 機器學習中Kernel的秘密
機器學習中Kernel的秘密
本文探討的不是關于深度學習方面的,但可能也會涉及一點兒,主要是因為 Kernel(內核)的強大。Kernel 一般來說適用于任何機器學習算法,你可能會問為什么,我將在文中回答這個問題。
一般來說,在機器學習領域中,我們要把相似的東西放在相似的地方。這個規則對所有的機器學習算法都是通用的,不論它是有監督、無監督、分類還是回歸。問題在于我們應該如何準確地確定什么是相似的?為了揭示這個問題,我們將從 Kernel 的基礎開始學習。
兩個向量之間的點積是一個神奇的東西,可以肯定地說,它在一定程度上度量了相似性。通常在機器學習的文章中,點積表示成以下形式:
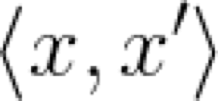
這表示了向量x和x'之間的點積。注意,為了簡便起見,此處省略了向量符號的箭頭。這個符號是向量分量乘積之和的簡寫:
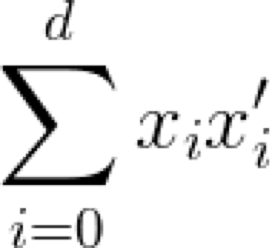
巧合的是,向量的范數是點積的平方根,可以這樣表示:
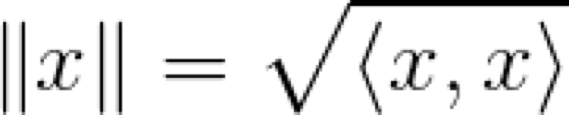
這當然不是全部的。我們肯定知道余弦定理,即點積等于向量之間角度的余弦與它們范數的乘積(這很容易用簡單的三角函數來證明):
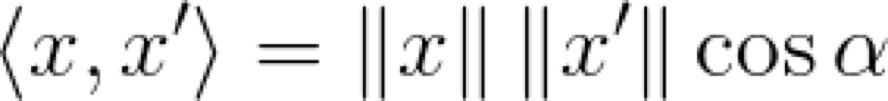
談論角度和范數的好處在于,我們可以想象出這個點積是什么樣子。讓我們畫一下這兩個向量,它們之間的夾角為 α:
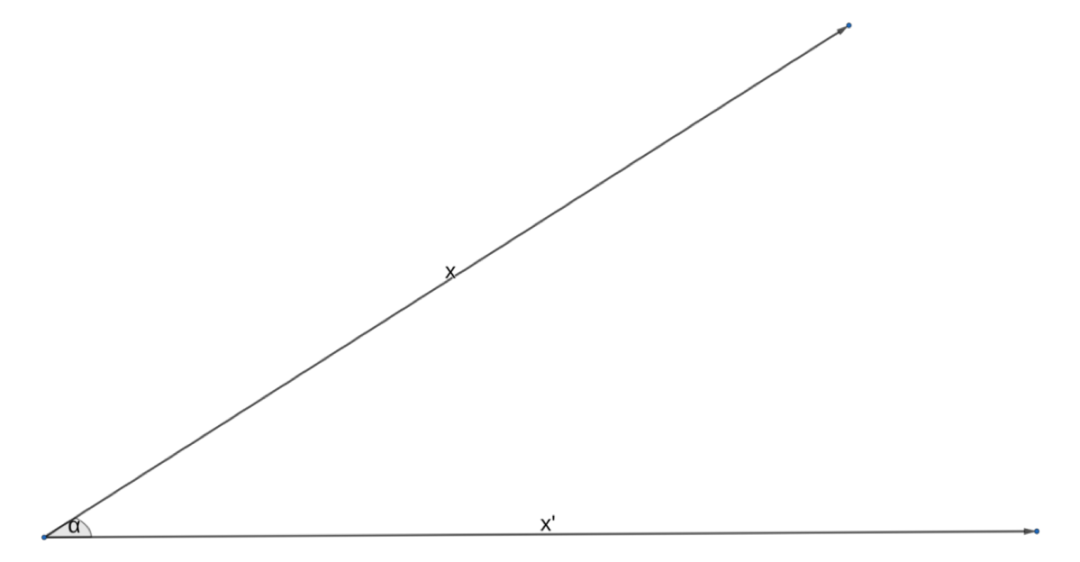
因此,如果我們采用點積作為相似性的度量,那么,它在什么時候會達到最大呢?這意味著是這些向量最相似的時候。顯而易見,當余弦等于 1 的時候,就會發生這種情況,也就是當角度為 0 度或者弧度的時候。如果向量的范數都是相同的,那么顯然我們討論的是同一個向量!很好,讓我們把目前為止學到的東西寫下來:
點積是向量間相似性的度量
現在你應該希望了解一下談論點積的意義。
當然,點積作為相似性的度量,在實際問題中可能會有用,或者一點兒用也沒有,這取決于你要解決的問題。因此,我們需要對輸入空間進行某種轉換,使點積作為相似性的度量起到實際的作用,用 ? 來表示轉換。現在,我們可以定義 Kernel 的含義了,映射空間中的點積:
Kernel 的定義非常直接,是對映射空間相似性的度量。實際上,數學家喜歡具體化。由于Kernel 所處理的底層函數和空間不應該存在隱含的假設,因此,通過函數分析 Kernel 背后存在著很多的理論,需要在其它的文章中來探索這方面的問題。簡而言之,我們需要明確地說明想以什么樣的函數來表示 ?:
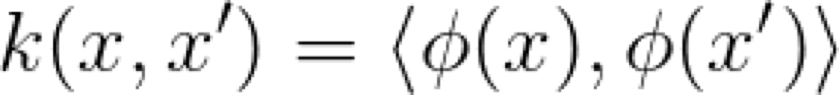
我們需要一個從 X 域映射到點積被定義好的空間的函數,這意味著它是一個很好的相似性度量。
Kernel 可以用作任何在點積過程(或相關范數)中定義的算法的泛化。最有名的是使用 Kernel 作為基礎算法例子是支持向量機(Support Vector Machines)和高斯過程(Gaussian Processes),但也有一些是 Kernel 與神經網絡一起使用的例子。
我們實際上需要 Kernel 和映射函數 ? 的另一個原因是輸入空間可能沒有定義明確的點積。快速地研究一個文檔分析的例子,我們只想根據兩個文檔的主題來得出它們之間的相似性,然后可能會對它們進行分類。那么,這兩個文檔之間的點積究竟是什么呢?一種選擇是獲取文檔字符的 ASCII 碼,并將它們連接到一個大的向量中 —— 當然,這不是你在實踐中要做的工作,而是僅供思考。
我們現在已經將文檔定義為向量了,然而問題還是在于文件的長度,即不同文件的長度不同。這沒什么大不了的,我們可以通過在較短的文檔中填充一定長度的 EOS 字符來應對這個問題。然后我們就可以計算這個高維空間中的點積了。但還有一個問題是,這個點積的相關性,或者更確切地說,這個點積實際上意味著什么。顯然,字符的細微變化會改變點積。即使我們用同義詞來替換,它一樣會改變點積。這是在比較兩個文檔的主題時要避免的問題。
那么,Kernel 是如何在此發揮作用的?理想的情況下,你需要找到一個映射函數 ? 將輸入空間映射到一個特征空間,其中點積具有你想要的意義。在剛才文檔比較的例子中,對于語義相似的文檔,點積值是很高的。換句話說,這種映射應該使分類器的工作更容易,因為數據變得更容易分離。
我們現在可以看一下典型的 XOR 示例來進一步理解概念。XOR 是一個二進制函數,如下所示:
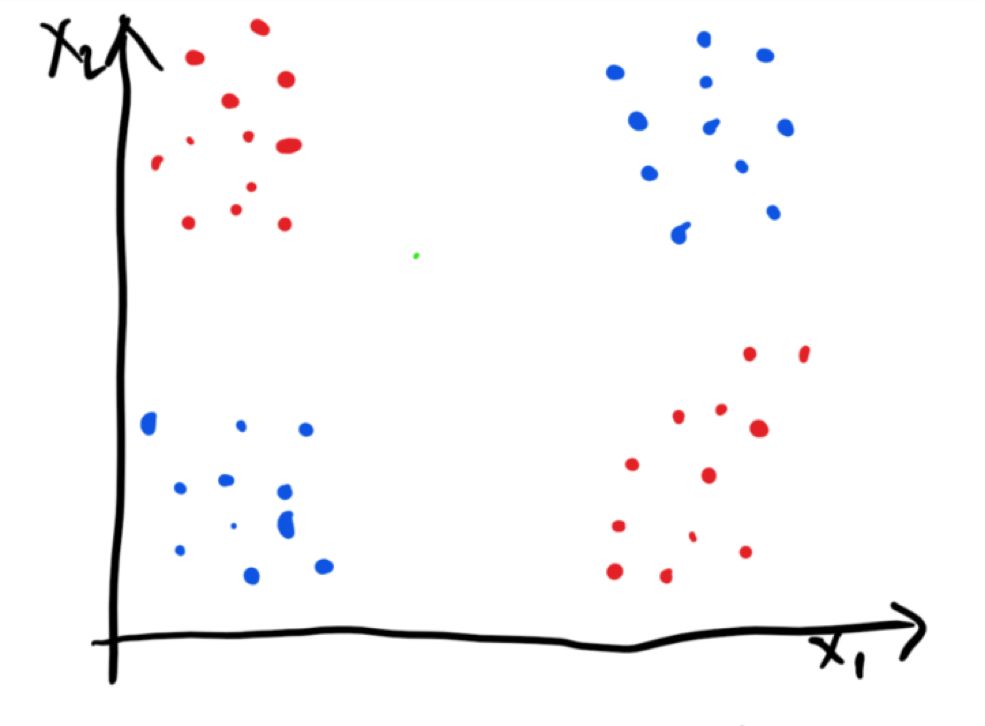
藍色的點以 0 來分類,紅色的點以 1 來分類。我們可以假設這是一個有噪音的 XOR 函數,因為集群的分布范圍很廣。我們馬上注意到了一個問題,數據是不可線性分離的。也就是說,我們不能在紅點和藍點之間劃一條線來分離它們。
在這種情況下能做些什么呢?我們可以應用一個特定的映射函數,以使工作變得更容易。具體來說,要創建一個映射函數,它將對通過紅點集群的線附近的輸入空間進行單側反射。我們將表示出這條線下面附近的所有點。那么,映射函數將會得到以下結果:
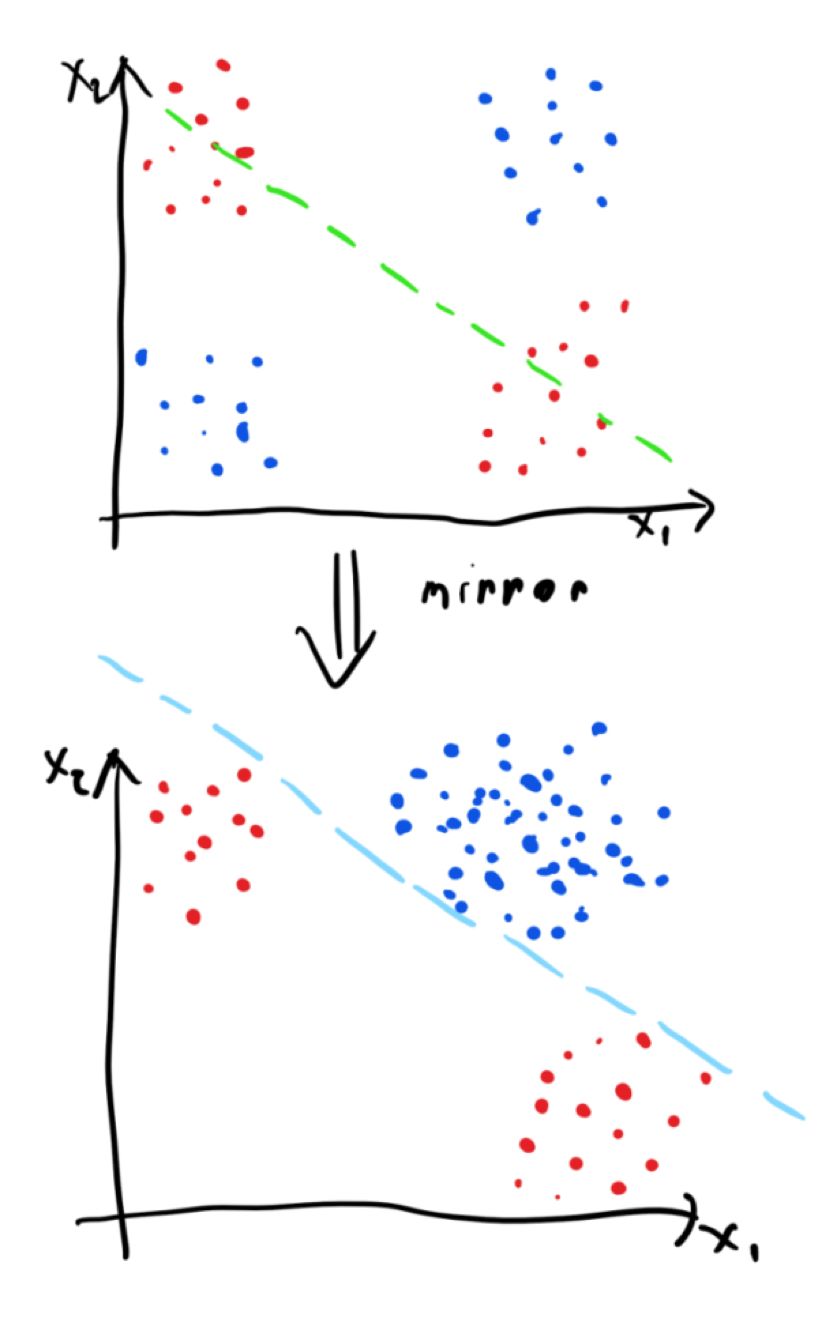
在映射之后,數據會變得很容易進行線性分離,因此如果我們有一個模型試圖擬合一個分離的超平面(例如感知器),這就是一個理想的情況。顯然,線性可分離很好,但是為了構建有效的模型,我們不一定需要線性可分離的,這就意味著并非所有的映射函數都需要得到線性可分離的數據才能構建有效的模型。
人們時常地混淆使用 Kernel 和使用映射函數的概念。Kernel 函數的輸出是一個標量,是對兩個點的相似性或相異性的度量,而映射函數的輸出則是一個提供相似性計算的向量。Kernel 的有趣之處在于,有時我們可以計算原始空間中映射的點積,而無需顯式地進行輸入映射。這就允許我們處理無限維度空間的映射!這是一個很難理解的事情,所以我將在后面的文章中進行討論。
最后,我想推薦一下 Smola 和 Schoelkopf 的書:《Learning with Kernels》。本書對 Kernel 核心及其理論背景進行了全面的闡述。
機器學習中Kernel的秘密(二)
在《機器學習中Kernel的秘密(一)》一文中,我用最簡單的方法解釋了 Kernel。在讀本文之前,我建議你先快速地閱讀一下這篇文章,了解一下 Kernel 是什么。希望你能得出這樣的結論:Kernel是映射空間中兩個向量之間的相似性的度量。
現在,我們可以討論一些比較有名的 Kernel,以及如何結合這些 Kernel 來構建其它的 Kernel。記住,對于我們將要使用的示例,x’ 是用于繪圖的一維向量,我們將 x’ 的值設置為 2。不再多說,讓我們開始吧。
線性 Kernel
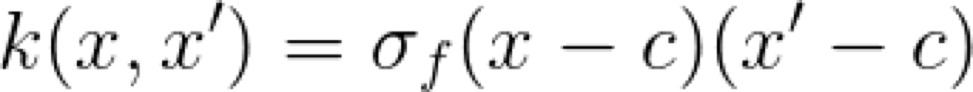
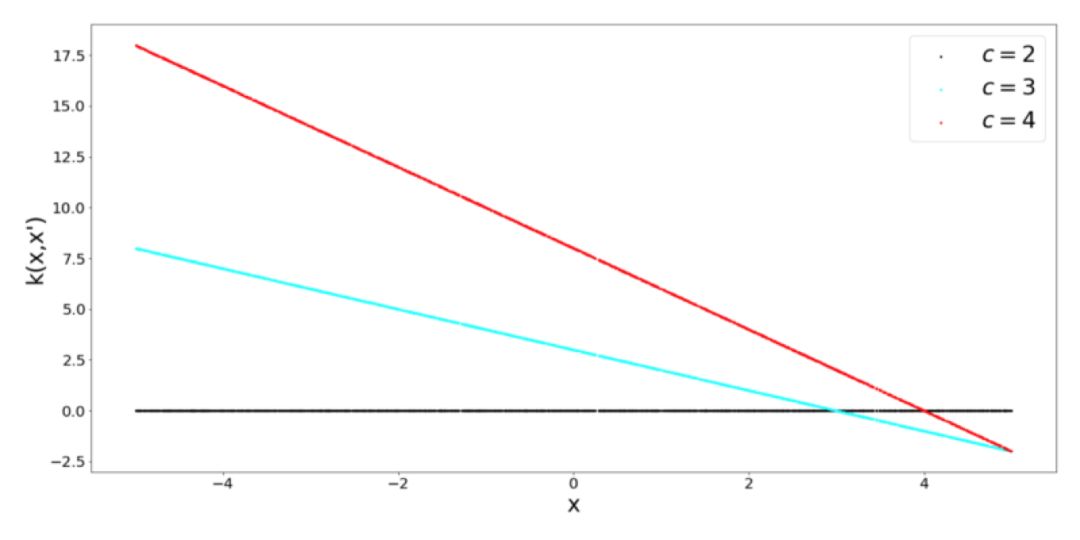
這個 Kernel 的超參數是 sigma 和偏差參數 c。直觀地說,這個 Kernel 是什么呢?如果我們取一個特定的 x,并將它與所有其它的 x’ 相比較,就會得到一條直線。這就是它被稱為線性 Kernel 的原因。不變的 x 值和變化的 x' 值有效地說明了我們沿著這條直線移動。
這個 Kernel 的另一個特點是,它具有非穩定性,這意味著它的值相對于 x’ 的絕對位置而不是相對位置發生了變化。另一個優點是,由于它是線性的,所以在優化過程中可以進行高效計算。
多項式 Kernel
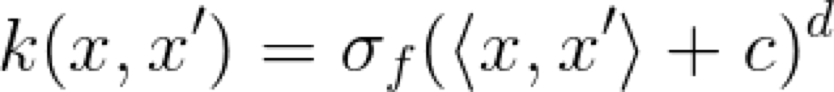
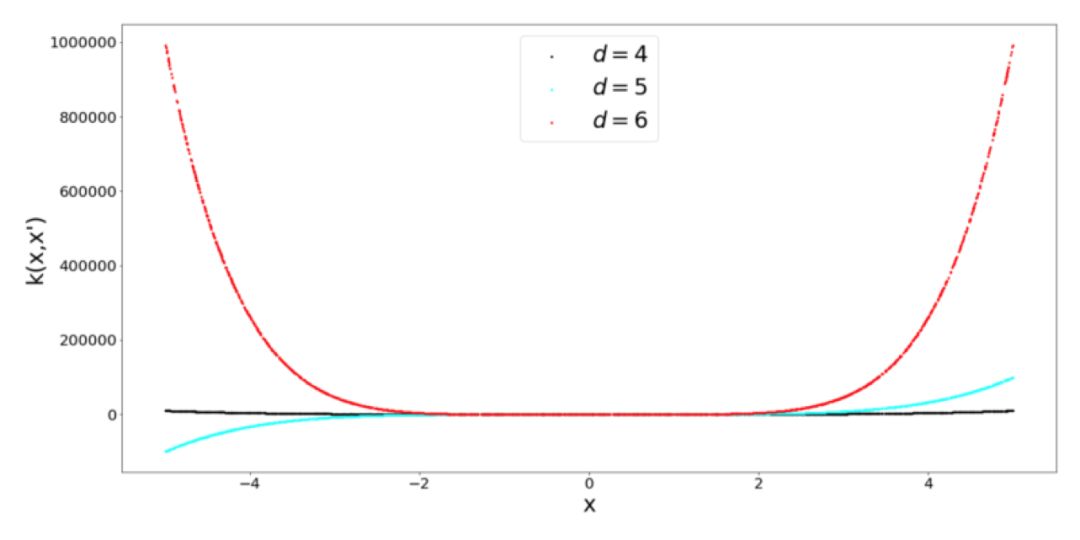
顧名思義,這個 Kernel 是一個帶有偏差量 c 的多項式函數。我認為值得花點時間來考慮會產生Kernel 的映射函數 ?,因為 Kernel 是在映射空間中的一個相似性函數(點積),所以它會返回一個標量。在二維空間中二階多項式 Kernel 的映射函數表示如下:
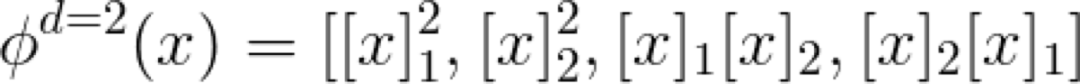
當增大輸入維度 d 的值和多項式的階數時,映射的特征空間就會變得相當大。那么,我們可以計算點積而不是進行轉換,如上面的公式中所列的那樣。這是 Kernel 理論中許多很不錯的公式之一。
徑向基函數 Kernel
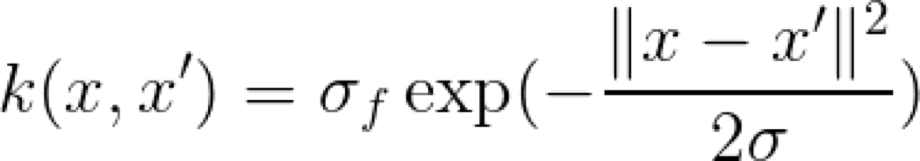
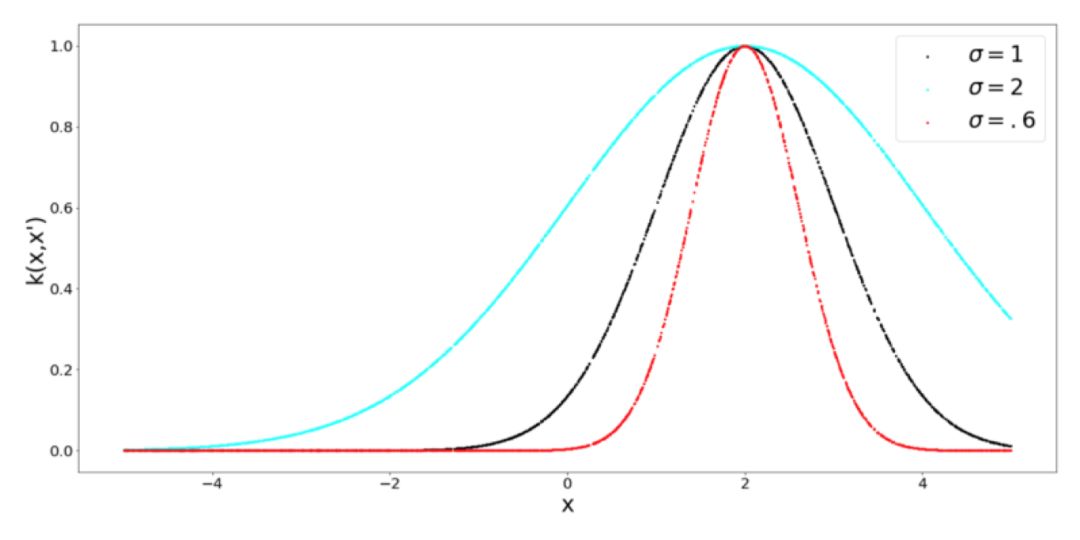
這是一個非常有名的,并經常使用的 Kernel。注意,由于指數中負指數的存在,所以指數的取值要在 0 到 1 范圍之間,這是一個不錯的特性,因為我們可以說 1 表示非常相似,或者相同,而接近 0 的值則表示完全不同。指數中的參數 σ 控制著 Kernel 的靈敏度。對于較低的 σ 值,我們只期望那些非常接近的點是相似的。對于較大的 σ 值,我們放寬了相似性標準,因為越遠的點就越相似。
當然,Kernel 看起來是這樣,因為我們把 x 設置為 0,并改變了 x’,邏輯上我們想要計算點之間整個 X 域的相似性。這就得出了一個平面,正是這個平面,才是描述一個 Kernel 的例子:
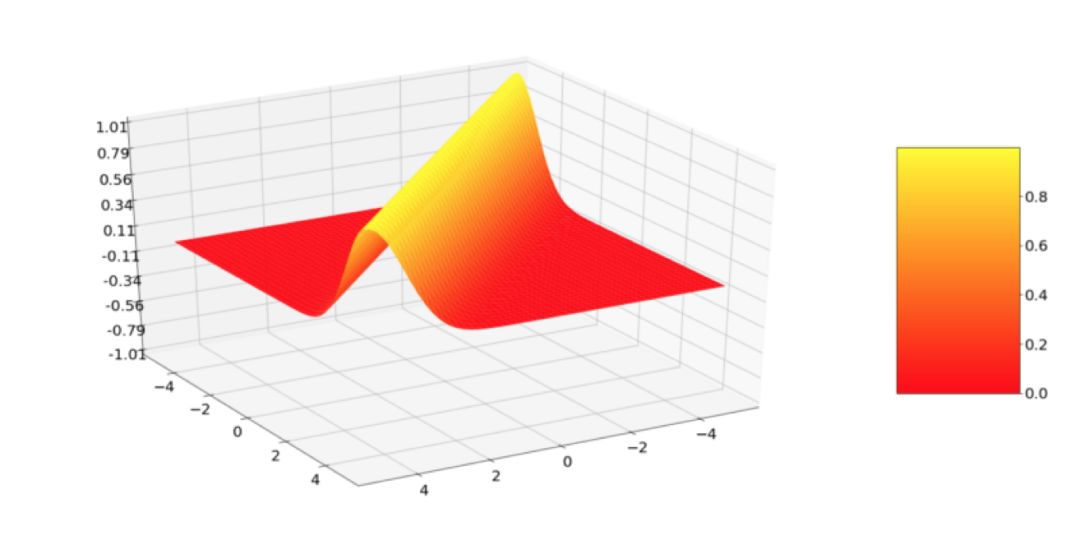
如圖所示,Kernel 的值在對角線處最高,其中 x 和 x' 是相同的。
周期 Kernel
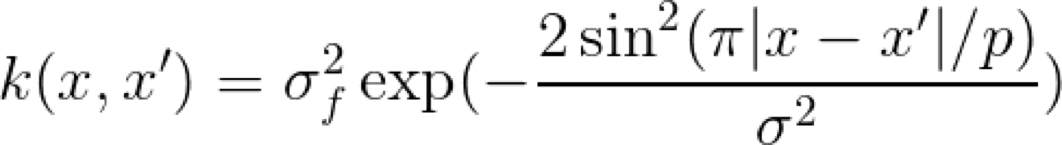
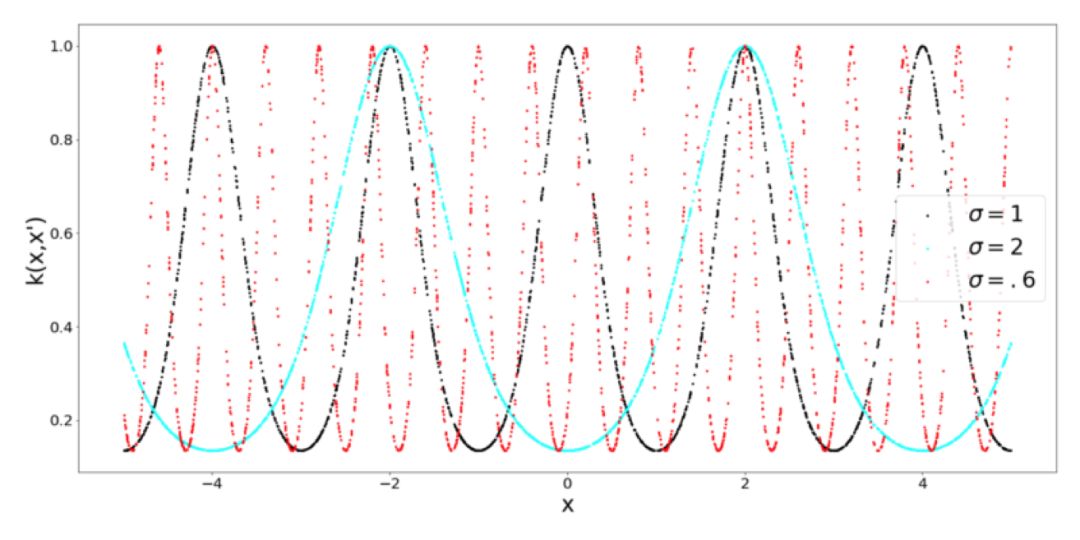
當你考慮周期性的時候,就會馬上想到周期函數,比如正弦函數和余弦函數。從邏輯上講,周期 Kernel 中有正弦函數。Kernel 的超參數 σ 還是表示了相似性的靈敏度,但是我們還有表示正弦函數周期的參數 p。另外,還要注意徑向基 Kernel 和周期 Kernel 之間的相似性,它們都被限定為輸出 0 到 1 范圍之間的值。
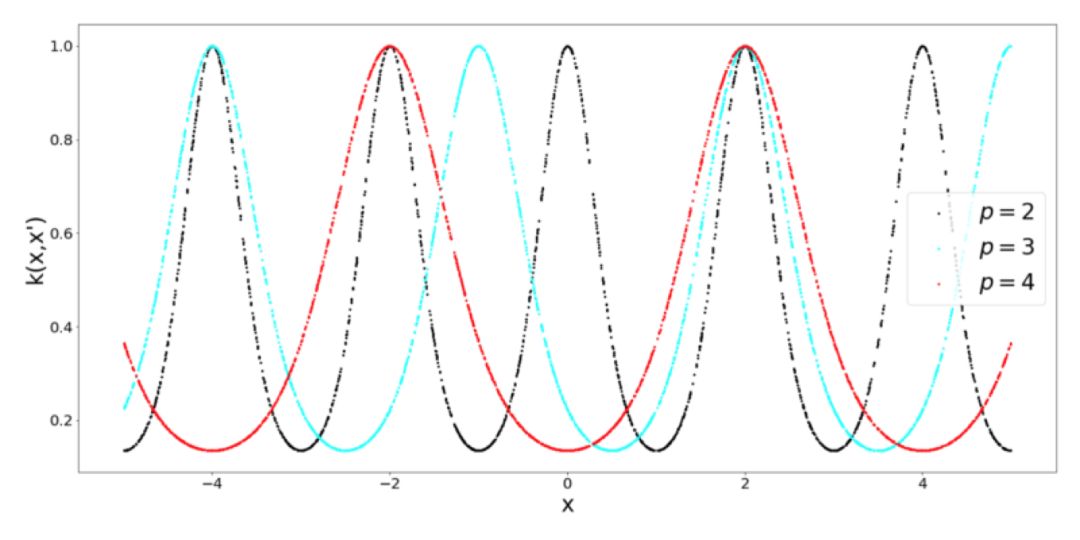
什么時候使用周期 Kernel?這是非常合乎邏輯的,假設你想要為一個類正弦函數建模,從這個函數中取 2 個點,它們相對于歐式距離比較遠,這并不意味著函數的值有什么不同。為了解決這類問題,就需要周期 Kernel。為了完整性起見,看看當我們調整周期 Kernel 的周期性時會發生什么(什么也沒有):
局部周期 Kernel
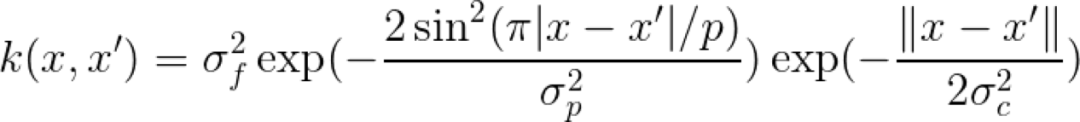
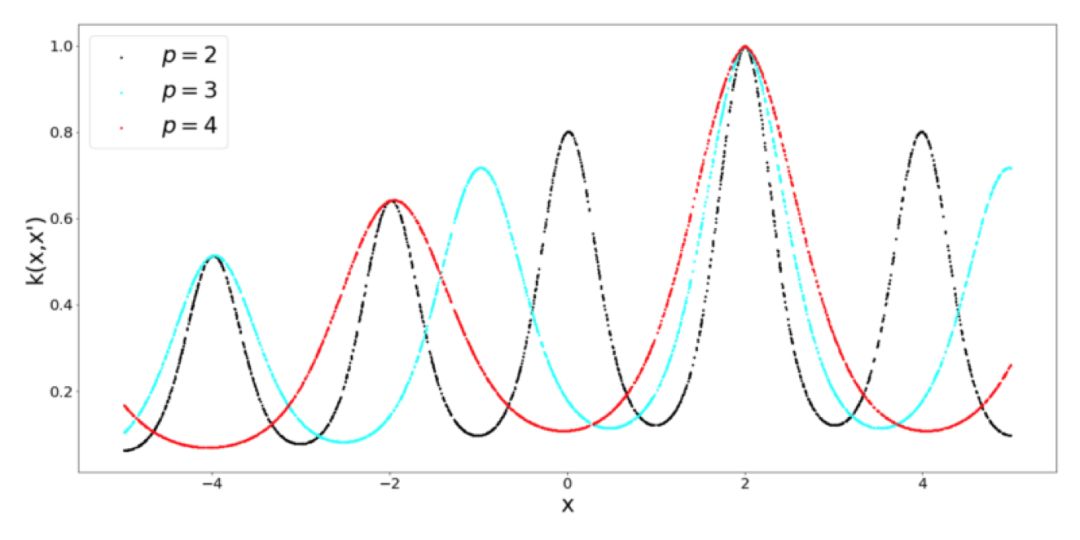
我們基本上是通過徑向基 Kernel 與周期 Kernel 的乘積得到了局部周期 Kernel。我們用這個方法得到的結果是,得到的 Kernel 的值隨 x 和 x' 之間距離的變化而變化,而不僅僅是隨距離的周期性變化而變化,這就導致了所謂的局部周期性。
只是因為我很好奇,用 3D 模式來繪制了這個 Kernel,并得到以下這個還不錯的形狀:
構建新 Kernel
到現在為止,我們接觸到了一些 Kernel 的例子。問題來了,我們拿什么來構建新的 Kernel 呢?Kernel 有以下兩個很好的特性:
1. 添加一個帶有 Kernel 的 Kernel 會產生一個新的 Kernel;
2. 多個 Kernel 的乘積會產生一個新的 Kernel;
以上兩個特性基本上可以讓你在不做太多數學運算的情況下構建新的 Kernel,也是非常直觀的。乘積可以看作是一個與運算,特別是在考慮 0 和 1 范圍之間的 Kernel 時。于是,我們可以將周期 Kernel 與徑向基函數 Kernel 相結合,得到一個局部周期 Kernel。
這幾個例子,可以讓你開始 Kernel 之旅。當然,也還有一些沒有被提及的 Kernel。針對實際問題進行的 Kernel 設計是一項非常重要的任務,要想學好它,需要一定的經驗。此外,在機器學習中有一個專門用于學習 Kernel 函數的領域。
由于算法上的要求,Kernel 設計也比較復雜。由于許多基于 Kernel 的算法都涉及到一種反向的被稱為“Gram”的矩陣,因此我們要求 Kernel 是正定的,但這是我將來要探討的內容。
現在我們已經了解了一些有用的 Kernel,可以更深入地研究 Hilbert 空間的理論以及它們與Kernel 的關系,但是這必須要等到下一篇文章了。
-
機器學習
+關注
關注
66文章
8438瀏覽量
132912 -
Kernel
+關注
關注
0文章
48瀏覽量
11215
原文標題:解密Kernel:為什么適用任何機器學習算法?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
傳統機器學習方法和應用指導

zeta在機器學習中的應用 zeta的優缺點分析
cmp在機器學習中的作用 如何使用cmp進行數據對比
什么是機器學習?通過機器學習方法能解決哪些問題?

eda在機器學習中的應用
【「時間序列與機器學習」閱讀體驗】+ 簡單建議
機器學習中的數據分割方法
機器學習中的數據預處理與特征工程
深度學習在工業機器視覺檢測中的應用
機器學習在數據分析中的應用
深度學習與傳統機器學習的對比
亞馬遜秘密研發AI聊天機器人Metis,挑戰ChatGPT
機器學習8大調參技巧
OpenVINO?協同Semantic Kernel:優化大模型應用性能新路徑





 工商網監
工商網監
評論