 電子發(fā)燒友App
電子發(fā)燒友App


前言
? ? ? ?本文總結(jié)了幾種網(wǎng)上或者論文中常見的MapReduce模式和算法,并系統(tǒng)化的解釋了這些技術的不同之處。所有描述性的文字和代碼都使用了標準hadoop的MapReduce模型,包括Mappers, Reduces, Combiners, Partitioners,和 sorting。詳細分析如下所示。
基本MapReduce模式
計數(shù)與求和
問題陳述: 有許多文檔,每個文檔都有一些字段組成。需要計算出每個字段在所有文檔中的出現(xiàn)次數(shù)或者這些字段的其他什么統(tǒng)計值。例如,給定一個log文件,其中的每條記錄都包含一個響應時間,需要計算出平均響應時間。
解決方案:
讓我們先從簡單的例子入手。在下面的代碼片段里,Mapper每遇到指定詞就把頻次記1,Reducer一個個遍歷這些詞的集合然后把他們的頻次加和。
?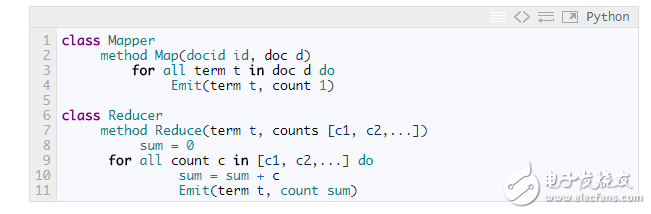
這種方法的缺點顯而易見,Mapper提交了太多無意義的計數(shù)。它完全可以通過先對每個文檔中的詞進行計數(shù)從而減少傳遞給Reducer的數(shù)據(jù)量:
?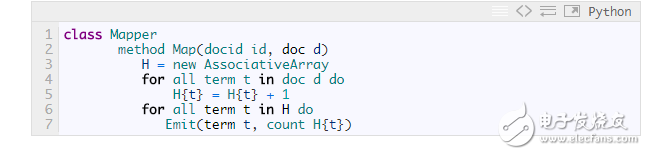
如果要累計計數(shù)的的不只是單個文檔中的內(nèi)容,還包括了一個Mapper節(jié)點處理的所有文檔,那就要用到Combiner了:
?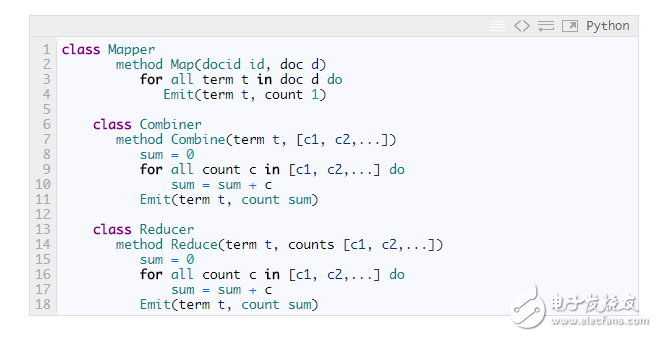
應用:
Log 分析, 數(shù)據(jù)查詢
整理歸類
問題陳述:
有一系列條目,每個條目都有幾個屬性,要把具有同一屬性值的條目都保存在一個文件里,或者把條目按照屬性值分組。 最典型的應用是倒排索引。
解決方案:
解決方案很簡單。 在 Mapper 中以每個條目的所需屬性值作為 key,其本身作為值傳遞給 Reducer。 Reducer 取得按照屬性值分組的條目,然后可以處理或者保存。如果是在構建倒排索引,那么 每個條目相當于一個詞而屬性值就是詞所在的文檔ID。
應用:
倒排索引, ETL
過濾 (文本查找),解析和校驗
問題陳述:
假設有很多條記錄,需要從其中找出滿足某個條件的所有記錄,或者將每條記錄傳換成另外一種形式(轉(zhuǎn)換操作相對于各條記錄獨立,即對一條記錄的操作與其他記錄無關)。像文本解析、特定值抽取、格式轉(zhuǎn)換等都屬于后一種用例。
解決方案:
非常簡單,在Mapper 里逐條進行操作,輸出需要的值或轉(zhuǎn)換后的形式。
應用:
日志分析,數(shù)據(jù)查詢,ETL,數(shù)據(jù)校驗
分布式任務執(zhí)行
問題陳述:
大型計算可以分解為多個部分分別進行然后合并各個計算的結(jié)果以獲得最終結(jié)果。
解決方案: 將數(shù)據(jù)切分成多份作為每個 Mapper 的輸入,每個Mapper處理一份數(shù)據(jù),執(zhí)行同樣的運算,產(chǎn)生結(jié)果,Reducer把多個Mapper的結(jié)果組合成一個。
案例研究: 數(shù)字通信系統(tǒng)模擬
像 WiMAX 這樣的數(shù)字通信模擬軟件通過系統(tǒng)模型來傳輸大量的隨機數(shù)據(jù),然后計算傳輸中的錯誤幾率。 每個 Mapper 處理樣本 1/N 的數(shù)據(jù),計算出這部分數(shù)據(jù)的錯誤率,然后在 Reducer 里計算平均錯誤率。
應用:
工程模擬,數(shù)字分析,性能測試
排序
問題陳述:
有許多條記錄,需要按照某種規(guī)則將所有記錄排序或是按照順序來處理記錄。
解決方案: 簡單排序很好辦 – Mappers 將待排序的屬性值為鍵,整條記錄為值輸出。 不過實際應用中的排序要更加巧妙一點, 這就是它之所以被稱為MapReduce 核心的原因(“核心”是說排序?因為證明Hadoop計算能力的實驗是大數(shù)據(jù)排序?還是說Hadoop的處理過程中對key排序的環(huán)節(jié)?)。在實踐中,常用組合鍵來實現(xiàn)二次排序和分組。
MapReduce 最初只能夠?qū)︽I排序, 但是也有技術利用可以利用Hadoop 的特性來實現(xiàn)按值排序。想了解的話可以看 這篇博客。
按照BigTable的概念,使用 MapReduce來對最初數(shù)據(jù)而非中間數(shù)據(jù)排序,也即保持數(shù)據(jù)的有序狀態(tài)更有好處,必須注意這一點。換句話說,在數(shù)據(jù)插入時排序一次要比在每次查詢數(shù)數(shù)據(jù)的時候排序更高效。
應用:
ETL,數(shù)據(jù)分析
#e#
非基本 MapReduce 模式
迭代消息傳遞 (圖處理)
問題陳述:
假設一個實體網(wǎng)絡,實體之間存在著關系。 需要按照與它比鄰的其他實體的屬性計算出一個狀態(tài)。這個狀態(tài)可以表現(xiàn)為它和其它節(jié)點之間的距離, 存在特定屬性的鄰接點的跡象, 鄰域密度特征等等。
解決方案:
網(wǎng)絡存儲為系列節(jié)點的結(jié)合,每個節(jié)點包含有其所有鄰接點ID的列表。按照這個概念,MapReduce 迭代進行,每次迭代中每個節(jié)點都發(fā)消息給它的鄰接點。鄰接點根據(jù)接收到的信息更新自己的狀態(tài)。當滿足了某些條件的時候迭代停止,如達到了最大迭代次數(shù)(網(wǎng)絡半徑)或兩次連續(xù)的迭代幾乎沒有狀態(tài)改變。從技術上來看,Mapper 以每個鄰接點的ID為鍵發(fā)出信息,所有的信息都會按照接受節(jié)點分組,reducer 就能夠重算各節(jié)點的狀態(tài)然后更新那些狀態(tài)改變了的節(jié)點。下面展示了這個算法:
class Mapper
method Map(id n, object N)
Emit(id n, object N)
for all id m in N.OutgoingRelations do
Emit(id m, message getMessage(N))
class Reducer
method Reduce(id m, [s1, s2,。..])
M = null
messages = []
for all s in [s1, s2,。..] do
if IsObject(s) then
M = s
else // s is a message
messages.add(s)
M.State = calculateState(messages)
Emit(id m, item M)
一個節(jié)點的狀態(tài)可以迅速的沿著網(wǎng)絡傳全網(wǎng),那些被感染了的節(jié)點又去感染它們的鄰居,整個過程就像下面的圖示一樣:
?
案例研究: 沿分類樹的有效性傳遞
問題陳述:
這個問題來自于真實的電子商務應用。將各種貨物分類,這些類別可以組成一個樹形結(jié)構,比較大的分類(像男人、女人、兒童)可以再分出小分類(像男褲或女裝),直到不能再分為止(像男式藍色牛仔褲)。這些不能再分的基層類別可以是有效(這個類別包含有貨品)或者已無效的(沒有屬于這個分類的貨品)。如果一個分類至少含有一個有效的子分類那么認為這個分類也是有效的。我們需要在已知一些基層分類有效的情況下找出分類樹上所有有效的分類。
解決方案:
這個問題可以用上一節(jié)提到的框架來解決。我們咋下面定義了名為 getMessage和 calculateState 的方法:
class N
State in {True = 2, False = 1, null = 0},
initialized 1 or 2 for end-of-line categories, 0 otherwise
method getMessage(object N)
return N.State
method calculateState(state s, data [d1, d2,。..])
return max( [d1, d2,。..] )
案例研究:廣度優(yōu)先搜索
問題陳述:需要計算出一個圖結(jié)構中某一個節(jié)點到其它所有節(jié)點的距離。
解決方案: Source源節(jié)點給所有鄰接點發(fā)出值為0的信號,鄰接點把收到的信號再轉(zhuǎn)發(fā)給自己的鄰接點,每轉(zhuǎn)發(fā)一次就對信號值加1:
class N
State is distance,
initialized 0 for source node, INFINITY for all other nodes
method getMessage(N)
return N.State + 1
method calculateState(state s, data [d1, d2,。..])
min( [d1, d2,。..] )
案例研究:網(wǎng)頁排名和 Mapper 端數(shù)據(jù)聚合
這個算法由Google提出,使用權威的PageRank算法,通過連接到一個網(wǎng)頁的其他網(wǎng)頁來計算網(wǎng)頁的相關性。真實算法是相當復雜的,但是核心思想是權重可以傳播,也即通過一個節(jié)點的各聯(lián)接節(jié)點的權重的均值來計算節(jié)點自身的權重。
class N
State is PageRank
method getMessage(object N)
return N.State / N.OutgoingRelations.size()
method calculateState(state s, data [d1, d2,。..])
return ( sum([d1, d2,。..]) )
要指出的是上面用一個數(shù)值來作為評分實際上是一種簡化,在實際情況下,我們需要在Mapper端來進行聚合計算得出這個值。下面的代碼片段展示了這個改變后的邏輯 (針對于 PageRank 算法):
class Mapper
method Initialize
H = new AssociativeArray
method Map(id n, object N)
p = N.PageRank / N.OutgoingRelations.size()
Emit(id n, object N)
for all id m in N.OutgoingRelations do
H{m} = H{m} + p
method Close
for all id n in H do
Emit(id n, value H{n})
class Reducer
method Reduce(id m, [s1, s2,。..])
M = null
p = 0
for all s in [s1, s2,。..] do
if IsObject(s) then
M = s
else
p = p + s
M.PageRank = p
Emit(id m, item M)
應用:
圖分析,網(wǎng)頁索引
#e#
值去重 (對唯一項計數(shù))
問題陳述: 記錄包含值域F和值域 G,要分別統(tǒng)計相同G值的記錄中不同的F值的數(shù)目 (相當于按照 G分組)。
這個問題可以推而廣之應用于分面搜索(某些電子商務網(wǎng)站稱之為Narrow Search)
Record 1: F=1, G={a, b}
Record 2: F=2, G={a, d, e}
Record 3: F=1, G={b}
Record 4: F=3, G={a, b}
Result:
a -》 3 // F=1, F=2, F=3
b -》 2 // F=1, F=3
d -》 1 // F=2
e -》 1 // F=2
解決方案 I:
第一種方法是分兩個階段來解決這個問題。第一階段在Mapper中使用F和G組成一個復合值對,然后在Reducer中輸出每個值對,目的是為了保證F值的唯一性。在第二階段,再將值對按照G值來分組計算每組中的條目數(shù)。
第一階段:
class Mapper
method Map(null, record [value f, categories [g1, g2,。..]])
for all category g in [g1, g2,。..]
Emit(record [g, f], count 1)
class Reducer
method Reduce(record [g, f], counts [n1, n2, 。..])
Emit(record [g, f], null )
第二階段:
class Mapper
method Map(record [f, g], null)
Emit(value g, count 1)
class Reducer
method Reduce(value g, counts [n1, n2,。..])
Emit(value g, sum( [n1, n2,。..] ) )
解決方案 II:
第二種方法只需要一次MapReduce 即可實現(xiàn),但擴展性不強。算法很簡單-Mapper 輸出值和分類,在Reducer里為每個值對應的分類去重然后給每個所屬的分類計數(shù)加1,最后再在Reducer結(jié)束后將所有計數(shù)加和。這種方法適用于只有有限個分類,而且擁有相同F(xiàn)值的記錄不是很多的情況。例如網(wǎng)絡日志處理和用戶分類,用戶的總數(shù)很多,但是每個用戶的事件是有限的,以此分類得到的類別也是有限的。值得一提的是在這種模式下可以在數(shù)據(jù)傳輸?shù)絉educer之前使用Combiner來去除分類的重復值。
class Mapper
method Map(null, record [value f, categories [g1, g2,。..] )
for all category g in [g1, g2,。..]
Emit(value f, category g)
class Reducer
method Initialize
H = new AssociativeArray : category -》 count
method Reduce(value f, categories [g1, g2,。..])
[g1‘, g2’,。.] = ExcludeDuplicates( [g1, g2,。.] )
for all category g in [g1‘, g2’,。..]
H{g} = H{g} + 1
method Close
for all category g in H do
Emit(category g, count H{g})
應用:
日志分析,用戶計數(shù)
互相關
問題陳述:有多個各由若干項構成的組,計算項兩兩共同出現(xiàn)于一個組中的次數(shù)。假如項數(shù)是N,那么應該計算N*N。
這種情況常見于文本分析(條目是單詞而元組是句子),市場分析(購買了此物的客戶還可能購買什么)。如果N*N小到可以容納于一臺機器的內(nèi)存,實現(xiàn)起來就比較簡單了。
配對法
第一種方法是在Mapper中給所有條目配對,然后在Reducer中將同一條目對的計數(shù)加和。但這種做法也有缺點:
· 使用 combiners 帶來的的好處有限,因為很可能所有項對都是唯一的
· 不能有效利用內(nèi)存
class Mapper
method Map(null, items [i1, i2,。..] )
for all item i in [i1, i2,。..]
for all item j in [i1, i2,。..]
Emit(pair [i j], count 1)
class Reducer
method Reduce(pair [i j], counts [c1, c2,。..])
s = sum([c1, c2,。..])
Emit(pair[i j], count s)
Stripes Approach(條方法?不知道這個名字怎么理解)
第二種方法是將數(shù)據(jù)按照pair中的第一項來分組,并維護一個關聯(lián)數(shù)組,數(shù)組中存儲的是所有關聯(lián)項的計數(shù)。The second approach is to group data by the first item in pair and maintain an associative array (“stripe”) where counters for all adjacent items are accumulated. Reducer receives all stripes for leading item i, merges them, and emits the same result as in the Pairs approach.
· 中間結(jié)果的鍵數(shù)量相對較少,因此減少了排序消耗。
· 可以有效利用 combiners。
· 可在內(nèi)存中執(zhí)行,不過如果沒有正確執(zhí)行的話也會帶來問題。
· 實現(xiàn)起來比較復雜。
· 一般來說, “stripes” 比 “pairs” 更快
class Mapper
method Map(null, items [i1, i2,。..] )
for all item i in [i1, i2,。..]
H = new AssociativeArray : item -》 counter
for all item j in [i1, i2,。..]
H{j} = H{j} + 1
Emit(item i, stripe H)
class Reducer
method Reduce(item i, stripes [H1, H2,。..])
H = new AssociativeArray : item -》 counter
H = merge-sum( [H1, H2,。..] )
for all item j in H.keys()
Emit(pair [i j], H{j})
應用:
文本分析,市場分析
References:
1. Lin J. Dyer C. Hirst G. Data Intensive Processing MapReduce
用MapReduce 表達關系模式
在這部分我們會討論一下怎么使用MapReduce來進行主要的關系操作。
篩選(Selection)
class Mapper
method Map(rowkey key, tuple t)
if t satisfies the predicate
Emit(tuple t, null)
投影(Projection)
投影只比篩選稍微復雜一點,在這種情況下我們可以用Reducer來消除可能的重復值
class Mapper
method Map(rowkey key, tuple t)
tuple g = project(t) // extract required fields to tuple g
Emit(tuple g, null)
class Reducer
method Reduce(tuple t, array n) // n is an array of nulls
Emit(tuple t, null)
合并(Union)
兩個數(shù)據(jù)集中的所有記錄都送入Mapper,在Reducer里消重。
class Mapper
method Map(rowkey key, tuple t)
Emit(tuple t, null)
class Reducer
method Reduce(tuple t, array n) // n is an array of one or two nulls
Emit(tuple t, null)
交集(Intersection)
將兩個數(shù)據(jù)集中需要做交叉的記錄輸入Mapper,Reducer 輸出出現(xiàn)了兩次的記錄。因為每條記錄都有一個主鍵,在每個數(shù)據(jù)集中只會出現(xiàn)一次,所以這樣做是可行的。
差異(Difference)
假設有兩個數(shù)據(jù)集R和S,我們要找出R與S的差異。Mapper將所有的元組做上標記,表明他們來自于R還是S,Reducer只輸出那些存在于R中而不在S中的記錄。
class Mapper
method Map(rowkey key, tuple t)
Emit(tuple t, string t.SetName) // t.SetName is either ‘R’ or ‘S’
class Reducer
method Reduce(tuple t, array n) // array n can be [‘R’], [‘S’], [‘R’ ‘S’], or [‘S’, ‘R’]
if n.size() = 1 and n[1] = ‘R’
Emit(tuple t, null)
分組聚合(GroupBy and Aggregation)
分組聚合可以在如下的一個MapReduce中完成。Mapper抽取數(shù)據(jù)并將之分組聚合,Reducer 中對收到的數(shù)據(jù)再次聚合。典型的聚合應用比如求和與最值可以以流的方式進行計算,因而不需要同時保有所有的值。但是另外一些情景就必須要兩階段MapReduce,前面提到過的惟一值模式就是一個這種類型的例子。
連接(Joining)
MapperReduce框架可以很好地處理連接,不過在面對不同的數(shù)據(jù)量和處理效率要求的時候還是有一些技巧。在這部分我們會介紹一些基本方法,在后面的參考文檔中還列出了一些關于這方面的專題文章。
分配后連接 (Reduce端連接,排序-合并連接)
這個算法按照鍵K來連接數(shù)據(jù)集R和L。Mapper 遍歷R和L中的所有元組,以K為鍵輸出每一個標記了來自于R還是L的元組,Reducer把同一個K的數(shù)據(jù)分裝入兩個容器(R和L),然后嵌套循環(huán)遍歷兩個容器中的數(shù)據(jù)以得到交集,最后輸出的每一條結(jié)果都包含了R中的數(shù)據(jù)、L中的數(shù)據(jù)和K。這種方法有以下缺點:
· Mapper要輸出所有的數(shù)據(jù),即使一些key只會在一個集合中出現(xiàn)。
· Reducer 要在內(nèi)存中保有一個key的所有數(shù)據(jù),如果數(shù)據(jù)量打過了內(nèi)存,那么就要緩存到硬盤上,這就增加了硬盤IO的消耗。
盡管如此,再分配連接方式仍然是最通用的方法,特別是其他優(yōu)化技術都不適用的時候。
class Mapper
method Map(null, tuple [join_key k, value v1, value v2,。..])
Emit(join_key k, tagged_tuple [set_name tag, values [v1, v2, 。..] ] )
class Reducer
method Reduce(join_key k, tagged_tuples [t1, t2,。..])
H = new AssociativeArray : set_name -》 values
for all tagged_tuple t in [t1, t2,。..] // separate values into 2 arrays
H{t.tag}.add(t.values)
for all values r in H{‘R’} // produce a cross-join of the two arrays
for all values l in H{‘L’}
Emit(null, [k r l] )
復制鏈接Replicated Join (Mapper端連接, Hash 連接)
在實際應用中,將一個小數(shù)據(jù)集和一個大數(shù)據(jù)集連接是很常見的(如用戶與日志記錄)。假定要連接兩個集合R和L,其中R相對較小,這樣,可以把R分發(fā)給所有的Mapper,每個Mapper都可以載入它并以連接鍵來索引其中的數(shù)據(jù),最常用和有效的索引技術就是哈希表。之后,Mapper遍歷L,并將其與存儲在哈希表中的R中的相應記錄連接,。這種方法非常高效,因為不需要對L中的數(shù)據(jù)排序,也不需要通過網(wǎng)絡傳送L中的數(shù)據(jù),但是R必須足夠小到能夠分發(fā)給所有的Mapper。
class Mapper
method Initialize
H = new AssociativeArray : join_key -》 tuple from R
R = loadR()
for all [ join_key k, tuple [r1, r2,。..] ] in R
H{k} = H{k}.append( [r1, r2,。..] )
method Map(join_key k, tuple l)
for all tuple r in H{k}
Emit(null, tuple [k r l] )












 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論