 電子發(fā)燒友App
電子發(fā)燒友App


本文主要介紹KMP算法和BM算法,它們分別是前綴匹配和后綴匹配的經(jīng)典算法。所謂前綴匹配是指:模式串和母串的比較從左到右,模式串的移動也是從左到右;所謂后綴匹配是指:模式串和母串的的比較從右到左,模式串的移動從左到右。看得出來前綴匹配和后綴匹配的區(qū)別就僅僅在于比較的順序不同。下文分別從最簡單的前綴蠻力匹配算法和后綴蠻力匹配算法入手,詳細的介紹KMP算法和BM算法以及它們的實現(xiàn)。
KMP算法
首先來看一下前綴蠻力匹配算法的代碼(以下代碼從linux源碼string.h中摳出),模式串和母串的比較是從左到右進行(strncmp()),如果找不到和模式串相同的子串,則從左到右移動模式串,距離為1(s++)。
har * strstr(register const char *s, register constchar *wanted)
{
register const size_t len = strlen(wanted);
if (len ==0) return (char*)s;
while (*s !=* wanted || strncmp(s, wanted, len))
if (*s++==‘\0’)
return (char*)NULL;
return (char*)s;
}
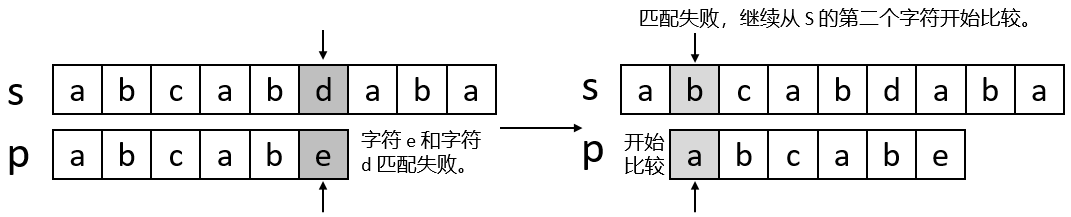
KMP算法中的KMP分別是指三個人名:Knuth、Morris、Pratt,其本質(zhì)也是前綴匹配算法,對比前綴蠻力匹配算法,區(qū)別在于它會動態(tài)調(diào)整每次模式串的移動距離,而不僅僅是加一,從而加快匹配過程。下圖通過一個直觀的例子展示前綴蠻力匹配算法和KMP算法的區(qū)別,前文提過,這二者唯一的不同在于模式串移動距離。
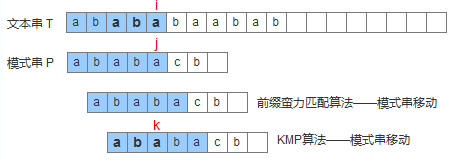
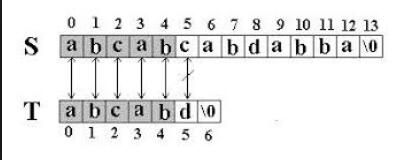
上圖中,前綴蠻力匹配算法發(fā)現(xiàn)匹配不上,就向右移動距離1,而KMP算法根據(jù)已經(jīng)比較過的前綴信息,了解到應(yīng)該移動距離為2;換句話說針對母串的下一個匹配字符,KMP算法了解它下回應(yīng)該匹配模式串的哪個位置,比如上圖中,針對母串的第i+1個字符,KMP算法了解它應(yīng)該匹配模式串的第k+1個字符。為什么會是這樣,這是因為母串的子串T[i-k, i]=aba,而模式串的子串P[0,k]=aba,這二者正好相等。所以模式串應(yīng)該移動到這個位置,從而讓母串的第i+1個字符和模式串的第k+1個字符繼續(xù)比較。
那k值又是如何尋找?請注意上圖中,模式串位置j已經(jīng)匹配上母串的位置i,也就是T[i-k, i] = P[j-k, j]=aba;根據(jù)前文的T[i-k, i] = P[0, k] = aba, 從而得出P[0, k] = P[j-k, j] = aba。通過觀察發(fā)現(xiàn),就是在模式的子串[0, j]中尋找一個最長前綴[0,k],從而使得[j-k, j] = [0,k];
于是可以定義一個jump數(shù)組,jump[j]=k,表示滿足P[0, k] ==P[j-k, j] 的最大k值,或者表述為:如果模式串j+1匹配不上母串的i+1,那跳轉(zhuǎn)到模式串k+1繼續(xù)比較。有了這個jump數(shù)組,就很容易寫出kmp算法的偽代碼:
j:=0;
for i:=1 to n do
Begin
while (j》0) and (P[j+1]《》T[i]) do j:=jump[j];[
if P[j+1]=T[i] then j:=j+1;
if j=m then
Begin
writeln(‘Pattern occurs with shift ’,i-m);
end;
end;
KMP算法中jump數(shù)組的構(gòu)建可以通過歸納法來解決,首先確定jump[1]=0;假設(shè)jump[j]=k,也就是P[0, k] == P[j-k, k],如果P[j+1] == P[k+1],那么得出[0,k+1] = P[j-k, j+1],從而更加定義得出jump[j+1] = k+1;
如果P[j+1] != P[k+1],那就接著比較P[j+1] ?= P[k1+1],其中(jump[k] = k1),根據(jù)(jump[k]=k1)的定義,P[0,k1] == P[k-k1, k],根據(jù)(jump[j]=k)的定義,P[0, k] == P[j-k, k],根據(jù)這兩個等式,推出P[0, k1] == P[j-k1, j],如果此時P[j+1] == P[k1+1],則得出:jump[j+1] = K1 +1 = jump[k] +1。
如果P[j+1] != P[K1+1],繼續(xù)遞歸比較P[j+1] 和P[jump[jump[k]]+1] …。 P[1]。
如果依次比較都不相等,那么jump[j+1] = 0;寫成偽代碼如下,可以看出其實就是模式串自我匹配的過程。
jump[1]:=0;
j:=0;
for i:=2 to m do
begin
while (j》0) and (P[j+1]《》P[i]) do j:=jump[j];
if P[j+1]=P[i] then j:=j+1;
jump[i]:=j;
end;
考慮模式串匹配不上母串的最壞情況,前綴蠻力匹配算法的時間復(fù)雜度最差是O(n×m),最好是O(n), 其中n為母串的長度,m為模式串的長度。KMP算法最差的時間復(fù)雜度是O(n);最好的時間復(fù)雜度是O(n/m)。
BM算法
后綴匹配,是指模式串的比較從右到左,模式串的移動也是從左到右的匹配過程,經(jīng)典的BM算法其實是對后綴蠻力匹配算法的改進。所以還是先從最簡單的后綴蠻力匹配算法開始。下面直接給出偽代碼,注意這一行代碼:j++;BM算法所做的唯一的事情就是改進了這行代碼,即模式串不是每次移動一步,而是根據(jù)已經(jīng)匹配的后綴信息,從而移動更多的距離。
j =0;
while (j 《= strlen(T) - strlen(P)) {
for (i = strlen(P) -1; i 》=0 && P[i] ==T[i + j]; --i)
if (i 《0)
match;
else
++j;
}
為了實現(xiàn)更快移動模式串,BM算法定義了兩個規(guī)則,好后綴規(guī)則和壞字符規(guī)則,如下圖可以清晰的看出他們的含義。利用好后綴和壞字符可以大大加快模式串的移動距離,不是簡單的++j,而是j+=max (shift(好后綴), shift(壞字符))
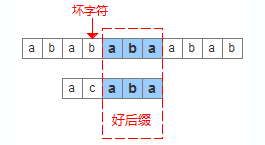
先來看如何根據(jù)壞字符來移動模式串,shift(壞字符)分為兩種情況:
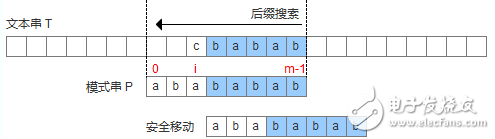
壞字符沒出現(xiàn)在模式串中,這時可以把模式串移動到壞字符的下一個字符,繼續(xù)比較,如下圖:
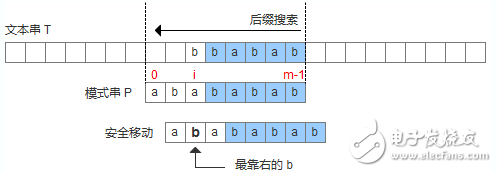
壞字符出現(xiàn)在模式串中,這時可以把模式串第一個出現(xiàn)的壞字符和母串的壞字符對齊,當然,這樣可能造成模式串倒退移動,如下圖:
為了用代碼來描述上述的兩種情況,設(shè)計一個數(shù)組bmBc[‘k’],表示壞字符‘k’在模式串中出現(xiàn)的位置距離模式串末尾的最大長度,那么當遇到壞字符的時候,模式串可以移動距離為: shift(壞字符) = bmBc[T[i]]-(m-1-i)。如下圖:
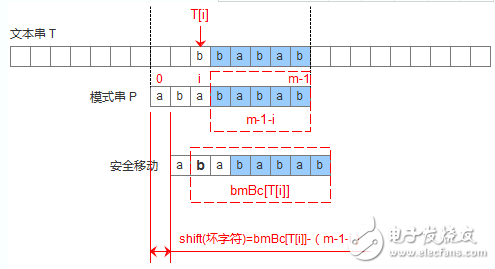
數(shù)組bmBc的創(chuàng)建非常簡單,直接貼出代碼如下:
void preBmBc(char*x, int m, int bmBc[]) {
int i;
for (i =0; i 《 ASIZE; ++i)
bmBc[i] = m;
for (i =0; i 《 m -1; ++i)
bmBc[x[i]] = m - i -1;
}
再來看如何根據(jù)好后綴規(guī)則移動模式串,shift(好后綴)分為三種情況:
模式串中有子串匹配上好后綴,此時移動模式串,讓該子串和好后綴對齊即可,如果超過一個子串匹配上好后綴,則選擇最靠左邊的子串對齊。
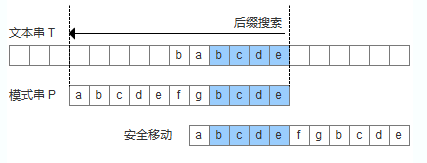
模式串中沒有子串匹配上后后綴,此時需要尋找模式串的一個最長前綴,并讓該前綴等于好后綴的后綴,尋找到該前綴后,讓該前綴和好后綴對齊即可。
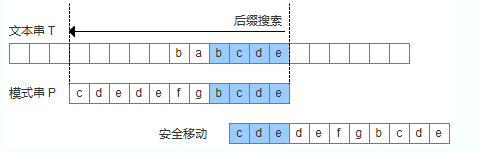
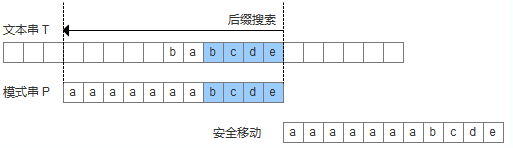
模式串中沒有子串匹配上后后綴,并且在模式串中找不到最長前綴,讓該前綴等于好后綴的后綴。此時,直接移動模式到好后綴的下一個字符。
為了實現(xiàn)好后綴規(guī)則,需要定義一個數(shù)組suffix[],其中suffix[i] = s 表示以i為邊界,與模式串后綴匹配的最大長度,如下圖所示,用公式可以描述:滿足P[i-s, i] == P[m-s, m]的最大長度s。

構(gòu)建suffix數(shù)組的代碼如下:
suffix[m-1]=m;
for (i=m-2;i》=0;--i){
q=i;
while(q》=0&&P[q]==P[m-1-i+q])
--q;
suffix[i]=i-q;
}
有了suffix數(shù)組,就可以定義bmGs[]數(shù)組,bmGs[i] 表示遇到好后綴時,模式串應(yīng)該移動的距離,其中i表示好后綴前面一個字符的位置(也就是壞字符的位置),構(gòu)建bmGs數(shù)組分為三種情況,分別對應(yīng)上述的移動模式串的三種情況
模式串中有子串匹配上好后綴
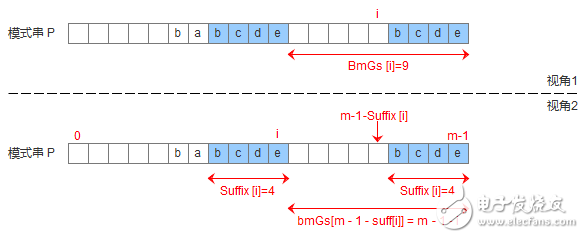
模式串中沒有子串匹配上好后綴,但找到一個最大前綴
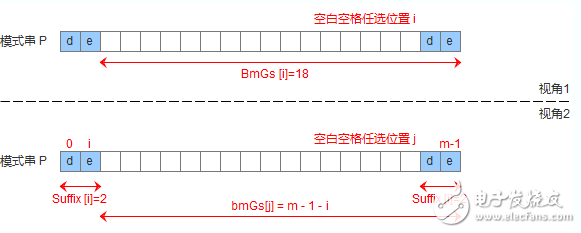
模式串中沒有子串匹配上好后綴,但找不到一個最大前綴

構(gòu)建bmGs數(shù)組的代碼如下:
void preBmGs(char*x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
for (i =0; i 《 m; ++i)
bmGs[i] = m;
j =0;
for (i = m -1; i 》=0; --i)
if (suff[i] == i +1)
for (; j 《 m -1- i; ++j)
if (bmGs[j] == m)
bmGs[j] = m -1- i;
for (i =0; i 《= m -2; ++i)
bmGs[m -1- suff[i]] = m -1- i;
}
再來重寫一遍BM算法:
j=0;
while (j 《= strlen(T) - strlen(P)) {
for (i = strlen(P) -1; i 》=0&& P[i] ==T[i + j]; --i)
if (i 《0)
match;
else
j += max(bmGs[i], bmBc[T[i]]-(m-1-i));
}
考慮模式串匹配不上母串的最壞情況,后綴蠻力匹配算法的時間復(fù)雜度最差是O(n×m),最好是O(n),其中n為母串的長度,m為模式串的長度。


















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論