") 一種不同于雙線性插值的上采樣方法
一種不同于雙線性插值的上采樣方法
今天為大家推薦一篇 CVPR2019 關(guān)于語義分割的文章 Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation,該文章提出了一種不同于雙線性插值的上采樣方法,能夠更好的建立每個(gè)像素之間預(yù)測的相關(guān)性。得益于這個(gè)強(qiáng)大的上采樣方法,模型能夠減少對特征圖分辨率的依賴,能極大的減少運(yùn)算量。該工作在 PASCAL VOC 數(shù)據(jù)集上達(dá)到了 88.1% 的 mIOU,超過了 DeeplabV3 + 的同時(shí)只有其 30% 的計(jì)算量。
論文傳送門:https://arxiv.org/abs/1903.02120
1. Introduction
在之前的語義分割方法中,雙線性插值通常作為其最后一步來還原特征圖的分辨率,由于非線性差值不能建立起每個(gè)像素的預(yù)測之間的關(guān)系,因此為了得到精細(xì)的結(jié)果,對特征圖的分辨率要求較高,同時(shí)帶來了巨額的計(jì)算量。
為了解決這個(gè)問題,本工作提出了Data-dependent Up-sampling (DUpsample),能夠減少上采樣操作對特征圖分辨率的依賴,大量的減少計(jì)算量。同時(shí)得益于 DUpsample, Encoder 中的 low-level feature 能夠以更小的運(yùn)算量與 Decoder 中的 high-level feature 進(jìn)行融合,模型結(jié)構(gòu)如下所示:
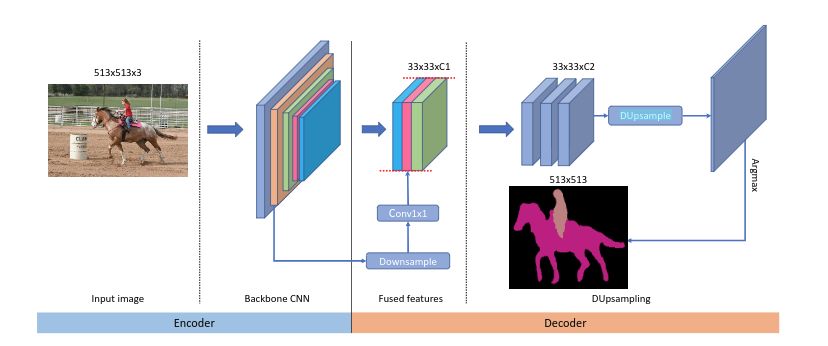
我們可以看到,該網(wǎng)絡(luò)將傳統(tǒng)的非線性插值替換成 DUpsample,同時(shí)在 feature fuse 方面,不同于之前方法將 Decoder 中的特征上采樣與 Encoder 特征融合,本工作將 Encoder 中的特征下采樣與 Decoder 融合,大大減少了計(jì)算量 ,這都得益于 DUpsample。
2. Our Approach
之前的語義分割方法使用下列公式來得到最終的損失:
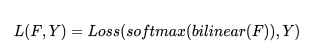
其中 Loss 通常為交叉熵?fù)p失,F(xiàn) 為特征圖,Y 為 ground truth,由于雙線性插值過于簡單,對特征圖 F 的分辨率較高,因此引入了大量的計(jì)算。一個(gè)重要的發(fā)現(xiàn)是語義分割輸入圖像的 label Y 并不是 i.i.d 的,所以 Y 可以被壓縮成 Y′,我們令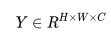 , 并將 Y 劃分成
, 并將 Y 劃分成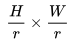 的子窗口,每個(gè)子窗口的大小為 r×r,接著我們將每個(gè)子窗口
的子窗口,每個(gè)子窗口的大小為 r×r,接著我們將每個(gè)子窗口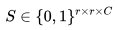 拉伸成向量
拉伸成向量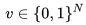 ,其中
,其中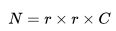 ,隨即我們將向量 v 壓縮成低維向量 x,我們使用線性投影來完成,最后,我們有:
,隨即我們將向量 v 壓縮成低維向量 x,我們使用線性投影來完成,最后,我們有: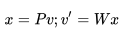 其中
其中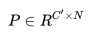 ,用來將 v 壓縮成 x,
,用來將 v 壓縮成 x,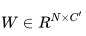 為 reconstruction matrix, v′為重建后的 v,我們可以用壓縮后的向量 x 組合成 Y′.
為 reconstruction matrix, v′為重建后的 v,我們可以用壓縮后的向量 x 組合成 Y′.
矩陣 P 和矩陣 W 可以通過最小化下列式子得到:
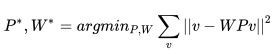
我們可以使用梯度下降,或者在正交約束的條件下使用 PCA 求解。
使用壓縮后的 Y′為目標(biāo),我們可以使用下列損失函數(shù)來預(yù)訓(xùn)練網(wǎng)絡(luò):
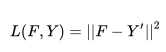
另一種直接的方法是在 Y 空間計(jì)算 loss,也就是并非將 Y 壓縮到 Y′, 我們可以將 F 使用 W(上面預(yù)訓(xùn)練得到的)上采樣然后計(jì)算損失,公式如下:
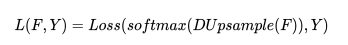
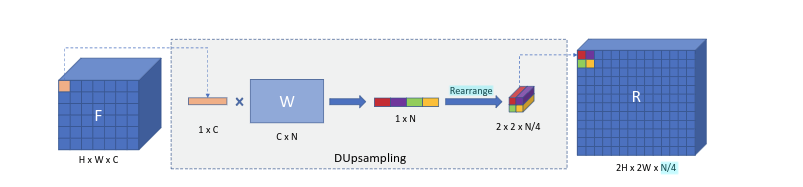
其中以兩倍為例,DUpsample 的操作如下圖所示:
我們可以用 1X1 卷積來完成上述的權(quán)重與特征相乘的過程。但是當(dāng)我們將這個(gè)模塊嵌入到網(wǎng)絡(luò)時(shí)會遇到優(yōu)化問題。因此我們使用 softmax with temperature 函數(shù)來解決這個(gè)問題:
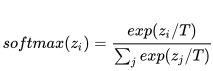
。
我們發(fā)現(xiàn) T 可以使用梯度下降學(xué)習(xí)得到,這樣減少了調(diào)試的麻煩。
有大量的工作說明,與 low-level features 結(jié)合可以顯著的提升分割的精度,其做法如下: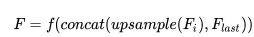
f 是在上采樣之后的卷積操作,其計(jì)算量依賴于特征圖的空間大小,這樣做會顯著增加計(jì)算量。得益于 DUpsample,我們可以使用下列操作來減少計(jì)算量:
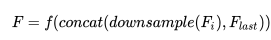
這樣做不僅保證了在低分辨率下的有效性,而且減少了計(jì)算量,同時(shí)允許任意 level feature 的融合。
只有使用了 DUpsample,上述操作才變得可行,否則語義分割的精度會被雙線性插值限制。
3. Experiments
本次實(shí)驗(yàn)使用以下兩種數(shù)據(jù)集:PASCAL VOC 2012 和 PASCAL Context benchmark。我們使用 ResNet-50 或 Xception-50 作為我們的 backbone,具體訓(xùn)練細(xì)節(jié)詳見論文。
首先我們設(shè)計(jì)實(shí)驗(yàn)說明雙線性插值的上限遠(yuǎn)遠(yuǎn)低于 DUpsample。首先我們搭建一個(gè)簡易網(wǎng)絡(luò)實(shí)現(xiàn) auto-encoder,其中上采樣方式分別使用雙線性插值與 DUpsample, 輸入分別為 ground_truth,得到下表中的 mIOU*,這個(gè)指標(biāo)代表上采樣方法的上限。同時(shí)我們使用 ResNet50 作為主干網(wǎng)絡(luò),輸入為 raw image 去實(shí)現(xiàn)語義分割,得到下表中的 mIOU:
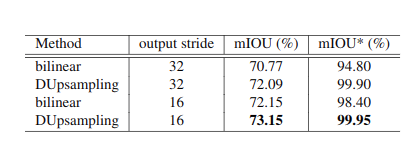
通過上表我們可以發(fā)現(xiàn):
1) 在相同條件下,DUpsampling 效果優(yōu)于 bilinear。
2)DUpsampling 在 output_stride=32 的情況下效果與 bilinear 在 output_stride=16 的情況下結(jié)果相當(dāng)。
接下來我們設(shè)計(jì)實(shí)驗(yàn)說明融合不同的 low-level 特征對結(jié)果的影響,如下表所示:
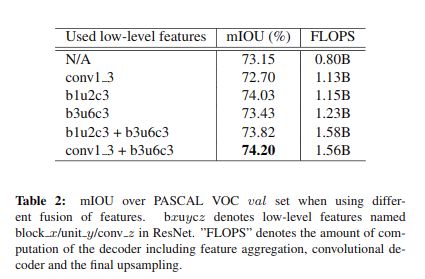
值得說明的是,并不是所有與 low-level feature 的融合都會提升結(jié)果,例如 conv1_3,因?yàn)槠浣Y(jié)果不夠魯棒。因此和什么 low-level feature 相結(jié)合對語義分割的結(jié)果有很大的影響。
接下來我們設(shè)計(jì)實(shí)驗(yàn)與雙線性插值進(jìn)行比較:
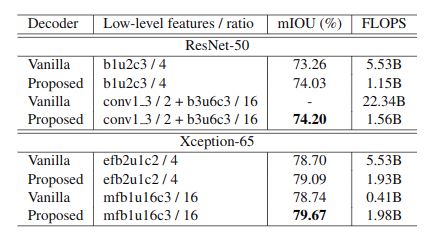
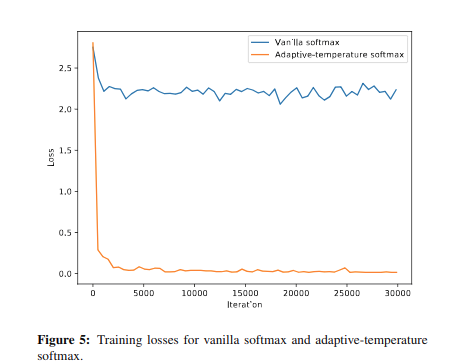
可以看到我們的方法優(yōu)于傳統(tǒng)的雙線性插值上采樣方法。同時(shí)我們驗(yàn)證了不同的 softmax 對結(jié)果的影響,在沒有使用 softmax with tenperature 的情況下只有 69.81 的 mIOU(這里沒設(shè)置消融實(shí)驗(yàn)有些疑惑,感覺不同的 softmax 對實(shí)驗(yàn)結(jié)果影響挺大的)。
最后將我們的方法與最新的模型進(jìn)行比較,結(jié)果如下(分別為 PASCAL VOC 與 PASCAL context):
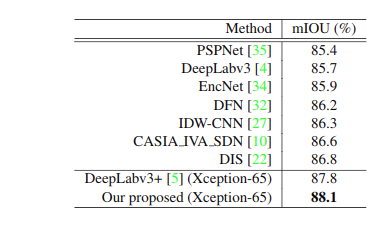
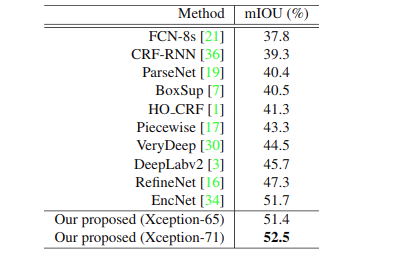
我們的方法在只用 deeplabv3+ 30% 的計(jì)算量的情況下,超越了當(dāng)前所有的方法。
總的來說,我覺得這個(gè)論文提出的想法很有趣,是一篇很有 insight 的論文。
由于論文現(xiàn)在還沒有開源,筆者嘗試實(shí)現(xiàn)了一下 DUpsample 的操作和網(wǎng)絡(luò):
https://github.com/LinZhuoChen/DUpsampling。
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4345瀏覽量
62867 -
梯度
+關(guān)注
關(guān)注
0文章
30瀏覽量
10335 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24790
原文標(biāo)題:Decoders對于語義分割的重要性 | CVPR 2019
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
什么是線性插值?一維線性插值和雙線性插值在BMS開發(fā)中的應(yīng)用
求線性插值
求雙線性插值法的C語言程序!幫幫忙!拜托各位了!
一種基于FPGA的實(shí)時(shí)視頻圖像處理算法研究與實(shí)現(xiàn)
基于FPGA的線性插值-上
雙線性變換法設(shè)計(jì)數(shù)字Butterworth和Chebyshe
一種改進(jìn)的線性圖像插值算法
基于最優(yōu)移位雙線性插值的圖像縮放旋轉(zhuǎn)硬件加速研究
基于AIS線性插值的綜合插值方法

在FPGA上如何實(shí)現(xiàn)雙線性插值的計(jì)算
一種線性插值隨機(jī)對偶平均優(yōu)化方法
雙線性插值算法的講解
基于FPGA的圖像旋轉(zhuǎn)和雙線性插值算法設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論