 哈工大PyLTP工具實踐:NLP任務中四大必備技術(附代碼)
哈工大PyLTP工具實踐:NLP任務中四大必備技術(附代碼)
【導語】此文是作者基于 Python 構建知識圖譜的系列實踐教程,具有一定創新性和實用性。文章前半部分內容先介紹哈工大 pytltp 工具,包括安裝過程、中文分詞、詞性標注和實體識別的一些基本用法;后半部分內容講解詞性標注、實體識別、依存句法分析和語義角色標注及代碼實現。
【上篇】
一、哈工大LTP
LTP(Language Technology Platform)中文為語言技術平臺,是哈工大社會計算與信息檢索研究中心開發的一整套中文語言處理系統。LTP制定了基于XML的語言處理結果表示,并在此基礎上提供了一整套自底向上的豐富而且高效的中文語言處理模塊(包括詞法、句法、語義等6項中文處理核心技術),以及基于動態鏈接庫(Dynamic Link Library,DLL)的應用程序接口,可視化工具,并且能夠以網絡服務的形式進行使用。
LTP開發文檔:
https://ltp.readthedocs.io/zh_CN/latest/index.html
語言云LTP-Cloud:
http://www.ltp-cloud.com/
模型下載地址:
http://ltp.ai/download.html
在線演示案例如下圖所示:
相信從事NLP、數據挖掘、知識圖譜等領域的博友都知道哈工大LTP、同義詞詞林這些工具,該系列文章也會介紹相關的知識,希望對您有所幫助。
此外,再補充另一個在線NLP分析系統,感興趣的朋友們也可以試一下~
http://ictclas.nlpir.org/nlpir/
二.pyltp 終極安裝
下面介紹 Windows10 Python 環境下 LTP 的擴展包 pyltp 安裝過程。
1.常見錯誤
大家通常會調用 “pip install pyltp” 安裝該擴展包,但會遇到各種錯誤,下面介紹一種可行的方法。
2.安裝pyltp包
首先,安裝Python3.6環境,如下圖所示“python-3.6.7-amd64.exe”。
接著,下載pyltp擴展包的whl文件至本地,調用CMD環境進行安裝,注意需要將所在文件的路徑寫清楚。
pyltp-0.2.1-cp35-cp35m-win_amd64.whl (對應Python3.5版本)pyltp-0.2.1-cp36-cp36m-win_amd64.whl (對應Python3.6版本)pip install C:Python36Scriptspyltp-0.2.1-cp36-cp36m-win_amd64.whl
whl下載地址:
https://download.csdn.net/download/qq_22521211/10460778
安裝過程下圖所示,此時表示pyltp安裝成功。
注意,如果報錯“error:Microsoft Visual C++ 9.0 is required”,則安裝下面exe文件。
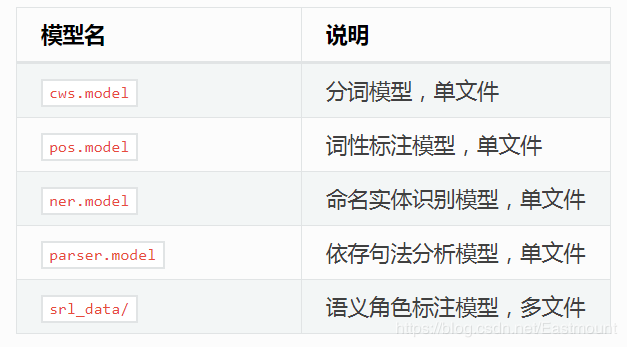
3.下載模型文件
最后需要下載模型文件,其下載地址為:
百度云
https://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569#list/path=%2F
七牛云
http://ltp.ai/download.html
本文下載3.4版本的模型,下載解壓如下圖所示:

模型對應的說明如下圖所示:
在編寫代碼時,需要導入指定文件夾中的模型,再進行中文分詞、詞性標注、命名實體識別、依存句法分析、語義角色標注等分析。例如:
#詞性標注pdir='AgriKG\ltp\pos.model'pos = Postagger()pos.load(pdir)postags = pos.postag(word) #基于分詞得到的list將下詞性標注postags = list(postags)print(u"詞性:", postags)
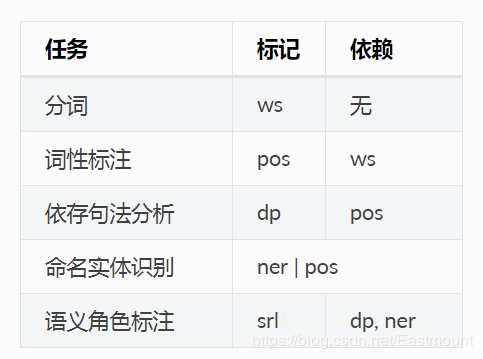
分詞、詞性標注、句法分析一系列任務之間存在依賴關系。舉例來講,對于詞性標注,必須在分詞結果之上進行才有意義。LTP中提供的5種分析之間的依賴關系如下所示:
講到這里,哈工大pyltp基本安裝成功,接下來將介紹它的基本用法。
基礎性文章,希望對入門者有所幫助。
三.中文分句和分詞
官方文檔:
https://pyltp.readthedocs.io/zh_CN/latest/api.html#id13
實現原理:
https://ltp.readthedocs.io/zh_CN/latest/theory.html#customized-cws-reference-label
1.中文分句
#-*-coding:utf-8-*-frompyltpimportSentenceSplitterfrompyltpimportSegmentorfrompyltpimportPostaggerfrom pyltp import NamedEntityRecognizer#分句text="貴州財經大學要舉辦大數據比賽嗎?那讓歐幾里得去問問看吧!其實是在貴陽花溪區吧。"sents=SentenceSplitter.split(text)print(' '.join(sents))
中文分句的輸出結果如下所示:
貴州財經大學要舉辦大數據比賽嗎?那讓歐幾里得去問問看吧!其實是在貴陽花溪區吧。
2.中文分詞
# -*- coding: utf-8 -*-from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizertext = "貴州財經大學要舉辦大數據比賽嗎?那讓歐幾里得去問問看吧!其實是在貴陽花溪區吧。"#中文分詞segmentor = Segmentor() #初始化實例segmentor.load("AgriKG\ltp\cws.model") #加載模型words = segmentor.segment(text) #分詞print(type(words))print(' '.join(words))segmentor.release()#釋放模型
輸出結果如下所示(人工換行):
此時的分詞效果并不理想,如 “大數據” 分為了“大”、“數據”,“歐幾里得”分為了“歐”、“幾”、“里”、“得”,“貴陽花溪區”分為了“貴陽”、“花溪區”等,故需要引入詞典進行更為準確的分詞。同時,返回值類型是native的VectorOfString類型,可以使用list轉換成Python的列表類型。
3.導入詞典中文分詞
pyltp 分詞支持用戶使用自定義詞典。分詞外部詞典本身是一個文本文件(plain text),每行指定一個詞,編碼同樣須為 UTF-8,比如“word”文件,如下圖所示:
完整代碼如下所示:
# -*- coding: utf-8 -*-from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizerldir='AgriKG\ltp\cws.model' #分詞模型dicdir='word' #外部字典text = "貴州財經大學要舉辦大數據比賽嗎?那讓歐幾里得去問問看吧!其實是在貴陽花溪區吧。"#中文分詞segmentor = Segmentor() #初始化實例segmentor.load_with_lexicon(ldir, 'word') #加載模型words = segmentor.segment(text) #分詞print(' '.join(words)) #分詞拼接words = list(words) #轉換listprint(u"分詞:", words)segmentor.release()#釋放模型
輸出結果如下所示,它將“大數據”、“歐幾里得”、“貴陽花溪區”進行了詞典匹配,再進行相關分詞,但是“貴州財經大學”仍然劃分為“貴州”、“財經”、“大學”。Why?
貴州 財經 大學 要 舉辦 大數據 比賽 嗎 ? 那 讓 歐幾里得 去 問問 看 吧 ! 其實 是 在 貴陽花溪區 吧 。分詞: ['貴州', '財經', '大學', '要', '舉辦', '大數據', '比賽', '嗎', '?', '那', '讓', '歐幾里得', '去', '問問', '看', '吧', '!', '其實','是','在','貴陽花溪區','吧','。']
4.個性化分詞
個性化分詞是 LTP 的特色功能。個性化分詞為了解決測試數據切換到如小說、財經等不同于新聞領域的領域。在切換到新領域時,用戶只需要標注少量數據。個性化分詞會在原有新聞數據基礎之上進行增量訓練。從而達到即利用新聞領域的豐富數據,又兼顧目標領域特殊性的目的。
pyltp 支持使用用戶訓練好的個性化模型。關于個性化模型的訓練需使用 LTP,詳細介紹和訓練方法請參考 個性化分詞 。在 pyltp 中使用個性化分詞模型的示例如下:
# -*- coding: utf-8 -*-from pyltp import CustomizedSegmentorcustomized_segmentor = CustomizedSegmentor() #初始化實例customized_segmentor.load('基本模型', '個性模型') #加載模型words = customized_segmentor.segment('亞硝酸鹽是一種化學物質')print ' '.join(words)customized_segmentor.release()
【下篇】
詞性標注、實體識別、依存句法分析和語義角色標注及代碼實現
一.詞性標注
詞性標注(Part-Of-Speech tagging, POS tagging)也被稱為語法標注(grammatical tagging)或詞類消疑(word-category disambiguation),是語料庫語言學(corpus linguistics)中將語料庫內單詞的詞性按其含義和上下文內容進行標記的文本數據處理技術。
pyltp詞性標注與分詞模塊相同,將詞性標注任務建模為基于詞的序列標注問題。對于輸入句子的詞序列,模型給句子中的每個詞標注一個標識詞邊界的標記。在LTP中,采用的北大標注集。
完整代碼:
# -*- coding: utf-8 -*-from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizerldir='AgriKG\ltp\cws.model' #分詞模型dicdir='word' #外部字典text = "貴州財經大學要舉辦大數據比賽嗎?"#中文分詞segmentor = Segmentor() #初始化實例segmentor.load_with_lexicon(ldir, 'word') #加載模型words = segmentor.segment(text) #分詞print(text)print(' '.join(words)) #分詞拼接words = list(words) #轉換listprint(u"分詞:", words)segmentor.release() #釋放模型#詞性標注pdir='AgriKG\ltp\pos.model'pos = Postagger() #初始化實例pos.load(pdir) #加載模型postags = pos.postag(words) #詞性標注postags = list(postags)print(u"詞性:", postags)pos.release() #釋放模型data = {"words": words, "tags": postags}print(data)
輸出結果如下圖所示,“貴州”詞性為“ns”(地理名詞 ),“財經”詞性為“n”(一般名詞),“舉辦”詞性為“v”(動詞),“嗎”詞性為“u”(助詞),“?”詞性為“wp”(標點)。
貴州財經大學要舉辦大數據比賽嗎?貴州 財經 大學 要 舉辦 大數據 比賽 嗎 ?分詞: ['貴州', '財經', '大學', '要', '舉辦', '大數據', '比賽', '嗎', '?']詞性: ['ns', 'n', 'n', 'v', 'v', 'n', 'v', 'u', 'wp']{'words': ['貴州', '財經', '大學', '要', '舉辦', '大數據', '比賽', '嗎', '?'], 'tags':['ns','n','n','v','v','n','v','u','wp']}
具體詞性為:
Tag Description Examplea adjective:形容詞 美麗 b other noun-modifier:其他的修飾名詞 大型, 西式 c conjunction:連詞 和, 雖然 d adverb:副詞 很 e exclamation:感嘆詞 哎 g morpheme 茨, 甥 h prefix:前綴 阿, 偽 i idiom:成語 百花齊放 j abbreviation:縮寫 公檢法 k suffix:后綴 界, 率 m number:數字 一, 第一 n general noun:一般名詞 蘋果 nd direction noun:方向名詞 右側 nh person name:人名 杜甫, 湯姆 ni organization name:公司名 保險公司,中國銀行nl location noun:地點名詞 城郊ns geographical name:地理名詞 北京nt temporal noun:時間名詞 近日, 明代nz other proper noun:其他名詞 諾貝爾獎o onomatopoeia:擬聲詞 嘩啦p preposition:介詞 在, 把,與q quantity:量詞 個r pronoun:代詞 我們u auxiliary:助詞 的, 地v verb:動詞 跑, 學習wp punctuation:標點 ,。!ws foreign words:國外詞 CPUx non-lexeme:不構成詞 萄, 翱zdescriptivewords描寫,敘述的詞瑟瑟,匆匆
二.命名實體識別
命名實體識別(Named Entity Recognition,簡稱NER),又稱作“專名識別”,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構名、專有名詞等。命名實體識別是信息提取、問答系統、句法分析、機器翻譯、面向Semantic Web的元數據標注等應用領域的重要基礎工具,在自然語言處理技術走向實用化的過程中占有重要地位。
在哈工大Pyltp中,NE識別模塊的標注結果采用O-S-B-I-E標注形式,其含義如下(參考):
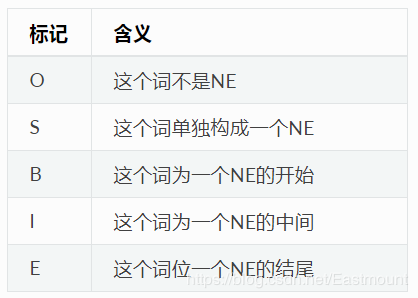
LTP中的NE 模塊識別三種NE,分別為人名(Nh)、機構名(Ni)、地名(Ns)。
完整代碼:
# -*- coding: utf-8 -*-from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import NamedEntityRecognizerldir='AgriKG\ltp\cws.model' #分詞模型dicdir='word' #外部字典text = "貴州財經大學要舉辦大數據比賽嗎?"#中文分詞segmentor = Segmentor() #初始化實例segmentor.load_with_lexicon(ldir, 'word') #加載模型words = segmentor.segment(text) #分詞print(text)print(' '.join(words)) #分詞拼接words = list(words) #轉換listprint(u"分詞:", words)segmentor.release() #釋放模型#詞性標注pdir='AgriKG\ltp\pos.model'pos = Postagger() #初始化實例pos.load(pdir) #加載模型postags = pos.postag(words) #詞性標注postags = list(postags)print(u"詞性:", postags)pos.release() #釋放模型data = {"words": words, "tags": postags}print(data)print(" ")#命名實體識別nermodel='AgriKG\ltp\ner.model'reg = NamedEntityRecognizer() #初始化命名實體實例reg.load(nermodel) #加載模型netags = reg.recognize(words, postags) #對分詞、詞性標注得到的數據進行實體標識netags = list(netags)print(u"命名實體識別:", netags)#實體識別結果data={"reg": netags,"words":words,"tags":postags}print(data)reg.release()
輸出結果如下圖所示,識別出的三個命名實體分別是:“貴州”(B-Ni)表示一個NE開始-機構名,“財經”(I-Ni)表示一個NE中間-機構名,“大學”(E-Ni)表示一個NE結束-機構名。
PS:雖然導入指定詞典,但“貴州財經大學”分詞仍然被分割,后續研究中。

三.依存句法分析
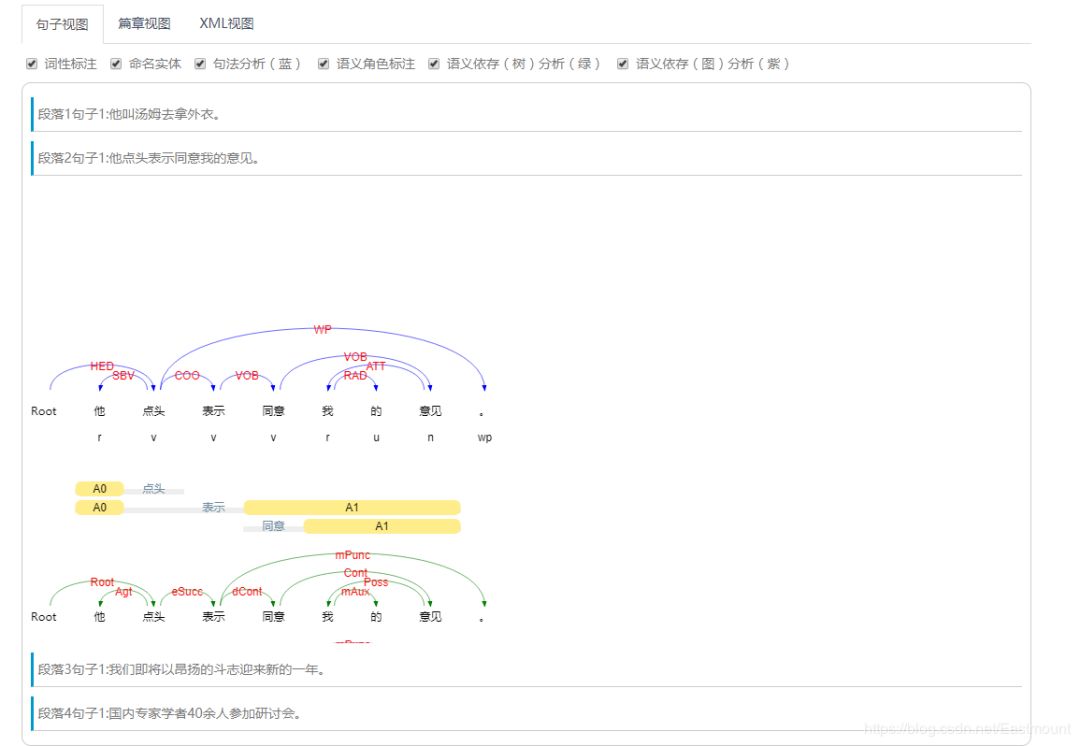
依存句法是由法國語言學家L.Tesniere最先提出。它將句子分析成一棵依存句法樹,描述出各個詞語之間的依存關系。也即指出了詞語之間在句法上的搭配關系,這種搭配關系是和語義相關聯的。如下圖所示:
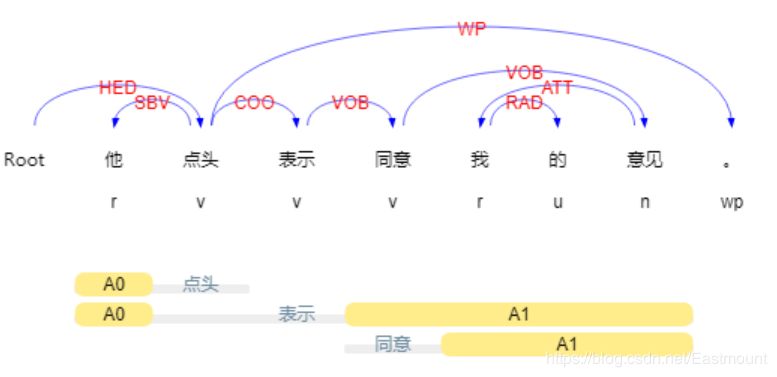
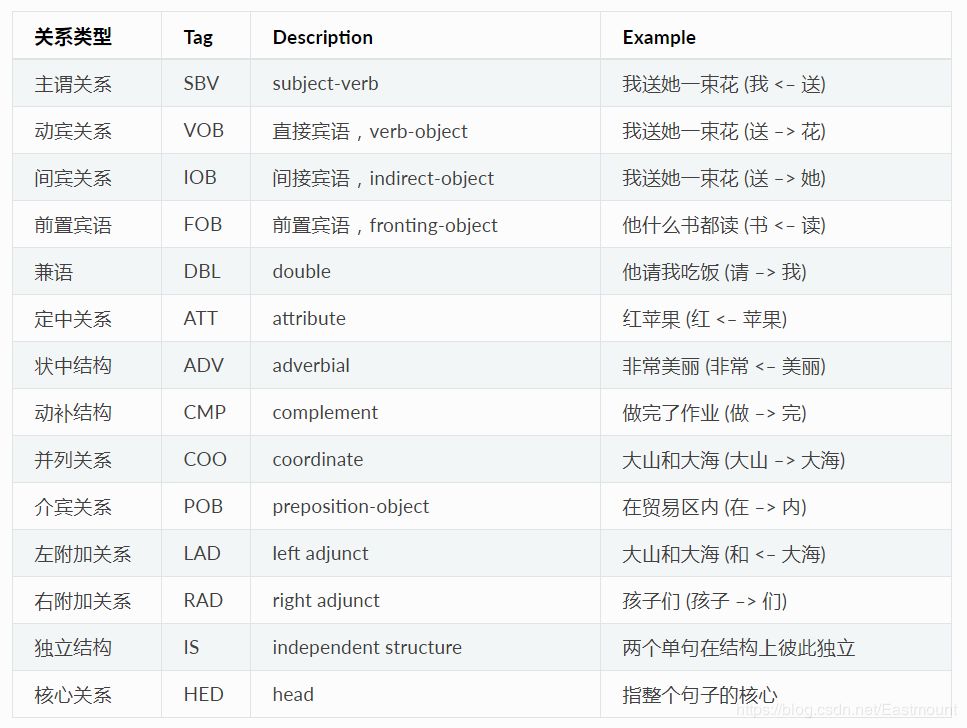
哈工大Pyltp的依存句法關系如下圖所示。
參考:
https://ltp.readthedocs.io/zh_CN/latest/appendix.html
完整代碼:
# -*- coding: utf-8 -*-from pyltp import SentenceSplitterfrom pyltp import Segmentorfrom pyltp import Postaggerfrom pyltp import Parserfrom pyltp import NamedEntityRecognizerldir = 'AgriKG\ltp\cws.model' #分詞模型dicdir = 'word' #外部字典text = "貴州財經大學要舉辦大數據比賽嗎?"#中文分詞segmentor = Segmentor() #初始化實例segmentor.load_with_lexicon(ldir, 'word') #加載模型words = segmentor.segment(text) #分詞print(text)print(' '.join(words)) #分詞拼接words = list(words) #轉換listprint(u"分詞:", words)segmentor.release() #釋放模型#詞性標注pdir = 'AgriKG\ltp\pos.model'pos = Postagger() #初始化實例pos.load(pdir) #加載模型postags = pos.postag(words) #詞性標注postags = list(postags)print(u"詞性:", postags)pos.release() #釋放模型data = {"words": words, "tags": postags}print(data)print(" ")#命名實體識別nermodel = 'AgriKG\ltp\ner.model'reg = NamedEntityRecognizer() #初始化命名實體實例reg.load(nermodel) #加載模型netags = reg.recognize(words, postags) #對分詞、詞性標注得到的數據進行實體標識netags = list(netags)print(u"命名實體識別:", netags)#實體識別結果data={"reg": netags,"words":words,"tags":postags}print(data)reg.release() #釋放模型print(" ")#依存句法分析parmodel = 'AgriKG\ltp\parser.model'parser = Parser() #初始化命名實體實例parser.load(parmodel) #加載模型arcs = parser.parse(words, postags) #句法分析#輸出結果print(words)print(" ".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))rely_id = [arc.head for arc in arcs] # 提取依存父節點idrelation = [arc.relation for arc in arcs] # 提取依存關系heads = ['Root' if id == 0 else words[id-1] for id in rely_id] # 匹配依存父節點詞語for i in range(len(words)): print(relation[i] + '(' + words[i] + ', ' + heads[i] + ')')parser.release()
輸出結果如下所示,其中ATT表示定中關系,如“貴州-大學”、“財經-大學”;SBV表示主謂關系,如“大學-舉辦”;ADV表示狀中結果“要-舉辦”;HED表示核心關系“舉辦-Root”,即“舉辦大數據”。
補充:arc.head表示依存弧的父節點詞的索引,arc.relation表示依存弧的關系。arc.head中的ROOT節點的索引是0,第一個詞開始的索引依次為1、2、3。

四.語義角色標注
該部分代碼僅供博友們參考,作者還在深入研究中。
#語義角色標注from pyltp import SementicRoleLabellersrlmodel = 'AgriKG\ltp\pisrl.model'labeller = SementicRoleLabeller() #初始化實例labeller.load(srlmodel) #加載模型words = ['元芳', '你', '怎么', '看']postags = ['nh', 'r', 'r', 'v']arcs = parser.parse(words, postags) #依存句法分析#arcs使用依存句法分析的結果roles = labeller.label(words, postags, arcs) #語義角色標注# 打印結果for role in roles: print(role.index, "".join( ["%s:(%d,%d)" % (arg.name, arg.range.start, arg.range.end) for arg in role.arguments]))labeller.release()#釋放模型
輸出結果如下:
3A0:(1,1)ADV:(2,2)
上面的例子,由于結果輸出一行,所以“元芳你怎么看”有一組語義角色。其謂詞索引為3,即“看”。這個謂詞有三個語義角色,范圍分別是(0,0)即“元芳”,(1,1)即“你”,(2,2)即“怎么”,類型分別是A0、A0、ADV。
希望這篇基礎性文章對你有所幫助,如果有錯誤或不足之處,還請海涵。
-
數據挖掘
+關注
關注
1文章
406瀏覽量
24287 -
nlp
+關注
關注
1文章
489瀏覽量
22069 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7725
原文標題:從0到1 | 手把手教你如何使用哈工大NLP工具——PyLTP!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
hanlp和jieba等六大中文分工具的測試對比

哈工大機器人積極籌備企業上市 謀求資本更高溢價
哈工大訊飛聯合實驗室發布基于全詞覆蓋的中文BERT預訓練模型






 工商網監
工商網監
評論