

本來想把題目取為“從煉丹到化學”,但是這樣的題目太言過其實,遠不是近期可以做到的,學術研究需要嚴謹。但是,尋找適當的數學工具去建模深度神經網絡表達能力和訓練能力,將基于經驗主義的調參式深度學習,逐漸過渡為基于一些評測指標定量指導的深度學習, 是新一代人工智能需要面對的課題,也是在當前深度學習渾渾噩噩的大背景中的一些新的希望。
這篇短文旨在介紹團隊近期的ICML工作——”Towards a Deep and Unified Understanding of Deep Neural Models in NLP”(這篇先介紹NLP領域,以后有時間再介紹類似思想解釋CV網絡的論文)。這是我與微軟亞洲研究院合作的一篇論文。其中,微軟研究院的王希廷研究員在NLP方向有豐富經驗,王老師和關超宇同學在這個課題上做出了非常巨大的貢獻,這里再三感謝。
大家說神經網絡是“黑箱”,其含義至少有以下兩個方面:一、神經網絡特征或決策邏輯在語義層面難以理解;二、缺少數學工具去診斷與評測網絡的特征表達能力(比如,去解釋深度模型所建模的知識量、其泛化能力和收斂速度),進而解釋目前不同神經網絡模型的信息處理特點。
過去我的研究一直關注第一個方面,而這篇ICML論文同時關注以上兩個方面——針對不同自然語言應用的神經網絡,尋找恰當的數學工具去建模其中層特征所建模的信息量,并可視化其中層特征的信息分布,進而解釋不同模型的性能差異。
其實,我一直希望去建模神經網絡的特征表達能力,但是又一直遲遲不愿意下手去做。究其原因,無非是找不到一套優美的數學建模方法。深度學習研究及其應用很多已經被人詬病為“經驗主義”與“拍腦袋”,我不能讓其解釋性算法也淪為經驗主義式的拍腦袋——不然解釋性工作還有什么意義。
研究的難點在于對神經網絡表達能力的評測指標需要具備“普適性”和“一貫性”。首先,這里“普適性”是指解釋性指標需要定義在某種通用的數學概念之上,保證與既有數學體系有盡可能多的連接,而與此同時,解釋性指標需要建立在盡可能少的條件假設之上,指標的計算算法盡可能獨立于神經網絡結構和目標任務的選擇。
其次,這里的“一貫性”指評測指標需要客觀的反應特征表達能力,并實現廣泛的比較,比如
診斷與比較同一神經網絡中不同層之間語義信息的繼承與遺忘;
診斷與比較針對同一任務的不同神經網絡的任意層之間的語義信息分
比較針對不同任務的不同神經網絡的信息處理特點。
具體來說,在某個NLP應用中,當輸入某句話x=[x1,x2,…,xn]到目標神經網絡時,我們可以把神經網絡的信息處理過程,看成對輸入單詞信息的逐層遺忘的過程。即,網絡特征每經過一層傳遞,就會損失一些信息,而神經網絡的作用就是盡可能多的遺忘與目標任務無關的信息,而保留與目標任務相關的信息。于是,相對于目標任務的信噪比會逐層上升,保證了目標任務的分類性能。
我們提出一套算法,測量每一中層特征f中所包含的輸入句子的信息量,即H(X|F=f)。當假設各單詞信息相互獨立時,我們可以把句子層面的信息量分解為各個單詞的信息量H(X|F=f) = H(X1=x1|F=f) + H(X2=x2|F=f) + … + H(Xn=xn|F=f). 這評測指標在形式上是不是與信息瓶頸理論相關?但其實兩者還是有明顯的區別的。信息瓶頸理論關注全部樣本上的輸入特征與中層特征的互信息,而我們僅針對某一特定輸入,細粒度地研究每個單詞的信息遺忘程度。
其實,我們可以從兩個不同的角度,計算出兩組不同的熵H(X|F=f)。(1)如果我們只關注真實自然語言的低維流形,那么p(X=x|F=f)的計算比較容易,可以將p建模為一個decoder,即用中層特征f去重建輸入句子x。(2)在這篇文章中,我們其實選取了第二個角度:我們不關注真實語言的分布,而考慮整個特征空間的分布,即x可以取值為噪聲。在計算p(X=x,F=f) = p(X=x) p(F=f|X=x)時,我們需要考慮“哪些噪聲輸入也可以生成同樣的特征f”。舉個toy example,當輸入句子是"How are you?"時,明顯“are”是廢話,可以從“How XXX you?”中猜得。這時,如果僅從真實句子分布出發,考慮句子重建,那些話佐料(“are” “is” “an”)將被很好的重建。而真實研究選取了第二個角度,即我們關注的是哪些單詞被神經網絡遺忘了,發現原來“How XYZ you?”也可以生成與“How are you?”一樣的特征。
這時,H(X|F=f)所體現的是,在中層特征f的計算過程中,哪些單詞的信息在層間傳遞的過程中逐漸被神經網絡所忽略——將這些單詞的信息替換為噪聲,也不會影響其中層特征。這種情況下,信息量H(X|F=f)不是直接就可以求出來的,如何計算信息量也是這個課題的難點。具體求解的公式推導可以看論文,知乎上只放文字,不談公式。
首先,從“普適性”的角度來看,中層特征中輸入句子的信息量(輸入句子的信息的遺忘程度)是信息論中基本定義,它只關注中層特征背后的“知識量”,而不受網絡模型參數大小、中層特征值的大小、中層卷積核順序影響。其次,從“一貫性”的角度來看,“信息量”可以客觀反映層間信息快遞能力,實現穩定的跨層比較。如下圖所示,基于梯度的評測標準,無法為不同中間層給出一貫的穩定的評測。

下圖比較了不同可視化方法在分析“reverse sequence”神經網絡中層特征關注點的區別。我們基于輸入單詞信息量的方法,可以更加平滑自然的顯示神經網絡內部信息處理邏輯。

下圖分析比較了不同可視化方法在診斷“情感語義分類”應用的神經網絡中層特征關注點的區別。我們基于輸入單詞信息量的方法,可以更加平滑自然的顯示神經網絡內部信息處理邏輯。

基于神經網絡中層信息量指標,分析不同神經網絡模型的處理能力。我們分析比較了四種在NLP中常用的深度學習模型,即BERT, Transformer, LSTM, 和CNN。在各NLP任務中, BERT模型往往表現最好,Transformer模型次之。
如下圖所示,我們發現相比于LSTM和CNN,基于預訓練參數的BERT模型和Transformer模型往往可以更加精確地找到與任務相關的目標單詞,而CNN和LSTM往往使用大范圍的鄰接單詞去做預測。

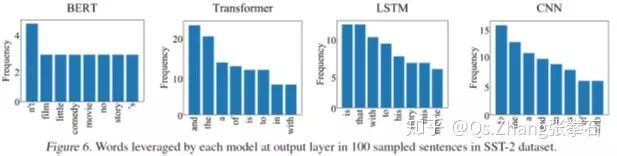
進一步,如下圖所示,BERT模型在預測過程中往往使用具有實際意義的單詞作為分類依據,而其他模型把更多的注意力放在了and the is 等缺少實際意義的單詞上。
如下圖所示,BERT模型在L3-L4層就已經遺忘了EOS單詞,往往在第5到12層逐漸遺忘其他與情感語義分析無關的單詞。相比于其他模型,BERT模型在單詞選擇上更有針對性。
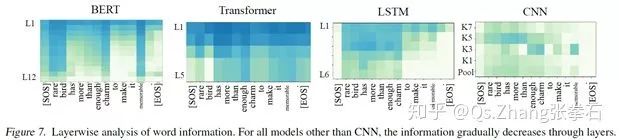
我們的方法可以進一步細粒度地分析,各個單詞的信息遺忘。BERT模型對各種細粒度信息保留的效果最好。

十多年前剛剛接觸AI時總感覺最難的是獨立找課題,后來發現追著熱點還是很容易拍腦袋想出一堆新題目,再后來發現真正想做的課題越來越少,雖然AI領域中學者們的投稿量一直指數增長。
回國以后,身份從博后變成了老師,帶的學生增加了不少,工作量也翻倍了,所以一直沒有時間寫文章與大家分享一些新的工作,如果有時間還會與大家分享更多的研究,包括這篇文章后續的眾多算法。信息量在CV方向應用的論文,以及基于這些技術衍生出的課題,我稍后有空再寫。
-
神經網絡
+關注
關注
42文章
4789瀏覽量
101827 -
AI
+關注
關注
87文章
32992瀏覽量
272738
原文標題:上海交大張拳石:神經網絡的可解釋性,從經驗主義到數學建模
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何優化BP神經網絡的學習率
小白學解釋性AI:從機器學習到大模型

數據智能系列講座第3期—交流式學習:神經網絡的精細與或邏輯與人類認知的對齊






 工商網監
工商網監

評論