 電子發燒友App
電子發燒友App


想了很久,要不要寫這篇文章?最后覺得對操作系統感興趣的人還是很多,寫吧。我不一定能造出玉,但我可以拋出磚。
包括我在內的很多人都對51使用操作系統呈悲觀態度,因為51的片上資源太少。但對于很多要求不高的系統來說,使用操作系統可以使代碼變得更直觀,易于維護,所以在51上仍有操作系統的生存機會。
流行的uCos,Tiny51等,其實都不適合在2051這樣的片子上用,占資源較多,唯有自已動手,以不變應萬變,才能讓51也有操作系統可用。這篇貼子的目的,是教會大家如何現場寫一個OS,而不是給大家提供一個OS版本。提供的所有代碼,也都是示例代碼,所以不要因為它沒什么功能就說LAJI之類的話。如果把功能寫全了,一來估計你也不想看了,二來也失去靈活性沒有價值了。
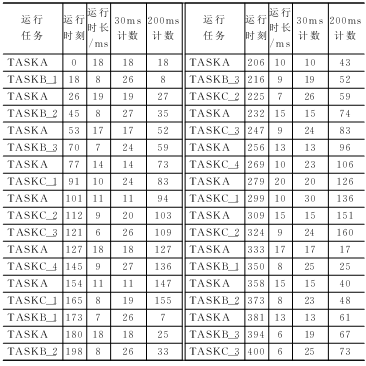
下面的貼一個示例出來,可以清楚的看到,OS本身只有不到10行源代碼,編譯后的目標代碼60字節,任務切換消耗為20個機器周期。相比之下,KEIL內嵌的TINY51目標代碼為800字節,切換消耗100~700周期。唯一不足之處是,每個任務要占用掉十幾字節的堆棧,所以任務數不能太多,用在128B內存的51里有點難度,但對于52來說問題不大。這套代碼在36M主頻的STC12C4052上實測,切換任務僅需2uS.
#include
#define MAX_TASKS 2 //任務槽個數。必須和實際任務數一至
#define MAX_TASK_DEP 12 //最大棧深。最低不得少于2個,保守值為12.
unsigned char idata task_stack[MAX_TASKS][MAX_TASK_DEP]; //任務堆棧。
unsigned char task_id; //當前活動任務號 //任務切換函數(任務調度器)
void task_switch(){
task_sp[task_id] = SP;
if(++task_id == MAX_TASKS)
task_id = 0;
SP = task_sp[task_id];
} //任務裝入函數。將指定的函數(參數1)裝入指定(參數2)的任務槽中。如果該槽中原來就有任務,則原任務丟失,但系統本身不會發生錯誤。
void task_load(unsigned int fn, unsigned char tid)
{
task_sp[tid] = task_stack[tid] + 1;
task_stack[tid][0] = (unsigned int)fn & 0xff;
task_stack[tid][1] = (unsigned int)fn 》》 8;
}//從指定的任務開始運行任務調度。調用該宏后,將永不返回。
#define os_start(tid) {task_id = tid,SP = task_sp[tid];return;}
/*======================以下為測試代碼======================*/ void task1()
{
static unsigned char i;
while(1){
i++;
task_switch(); //編譯后在這里打上斷點
}
} void task2()
{
static unsigned char j;
while(1){
j+=2;
task_switch(); //編譯后在這里打上斷點
}
} void main()
{
//這里裝載了兩個任務,因此在定義MAX_TASKS時也必須定義為2
task_load(task1, 0); //將task1函數裝入0號槽
task_load(task2, 1); //將task2函數裝入1號槽
os_start(0);
}
這樣一個簡單的多任務系統雖然不能稱得上真正的操作系統,但只要你了解了它的原理,就能輕易地將它擴展得非常強大,想知道要如何做嗎?
一。什么是操作系統?
人腦比較容易接受“類比”這種表達方式,我就用“公交系統”來類比“操作系統”吧。
當我們要解決一個問題的時候,是用某種處理手段去完成它,這就是我們常說的“方法”,計算機里叫“程序”(有時候也可以叫它“算法”)。
以出行為例,當我們要從A地走到B地的時候,可以走著去,也可以飛著去,可以走直線,也可以繞彎路,只要能從A地到B地,都叫作方法。這種從A地到B的需求,相當于計算機里的“任務”,而實現從A地到B地的方法,叫作“任務處理流程”
很顯然,這些走法中,并不是每種都合理,有些傻子都會采用的,有些是傻子都不采會用的。用計算機的話來說就是,有的任務處理流程好,有的任務處理流程好,有的處理流程差。
可以歸納出這么幾種真正算得上方法的方法:
有些走法比較快速,適合于趕時間的人;有些走法比較省事,適合于懶人;有些走法比較便宜,適合于窮人。
用計算機的話說就是,有些省CPU,有些流程簡單,有些對系統資源要求低。
現在我們可以看到一個問題:
如果全世界所有的資源給你一個人用(單任務獨占全部資源),那最適合你需求的方法就是好方法。但事實上要外出的人很多,例如10個人(10個任務),卻只有1輛車(1套資源),這叫作“資源爭用”。
如果每個人都要使用最適合他需求的方法,那司機就只好給他們一人跑一趟了,而在任一時刻里,車上只有一個乘客。這叫作“順序執行”,我們可以看到這種方法對系統資源的浪費是嚴重的。
如果我們沒有法力將1臺車變成10臺車來送這10個人,就只好制定一些機制和約定,讓1臺車看起來像10臺車,來解決這個問題的辦法想必大家都知道,那就是制定公交線路。
最簡單的辦法是將所有旅客需要走的起點與終點串成一條線,車在這條線上開,乘客則自已決定上下車。這就是最簡單的公交線路。它很差勁,但起碼解決客人們對車爭用。對應到計算機里,就是把所有任務的代碼混在一起執行。
這樣做既不優異雅,也沒效率,于是司機想了個辦法,把這些客戶叫到一起商量,將所有客人出行的起點與終點羅列出來,統計這些線路的使用頻度,然后制定出公交線路:有些路線可以合并起來成為一條線路,而那些不能合并的路線,則另行開辟行車車次,這叫作“任務定義”。另外,對于人多路線,車次排多點,時間上也優先安排,這叫作“任務優先級”。
經過這樣的安排后,雖然仍只有一輛車,但運載能力卻大多了。這套車次/路線的按排,就是一套“公交系統”。哈,知道什么叫操作系統了吧?它也就是這么樣的一種約定。
操作系統:
我們先回過頭歸納一下:
汽車 系統資源。主要指的是CPU,當然還有其它,比如內存,定時器,中斷源等。
客戶出行 任務
正在走的路線 進程
一個一個的運送旅客 順序執行
同時運送所有旅客 多任務并行
按不同的使用頻度制定路線并優先跑較繁忙的路線 任務優先級
計算機內有各種資源,單從硬件上說,就有CPU,內存,定時器,中斷源,I/O端口等。而且還會派生出來很多軟件資源,例如消息池。
操作系統的存在,就是為了讓這些資源能被合理地分配。
最后我們來總結一下,所謂操作系統,以我們目前權宜的理解就是:為“解決計算機資源爭用而制定出的一種約定”。
二.51上的操作系統
對于一個操作系統來說,最重要的莫過于并行多任務。在這里要澄清一下,不要拿當年的DOS來說事,時代不同了。況且當年IBM和小比爾著急將PC搬上市,所以才抄襲PLM(好象是叫這個名吧?記不太清)搞了個今天看來很“粗制濫造”的DOS出來。看看當時真正的操作系統---UNIX,它還在紙上時就已經是多任務的了。
對于我們PC來說,要實現多任務并不是什么問題,但換到MCU卻很頭痛:
1.系統資源少
在PC上,CPU主頻以G為單位,內存以GB為單位,而MCU的主頻通常只有十幾M,內存則是Byts.在這么少的資源上同時運行多個任務,就意味著操作系統必須盡可能的少占用硬件資源。
2.任務實時性要求高
PC并不需要太關心實時性,因為PC上幾乎所有的實時任務都被專門的硬件所接管,例如所有的聲卡網卡顯示上都內置有DSP以及大量的緩存.CPU只需坐在那里指手劃腳告訴這些板卡如何應付實時信息就行了。
而MCU不同,實時信息是靠CPU來處理的,緩存也非常有限,甚至沒有緩存。一旦信息到達,CPU必須在極短的時間內響應,否則信息就會丟失。
就拿串口通信來舉例,在標準的PC架構里,巨大的內存允許將信息保存足夠長的時間。而對于MCU來說內存有限,例如51僅有128字節內存,還要扣除掉寄存器組占用掉的8~32個字節,所以通常都僅用幾個字節來緩沖。當然,你可以將數據的接收與處理的過程合并,但對于一個操作系統來說,不推薦這么做。
假定以115200bps通信速率向MCU傳數據,則每個字節的傳送時間約為9uS,假定緩存為8字節,則串口處理任務必須在70uS內響應。
這兩個問題都指向了同一種解決思路:操作系統必須輕量輕量再輕量,最好是不占資源(那當然是做夢啦)。
可用于MCU的操作系統很多,但適合51(這里的51專指無擴展內存的51)幾乎沒有。前陣子見過一個“圈圈操作系統”,那是我所見過的操作系統里最輕量的,但仍有改進的余地。
很多人認為,51根本不適合使用操作系統。其實我對這種說法并不完全接受,否則也沒有這篇文章了。
我的看法是,51不適合采用“通用操作系統”。所謂通用操作系統就是,不論你是什么樣的應用需求,也不管你用什么芯片,只要你是51,通通用同一個操作系統。
這種想法對于PC來說沒問題,對于嵌入式來說也不錯,對AVR來說還湊合,而對于51這種“貧窮型”的MCU來說,不行。
怎樣行?量體裁衣,現場根據需求構建一個操作系統出來!
看到這里,估計很多人要翻白眼了,大體上兩種:
1.操作系統那么復雜,說造就造,當自已是神了?
2.操作系統那么復雜,現場造一個會不會出BUG?
哈哈,看清楚了?問題出在“復雜”上面,如果操作系統不復雜,問題不就解決了?
事實上,很多人對操作系統的理解是片面的,操作系統不一定要做得很復雜很全面,就算僅個多任務并行管理能力,你也可以稱它操作系統。
只要你對多任務并行的原理有所了解,就不難現場寫一個出來,而一旦你做到了這一點,為各任務間安排通信約定,使之發展成一個為你的應用系統量身定做的操作系統也就不難了。
為了加深對操作系統的理解,可以看一看《《演變》》這份PPT,讓你充分了解一個并行多任務是如何一步步從順序流程演變過來的。里面還提到了很多人都在用的“狀態機”,你會發現操作系統跟狀態機從原理上其實是多么相似。會用狀態機寫程序,都能寫出操作系統。
三file:///C:/DOCUME~1/ADMINI~1/LOCALS~1/Temp/msohtml1/01/clip_image001.gif
我的第一個操作系統
直接進入主題,先貼一個操作系統的示范出來。大家可以看到,原來操作系統可以做得么簡單。
當然,這里要申明一下,這玩意兒其實算不上真正的操作系統,它除了并行多任務并行外根本沒有別的功能。但凡事都從簡單開始,搞懂了它,就能根據應用需求,將它擴展成一個真正的操作系統。
好了,代碼來了。
將下面的代碼直接放到KEIL里編譯,在每個task?()函數的“task_switch();”那里打上斷點,就可以看到它們的確是“同時”在執行的。
#include
#define MAX_TASKS 2 //任務槽個數。必須和實際任務數一至
#define MAX_TASK_DEP 12 //最大棧深。最低不得少于2個,保守值為12.
unsigned char idata task_stack[MAX_TASKS][MAX_TASK_DEP];//任務堆棧。
unsigned char task_id; //當前活動任務號
//任務切換函數(任務調度器)
void task_switch()
{
task_sp[task_id] = SP;
if(++task_id == MAX_TASKS)
task_id = 0;
SP = task_sp[task_id];
}
//任務裝入函數。將指定的函數(參數1)裝入指定(參數2)的任務槽中。如果該槽中原來就有任務,則原任務丟失,但系統本身不會發生錯誤。
void task_load(unsigned int fn, unsigned char tid)
{
task_sp[tid] = task_stack[tid] + 1;
task_stack[tid][0] = (unsigned int)fn & 0xff;
task_stack[tid][1] = (unsigned int)fn 》》 8;
}
//從指定的任務開始運行任務調度。調用該宏后,將永不返回。
#define os_start(tid) {task_id = tid,SP = task_sp[tid];return;}
/*==================以下為測試代碼=====================*/
void task1()
{
static unsigned char i;
while(1){
i++;
task_switch();//編譯后在這里打上斷點
}
}
void task2()
{
static unsigned char j;
while(1){
j+=2;
task_switch();//編譯后在這里打上斷點
}
}
void main()
{
//這里裝載了兩個任務,因此在定義MAX_TASKS時也必須定義為2
task_load(task1, 0);//將task1函數裝入0號槽
task_load(task2, 1);//將task2函數裝入1號槽
os_start(0);
}
限于篇幅我已經將代碼作了簡化,并刪掉了大部分注釋,大家可以直接下載源碼包,里面完整的注解,并帶KEIL工程文件,斷點也打好了,直接按ctrl+f5就行了。
現在來看看這個多任務系統的原理:
這個多任務系統準確來說,叫作“協同式多任務”。
所謂“協同式”,指的是當一個任務持續運行而不釋放資源時,其它任務是沒有任何機會和方式獲得運行機會,除非該任務主動釋放CPU.
在本例里,釋放CPU是靠task_switch()來完成的.task_switch()函數是一個很特殊的函數,我們可以稱它為“任務切換器”。
要清楚任務是如何切換的,首先要回顧一下堆棧的相關知識。
有個很簡單的問題,因為它太簡單了,所以相信大家都沒留意過:
我們知道,不論是CALL還是JMP,都是將當前的程序流打斷,請問CALL和JMP的區別是什么?
你會說:CALL可以RET,JMP不行。沒錯,但原因是啥呢?為啥CALL過去的就可以用RET跳回來,JMP過去的就不能用RET來跳回呢?
很顯然,CALL通過某種方法保存了打斷前的某些信息,而在返回斷點前執行的RET指令,就是用于取回這些信息。
不用多說,大家都知道,“某些信息”就是PC指針,而“某種方法”就是壓棧。
很幸運,在51里,堆棧及堆棧指針都是可被任意修改的,只要你不怕死。那么假如在執行RET前將堆棧修改一下會如何?往下看:
當程序執行CALL后,在子程序里將堆棧剛才壓入的斷點地址清除掉,并將一個函數的地址壓入,那么執行完RET后,程序就跳到這個函數去了。
事實上,只要我們在RET前將堆棧改掉,就能將程序跳到任務地方去,而不限于CALL里壓入的地址。
重點來了。..。..
首先我們得為每個任務單獨開一塊內存,這塊內存專用于作為對應的任務的堆棧,想將CPU交給哪個任務,只需將棧指針指向誰內存塊就行了。
接下來我們構造一個這樣的函數:
當任務調用該函數時,將當前的堆棧指針保存一個變量里,并換上另一個任務的堆棧指針。這就是任務調度器了。
OK了,現在我們只要正確的填充好這幾個堆棧的原始內容,再調用這個函數,這個任務調度就能運行起來了。
那么這幾個堆棧里的原始內容是哪里來的呢?這就是“任務裝載”函數要干的事了。
在啟動任務調度前將各個任務函數的入口地址放在上面所說的“任務專用的內存塊”里就行了!對了,順便說一下,這個“任務專用的內存塊”叫作“私棧”,私棧的意思就是說,每個任務的堆棧都是私有的,每個任務都有一個自已的堆棧。
話都說到這份上了,相信大家也明白要怎么做了:
1.分配若干個內存塊,每個內存塊為若干字節:
這里所說的“若干個內存塊”就是私棧,要想同時運行幾少個任務就得分配多少塊。而“每個子內存塊若干字節”就是棧深。記住,每調一層子程序需要2字節。如果不考慮中斷,4層調用深度,也就是8字節棧深應該差不多了。
unsigned char idata task_stack[MAX_TASKS][MAX_TASK_DEP]
當然,還有件事不能忘,就是堆指針的保存處。不然光有堆棧怎么知道應該從哪個地址取數據啊
unsigned char idata task_sp[MAX_TASKS]
上面兩項用于裝任務信息的區域,我們給它個概念叫“任務槽”。有些人叫它“任務堆”,我覺得還是“槽”比較直觀
對了,還有任務號。不然怎么知道當前運行的是哪個任務呢?
unsigned char task_id
當前運行存放在1號槽的任務時,這個值就是1,運行2號槽的任務時,這個值就是2.。..
2.構造任務調度函函數:
void task_switch()
{
task_sp[task_id] = SP; //保存當前任務的棧指針
if(++task_id == MAX_TASKS) //任務號切換到下一個任務
task_id = 0;
SP = task_sp[task_id]; //將系統的棧指針指向下個任務的私棧。
}
3.裝載任務:
將各任務的函數地址的低字節和高字節分別入在
task_stack[任務號][0]和task_stack[任務號][1]中:
為了便于使用,寫一個函數: task_load(函數名, 任務號)
void task_load(unsigned int fn, unsigned char tid)
{
task_sp[tid] = task_stack[tid] + 1;
task_stack[tid][0] = (unsigned int)fn & 0xff;
task_stack[tid][1] = (unsigned int)fn 》》 8;
}
4.啟動任務調度器:
將棧指針指向任意一個任務的私棧,執行RET指令。注意,這可很有學問的哦,沒玩過堆棧的人腦子有點轉不彎:這一RET,RET到哪去了?嘿嘿,別忘了在RET前已經將堆棧指針指向一個函數的入口了。你別把RET看成RET,你把它看成是另一種類型的JMP就好理解了。
SP = task_sp[任務號];
return;
做完這4件事后,任務“并行”執行就開始了。你可以象寫普通函數一個寫任務函數,只需(目前可以這么說)注意在適當的時候(例如以前調延時的地方)調用一下task_switch(),以讓出CPU控制權給別的任務就行了。
最后說下效率問題。
這個多任務系統的開銷是每次切換消耗20個機器周期(CALL和RET都算在內了),貴嗎?不算貴,對于很多用狀態機方式實現的多任務系統來說,其實效率還沒這么高--- case switch和if()可不像你想像中那么便宜。
關于內存的消耗我要說的是,當然不能否認這種多任務機制的確很占內存。但建議大家不要老盯著編譯器下面的那行字“DATA = XXXbyte”。那個值沒意義,堆棧沒算進去。關于比較省內存多任務機制,我將來會說到。
概括來說,這個多任務系統適用于實時性要求較高而內存需求不大的應用場合,我在運行于36M主頻的STC12C4052上實測了一把,切換一個任務不到3微秒。
下回我們講講用KEIL寫多任務函數時要注意的事項。
下下回我們講講如何增強這個多任務系統,跑步進入操作系統時代。
四。用KEIL寫多任務系統的技巧與注意事項
C51編譯器很多,KEIL是其中比較流行的一種。我列出的所有例子都必須在KEIL中使用。為何?不是因為KEIL好所以用它(當然它的確很棒),而是因為這里面用到了KEIL的一些特性,如果換到其它編譯器下,通過編譯的倒不是問題,但運行起來可能是堆棧錯位,上下文丟失等各種要命的錯誤,因為每種編譯器的特性并不相同。所以在這里先說清楚這一點。
但是,我開頭已經說了,這套帖子的主要目的是闡述原理,只要你能把這幾個例子消化掉,那么也能夠自已動手寫出適合其它編譯器的OS.
好了,說說KEIL的特性吧,先看下面的函數:
sbit sigl = P1^7;
void func1()
{
register char data i;
i = 5;
do{
sigl = !sigl;
}while(--i);
}
你會說,這個函數沒什么特別的嘛!呵呵,別著急,你將它編譯了,然后展開匯編代碼再看看:
193: void func1(){
194: register char data i;
195: i = 5;
C:0x00C3 7F05 MOV R7,#0x05
196: do{
197: sigl = !sigl;
C:0x00C5 B297 CPL sigl(0x90.7)
198: }while(--i);
C:0x00C7 DFFC DJNZ R7,C:00C5
199: }
C:0x00C9 22 RET
看清楚了沒?這個函數里用到了R7,卻沒有對R7進行保護!
有人會跳起來了:這有什么值得奇怪的,因為上層函數里沒用到R7啊。呵呵,你說的沒錯,但只說對了一半:事實上,KEIL編譯器里作了約定,在調子函數前會盡可能釋放掉所有寄存器。通常性況下,除了中斷函數外,其它函數里都可以任意修改所有寄存器而無需先壓棧保護(其實并不是這樣,但現在暫時這樣認為,飯要一口一口吃嘛,我很快會說到的)。
這個特性有什么用呢?有!當我們調用任務切換函數時,要保護的對象里可以把所有的寄存器排除掉了,就是說,只需要保護堆棧即可!
現在我們回過頭來看看之前例子里的任務切換函數:
void task_switch()
{
task_sp[task_id] = SP; //保存當前任務的棧指針
if(++task_id == MAX_TASKS) //任務號切換到下一個任務
task_id = 0;
SP = task_sp[task_id]; //將系統的棧指針指向下個任務的私棧。
}
看到沒,一個寄存器也沒保護,展開匯編看看,的確沒保護寄存器。
好了,現在要給大家潑冷水了,看下面兩個函數:
void func1()
{
register char data i;
i = 5;
do{
sigl = !sigl;
}while(--i);
}
void func2()
{
register char data i;
i = 5;
do{
func1();
}while(--i);
}
父函數fun2()里調用func1(),展開匯編代碼看看:
193: void func1(){
194: register char data i;
195: i = 5;
C:0x00C3 7F05 MOV R7,#0x05
196: do{
197: sigl = !sigl;
C:0x00C5 B297 CPL sigl(0x90.7)
198: }while(--i);
C:0x00C7 DFFC DJNZ R7,C:00C5
199: }
C:0x00C9 22 RET
200: void func2(){
201: register char data i;
202: i = 5;
C:0x00CA 7E05 MOV R6,#0x05
203: do{
204: func1();
C:0x00CC 11C3 ACALL func1(C:00C3)
205: }while(--i);
C:0x00CE DEFC DJNZ R6,C:00CC
206: }
C:0x00D0 22 RET
看清楚沒?函數func2()里的變量使用了寄存器R6,而在func1和func2里都沒保護。
聽到這里,你可能又要跳一跳了:func1()里并沒有用到R6,干嘛要保護?沒錯,但編譯器是怎么知道func1()沒用到R6的呢?是從調用關系里推測出來的。
一點都沒錯,KEIL會根據函數間的直接調用關系為各函數分配寄存器,既不用保護,又不會沖突,KEIL好棒哦!!等一下,先別高興,換到多任務的環境里再試試:
void func1()
{
register char data i;
i = 5;
do{
sigl = !sigl;
}while(--i);
}
void func2()
{
register char data i;
i = 5;
do{
sigl = !sigl;
}while(--i);
}
展開匯編代碼看看:
193: void func1(){
194: register char data i;
195: i = 5;
C:0x00C3 7F05 MOV R7,#0x05
196: do{
197: sigl = !sigl;
C:0x00C5 B297 CPL sigl(0x90.7)
198: }while(--i);
C:0x00C7 DFFC DJNZ R7,C:00C5
199: }
C:0x00C9 22 RET
200: void func2(){
201: register char data i;
202: i = 5;
C:0x00CA 7F05 MOV R7,#0x05
203: do{
204: sigl = !sigl;
C:0x00CC B297 CPL sigl(0x90.7)
205: }while(--i);
C:0x00CE DFFC DJNZ R7,C:00CC
206: }
C:0x00D0 22 RET
看到了吧?哈哈,這回神仙也算不出來了。因為兩個函數沒有了直接調用的關系,所以編譯器認為它們之間不會產生沖突,結果分配了一對互相沖突的寄存器,當任務從func1()切換到func2()時,func1()中的寄存器內容就給破壞掉了。大家可以試著去編譯一下下面的程序:
sbit sigl = P1^7;
void func1()
{
register char data i;
i = 5;
do{
sigl = !sigl;
task_switch();
} while (--i);
}
void func2()
{
register char data i;
i = 5;
do{
sigl = !sigl;
task_switch();
}while(--i);
}
我們這里只是示例,所以仍可以通過手工分配不同的寄存器避免寄存器沖突,但在真實的應用中,由于任務間的切換是非常隨機的,我們無法預知某個時刻哪個寄存器不會沖突,所以分配不同寄存器的方法不可取。那么,要怎么辦呢?
這樣就行了:
sbit sigl = P1^7;
void func1()
{
static char data i;
while(1){
i = 5;
do{
sigl = !sigl;
task_switch();
}while(--i);
}
}
void func2()
{
static char data i;
while(1){
i = 5;
do{
sigl = !sigl;
task_switch();
}while(--i);
}
}
將兩個函數中的變量通通改成靜態就行了。還可以這么做:
sbit sigl = P1^7;
void func1()
{
register char data i;
while(1){
i = 5;
do{
sigl = !sigl;
}while(--i);
task_switch();
}
}
void func2()
{
register char data i;
while(1){
i = 5;
do{
sigl = !sigl;
}while(--i);
task_switch();
}
}
即,在變量的作用域內不切換任務,等變量用完了,再切換任務。此時雖然兩個任務仍然會互相破壞對方的寄存器內容,但對方已經不關心寄存器里的內容了。
以上所說的,就是“變量覆蓋”的問題。現在我們系統地說說關于“變量覆蓋”。
變量分兩種,一種是全局變量,一種是局部變量(在這里,寄存器變量算到局部變量里)。
對于全局變量,每個變量都會分配到單獨的地址。
而對于局部變量,KEIL會做一個“覆蓋優化”,即沒有直接調用關系的函數的變量共用空間。由于不是同時使用,所以不會沖突,這對內存小的51來說,是好事。
但現在我們進入多任務的世界了,這就意味著兩個沒有直接調用關系的函數其實是并列執行的,空間不能共用了。怎么辦呢?一種笨辦法是關掉覆蓋優化功能。呵呵,的確很笨。
比較簡單易行一個解決辦法是,不關閉覆蓋優化,但將那些在作用域內需要跨越任務(換句話說就是在變量用完前會調用task_switch()函數的)變量通通改成靜態(static)即可。這里要對初學者提一下,“靜態”你可以理解為“全局”,因為它的地址空間一直保留,但它又不是全局,它只能在定義它的那個花括號對{}里訪問。
靜態變量有個副作用,就是即使函數退出了,仍會占著內存。所以寫任務函數的時候,盡量在變量作用域結束后才切換任務,除非這個變量的作用域很長(時間上長),會影響到其它任務的實時性。只有在這種情況下才考慮在變量作用域內跨越任務,并將變量申明為靜態。
事實上,只要編程思路比較清析,很少有變量需要跨越任務的。就是說,靜態變量并不多。
說完了“覆蓋”我們再說說“重入”。
所謂重入,就是一個函數在同一時刻有兩個不同的進程復本。對初學者來說可能不好理解,我舉個例子吧:
有一個函數在主程序會被調用,在中斷里也會被調用,假如正當在主程序里調用時,中斷發生了,會發生什么情況?
void func1()
{
static char data i;
i = 5;
do{
sigl = !sigl;
}while(--i);
}
假定func1()正執行到i=3時,中斷發生,一旦中斷調用到func1()時,i的值就被破壞了,當中斷結束后,i == 0.
以上說的是在傳統的單任務系統中,所以重入的機率不是很大。但在多任務系統中,很容易發生重入,看下面的例子:
void func1()
{
。..。
delay();
。..。
}
void func2()
{
。..。
delay();
。..。
}
void delay()
{
static unsigned char i;//注意這里是申明為static,不申明static的話會發生覆蓋問題。而申明為static會發生重入問題。麻煩啊
for(i=0;i《10;i++)
task_switch();
}
兩個并行執行的任務都調用了delay(),這就叫重入。問題在于重入后的兩個復本都依賴變量i來控制循環,而該變量跨越了任務,這樣,兩個任務都會修改i值了。
重入只能以防為主,就是說盡量不要讓重入發生,比如將代碼改成下面的樣子:
#define delay() {static unsigned char i; for(i=0;i《10;i++) task_switch();}//i仍定義為static,但實際上已經不是同一個函數了,所以分配的地址不同。
void func1()
{
。..。
delay();
。..。
}
void func2()
{
。..。
delay();
。..。
}
用宏來代替函數,就意味著每個調用處都是一個獨立的代碼復本,那么兩個delay實際使用的內存地址也就不同了,重入問題消失。
但這種方法帶來的問題是,每調用一次delay(),都會產生一個delay的目標代碼,如果delay的代碼很多,那就會造成大量的rom空間占用。有其它辦法沒?
本人所知有限,只有最后一招了:
void delay() reentrant
{
unsigned char i;
for(i=0;i《10;i++)
task_switch();
}
加入reentrant申明后,該函數就可以支持重入。但小心使用,申明為重入后,函數效率極低!
最后附帶說下中斷。因為沒太多可說的,就不單獨開章了。
中斷跟普通的寫法沒什么區別,只不過在目前所示例的多任務系統里因為有堆棧的壓力,所以要使用using來減少對堆棧的使用(順便提下,也不要調用子函數,同樣是為了減輕堆棧壓力)
用using,必須用#pragma NOAREGS關閉掉絕對寄存器訪問,如果中斷里非要調用函數,連同函數也要放在#pragma NOAREGS的作用域內。如例所示:
#pragma SAVE
#pragma NOAREGS //使用using時必須將絕對寄存器訪問關閉
void clock_timer(void) interrupt 1 using 1 //使用using是為了減輕堆棧的壓力
}
#pragma RESTORE
改成上面的寫法后,中斷固定占用4個字節堆棧。就是說,如果你在不用中斷時任務棧深定為8的話,現在就要定為8+4 = 12了。
另外說句廢話,中斷里處理的事一定要少,做個標記就行了,剩下的事交給對應的任務去處理。
現在小結一下:
切換任務時要保證沒有寄存器跨越任務,否則產生任務間寄存器覆蓋。 使用靜態變量解決
切換任務時要保證沒有變量跨越任務,否則產生任務間地址空間(變量)覆蓋。 使用靜態變量解決
兩個不同的任務不要調用同時調用同一個函數,否則產生重入覆蓋。 使用重入申明解決










 工商網監
工商網監
評論