 電子發燒友App
電子發燒友App


引言
隨著現代科技和計算機技術的不斷發展,人們在與機器的信息交流中,需要一種更加方便、自然的交互方式,實現人機之間的語音交互,讓機器聽懂人話是人們夢寐以求的事情。語音識別技術的發展,使得這一理想得以實現,把語音識別技術與機器人控制技術相結合,正成為目前研究的熱點,不但具有較好的理論意義,而且有較大的實用價值。
語音識別技術應用于機器人系統大多是針對特定的環境,設計出語音命令來進行控制的。只需要對幾十個字或詞的命令行進語音識別,便可使得原本需要手工操作的工作由語音輕松完成。本文針對現有機器人平臺,設計一個非特定人的孤立詞語音識別系統。
1、語音識別原理及JuliUS簡介
1.1 基于HMM的語音識別原理
語音識別系統是一種模式識別系統,系統首先對語音信號進行分析,得到語音的特征參數,然后對這些參數進行處理,形成標準的模板。這個過程稱為訓練或學習。當有測試語音進入系統時,系統將對這些語音信號進行處理,然后進行參考模板的匹配,得出結果。此時便完成了語音識別的過程。
目前,HMM作為語音信號的一種統計模型,是語音識別技術的主流建模方法,正在語音處理各個領域中獲得廣泛的應用。現在許多商用語音軟件,以及各種具有優良性能的語音識別系統,都是在此模型上開發的,已經形成了完整的理論框架。
基于HMM模式匹配算法的語音識別系統表現為:在訓練階段,采用HMM訓練算法為每一個詞條建立一個HMM模型。詞條經過反復訓練后,將得到的對應HMM模型加入HMM模型庫中以數據的形式保存。在匹配階段,也就是識別階段,采用HMM匹配算法將輸入的未知語音信號與訓練階段得到的模型庫中的模型進行匹配,輸出語音識別的結果。
1.2 JuliUS簡介
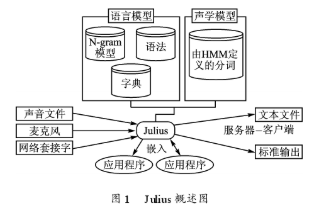
Julius是日本京都大學和日本IPA(Information-tech-nology Promotion Agency)聯合開發的一個實用高效雙通道的大詞匯連續語音識別引擎。目前已經能較好地應用于日語和漢語的大詞匯量連續的語音識別系統。Julius由純C語言開發,遵循GPL開源協議,能夠運行在Lin-ux、Windows、Mac:OS X、Solaris以及其他Unix平臺。Julius最新的版本采用模塊化的設計思想,使得各功能模塊可以通過參數配置。
Julius的運行需要一個語言模型和一個聲學模型。利用Julius,通過結合語言模型和聲學模型,可以很方便地建立一個語音識別系統。語言模型包括一個詞的發音字典和語法約束。Julius支持的語言模型包括:N-gram模型,以規則為基礎的語法和針對孤立詞識別的簡單單詞列表。聲學模型必須是以分詞為單位且由HMM定義的。
應用程序可以有兩種方式與Julius交互:一種是基于套接字的服務器一客戶端通信方式,另一種是基于函數庫的嵌入方式。在這兩種情況下,要識別過程結束,識別結果就被送入應用程序中,應用程序就能得到Julius引擎的現有狀態和統計,并可以操作官。Julius概述如圖1所示。
2、系統框架
2.1 硬件結構
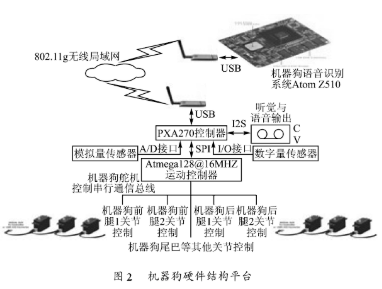
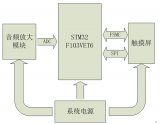
在語音識別的機器狗控制系統中Atom Z510為訓練學習機大腦(1.1 GHz主頻的Intel Atom Z510嵌入式控制平臺),它主要完成語音識別的功能。PXA270控制器(Intel公司于2003年底推出的性能強勁的PXA27x系列嵌入式處理器,基于ARMv5E的XScale內核,最高頻率可達624MHz)作為機器狗本體上的核心智能控制器,接收Atom Z510識別后的結果,發出控制命令。ATmega128控制器(Atmel公司的8位系列單片機中的一種,運行頻率16 MHz)完成基于串行總線的數字舵機控制,完成對機器狗的前后腿以及尾巴等關節控制。機器狗硬件結構平臺如圖2所示。
2.2 軟件結構
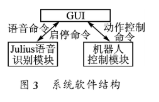
整個機器人系統包括3個模塊:Julius語音識別模塊、GUI人機界面、機器人控制模塊。Julius將識別的語音命令提交給GUI模塊,并在GUI上顯示;同時GUI將語音命令轉化為動作控制命令并發給機器人控制模塊;GUI還可以控制Julius的啟動和停止。其中機器人控制模塊主要在PXA270上,而語音識別和GUI是在Atom Z510上。系統軟件模型如圖3所示。
3 、語音識別系統構建
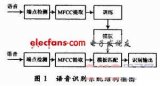
一個完整的語音識別系統一般包括3部分:聲學模型、語言模型和識別器。在本系統中只建立基于控制命令(動詞)的識別語法,其他詞忽略,因此沒有構建語言模型;識別器采用Julius開源平臺,此部分只用配置參數和相關文件。本文主要工作是聲學模型訓練和語音識別系統構建。
3.1 聲學模型訓練
聲學模型是識別系統的底層模型,是語音識別系統中最關鍵的一部分,它是每個聲學單元的聲學模型參數集合。本系統的聲學模型是使用HTK對采集的語音庫進行多次迭代訓練后提取的,基于詞的聲學特征向量集。HTK(HMM Tools Kit)是由英國劍橋大學工程系的語音視覺和機器人技術工作組(Speech Vision and Robotics Group)開發,專門用于建立和處理HMM的實驗工具包,主要應用于語音識別領域,也可用于語音模型的測試和分析。其具體訓練步驟如下:
(1)數據準備
收集漢語標準普通話的語料庫,并將語料庫中的語音標記,創建語音識別單元元素列表文件。
(2)特征提取
本系統采用MFCC進行語音的特征參數提取,訓練中將每一個語音文件用工具HCopy轉換成MFCC格式。
(3)HMM定義
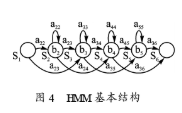
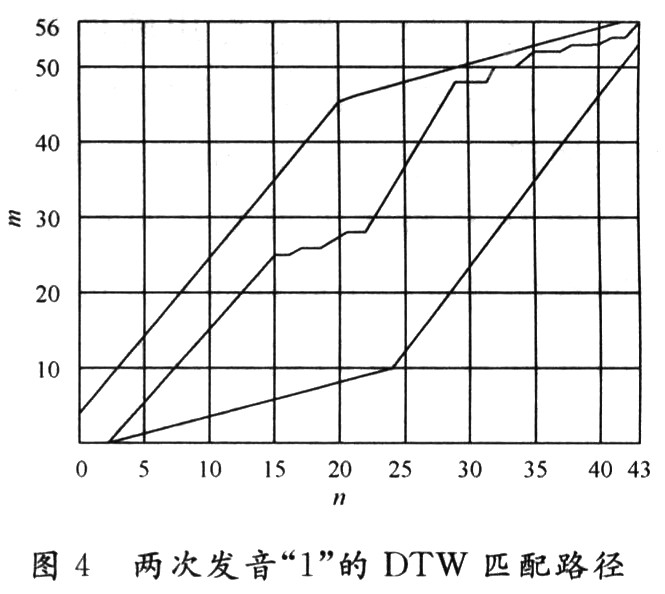
在訓練HMM模型時要給出模型的初始框架,本系統中的HMM模型選擇同一個結構,如圖4所示。該模型包含4個活動狀態{S2,S3,S4,S5),開始和結束(這里是S1.S6),是非發散狀態。觀察函數bi是帶對角矩陣的高斯分布,狀態的可能轉換由aij表示。
(4)HMM訓練
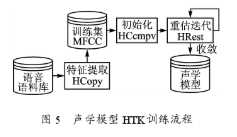
本系統先使用HInit工具對HMM模型進行初始化,再用HCompv工具來對模型進行平坦初始化。HMM模型的每個狀態給定相同的平均向量和變化向量,在整個訓練集上全局計算而得。最后用HRest的多次估計迭代,估計出HMM模型參數的最佳值,經多次迭代,將訓練得到的單個HMM模型整合到一個hmmsdef.mmf文件中。聲學模型HTK訓練流程如圖5所示。
3.2 Julius應用
3.2.1 Julius部署
在本系統中語音識別部分是部署在Atom Z510上,而Atom Z510上首先需要移植linux操作系統(本系統采用的是ubuntu8.10)以上步驟在此不詳細介紹,文獻中有詳細說明。語音識別的核心部分是Julius識別器,需要將Julius源碼編譯部署到Atom Z510平臺。其步驟如下:
①要確保linux系統中有以下支持庫:Zlib、flex、OSS音頻驅動接口、ESounD和libsndfile。
②從Julius官網下載源代碼Julius-4.1.5。
③解壓:tar-zxjf julius-4.1.5。
④編譯:%./configure,%make,%make install。
3.2.2 Julius配置
Julius全部采用C語言代碼實現,采用模塊化設計方式,而且各功能模塊可配置。在使用前需要將配置參數寫入jconf文件,此文件作為運行參數載入系統,系統掃描參數配置并啟動各功能塊。其中重點介紹以下幾個配置參數:
◆-dfa rtdog.dfa,指定語法文件rtdog.dfa;
◆-v rtdog.dict,指定字典文件;
◆-h rtdog.binhmm,指定HMM模型文件;
◆-lv 8000,設定音頻的閾值便于濾去噪音;
◆-rejectshort 600,設定最小的語音長度;
◆-input mic,設定語音的輸入方式為microphone。
3.3 語音識別系統軟件設計
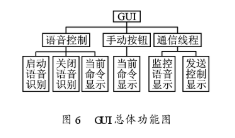
3.3.1 GUI設計
本系統為了方便測試,采用QT4的圖形庫來開發人機界面(GUI),同時加入了手動控制的按鈕。其總體功能如圖6所示。通信線程是本系統的數據傳輸樞紐,十分重要。在QT中通過對線程類QThread繼承來實現新的線程設計。該類提供了創建一個新線程以及控制線程運行的各種方法。線程是通過QThread::run()重載函數開始執行的。在本系統中設計了1個數據通信線程,用它來不斷地讀取共享內存中的語音命令,然后將其轉化為控制命令傳給機器人控制模塊。
3.3.2 模塊間通信
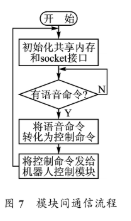
由于系統的3個模塊不在同一個平臺上部署,運行過程中需要進行數據通信。GUI和Julius都部署在Atom Z510平臺上,但屬于2個進程,它們之間可以通過共享內存來交互數據。而GUI和機器人控制模塊就需要通過網絡通信來實現數據交互。這里采用的是基于TCP的socket編程接口來實現模塊間的通信,模塊間通信流程如圖7所示。
4、 實驗測試
演示系統界面如圖8所示。本文使用大量的語音樣本來完成HTK的訓練和模式構建,語音樣本采用16 kHz采樣,16位量化。獨立的語音識別測試中,將訓練集以及測試集中語音樣本和識別結果進行了對比分析。本文語音樣本的內容包括訓練集(語料庫中的語音成分)和測試集(本實驗中采集的語音)。由于本系統只用提取語音命令,不需要完整句子的識別,所以沒有針對句子做測試。

本文對于訓練集基于詞的識別率為71.7%,測試集基于詞的識別率為56.5%,測試結果如表1所列。

表中各符號所表示的意義如下所示:
H,正確;S,替代錯誤;D,刪除錯誤;I,插入錯誤;N,標記文件中單元總數;SENT,句子,WORD:基本單元。
結語
本文在給定的實驗室機器人平臺上,設計了基于語音控制的機器狗系統。其中,語音識別子系統通過HTK和Julius的開源平臺構建而成。經過測試分析,該系統能夠較好地識別人發出的語音命令,簡化了機器人的操作,使機器與人的交互更加智能化。
責任編輯:gt





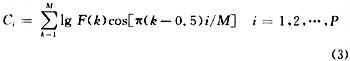







 工商網監
工商網監
評論