 數據挖掘的功能
數據挖掘的功能
數據挖掘的功能
1、數據分類
數據分類為數據挖掘中常見的功能之一,顧名思義即是將分析對象依不同的屬性分類加以定義,建立不同的類組。數據挖掘中的分類是指針對未發生的結果進行預測分類,主要包括歸納和推論兩步驟,其主要目的在于提高分類的準確度,建立分類規則,再評估準則的優劣。常用“判定樹”算法。
2、數據估計
根據不同相關屬性數據的連續性數值,找出各屬性間的關聯性,以了解并獲得某一特定屬性未知的連續性數值,常用“回歸分析”及“類神經網絡算法”。
3、數據預測
預測工作的目的在于以其他屬性的值為基礎來預測特定屬性的值。而這個被預測屬性的值通常稱為目標變量或是因變量;而其他屬性則稱為解釋變量或自變量,預測的主要方法在于建立數據當中因變量與自變量間的關系。常用“回歸分析”“時間序列分析”及“類神經網絡”算法。
4、數據關聯分組
數據關聯分組主要用來發現數據中特征屬性間具有高度關聯性的一種模式,其所發現的模式通常是用規則來表現。常用“關聯規則(又稱購物藍分析)”算法。
5、數據聚類
數據聚類主要是利用數據中類似或相同的項目,將同構型較高的數據區隔為不同的聚類,聚類內數據相似度越高越好,聚類間差異度越大越好。在一大群的研究對象中,根據不同的研究目的必定會有異質化的現象,但異質化的現象可能是幾個同質化的群組所造成,數據聚類的主要目的便是將不同的同質化的組別差異找出來,常用“判別分析”與聚類分析“算法。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據挖掘
+關注
關注
1文章
406瀏覽量
24287
發布評論請先 登錄
相關推薦
精準定位隧道挖掘通訊難題:虹科PCAN卡如何滿足專業通訊需求?
在現代隧道挖掘行業中,電控系統作為設備的“大腦”,其性能優劣直接關系到設備的整體運作效率與安全性。本文將深入探討虹科PCAN卡在隧道挖掘機器電控系統中的應用,了解它是如何提升設備性能,確保工程

中科曙光受邀參加第十屆中國數據挖掘會議
近日,國內數據挖掘領域最主要的學術活動之一—第十屆中國數據挖掘會議(CCDM2024)于山東泰安舉行,中科曙光參與并分享了曙光AI構建產學研用的生態實踐。
工業數據中臺的功能和應用場景
工業數據中臺是一個集數據采集、存儲、處理、分析和應用于一體的綜合性平臺,其主要功能和應用場景如下: 功能 1.數據采集與接入: 支持多種
易華錄無錫數據湖與清華大學蘇州汽車研究院(吳江)合作挖掘智能駕駛數據新價值
6月15日,易華錄無錫數據湖與清華大學蘇州汽車研究院(吳江)數字工業中心就“聚焦汽車智能駕駛領域,共同挖掘智駕數據新價值”舉行了簽約儀式。清華大學蘇州汽車研究院顧問、數字工業中心主任王小明,易華錄
數據采集網關的功能和應用場景
隨著信息技術的飛速發展,物聯網系統在各行業的應用越來越廣泛,數據采集網關作為物聯網系統中的重要組成部分,發揮著至關重要的作用。本文將詳細介紹數據采集網關的功能及應用場景,以便讀者更好地理解其在物聯網

工業數據采集網關功能優勢
實現智能制造和精益生產提供了強有力的支持。 一、工業數據采集網關的定義與功能 工業數據采集網關是一種用于連接不同設備、系統和網絡,實現數據互通與信息共享的設備。其主要

求助,labview數據存儲和歷史數據查詢功能應該如何做課程設計?
純labview小白,正在做聲卡聲音信號采集的課程設計,要求有數據存儲和歷史數據查詢功能,搞不懂如何歷史數據查詢,都將數據存儲在了文件夾,在
發表于 04-15 09:32
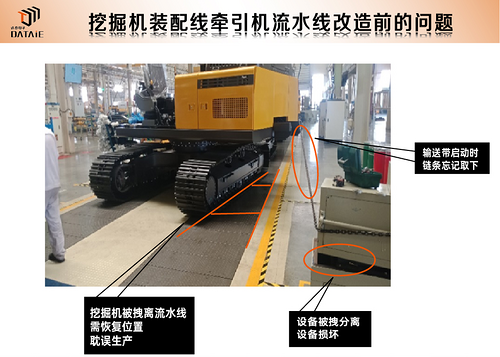
牽引機和挖掘機裝配流水線自動互鎖防呆系統無線通訊應用
在挖掘機裝配工序中,液壓系統檢測、調試是其生產工藝中的重要環節。液壓檢測過程中需要操作鏟斗、斗桿、動臂動作,這一過程中流水線挖掘機因帶動偏移易發生安全事故及機械損傷故障等情況,需要采用牽引機鏈條牽引

AD4003數據手冊中的Input span compression功能是什么意思?
AD4003數據手冊中的Input span compression功能是什么意思啊
發表于 02-26 08:19
挖掘機生產裝配線無線通訊應用
一、應用背景 山東某挖掘機機械有限公司主要產品有裝載機、挖掘機、道路機械及核心關鍵零部件等系列工程機械產品。為加速新舊動能轉換,全新挖掘機整機裝配線配合勞動組合的調整,提高裝配水平和生產效率;可集中
谷歌在Play商店啟用AI摘要功能?
據悉,現階段該功能對少數用戶開放,他們可以在應用詳情頁面的“安裝”按鈕之下查看到“應用亮點”。這一功能依靠AI算法自動挖掘出應用的核心優勢,并用通俗易懂的文字概括出來,以便用戶能夠迅速了解應用的主要特色。
數據挖掘的應用領域,并舉例說明
數據挖掘(Data Mining)是一種從大量數據中提取出有意義的信息和模式的技術。它結合了數據庫、統計學、機器學習和人工智能等領域的理論和方法,通過高效的算法和工具,對大





 工商網監
工商網監
評論