") 谷歌深度神經(jīng)網(wǎng)絡 基于數(shù)據(jù)共享的快速訓練方法
谷歌深度神經(jīng)網(wǎng)絡 基于數(shù)據(jù)共享的快速訓練方法
導讀:神經(jīng)網(wǎng)絡技術的普及離不開硬件技術的發(fā)展,GPU 和 TPU 等硬件型訓練加速器帶來的高算力極大的縮短了訓練模型需要的時間,使得研究者們能在短時間內(nèi)驗證并調整想法,從而快速得到理想的模型。然而,在整個訓練流程中,只有反向傳播優(yōu)化階段在硬件加速器上完成,而其他的例如數(shù)據(jù)載入和數(shù)據(jù)預處理等過程則不受益于硬件加速器,因此逐漸成為了整個訓練過程的瓶頸。本文應用數(shù)據(jù)共享和并行流水線的思想,在一個數(shù)據(jù)讀入和預處理周期內(nèi)多次重復使用上一次讀入的數(shù)據(jù)進行訓練,有效降低模型達到相同效果所需的總 epoch 次數(shù),在算法層面實現(xiàn)對訓練過程的加速。
網(wǎng)絡訓練的另一個瓶頸
網(wǎng)絡訓練速度的提升對神經(jīng)網(wǎng)絡的發(fā)展至關重要。過去的研究著重于如何在 GPU 和更專業(yè)的硬件設備上進行矩陣和張量的相關運算,從而代替 CPU 進行網(wǎng)絡訓練。GPU 和TPU 等相關專業(yè)計算硬件的通用性不像 CPU 那么廣泛,但是由于特殊的設計和計算單元構造,能夠在一些專門的任務中具有大幅超越 CPU 的表現(xiàn)。
由于 GPU 相關硬件善于進行矩陣和張量運算,因此通常用于訓練中的反向傳播計算過程,也就是參數(shù)優(yōu)化過程。然而,一個完整的網(wǎng)絡訓練流程不應該只包含反向傳播參數(shù)優(yōu)化過程,還應該有數(shù)據(jù)的讀入和預處理的過程,后者依賴于多種硬件指標,包括 CPU、硬盤、內(nèi)存大小、內(nèi)存帶寬、網(wǎng)絡帶寬,而且在不同的任務中細節(jié)也不盡相同,很難專門為這個概念寬泛的過程設計專用的硬件加速器,因此其逐漸成為了神經(jīng)網(wǎng)絡訓練過程中相對于方向傳播過程的另一個瓶頸。
因此,如果要進一步提升訓練速度,就需要考慮優(yōu)化非硬件加速的相關任務,而不僅僅是優(yōu)化反向傳播過程,這一優(yōu)化可以從兩個方面來進行:
(1) 提升數(shù)據(jù)載入和預處理的速度,類似于提升運算速度
(2) 減少數(shù)據(jù)載入和預處理的工作量
其中第一個思路更多的需要在硬件層面進行改進,而第二個思路則可以通過并行計算和數(shù)據(jù)共享,重復利用的方法來實現(xiàn)。
并行化問題
在了解具體的訓練優(yōu)化方法之前,我們需要知道神經(jīng)網(wǎng)絡訓練過程中的典型步驟,并做一些合理假設。下圖是一個典型的神經(jīng)網(wǎng)絡訓練流程:

圖1 一種典型的神經(jīng)網(wǎng)絡訓練流程
包含了 5 個步驟:read and decode 表示讀入數(shù)據(jù)并解碼,例如將圖片數(shù)據(jù)重新 resize成相應的矩陣形式;Shuffle 表示數(shù)據(jù)打亂,即隨機重新排列各個樣本;augmentation 表示對數(shù)據(jù)進行變換和增強;batch 對數(shù)據(jù)按照 batch size 進行打包;Apply SGD update表示將數(shù)據(jù)輸入到目標網(wǎng)絡中,并利用基于 SGD 的優(yōu)化算法進行參數(shù)學習。
不同的任務中或許會增加或減少某些環(huán)節(jié),但大致上的流程就是由這5步構成的。此外,網(wǎng)絡采用的學習優(yōu)化算法也會有不同,但都是基于 SGD 算法的,因此一律用“SGD update”來表示。這個流程每次運行對應一個 epoch,因此其輸入也就是整個訓練數(shù)據(jù)集。
可并行化是這個過程的重要特點,也是對其進行優(yōu)化的關鍵所在。不同的 epoch 流程之間的某些環(huán)節(jié)是可以同時進行的,例如在上一個 epoch 訓練時,就可以同步的讀入并處理下一個epoch 的數(shù)據(jù)。進一步地,作者將該流程劃分為兩個部分,上游(upstream)過程和下游(downstream)過程。其中上游過程包含數(shù)據(jù)載入和部分的數(shù)據(jù)預處理操作,而下游過程包含剩余的數(shù)據(jù)預處理操作和 SGD update 操作。這個劃分并不是固定的,不同的劃分決定了上游和下游過程的計算量和時間開銷。這樣劃分后,可以簡單地將并行操作理解為兩個流水線并行處理,如下圖:

圖1 基礎并行操作,idle表示空閑時間
上面的流水線處理上游過程,下面的處理下游過程。為了更好地表示對應關系,我在原圖的基礎上添加了一個紅色箭頭,表示左邊的上游過程是為右邊的下游過程提供數(shù)據(jù)的,他們共同構成一個 epoch 的完整訓練流程,并且必須在完成這個 epoch 的上游過程后才可以開始其下游過程,而與左側的上游過程豎直對應的下游過程則隸屬于上一個 epoch了。
從圖中可以看到,上游過程需要的時間是比下游過程更長的,因此在下游過程的流水線中有一部分時間(紅色部分)是空閑的等待時間,這也是本文中的主要優(yōu)化對象。此處做了第一個重要假設:上游過程的時間消耗大于下游過程,這使得訓練所需時間完全取決于上游過程。如果是小于關系,那么優(yōu)化的重點就會放到下游過程中,而下游過程中主要優(yōu)化內(nèi)容還是反向傳播過程。因此這個假設是將優(yōu)化內(nèi)容集中在下游過程流水線的充分條件。
那么如何利用這部分空閑時間呢?答案是繼續(xù)用來處理下游過程,如下圖:

圖2 單上游過程對應多下游過程
同一個上游過程可以為多個下游過程提供數(shù)據(jù)(圖中是 2 個),通過在上游過程和下游過程的分界處添加一個額外的數(shù)據(jù)復制和分發(fā)操作,就可以實現(xiàn)相同的上游數(shù)據(jù)在多個下游過程中的重復利用,從而減少乃至消除下游過程流水線中的空閑時間。這樣,在相同的訓練時間里,雖然和圖1中的一對一并行操作相比執(zhí)行了相同次數(shù)的上游過程,但是下游過程的次數(shù)卻提升了一定的倍數(shù),模型獲得了更多的訓練次數(shù),因此最終性能一定會有所提升。
那么進一步,如果要達到相同的模型性能,后者所需執(zhí)行的上游過程勢必比前者要少,因此從另個角度來講,訓練時間就得到了縮短,即達到相同性能所需的訓練時間更少。
但是,由于同一個上游過程所生成的數(shù)據(jù)是完全相同的,而在不同的反向傳播過程中使用完全相同的數(shù)據(jù)(repeated data),和使用完全不同的新數(shù)據(jù)(fresh data)相比,帶來的性能提升在一定程度上是會打折扣的。這個問題有兩個解決方法:
(1)由于下游過程并不是只包含最后的 SGD update 操作,還會包含之前的一些操作(只要不包含 read and encode 就可以),而諸如 shuffle 和 dropout 等具有隨機性的操作會在一定程度上帶來數(shù)據(jù)的差異性,因此合理的在下游過程中包含一些具有隨機性的操作,就可以保證最后用于 SGD update 的數(shù)據(jù)具有多樣性,這具體取決于上下游過程在整個流程中的分界點。
(2)在進行分發(fā)操作的同時對數(shù)據(jù)進行打亂,也能提高數(shù)據(jù)的多樣性,但由于數(shù)據(jù)打亂的操作本身要消耗計算資源,因此這不是一個可以隨意使用的方法。
我們將這種對上游過程的數(shù)據(jù)重復利用的算法稱為數(shù)據(jù)交流 data echoing,而重復利用的次數(shù)為重復因子 echoing factor。
數(shù)據(jù)重復利用效率分析
假設在完成一個上游過程的時間內(nèi),可以至多并行地完成 R 個下游過程,而數(shù)據(jù)的實際重復使用次數(shù)為e,通常 e 和 R 滿足 e
在此基礎上,可以得到以下關于訓練效率的結論:
(1)只要e不大于R,那么訓練時間就完全取決于上游過程所需的時間,而總訓練時間就取決于上游過程的次數(shù),也就是第一條流水線的總時長。
(2)由于重復數(shù)據(jù)的效果沒有新數(shù)據(jù)的效果好,因此要達到相同的模型性能,數(shù)據(jù)交流訓練方法就需要更多的 SGD update操作,也就是需要更多下游過程。理論上,只要下游過程的擴張倍數(shù)小于e倍,那么數(shù)據(jù)交流訓練方法所需的總訓練時長就小于傳統(tǒng)訓練方法。
(3)由于e的上限是R,那么R越大,e就可以取得越大,在下游過程只包含SGD update過程時,R最大。進一步地,若此時重復數(shù)據(jù)和新數(shù)據(jù)對訓練的貢獻完全相同,那么訓練加速效果將達到最大,即訓練時間縮短為原來的1/R。
然而在前面已經(jīng)提到了,對重復利用的數(shù)據(jù)而言,其效果是不可能和新數(shù)據(jù)媲美的,這是限制該訓練方法效率的主要因素。作者進一步探究了在訓練流程中的不同位置進行上下游過程分割和數(shù)據(jù)交流所帶來的影響。
(1)批處理操作(batching)前后的數(shù)據(jù)交流
如果將批處理操作劃分為下游過程,那么由于批處理操作本身具有一定的隨機性,不同的下游過程就會對數(shù)據(jù)進行不同的打包操作,最后送到 SGD update 階段的數(shù)據(jù)也就具備了一定的batch間的多樣性。當然,如果將批處理操作劃分為上游過程,那么R值會更大,可以執(zhí)行更多次的SGD update 訓練操作,當然這些訓練過程的數(shù)據(jù)相似度就更高了,每次訓練帶來的性能提升也可能變得更少。
(2)數(shù)據(jù)增強(data augmentation)前后的數(shù)據(jù)交流
如果在 data augmentation 之前進行數(shù)據(jù)交流,那么每個下游過程最終用于訓練的數(shù)據(jù)就更不相同,也更接近于新數(shù)據(jù)的效果,這個道理同批處理操作前后的數(shù)據(jù)交流是相同的,只不過數(shù)據(jù)交流操作的插入點更靠前,R值更小,帶來的數(shù)據(jù)差異性也更強。
(3)在數(shù)據(jù)交流的同時進行數(shù)據(jù)打亂
數(shù)據(jù)打亂本質上也是在提升分發(fā)到不同下游過程的數(shù)據(jù)的多樣性,但這是一個有開銷的過程,根據(jù)應用環(huán)境的不同,能進行數(shù)據(jù)打亂的范圍也不同。
進一步地,作者通過實驗在5個不同的方面評估了數(shù)據(jù)交流訓練方法帶來的性能提升,并得到了以下結論:
(1)數(shù)據(jù)交流能降低訓練模型達到相同效果所需的樣本數(shù)量。由于對數(shù)據(jù)進行了重復使用,因此相應的所需新數(shù)據(jù)數(shù)量就會減少。
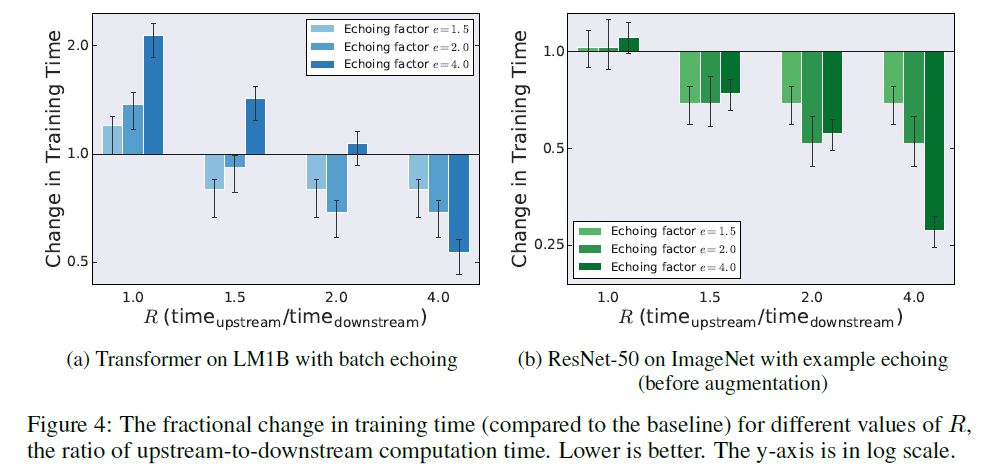
(2)數(shù)據(jù)交流能降低訓練時間。事實上即便是 e>R,在某些網(wǎng)絡上仍然會帶來訓練效果的提升,如下圖:
圖4 不同的e和R值在兩個不同網(wǎng)絡中帶來的訓練時間提升
在 LM1B 數(shù)據(jù)集中,當 e>R 是總訓練時間都是擴大的,而在 ImageNet 數(shù)據(jù)集中,只要R 大于1.5, e 越大,訓練時間就越小,作者并沒有對這個結論給出解釋,筆者認為這是以為因為在ImageNet 數(shù)據(jù)集中,重復數(shù)據(jù)帶來的性能衰減 小于 重復訓練帶來的性能提升,因此,e 越大,達到相同性能所需的訓練時間越少,只是 LMDB 對重復數(shù)據(jù)的敏感度更高。
(3)batch_size越大,能支持的e數(shù)量也就越大。進一步的,batch_size越大,所需要的訓練數(shù)據(jù)也就越少。
(4)數(shù)據(jù)打亂操作可以提高最終訓練效果,這是一個顯而易見的結論。
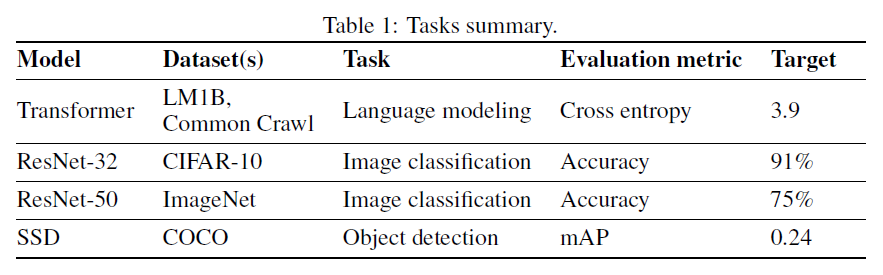
(5)在數(shù)據(jù)交流的訓練方法下,模型仍然能訓練到和傳統(tǒng)訓練方法一樣的精度,也就是不損失精度。作者在 4 個任務上進行了對比試驗:
總結
本文的核心思想就是數(shù)據(jù)的重復利用,通過數(shù)據(jù)的重復利用在并行執(zhí)行訓練流程的過程中執(zhí)行更多次的參數(shù)優(yōu)化操作,一方面提高了流水線效率,另一方面提高了訓練次數(shù),從而降低了達到相同精度所需的訓練時間。(作者 | Google Brain譯者 | 凱隱責編 | 夕顏)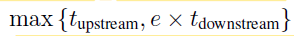 ? ? ?
? ? ?
-
谷歌
+關注
關注
27文章
6192瀏覽量
105814 -
神經(jīng)網(wǎng)絡
+關注
關注
42文章
4779瀏覽量
101047
原文標題:谷歌新研究:基于數(shù)據(jù)共享的神經(jīng)網(wǎng)絡快速訓練方法
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
從AlexNet到MobileNet,帶你入門深度神經(jīng)網(wǎng)絡
CV之YOLO:深度學習之計算機視覺神經(jīng)網(wǎng)絡tiny-yolo-5clessses訓練自己的數(shù)據(jù)集全程記錄
CV之YOLOv3:深度學習之計算機視覺神經(jīng)網(wǎng)絡Yolov3-5clessses訓練自己的數(shù)據(jù)集全程記錄
卷積神經(jīng)網(wǎng)絡模型發(fā)展及應用
BP神經(jīng)網(wǎng)絡MapReduce訓練
叫板谷歌,亞馬遜微軟推出深度學習庫 訓練神經(jīng)網(wǎng)絡更加簡單
基于粒子群優(yōu)化的條件概率神經(jīng)網(wǎng)絡的訓練方法
基于虛擬化的多GPU深度神經(jīng)網(wǎng)絡訓練框架





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論