 電子發燒友App
電子發燒友App


0 引言
語音識別技術的目的是使機器能理解人類語言,最終使人機通信成為現實。在過去幾十年,自動語音識別(AutomaticSpeech Recognition,ASR)技術已經取得了非常重大的進步。
ASR系統已經能從處理像數字之類的小詞匯量到廣播新聞之類的大詞匯量。然而針對識別效果來說,ASR 系統則相對較差。尤其在會話任務上,自動語音識別系統遠不及人類。因此,語音識別技術的應用已成為一個極具競爭性和挑戰性的高新技術產業。
隨著DSP技術的快速發展及性能不斷完善,基于DSP的語音識別算法得到了實現,并且在費用、功耗、速度、精確度和體積等方面有著PC機所不具備的優勢,具有廣闊的應用前景。
1 系統參數選擇
一般情況下,語音識別系統按照不同的角度、不同的應用范圍、不同的性能要求有不同的分類方法。針對識別對象不同有孤立詞識別、連接詞識別、連續語音識別與理解和會話語音識別等。針對識別系統的詞匯量有小詞匯量語音識別(1~20個詞匯)、中詞匯量識別(20~1 000個詞匯)和大詞匯量(1 000以上個詞匯)語音識別。針對發音人范圍來分,分為特定人語音識別、非特定人語音識別、自適應語音識別。
本文主要研究非特定人小詞匯量連續語音實時識別系統。
1.1 語音識別系統
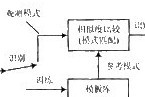
語音識別本質上是一種模式識別的過程,即未知語音的模式與已知語音的參考模式逐一進行比較,最佳匹配的參考模式被作為識別結果。語音識別系統一般包括前端處理、特征參數提取、模型訓練和識別部分。圖1所示是基于模式匹配原理的語音識別系統框圖。
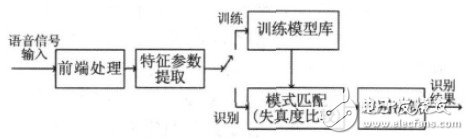
圖1 語音識別系統基本框圖
1.2 特征參數
語音信號中含有非常豐富的信息,包括影響語音識別的重要信息,也包括對語音識別無關緊要甚至會降低識別率的冗余信息。特征提取則可以去除冗余信息,將能準確表征語音信號特征的聲學參數提取出來用于后端的模型建立和匹配,大大減少了存儲空間、訓練和測試時間。對特定人語音識別來說,希望提取的特征參數盡可能少的反映語義信息,盡可能多的反映說話人的個人信息,而對非特定人語音識別來說,則相反。
現在較常用的特征參數有線性預測參數(LPCC)、線譜對(LSP)參數、Mel頻率倒譜參數(MFCC)、感覺加權的線性預測(PLP)參數、動態差分參數和高階信號譜類特征等,尤其是LPCC和MFCC兩種參數最為常用。本文選擇MFCC作為特征參數。
1.3 模型訓練及模式識別
在識別系統后端,從已知模式中獲取用以表征該模式本質特征的模型參數即形成模式庫,再將輸入的語音提取特征矢量參數后與已建立的聲學模型進行相似度比較,同時根據一定的專家知識(如構詞規則,語法規則等)和判別規則決策出最終的識別結果。
目前,語音識別所應用模型匹配技術主要有動態時間規整(DTW)、隱馬爾可夫模型(HMM)、人工神經元網絡(ANN)和支持向量機(SVM)等。DTW 是基本的語音相似性或相異性的一種測量工具,僅僅適合于孤立詞語音識別系統中。在解決非特定人、大詞匯量、連續語音識別問題時較之HMM 算法相形見絀。HMM 模型是隨機過程的數學模型,它用統計方式建立語音信號的動態模型,將聲學模型和語言模型融入語音識別搜索算法中,被認為是語音識別中最有效的模型。
然而由Vapnik和co-workers提出來的SVM 基于結構風險最小化準則和非線性和函數,具有更好的泛化能力和分類精確度。目前,SVM 已經成功應用于語音識別與話者識別。
除此之外,Ganapathiraju等人已經將支持向量機成功運用到復雜的大詞表非特定人連續語音識別上來。因此本文選擇SVM結合VQ完成語音模式識別。
2 系統構建及實現
為了更好地體現DSP的實時性,選擇的合適參數相當重要。考慮到DSP的存儲容量和實時性要求,本文首先選用Matlab平臺對系統進行仿真以比較選取合適的參數。
2.1 Matlab平臺上的仿真實現
2.1.1 實驗數據的建立
基于Matlab平臺,本文實驗語音信號在安靜的實驗室環境下用普通的麥克風通過Windows音頻設備和Cool edit軟件進行錄制,語速一般,音量適中,文件存儲格式為wav文件。語音采樣頻率為8kHz,采樣量化精度為16bit,雙聲道。
由于無調音節有412個,有調音節為1 282個,若采用SVM 對所有音節進行分類,數據量很龐大,故本文選擇10個人對6個不固定的連續漢語數字進行發音,每人發音15次,音節切分后共900個樣本,其中600個樣本作為訓練樣本集,其余300個樣本用于特定人的識別;另外選擇5個人對漢語數字0~9發音,每人發音3次,共150個測試樣本作為非特定人的識別。此外,以上選取的訓練或測試樣本均考慮到0~9共10個數字的均勻分布,并且樣本類型通過手工標定。
2.1.2 基于Matlab的語音識別系統的仿真及性能分析
首先對語音信號進行了預處理及時域分析:使用H(Z)=1-0.9375z-1 進行預加重處理;同時考慮語音信號的短時平穩性,進行分幀加窗---選用Hamming窗,幀長32ms,幀移是10ms.本文所設計系統為小詞匯量的連續語音識別,考慮到訓練時的工作量和運算量,選用音節作為基本識別單元。語音特征參數矢量采用12維MFCC、12維一階MFCC以及每幀的短時歸一化能量共25維構成。
本文構造了基于SVM 的連續語音識別系統。系統前端采用MFCC特征參數、并用遺傳算法(GA)與矢量量化(VQ)混合算法對其進行聚類得到優化碼本,然后將所得碼本作為 SVM 模式訓練和識別算法的輸入,按照相應的準則最終得到識別的結果。語音識別系統流程圖如圖2所示。
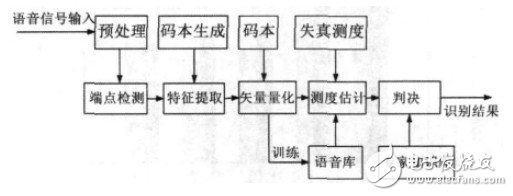
圖2 語音識別系統流程圖
首先對不同初始種群數的語音識別系統性能進行了分析。表1給出了不同初始種群下的識別系統性能,從表中可以得出,在迭代次數為100、初始種群數為100時,種群最終平均適應度和正識率最高,之后隨著初始種群數繼續增加,平均適應度和正識率都在降低。綜合考慮迭代所需時間和正識率,本文折衷采用初始種群數為80進行系統的仿真和實現。
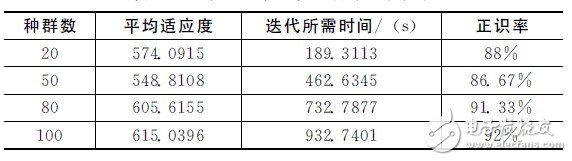
表1 不同初始種群下的識別系統性能
種群數平均適應度迭代所需時間/ (s) 正識率系統設計中考慮到MFCC參數數據量太大,對模型訓練和識別的時間有很大的影響,因此選擇矢量量化對數據進行分類。矢量量化的關鍵問題是如何獲取VQ碼本及碼本長度的確定,對此進行了仿真比較。
表2給出了不同VQ算法對正識率的影響比較。由表可以采用種群數為80,碼本長度為16,核函數為 RBF,選用的改進遺傳算法(GA)時系統的正識率要明顯高于LBG和傳統GA.LBG容易陷入局部最優,傳統GA 具有全局搜索能力,但收斂速度慢。實驗證明,改進的GA較好地解決了這兩者的問題,收斂速度較快,正識率也有較為明顯的提高。
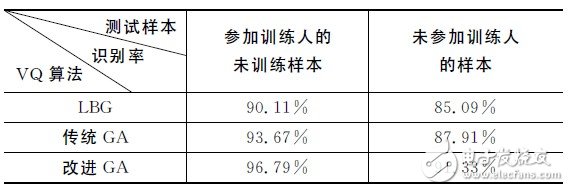
表2 不同VQ算法對正識率的影響比較
在此基礎上比較了傳統GA和優化后GA對不同碼本長度失真測度的影響,如圖3所示。由圖可知,在碼本平均失真測度上,改進的GA比傳統GA在整體上明顯有所降低,即種群平均適應度更高。從圖3還可以發現碼本長度為32時失真測度達到最低,但相比碼本長度為16時的值減少的并不太明顯。 考慮到迭代時間問題,本文所采用的碼本長度為16.
不同SVM 核函數對語音識別系統性能也會有影響。SVM分類器的目的是設計一個具有良好性能的分類超平面,以滿足在高維特征空間中能通過這個分類超平面區分多類數據樣本。
已有文獻證明一對一分類器在邊界距離上比一對多分類器更精確,故本文采用一對一方法對多類數據樣本進行訓練和識別。
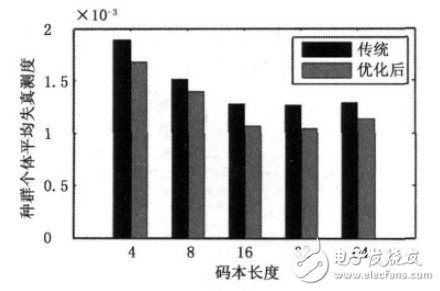
圖3 碼本長度的失真測度對比
表3給出了針對非特定人的不同SVM 核函數的識別系統性能。表中顯示,在取C =3,γ= 125(這里的25為特征參數維數)情況下,盡管核函數為RBF時所需的支持向量數要略高于核函數為Sigmoid時,但系統的正確識別率要明顯高于采用其他核函數的系統,因此本文選取RBF作為核函數。
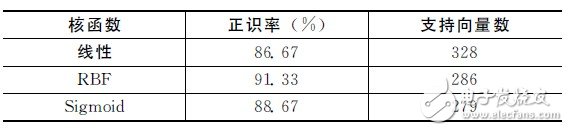
表3 不同SVM 核函數的識別系統性能
通過Matlab仿真分析了不同的矢量量化算法、SVM 核函數和初始種群數對語音識別系統性能產生的影響,為語音識別系統在DSP上的實現提供了參數和模型的選擇。












 工商網監
工商網監
評論