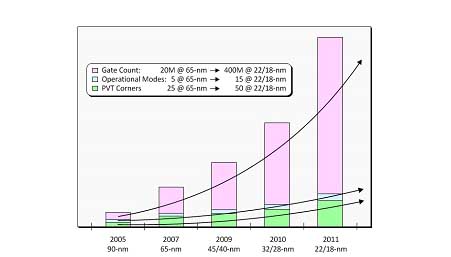
?
圖6.在32/28納米節點需要解決大量模式和角點。
如worst-case和best-casePVT等特定系列條件就是我們俗稱的“角點”。在32/28納米技術節點,晶粒間與晶粒內PVT差異十分明顯,解決大量模式和角點的工作是必不可少的。而且,前文提過的低功耗設計技術還會讓這一問題進一步復雜化。例如:在多電源多電壓(MSMV)技術情況下,可能一個電壓島的電壓值為其允許電壓范圍內最低電壓,另一個電壓島的電壓值為其允許電壓范圍內最高電壓,而其余電壓島的電壓值則會在這兩者之間。又如:有的芯片具有不同操作模式、擁有的一個或多個電路模塊位于在電源切斷的晶粒中心都將導致所需分析的角點情況顯著增加。
目前工具的問題在于:實現期間,芯片必須可在MMMC前景下進行優化。許多現有系統通過先考量已假設的worst-case情景、然后對別的條件進行優化的方式來著手處理優化問題。遺憾的是,這可能導致過度悲觀主義,造成次優性能。甚至更糟的是,如果這些關于哪些是worst-case情景的假設是錯誤的,那么結果可能是得到完全不管用的芯片。Talus1.2內置有自帶MMMC處理功能,這意味著優化過程不會漏掉任何情景。此外,Talus1.2的高速度和大容量還意味著,它能夠考慮到的不只是較小子集的實現情景,而是這款工具需要處理的整個系列的簽核情景。因此,Talus1.2可提供更好的性能和更短的實現周期。
以DistributedSmartSync技術增強TalusVortex的性能
前文所提及的物理實現流程每個步驟都是屬于計算密集型問題。而且為了解決伴隨技術節點而增加的復雜性,每個節點必須執行的計算量也在提高。此外,當器件中所集成的功能越來越多時,設計的規模和復雜性會隨著每個節點而提高,物理實現相關的計算需求也會相應增加。
再有一個因素就是:功能模塊的尺寸(為實現模塊功能所需的單元數量)也會隨著每項功能中包裝進越來越多特性而不斷增加。一些物理實現團隊偏愛層次化方案,而另外一些團隊則更喜歡使用“扁平化”方案,因為他們感覺在使用層次化方案時放棄了太多東西。
如果工具具有處理更大型電路模塊的能力,那么生產率就可得到即時的提升。例如:定義和微調層次化模塊間約束是極為耗時的資源密集型工作。如果這些工具具有處理更大型電路模塊的能力,那么就不需要定義子模塊間約束,因為不會有任何子模塊存在。這會大大提高生產率。
問題在于:多數布局布線解決方案都局限于只能處理幾百萬個單元。這常迫使物理實現工程師由于工具的局限性而不得不人工將電路模塊進行分割。而這也對工程師生產率造成了影響。
除非通過某些方式進行增強,不然的話即便目前最先進的Talus1.2布局布線解決方案的實際容量也只在200萬到500萬個單元之間,所提供的生產率為每天100-150萬單元。結果會造成一種由容量驅動的生產率差距。為了處理32/28納米節點設計,實現包括1000萬以上個單元的扁平電路模塊是必不可少的,如圖7所示(另見側邊欄)。
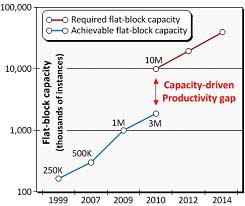
?
圖7.物理實現工具對扁平容量需求永不滿足。
在過去,一直是通過提供多線程功能來增強物理實現工具的容量和性能。在有些情況下,這些功能是被“生搬硬套”到的傳統工具上,效果有限。相較之下,Talus1.2中所有工具均完全內置有自帶的多線程功能。
前文已說過,多線程對工具的作用十分有限;基于阿姆達爾定律(Amdahl’slaw)等計算機科學定律,(伴隨在其核心運行的每個線程)線程的數量越來越多所起到的效果卻越來越小。簡單來說,就是告訴我們,任何程序的加速均會受到并行數量的限制(也就是說,程序的最長序列片斷關系到程序的其它部分),如圖8所示。
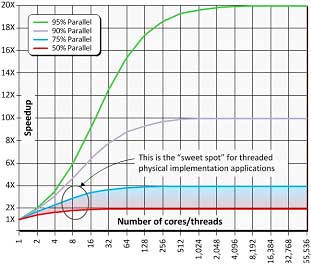
?
圖8.阿姆達爾定律反映了多線程的局限性。
對于被用來創建ASIC/ASSP/SoC器件的物理實現工具來說,這些工具的并行部分約占到了50%到75%。就如我們從圖8中所看到的“甜蜜點(sweetspot)”,而在best-case情景下,使用8-10個處理核心,只可獲得約3倍的加速。
幸運的是,通過將物理實現任務分發到多臺機器上就可以克服阿姆達爾定律所定義的局限性。如圖9所示,采用全新DistributedSmartSync(分布式智能同步)技術的TalusVortexFX提供了與貫穿物理實現流程所有步驟(時鐘樹綜合除外,這種方法對它起不了什么作用)的智能同步技術相結合的獨特分布式管理。微捷碼將這款最新解決方案稱為TalusVortexFX,它以DistributedSmartSync技術增強了Talus1.2。
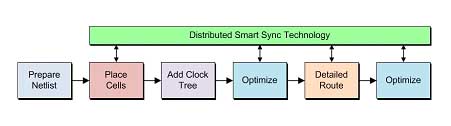
?
技術增強的TalusVortexFX流程的高級視圖
這種技術背后的概念是:對一個更大型的設計或模塊進行智能分割、將設計分區分散到整個網絡的服務器上執行設計實現、最后在主要流程階段自動對這些設計實施重新同步。本質上,這讓設計師能夠處理更大型設計,同時仍可獲得與他們之前在規模更小得多的電路模塊上所實現的相同的吞吐量(即每天單元數)。甚至在使用同等數量的內核/線程的時候,這種分布式方案的處理速度也較最佳多線程扁平流程要快上2-3倍。
?
圖10.僅多線程vs.多線程+分布式處理
物理實現工程師的生產率一般是根據每天單元數來進行衡量。使用最好的常規流程,可能獲得的最大生產率一般約為每天100萬個單元。相較之下,TalusVortexFX的分布式處理技術可將這一數字提高到每天200-500萬個單元,這種技術貫穿整個流程(對于只布局的門極電路而言,生產率可獲得更高的提升,這是一些用戶會關注的另一指標)。
還值得關注的是:TalusVortexFX為物理實現團隊提供了在設計周期早期執行快速的假設分析的能力,實現了最佳的面積、速度和功耗間折衷權衡。但還有一點也不容忽視:DistributedSmartSync技術完全增強了現有Talus1.2技術,進而促進了這款產品的快速采用。
至于保留現有硬件資源的投資方面,DistributedSmartSync技術讓用戶現有的內存為32GB和64GB的設備能夠得到充分利用。若未采用這項技術而轉向32/28納米節點設計,那么將要求用戶的設備要升級為內存128GB或256GB的設備,碰到大型服務器場的話這可能需耗費幾百萬美元。
除了通過縮短設計周期、提高工程團隊使用扁平方法的能力(在不必添加額外資源的前提下)、提高工程團隊的生產率以外,TalusVortexFX的使用通過縮短上市時間(贏利時間)還解決了如何滿足日益緊張的開發時間表這一問題。
總結
進行32/28納米及更小尺寸技術節點設計時會遇到許許多多的問題,包括低功耗設計、串擾效應、工藝變異以及操作模式和角點數量的顯著增加。微捷碼的TalusVortex1.2物理實現環境完全解決了所有這些問題。
此外,32/28納米節點設計尺寸及復雜性的不斷提高還造成了工程資源(不擴大團隊規模而取得更大成果)、硬件資源(無需升級主板、增加內存或購買全新設備,使用現有設備和服務器場來處理更大型設計)和如何滿足日益緊張開發時間表等方面相關問題的增加。為了解決這些問題,通過TalusVortexFX創新性的DistributedSmartSync?(分布式智能同步)技術,TalusVortex顯著地提高了其容量和性能。










 工商網監
工商網監
評論