") Jurgen:我比GAN之父提前三年想到生成式對抗網(wǎng)絡(luò)
Jurgen:我比GAN之父提前三年想到生成式對抗網(wǎng)絡(luò)
2014年的一晚,Ian Goodfellow和一個剛剛畢業(yè)的博士生一起喝酒慶祝。在蒙特利爾一個酒吧,一些朋友希望他能幫忙看看手頭上一個棘手的項目:計算機如何自己生成圖片。
研究人員已經(jīng)使用了神經(jīng)網(wǎng)絡(luò)(模擬人腦的神經(jīng)元網(wǎng)絡(luò)的一種算法),作為生成模型來創(chuàng)造合理的新數(shù)據(jù)。但結(jié)果往往不盡人意。計算機生成的人臉圖像通常不是模糊不清,就是缺耳少鼻。
Ian Goodfellow朋友們提出的方案是對那些組成圖片的元素進行復(fù)雜的統(tǒng)計分析以幫助機器自己生成圖片。這需要進行大量的數(shù)據(jù)運算,Ian Goodfellow告訴他們這根本行不通。
邊喝啤酒邊思考問題時,他突然有了一個想法。如果讓兩個神經(jīng)網(wǎng)絡(luò)相互對抗會出現(xiàn)什么結(jié)果呢?他的朋友對此持懷疑態(tài)度。
當(dāng)他回到家,女朋友已經(jīng)熟睡,他決定馬上實驗自己的想法。那天他一直寫代碼寫到凌晨,然后進行測試。第一次運行就成功了!
那天晚上他提出的方法現(xiàn)在叫做GAN,即生成對抗網(wǎng)絡(luò)(generative adversarial network)。
通過使用兩個神經(jīng)網(wǎng)絡(luò)的相互對抗,Ian Goodfellow創(chuàng)造了一個強大的AI工具——生成對抗網(wǎng)絡(luò)GAN(generative adversarial network)。現(xiàn)在,該方法已經(jīng)在機器學(xué)習(xí)領(lǐng)域產(chǎn)生了巨大的影響,也讓他的創(chuàng)造者Goodfellow成為了人工智能界的重要人物。
GAN的誕生故事早已為技術(shù)圈所熟知,但是,產(chǎn)生這樣奇妙對抗想法的似乎不止Ian Goodfellow一人。
比如另一位機器學(xué)習(xí)領(lǐng)袖Jurgen Schmidhuber就聲稱早些時候已經(jīng)做過類似的工作。
NIPS 2016上有的相關(guān)爭論:
https://media.nips.cc/nipsbooks/nipspapers/paper_files/nips27/reviews/1384.html
今天,一篇2010年的博文亦在reddit上引發(fā)熱議。這是一篇非常簡短的文章,但是很精確的提出了GAN的基本想法,其中附帶的一張圖片更是直接表示出了GAN的部署方式。
https://web.archive.org/web/20120312111546/http://yehar.com:80 /blog /?p = 167

這篇帖子引發(fā)了大量討論,不少人覺得遺憾,稱,如果小哥能更重視一下自己的這個想法,“他可能才會成為那個改變世界的人。”
當(dāng)然,也有人表示,有這樣的想法很重要,但真的付諸實踐才行,并且,2010年的硬件條件或許也還無法支撐讓GAN大火的一些應(yīng)用。甚至拿出來哥倫布發(fā)現(xiàn)新大陸的例子表示,“哥倫布可能是第一個發(fā)現(xiàn)者,但一定有很多人早就預(yù)言過'也許在大西洋有一些島嶼'?”
事實上,這篇博客的作者Olli Niemitalo的心態(tài)其實比吃瓜群眾要好很多,Olli是位來自芬蘭的電器工程師,在2017年的一篇帖子了,他敘述了自己在剛剛發(fā)現(xiàn)GAN的心路歷程:“2017年5月,我在YouTube看到了Ian Goodfellow的相關(guān)教程,made my day! 我之前寫下的只是一個基本的想法,并且已經(jīng)做了很多工作來使它取得良好的效果。這個演講回答了我曾經(jīng)遇到過的問題以及更多問題。”
從這篇博客作者的個人主頁可以看出,Olli本身也是位思維活躍并且樂于提出新想法的“寶藏男孩”,從2007年開始,他在博客中記下了從“能唱歌的自行車剎車“到”永不遲到的手表“等超多自己的想法,當(dāng)然其中也包括了這個“GAN”的雛形。
正如Goodfellow所說,“如果你有一個覺得可行的想法,也具有領(lǐng)域知識能夠認(rèn)識到它切實有效,那么你的想法才會真的價值。我提出GAN只花了大約1個小時,寫論文花了2個星期。這絕對是一個“99%靈感,1%汗水”的故事,但是在那之前我花了4年時間在相關(guān)主題上攻讀博士學(xué)位。”
最后,歡迎看看這個比Goodfellow早三年提出的GAN的簡短想法。
Amethod for training artificial neural networksto generate missing data within a variable context. As the idea is hard to put in a single sentence, I will use an example:
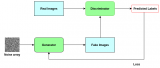
An image may have missing pixels (let's say, under a smudge). How can one restore the missing pixels, knowing only the surrounding pixels? One approach would be a "generator" neural network that, given the surrounding pixels as input, generates the missing pixels.
But how to train such a network? One can't expect the network to exactly produce the missing pixels. Imagine, for example, that the missing data is a patch of grass. One could teach the network with a bunch of images of lawns, with portions removed. The teacher knows the data that is missing, and could score the network according to the root mean square difference (RMSD) between the generated patch of grass and the original data. The problem is that if the generator encounters an image that is not part of the training set, it would be impossible for the neural network to put all the leaves, especially in the middle of the patch, in exactly the right places. The lowest RMSD error would probably be achieved by the network filling the middle area of the patch with a solid color that is the average of the color of pixels in typical images of grass. If the network tried to generate grass that looks convincing to a human and as such fulfills its purpose, there would be an unfortunate penalty by the RMSD metric.
My idea is this (see figure below): Train simultaneously with the generator a classifier network that is given, in random or alternating sequence, generated and original data. The classifier then has to guess, in the context of the surrounding image context, whether the input is original (1) or generated (0). The generator network is simultaneously trying to get a high score (1) from the classifier. The outcome, hopefully, is that both networks start out really simple, and progress towards generating and recognizing more and more advanced features, approaching and possibly defeating human's ability to discern between the generated data and the original. If multiple training samples are considered for each score, then RMSD is the correct error metric to use, as this will encourage the classifier network to output probabilities.
如果你對GAN的誕生故事感興趣,也可以看大數(shù)據(jù)文摘的相關(guān)報道:
GAN之父Ian Goodfellow :那個賦予機器想象力的人類
-
GaN
+關(guān)注
關(guān)注
19文章
1964瀏覽量
74005 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8438瀏覽量
132957
原文標(biāo)題:“我比Goodfellow提前三年想到了GAN”
文章出處:【微信號:BigDataDigest,微信公眾號:大數(shù)據(jù)文摘】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
AI將推動未來三年存儲需求翻倍
嵌入式搞啥掙錢,干了三年好迷茫?

#新年新氣象,大家新年快樂!#AIGC入門及鴻蒙入門
AIGC入門及鴻蒙入門
廣汽三年“番禺行動”深度解讀
三行代碼完成生成式AI部署
生成對抗網(wǎng)絡(luò)(GANs)的原理與應(yīng)用案例
生成式AI與神經(jīng)網(wǎng)絡(luò)模型的區(qū)別和聯(lián)系
華為分布式存儲連續(xù)三年榮膺2024年Gartner“客戶之選”

京東集團連續(xù)第三年入選《財富》中國ESG影響力榜
洛微科技續(xù)三年榮獲「2024杭州準(zhǔn)獨角獸企業(yè)」殊榮!

生成式 AI 進入模型驅(qū)動時代

深度學(xué)習(xí)生成對抗網(wǎng)絡(luò)(GAN)全解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論