 為大家介紹了多篇2019 CVPR的精彩、優質論文解讀!
為大家介紹了多篇2019 CVPR的精彩、優質論文解讀!
最近,AI科技大本營陸續為大家介紹了多篇 2019 CVPR 的精彩、優質論文解讀!為了方便大家集中學習,營長特此為大家做了近期的匯總整理!不僅如此,作為清明小長假的第一天,營長精心準備了更精彩的福利內容:回顧 2018 年 CVPR 的 3 天大會,并對主要內容進行了整理與總結,也談及了一些研究趨勢,正好可以與今年的成果進行對比!
回顧 CVPR 2018,三天會議主要包括以下九大部分內容:
特別版塊:專題研討會及比賽
目標識別和場景理解問題
對圖像中人的分析研究
3D視覺問題
視頻分析問題
計算攝影問題
圖像運動及跟蹤問題
應用
下面是去年總結的一些未來值得研究的趨勢和話題,隨著 CVPR 2019 的成果不斷跟蹤與積累,后續還可以繼續做對比與分析:
視頻分析:如視頻字幕,動作分類,預測人(行人) 移動的方向等問題
視覺情感分析
空間(房間) 中智能體的方向,虛擬房間數據集,這些話題都跟機器學習的應用有關
視頻中的行人重識別問題
圖像的風格轉移(GAaaaNs) 仍然是一個研究熱點
對抗性攻擊問題的分析
圖像增強問題,包括消除圖像脫落、陰影等問題
自然語言處理與計算機視覺領域的結合話題
圖像和視頻的顯著性分析
邊緣設備(edge device) 上的計算效率問題
弱監督學習下的計算機視覺問題
域自適應問題
機器學習的可解釋性
強化學習在計算機視覺領域中的應用:包括網絡優化,數據,神經網絡的學習過程等
有關數據標記領域的話題
接下來,AI科技大本營把 2018 CVPR 會議上的主要內容劃分了八大類別為大家做進一步的分析:
1.場景的分析與問答
2.圖像增強及操作
3.計算機視覺領域中的各種神經網絡架構
4.基于目標驅動的導航系統及室內3D場景
5.人物相關性分析
6.高效的深度神經網絡
7.文本與計算機視覺
8.數據與計算機視覺
一、場景分析及問答
模塊主題一:Embodied Question Answering (具體的問答問題)
亮點:走向具體化的智能體,能夠聽說看,還能采取行動和進行推理。
架構和技術細節:
視覺模型:結構示意圖如下,以 CNN 結構作為編碼,進行多任務的、像素到像素的預測。
語言模型:兩層的 LSTMs 結構。
操縱模型:結構示意圖如下,這是一個多層次的 RL 結構。Planner 選擇動作 (向前,向左,向右),而控制器 (controller) 將這些原始動作作為多次使用的變量,并將 controller 執行的結果返回給 planner。
回答模型:結構示意圖如下,檢查最后5幀,并根據圖像--問題的相似度來計算一個基于注意池化的視覺編碼,然后將這些與問題的 LSTM 編碼相結合,并在 172 個可能的答案空間上輸出 softmax 結果。
數據集:使用EQA 數據集 (環境中的問題):該數據集含有 rgb 圖像,語義分割掩碼,深度映射圖,自上而下的映射圖。此外,數據集共包含12種房型 (廚房,生活區等) 和50種對象類型,并以編程方式生成的問題,這與 CLEVR 數據集的方式類似。
應用場景:智能體能夠在自然環境中采取行動并跟人類以自然語言的方式交流。
論文與項目地址:
https://arxiv.org/abs/1711.11543
https://embodiedqa.org/
https://github.com/facebookresearch/EmbodiedQA
模塊主題二:Learning by Asking Questions (LBA) (通過問答進行學習)
亮點:LBA Interactive Agents,決定它們需要什么樣的信息以及如何獲取這些信息。這種方式更優于被動的監督式學習。
架構和技術細節:給定一組圖像提出問題,以監督學習的方式得到問題的答案。其流程如下圖所示:
問題生成模型:是一種圖像字幕生成模型,它使用以圖像特征 (第一隱藏輸入) 為條件的 LSTM 模型來生成一個問題。而問答模塊是標準的 VQA 模型。
數據集:使用 CLEVR 數據集,包含 70K 張圖片和 700 張 QA 圖片。
參考:
https://research.fb.com/publications/learning-by-asking-questions/
模塊主題三:Im2Flow: Motion Hallucination from Static Images for Action Recognition (基于靜態圖幻覺的動作識別研究)
亮點:將靜態圖像轉換為精準的映射流圖,并通過 single snapshot 的方式預測隱含的、未觀察到的未來的運動情況。這有助于靜態圖像的動作識別研究。
架構和技術細節:通過編碼--解碼的 CNN 結構和一種新穎的光流編碼結構,來將靜態圖像轉換為映射流圖。其結構示意圖如下:
數據集:UCF-101 HMDB-51 的視頻數據集上訓練,該數據集含 700K 幀。
應用場景:圖像視頻分析,字幕生成,動作識別和動態場景識別。
其他觀點:除了人類的運動,該模型還可以用于預測場景的運動情況,如海洋中波浪的起落等。此外,該模型也可以推斷出新圖像的運動潛在性 (得分),即準備發生的運動和運動的強度等。
論文與項目地址:
https://arxiv.org/abs/1712.04109
http://vision.cs.utexas.edu/projects/im2flow/
模塊主題四:Actor and Action Video Segmentation from a Sentence (基于語句的視頻動作、動作者分割研究)
亮點:動作由自然語句所指定 (vs 預定義好的動作詞匯表)。任何動作者 (vs 與人類接近的動作者)。
架構和技術細節:來自于自然語句的 RGB 模型,該模型用于動作者和視頻動作的分割任務,包括三個組成,其結構示意圖如下:
用 CNN 結構來編碼表達式
用 3D CNN 結構來對視頻進行編碼
解碼器:通過對已編碼好的文本表征和視頻表征進行進行動態的卷積過程,實現逐像素的分割。此外,相同的模型也應用于輸入流。
數據集:兩個流行的動作者和動作數據集,包含超過7500條的自然語言描述。
應用場景:視頻分析,索引,字幕生成等。
其他觀點:
IoU (Intersectionction-union) 用于衡量分割結果的質量。
句子感知 (sentence awareness) 對動作者和動作描述是有幫助的。
視頻感知 (video awareness) 有助于得到更準確的分割結果。
好的效果圖如下:
論文與項目地址:
https://arxiv.org/abs/1803.07485
https://kgavrilyuk.github.io/publication/actor_action/
模塊主題五:Egocentric Activity Recognition (EAR) on a Budget (以自我為中心的動作識別研究)
亮點:基于不同的能量模型,利用 RL 學習策略。
架構和技術細節:智能眼鏡的功能受限于電池及其自身的處理能力。
數據集:基準數據集采用 Multimodal 數據庫。
應用場景:使用 AI 來幫助進行生活助理和護理服務工作 (使用智能眼鏡得到的數據進行動作的跟蹤和識別)。此外,EAR 還可以提供自動提醒/警告的功能,幫助認知障礙以避免危險情況。
其他觀點:學習用戶環境是利用能量運動和視覺方法的關鍵。
論文地址,數據集鏈接:
http://sheilacaceres.com/dataego/
http://www-personal.usyd.edu.au/~framos/Publications_files/egocentric-activity-recognition%20(2).pdf
模塊主題六:Emotional Attention: A Study of Image Sentiment and Visual Attention (情感注意力:圖像情感與視覺注意力研究)
亮點:這是第一項側重于圖像情感屬性與視覺注意力之間關系的研究。此外,該研究另一貢獻是創建 EMOtional 注意數據集 (EMOd 數據集)。
架構和技術細節:設計一個深度神經網絡結構用于顯著性預測,結構包括一個學習圖像場景中空間和語義上下文信息的子網絡,結構示意圖如下。CASNet:一個對通道進行加權操作的子網絡 (下圖中在虛線橙色矩形內部分),用于計算每個圖像中一組1024維特征的權重,以捕獲特定圖像語義特征信息的相對重要性。
灰色虛線箭頭表示的是通過子網絡修正后,圖像中不同區域的相對顯著性。
數據集:三種包含情感內容的數據庫:EMOd 數據集包含1019張圖片,NUSEF數據集包含751張圖片,CAT 數據集包含2000張圖片。
應用場景:用于視頻監督,字幕生成等。
其他觀點:情感目標會吸引簡短而強烈的注意力。與人類相關的目標的情感優先級要大于那些與人類無關的目標。
論文地址:
https://nus-sesame.top/emotionalattention/
模塊主題七:Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation (基于角定位和區域分割的多導向場景文本檢測研究)
亮點:通過定位文本邊界框的角點并在相對位置上分割文本區域來檢測場景中的文本。
架構和技術細節:結合目標檢測和語義分割的思想,并以另一種方式應用二者。基于給定的圖像,網絡通過角點檢測和位置敏感性分割輸出角點和分割映射圖。然后通過對角點進行采樣和分組來進一步生成候選框。最后,通過分割映射圖和 NMS 抑制來得到這些候選框的分數。其結構示意圖如下:
數據集:ICDAR2013 數據集,ICDAR2015 數據集,MSRA-TD500 數據集, MLT 和 COCO-Text 數據集。
應用場景:一些從自然場景圖像中提取文本信息的任務:如產品搜索,圖像檢索,自動駕駛等。
其他觀點:與一般物體檢測相比,場景中的文本檢測更加復雜,因為:
場景文本可能存在于任意方向的自然圖像中,因此邊界框的形狀可以是旋轉的矩形或四邊形。
場景文本的邊界框的寬高比變化很大。
由于場景文本的形式可以是字符,單詞或文本行等,因此算法在定位邊界時可能會產生混淆。
論文地址:
https://arxiv.org/abs/1802.08948
模塊主題八:Neural baby talk (神經網絡之間的對話)
亮點:Neural baby talk:這是一種新穎的框架,用于準確地定位圖中的目標,同時生成自然語言描述字幕。首先,生成指數量級的模板,再將檢測過程與字幕生成過程分離,并以不同類型的監督方式進行處理。該研究使用神經網絡的方法協調經典的“槽填充”方法 (slot filling),同時在聽覺上和視覺上實現神經網絡的應用。
架構和技術細節:其結構示意圖如下:
數據集:COCO 數據集。
應用場景:圖像字幕生成任務。
其他觀點:該研究使目標檢測的升級版--在目標檢測的基礎上結合了自然語言的處理。
論文和github 鏈接:
https://arxiv.org/pdf/1803.09845.pdf
https://github.com/jiasenlu/NeuralBabyTalk
二、計算機視覺領域中的各種神經網絡架構
模塊主題一:Deep Layer Aggregation (深度層聚合)
亮點:深度層聚合的方式使得模型具有更準確的性能表現和更少的參數量,同時這也為深層可視化架構的泛化和有效擴展應用提供了一種方式。
架構和技術細節:模型通過學習任意模塊的聚合層輸出,表現出更有表現力的層輸入和更快速的層聚合性能。其結構示意圖如下:
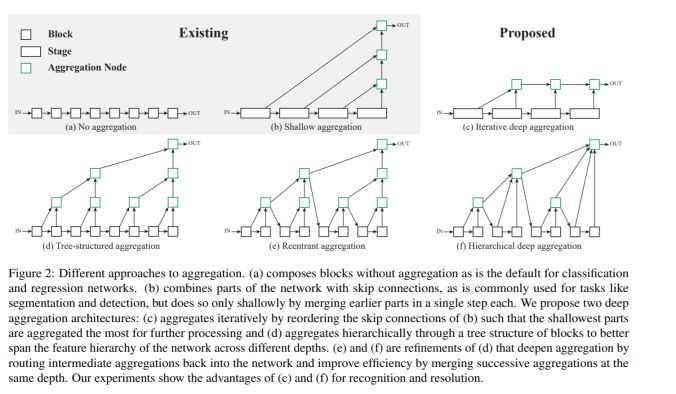
應用場景:圖像識別,圖像分割任務。
其他觀點:該研究涉及到未來圖像識別領域的兩個趨勢:
更好的構建模塊。
跳躍連接。
我們要考慮的是如何才能使二者更好得兼容,以及如何通過有效的跳躍連接來提高 DRN (擴張性的殘差神經網絡) 的準確性?
論文和github 鏈接:
https://arxiv.org/abs/1707.06484
https://github.com/ucbdrive/dla
http://www.scalabel.ai/
模塊主題二:Practical Block-wise Neural Network Architecture Generation (逐模塊地神經網絡結構生成)
亮點:該研究提出了一個名為 BlockQNN 的逐模塊神經網絡生成管道 (pipeline)
架構和技術細節:神經網絡生成管道(pipeline)模塊能夠通過帶 epsilon-greedy 探索策略的 Q-Learning 范式來自動構建高性能的神經網絡結構。此外,它還是個分布式的異步網絡框架,這能大大提高網絡的運行速度。其結構示意圖如下:
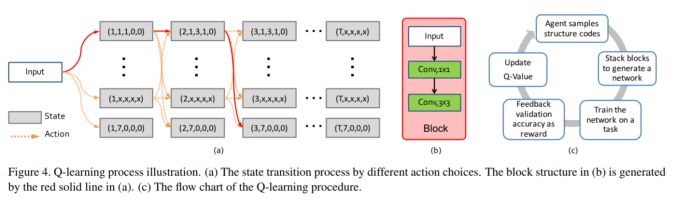
數據集:CIFAR,ImageNet
其他觀點:在 CIFAR 數據集上的圖像分類任務:使用32個 GPU只需花費3天的時間就能自動生成網絡結構,這比 NASv1-Google (800GPU,28天) 所需的時間和資源要少的多。
論文鏈接:
https://arxiv.org/abs/1708.05552
模塊主題三:Relation Networks for Object Detection (用于目標檢測的推理網絡)
亮點:目標關系的建議模塊 (ORM) 可以嵌入到現有的目標檢測體系中 (如 Faster RCNN),并提高了目標檢測的 mAP 值 (+ 0.5-2)。此外,該模塊能夠通過目標的外觀特征和幾何關系間的交互來同時處理一組目標。
架構和技術細節:其結構示意圖如下
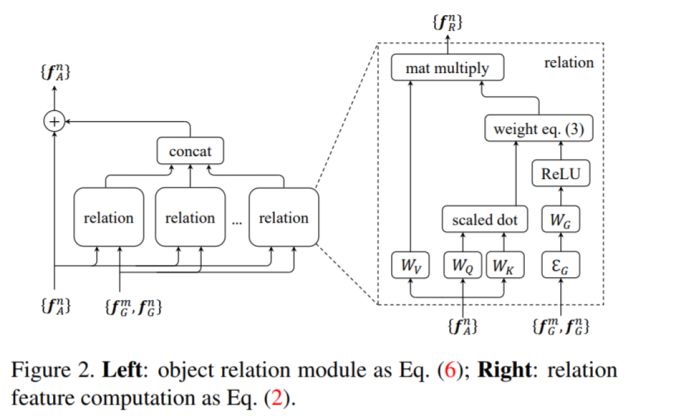
其他觀點:該研究作者聲稱,在 Faster RCNN 中插入2個建議模塊 (ORM),可以提高 2.3 mAP。此外,這種關系網絡的學習不僅能夠適用于具有高關系權重的目標對,還能在不同類之間實現信息的共享。
論文和 github 鏈接:
https://arxiv.org/abs/1711.11575
https://github.com/msracver/Relation-Networks-for-Object-Detection
模塊主題四:DeepGlobe: A Challenge for Parsing the Earth through Satellite Images (DeepGlobe:通過衛星圖像解析地球)
亮點:該研究包含三個部分:用于路面特征提取的 D-LinkNet,用于地面覆蓋物分類的 Dense Fusion,以及用于建筑物檢測的 Multi-task U-net。
架構和技術細節:
1、D-LinkNet:
結構:網絡采用 LinkNet 結構構建,并在其中心部分引入了擴張卷積層 (dilated convolution layer)。Linknet 結構在計算和存儲方面都非常高效。擴張卷積是一種強大的工具,可以在不降低特征映射圖分辨率的情況下擴大特征點的感受野。
損失函數和優化器:以 BCE (二進制交叉熵) 和 dice coefficient loss 作為損失函數,以 Adam 作為優化器。
數據增強:在測試階段的圖像增強 (TTA),包括圖像水平翻轉,圖像垂直翻轉,圖像對角線翻轉 (每張預測圖像將被增強 2×2×2 = 8次),然后還原輸出圖像以匹配原始圖像。
2、Dense Fusion:密集融合網絡(DFCNet),其結構示意圖如下:
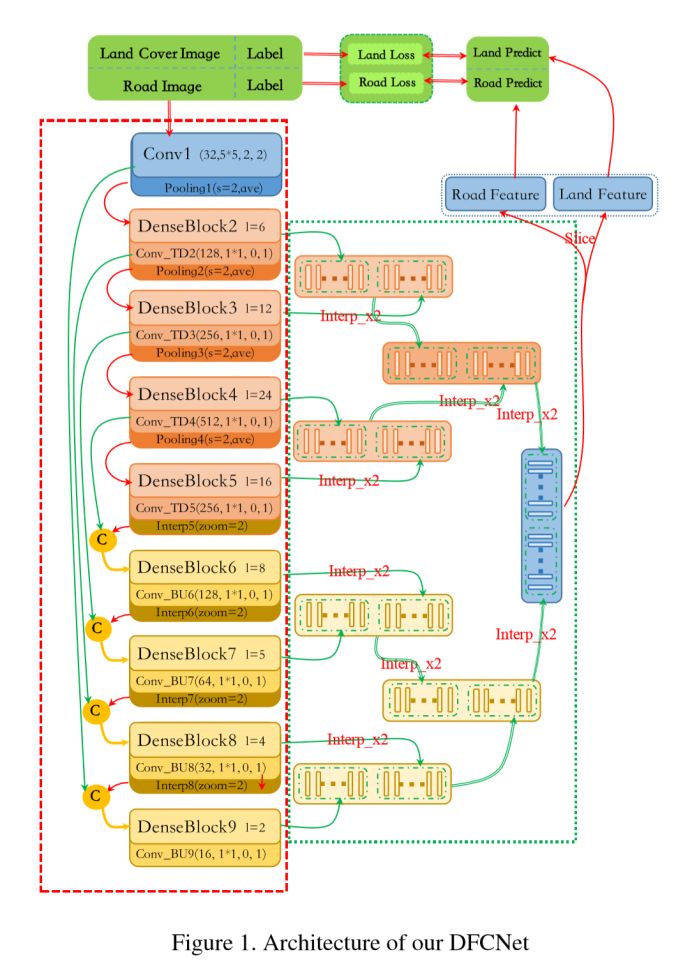
Multi-task U-net:其結構示意圖如下:
數據集:高分辨率的衛星圖像數據集及其相應的訓練數據。
應用場景:可用于三種任務挑戰--道路特征提取,建筑物檢測及地面覆蓋物分類。
其他觀點:對于實例分割任務,除了少數一兩個研究中使用到 maskRCNN 結構,其他的研究都是基于 Unet 網絡展開的,如 stacked Unet,NU-net,multi-task Unet等。
項目主頁鏈接:
http://deepglobe.org/
模塊主題五:Interpretable Machine Learning for Computer Vision (計算機視覺中可解釋性的機器學習)
亮點:可解釋性并不是要理解模型中所有數據點的所有細節。
架構和技術細節:詳細介紹在下面的鏈接中
應用場景:當你向別人展示一個 AI 項目時,大多數人仍然認為 AI 是一個黑盒子。而該研究能夠為這一切提供不錯的解釋。
其他觀點:
何時需要可解釋性:當我們無法將想法形式化時,可解釋性可以幫助我們實現。
何時不需要可解釋性:你只需要預測的情況;已被充分研究的問題;不匹配的目標問題等。
可解釋性的例子:EDA;規則解讀;例子;稀疏性和單調性;消融測試 (ablation test);輸入特征的重要性;概念的重要性等。
如何評估:通過實驗 (human experiment and ground-truth experiment)。
關于 t-sne可視化 (google 有一篇關于 t-sne 可視化的文章):使用 T-SNE 可視化模型的思考方式。
參考鏈接:
http://deeplearning.csail.mit.edu/slide_cvpr2018/been_cvpr18tutorial.pdf
https://interpretablevision.github.io/
模塊主題六:What do deep networks like to see? (深度神經網絡喜歡看什么?)
亮點:對分類器進行交叉式重建。
架構和技術細節:其結構示意圖如下:
數據集:YFCC100m,Imagenet
應用場景:解釋或理解 CNNs。
其他觀點:該研究深入了解深度神經網絡的每一層,這可能有助于選擇所要切割的層,提取圖像特征以及使用這些特征來訓練新模型。
項目主頁鏈接:
https://spalaciob.github.io/s2snets.html
模塊主題七:Context Encoding for Semantic Segmentation(用于語義分割的上下文編碼)
亮點:相比于 FCN,上下文編碼模塊在略微增加計算成本的情況下,能夠顯著地改善語義分割的結果。總的說來,該研究的主要貢獻包括:提出語義編碼丟失 (SE-loss):這是一個利用全局場景的上下文信息的單元。實現了一個新的語義分割框架:上下文編碼網絡 EncNet,增強了一個預訓練好的深度殘差網絡。
架構和技術細節:該模塊能夠選擇性地突出與類別相關的特征映射,并簡化了網絡的問題。該模型在 ADE20K 測試集上取得了0.5567的最終得分,超過了 COCO Challenge 2017 的獲勝者的表現。此外,它還改進了相對陰影網絡的特征表示,這是在 CIFAR-10 數據集上用于圖像分類任務的模型。其結構示意圖如下:
數據集:PSCAL-Context 數據集,PASCAL VOC 2012 數據集,ADE20K 數據集,CIFAR-10 數據集
應用場景:語音分割任務
論文及 github 鏈接:
https://arxiv.org/pdf/1803.08904.pdf
http://hangzh.com/PyTorch-Encoding/experiments/segmentation.html
https://github.com/zhanghang1989/PyTorch-Encoding
模塊主題八:Learn to See in the dark(“暗夜之眼”:學會在黑暗中觀察)
亮點:訓練一個端到端的全卷積神經網絡,用于處理低光圖像。
架構和技術細節:其結構示意圖如下:
數據集:研究中使用的數據集由作者收集的,包括夜間的室內和室外圖像,共5094個原始短曝光圖像。
應用場景:圖像處理
其他觀點:未來我們要思考的是這項研究能否封裝成一個 API,以方便使用。
論文及 github 鏈接:
https://arxiv.org/pdf/1805.01934.pdf
https://github.com/cchen156/Learning-to-See-in-the-Dark
三、圖像增強及操作
模塊主題一:xUnit: Learning a Spatial Activation Function for Efficient Image Restoration(xUit:用于圖像還原的高效空間激活函數)
亮點:該研究提出的方法能夠顯著地減少模型學習過程的參數量,特別是對用于圖像超分辨率和圖像去噪的神經網絡,其參數量減少了一半以上。
架構和技術細節:與逐像素的激活單元 (如 ReLU 和 sigmoids) 相比,該研究提出的函數單元是一個具有空間連接性的可學習的非線性函數,這使得網絡能夠捕獲更復雜的特征。因此,網絡以更少的層數就能達到相同的性能。其結構示意圖如下。
數據集:BSD68 數據集和Rain12 數據集
應用場景:圖像超分辨率和圖像去燥
論文及 github 鏈接:
https://arxiv.org/abs/1711.06445
https://github.com/kligvasser/xUnit
模塊主題二:Deformation Aware Image Compression(變形可感知的圖像壓縮技術)
亮點:該研究中編碼器無需過多地描述精細結構的幾何形狀,而只需要著重描述一些重要部分的幾何結構,這將大大提高了細節保存的效果 (研究結果已經驗證)。
架構和技術細節:該研究很容易與其他的 CODEC 相結合。由于人類觀察者對部件輕微的局部平移性并不重視,受此啟發作者提出了 SSD 的變形不敏感版本 (以平方差的和作為度量):變形可感知的 SSD 結構 (DASSD)。
數據集:Berkley 的圖像分割數據集和Kodak 數據集
應用場景:圖像壓縮
其他觀點:該研究所展現的視覺效果令人震撼。
論文鏈接:
https://arxiv.org/abs/1804.04593
模塊主題三:Residual Dense Network for Image Super-Resolution(用于圖像超分辨率的殘差密集型網絡)
亮點:該研究的目標是充分利用原始低分辨率 (LR) 圖像的分層特征。
架構和技術細節:其結構示意圖如下:
RGB 模塊的結構示意圖如下:
數據集:DIV2K 數據集,Set5 數據集,Set14 數據集,B100 數據集,Urban100 數據集,Manga109 數據集
應用場景:圖像增強
論文和 github 鏈接:
https://arxiv.org/abs/1802.08797
https://github.com/yulunzhang/RDN
模塊主題四:Attentive Generative Adversarial Network for Raindrop Removal from a Single Image(用于單幅圖像雨滴去除的注意力生成對抗網絡)
亮點:該研究將視覺注意力機制引入生成對抗網絡,在這里的注意力主要是針對特定的雨滴區域。
架構和技術細節:該研究的模型混合了帶 LSTMs 的 GANs 和 Unet 網絡,其結構示意圖如下:
數據集:該研究使用的數據集含有 1K 圖像對。為了準備數據集,研究中作者在拍照時使用了兩塊完全相同的玻璃:一塊玻璃上帶水滴,而另一塊保持清潔,以便形成對比。
應用場景:圖像編輯處理
其他觀點:該研究使用預訓練好的 VGG-16 模型所展現的視覺效果令人震撼,如下圖所示。
論文鏈接:
https://arxiv.org/abs/1711.10098
模塊主題五:Burst Denoising with Kernel Prediction Networks(用于圖像去燥的核預測網絡)
亮點:該研究中采用CNN 結構預測空間變化核,它可以用于圖像對齊和去燥。此外,研究中采用的一種有意思的數據生成方式,用于模型訓練。
架構和技術細節:模型的結構示意圖如下:
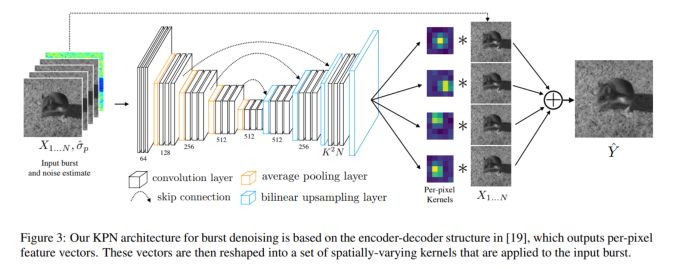
數據集:使用開放圖像數據集的圖像數據來合成訓練數據:修改圖像以引入合成的訓練數據,這些數據是未對齊的和近似噪聲的圖像。為了生成 N 幀的合成數據,作者采用單張圖像并生成 N 張未對齊的、裁剪后的圖像補丁 (cropped patches)。
應用場景:圖像相關的應用
其他觀點:在真實的數據集上 (昏暗條件下用 Nexus 6P手機拍攝),作者聲稱了該研究具有良好的表現:模型是在合成數據集上進行訓練的,經一些圖像預處理后在真實數據集進行基準測試,其中圖像預處理操作包括:去除黑暗度,抑制熱點像素 (hot pixels),交替幀的全像素對齊等。
論文和 github 鏈接:
https://arxiv.org/abs/1712.02327
https://github.com/google/burst-denoising
模塊主題六:Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning(利用深度強化學習精心設計的 Toolchain 用于圖像還原)
亮點:Toolbox 由專門處理小規模不同任務的 CNN 結構和 RL 組成:通過學習策略來選擇最合適的工具以便恢復受損圖像。
架構和技術細節:模型的結構示意圖如下:
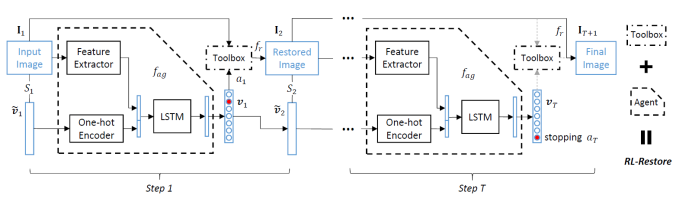
數據集:DIV2K 數據集,一個受損圖像的數據集并添加部分合成的數據。
應用場景:圖像相關的應用
其他觀點:該研究在真實數據集上表現得相當良好。智能代理能夠自主決定何時停止圖像恢復。此外,該框架也能處理并恢復真實圖像的扭曲。
項目主頁和 github 鏈接:
http://mmlab.ie.cuhk.edu.hk/projects/RL-Restore/
http://mmlab.ie.cuhk.edu.hk/projects/RL-Restore/
四、基于目標驅動的導航系統及室內 3D 場景
模塊主題一:Density Adaptive Point Set Registration(基于密度自適應機制的點集配準研究)
亮點:該研究能夠成功解決地面激光雷達應用中常見的密度嚴重變化問題。
架構和技術細節:將場景的潛在結構視為一個潛在的概率分布模型,以保證點集密度變化的不變性。然后,基于期望最大化的框架,通過最小化 Kullback-Leibler 散度來推斷場景的概率模型及其配準參數。該研究中還引入了觀察的權重函數。
數據集:合成數據集:通過在室內3D場景的多邊形網格上模擬點采樣過程來構建合成點云數據。此外,研究中還使用到 Virtual Photo 數據集和 ETH TLS 數據集。
應用場景:激光相關的應用,3D 地圖,場景理解等。
其他觀點:該研究的作者在幾個具有挑戰性的、來自真實世界的激光雷達數據集上進行了大量實驗,并對3D 場景的基礎結構和采集過程進行建模,以獲得對密度變化的魯棒性。
論文鏈接:
https://arxiv.org/abs/1804.01495
模塊主題二:Im2Pano3D: Extrapolating 360 Structure and Semantics Beyond the Field of View (通過外推法獲取360度的結構及視野外的語義信息)
亮點:為了簡化 3D 結構的預測,我們提出一種平面方程來對3D 表面進行參數化,并訓練模型對這些參數進行直接預測。
架構和技術細節:
該研究的核心思想:利用室內環境的高度結構化,通過學習許多典型場景的統計數據,模型能夠利用強大的上下文信息來預測超出視野范圍 (Field of View,FoV) 的內容。
使用多個損失函數:逐像素精度損失,使用 Patch-GAN 獲取的 mid-level 上下文一致性的對抗損失,以及通過場景類別和目標分布的全局場景一致性測量。最終,每個通道的損失是這三個損失的加權和。
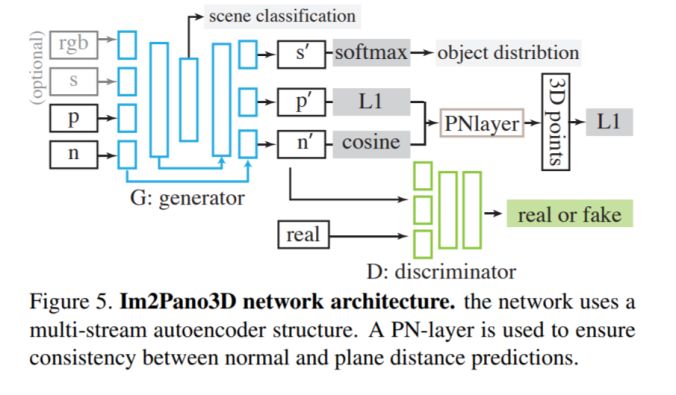
數據集:3D House 數據,其中包含合成的房間 (SUNCG) 和真實的房間(Matterplot3D)。
應用場景:機器人應用,基于目標驅動的導航,下一最佳視角的估計等。
其他觀點:Im2Pano3D 能夠預測未知場景的 3D 結構和語義信息,實現超過56%的像素精度和小于 0.52m 的平均距離誤差。研究還表明經合成數據 SUNCG預訓練,能夠顯著地提高了模型的性能。此外,論文進一步介紹了人類應對場景補全任務的研究結果:雖然目前神經網絡的效果并不是很好,但卻是非常有前途的一個方向。
項目主頁和 github 鏈接:
http://im2pano3d.cs.princeton.edu/
https://github.com/shurans/im2pano3d
模塊主題三:Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments (視覺到語言:在真實環境中解釋視覺的指示信息)
亮點:真實環境中平均的指示信息長度:29個由自然語言構成的單詞。該研究提出第一個用于真實建筑物導航的基準數據集。
架構和技術細節:研究中采用 RNN (Seq2Seq LSTM) 結構。
數據集:Matterport3D 數據集,Room-to-Room (R2R) 數據集,測試數據集采用的是未知的建筑物數據。
應用場景:機器人應用
其他觀點:這是一項成功的研究:作者介紹了 Matterport3D 模擬器,這是一個基于 Matterport3D 數據集的智能代理研究,并開發了新型大規模 RL 可視化的模擬環境。
項目主頁鏈接:
https://bringmeaspoon.org/
模塊主題四:Sim2Real View Invariant Visual Servoing by Recurrent Control (通過循環控制的 Sim2Real 視覺視角不變形研究)
亮點:視覺服務系統利用其對過去運動的記憶來理解動作如何在當前的視覺點影響機器人運動,糾正錯誤并逐漸靠近目標。研究中使用模擬數據和一個強化學習目標來學習該循環控制器。
架構和技術細節:視覺服務系統主要使用視覺反饋機制將工具或終點移動到所需位置。該研究的目標是由要查詢的目標圖像所指示,并且網絡必須都找出該目標在圖像中的位置。模型的結構示意圖如下:
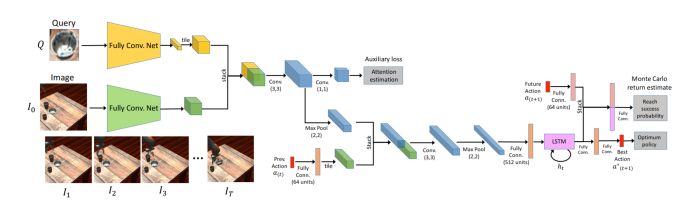
數據集:通過大量生成具有不同相機位置,對象和紋理數據來合成強監督的訓練數據。
應用場景:機器人應用
其他觀點:這是一項有趣,但無法馬上投入生產應用的研究。
論文和項目主頁鏈接:
https://arxiv.org/pdf/1712.07642
https://fsadeghi.github.io/Sim2RealViewInvariantServo/
五、人物相關性分析
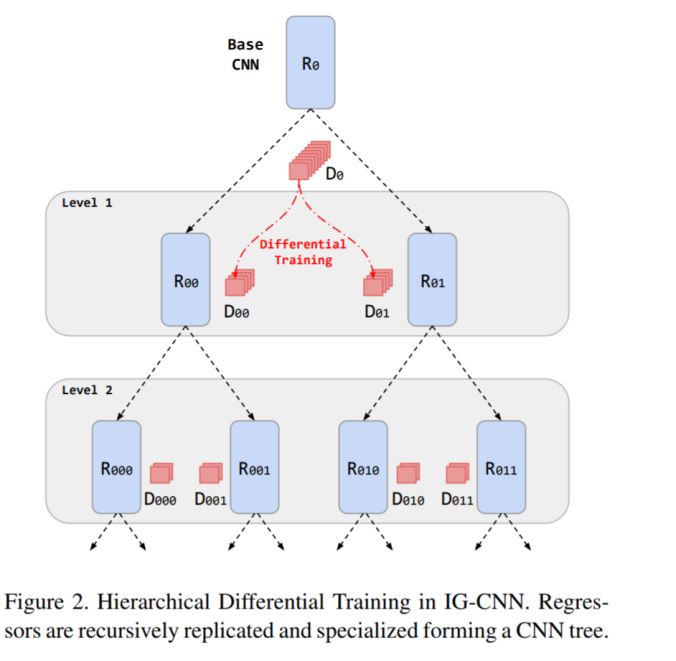
模塊主題一:Divide and Grow: Capturing Huge Diversity in Crowd Images With Incrementally Growing CNN (用遞增式 CNN 結構來捕捉圖像中人群的多樣性)
亮點:該研究采用遞歸式的 CNN 結構來估計人群數量。
架構和技術細節:在預訓練基礎 CNN 模型后,逐步構建 CNN 樹模型,其中每個節點表示在子數據集上微調的回歸量。回歸量的計算是通過復制樹葉節點每個回歸量并經差分訓練專門化子網絡來實現的。模型的結構示意圖如下:
數據集:Shanghaitech 數據集,UCF CC 50 數據集,World Expo10 數據集。
應用場景:與監視有關的應用
其他觀點:該研究的一大亮點是其度量標準:采用平均絕對誤差和均方誤差結合。此外,CNN 樹結構的葉節點處的回歸量是在沒有任何手動指定標準的情況下才記得到的,無需任何的專家干預。
論文鏈接:
http://openaccess.thecvf.com/content_cvpr_2018/html/2726.html
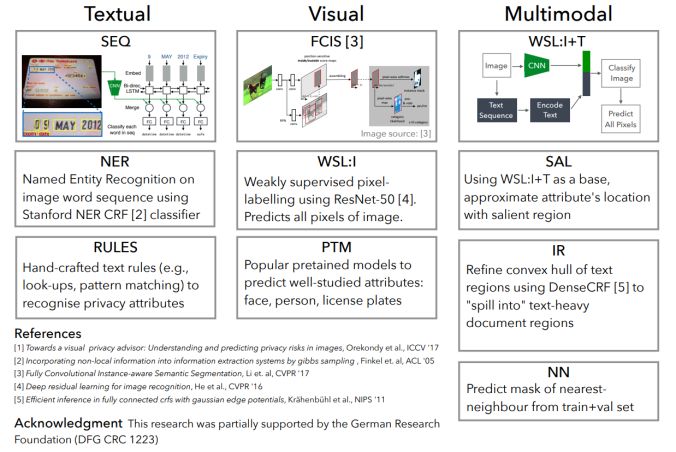
模塊主題二:Connecting Pixels to Privacy and Utility: Automatic Redaction of Private Information in Images (將像素與個人隱私和實用程序相連接:自動編輯圖像中的私人信息)
亮點:這是第一個能夠自動編輯各種私人信息的研究。也是第一個提出大型的私人圖像數據集,這些數據都是在真實環境中采集得到的,研究中對各種隱私類別進行像素和實例級別的標簽注釋。
架構和技術細節:該研究的主要挑戰是要對多種形式的私人信息 (Textual,Visual,Multimodal) 進行跨形式、多屬性的整體編輯。模型的結構示意圖如下:
數據集:該研究采用新的數據集,擴展了原始的 Visual Privacy (VISPR) 數據集,增加了高質量的像素和實例級標簽注釋。最終,作者提出了一個包含 8.5k 張圖像的數據集,這些圖像對24種隱私屬性進行了 47.6k 個實例注釋。
應用場景:隱私數據的清洗
其他觀點:該研究所提出的方法在手動編輯的情況下能夠有效地實現對多種隱私信息與實用程序的權衡,取得83%的性能表現。
項目主頁和 github 鏈接:
https://resources.mpi-inf.mpg.de/d2/orekondy/redactions/
https://github.com/tribhuvanesh/visual_redactions
模塊主題三:Fashion AI (時尚界的 AI)
亮點:這是來自阿里巴巴團隊提出的 Fashion AI 研究。
架構和技術細節:該研究能夠根據時尚的衣服圖片自動創建屬于你自己的衣柜。

數據集:數據來源主要包括兩個方面:首先是來自淘寶上的很多衣服圖片。此外,在 Google 上使用屬性名稱進行關鍵詞搜索以獲取大量的衣服圖像數據。總的來說,最終每個屬性有 100-300 張圖片,共由 12K 張圖片數據構成。
應用場景:阿里巴巴提出的 Fashion AI 應用能夠為造型師自動化地探索服裝的搭配。首先,探索多張圖像并嘗試識別不同風格的衣服。接著,在網站上基于給定的一件 T 恤,Fashion AI 能夠為你推薦相匹配的褲子或裙子。
論文鏈接在:
https://arxiv.org/pdf/1712.02662.pdf
六、高效的深度神經網絡
模塊主題一:Efficient and accurate CNN Models at Edge compute platforms(用于Edge 計算平臺的高效而精準的 CNN 模型)
亮點:該研究提出的 CNN 模型在 DeepLens 上以 CPU 運行實時的目標檢測的速度比在 GPU 上更快。
架構和技術細節:該研究由 XNOR.AI 團隊提出。隨著對 Edge 設備隱私性、安全性及帶寬的需求不斷增長,該研究團隊提出了自己的解決方案:
精度較低 (量化):固定點,二進制 (XNOR-Net)
稀疏模型:基于 CNN 的查找和分解
緊湊型網絡設計:移動網絡 (Mobile Net)
如何提高準確性:標簽精煉。
應用場景:用于 Edge 設備
其他觀點:圖像標簽應該是富含類別的信息的一種軟標識。當前圖像標簽所面臨的挑戰 (以 Imagenet 為例):
標簽具有誤導性:如下圖“波斯貓”的例子:
在無需任何背景的情況下,隨機裁剪可以制作訓練數據。
如果 chihuahua 被錯誤分類為貓或汽車,則會受到同等量級的懲罰。
模塊主題二:Co-Design of Deep Neural Nets and Neural Net Accelerators for Embedded Vision Applications (為嵌入式視覺應用聯合設計深度神經網絡及其加速器)
亮點:該研究提出的觀點是深度神經網絡及其加速器需要聯合設計。
架構和技術細節:流行的神經網絡及其進行目標檢測的計算要求如下圖所示(源于 MobileNetV2 論文):
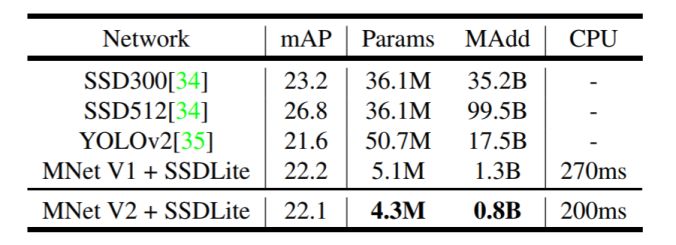

與操作相比,速度與內存訪問的相關性更高更相關;與計算相比,能量消耗與存儲器訪問更相關。
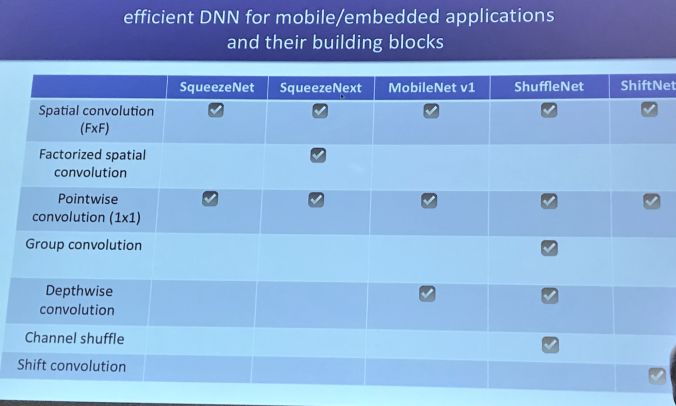
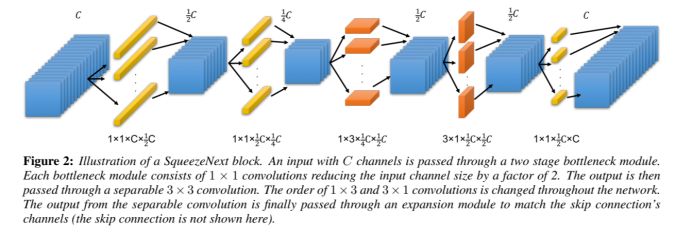
SqueezeNet 網絡:基于硬件可感知的神經網絡,其結構示意圖如下:
應用場景:用于 Edge 設備
其他觀點:
高效的 DNN 計算的關鍵在于數據重用性。
不同的 CNN 層具有數據重用的不同模式。
不同的神經網絡加速器架構支持不同數據類型的重用 (輸出 vs 權重)
論文鏈接:
https://arxiv.org/abs/1804.10642
模塊主題三:Intel deployment tutorial(Intel 的部署教程)
亮點:OpenCV 是計算機視覺領域最廣泛使用的庫。
架構和技術細節:“OpenVINO”(開源的視覺推理和神經網絡優化工具包):這是被 Intel 內部廣泛使用的計算機視覺工具包,包括跨 CPU,GPU,FPGA,VPU,IPU 等傳統計算機視覺庫 OpenCV 和深度學習工具包。
允許在 Edge 設備上進行基于 CNN 的深度學習推理。
在 Intel CV 加速器上支持跨平臺的異構執行,使用支持 CPU ,Intel 集成顯卡,Intel Movidius? Neural Compute Stick 和 FPGA 的一個通用 API。
通過一個易于使用的 CV 函數庫和預優化的內核,加快產品上市速度。
優化 CV 標準的調用,包括OpenCV *,OpenCL?和OpenVX *。
應用場景:本教程涉及到 OpenCV,在未來的 CV 項目可能還會更多地考慮關于 OpenCV的內容。
其他觀點:這是一個用于高性能 CV 和 DL 推理的開發工具包,能夠解決 CV 和 DL 部署的相關問題。
參考鏈接:
https://software.intel.com/en-us/openvino-toolkit
https://opencv.org/CVPR-2018-tutorial.html
七、文本與計算機視覺
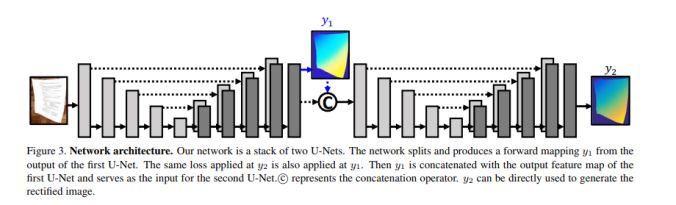
模塊主題一:DocUnet: Document Image Unwarping via A stacked U-Net (DocUnet:通過一個堆疊的 U-Net 展開文檔圖像)
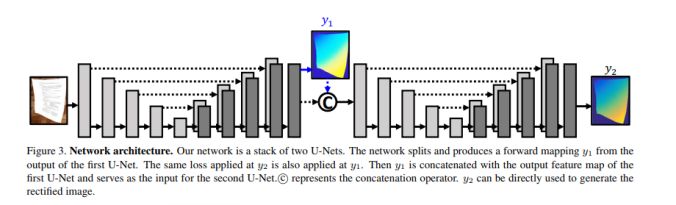
亮點:本研究實現了一個具有中間層監督機制的堆疊 U-Net,以從失真圖像直接預測其修正版本的前向映射圖。
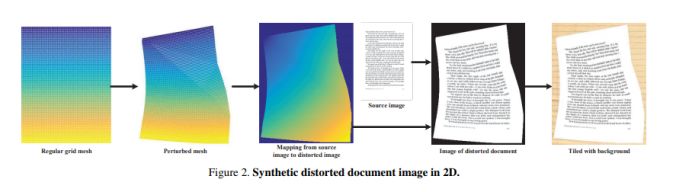
架構和技術細節:研究中提出的數據增強操作來提高模型的泛化能力:利用可描述的紋理數據集(DTD),產生各種背景紋理數據;在原始數據的 HSV 色彩空間中添加抖動處理以放大圖像亮度和紙張顏色變化;通過一個投射變換來解決視角變化問題。模型的結構示意圖如下圖所示:
數據集:合成數據集,如下圖所示:
應用場景:文本分析。
其他觀點:該研究中使用合成數據集來訓練模型,而在真實數據集上進行評估測試。

論文鏈接:
http://www.juew.org/publication/DocUNet.pdf
模塊主題二:Document enhancement using visibility detection (基于視覺檢測的文本增強研究)
亮點:本研究主要是基于計算機視覺檢測技術,來實現文本的增強,其實驗效果如下圖所示。


架構和技術細節:
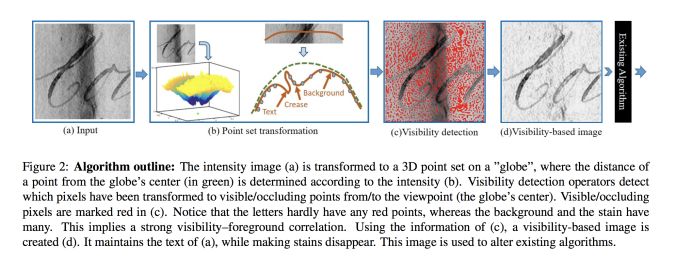
應用場景:文本圖像的二值化,文本去陰影等應用。
其他觀點:該研究可用于預處理文檔,然后將圖像傳遞給 OCR,實現在惡劣的光線條件下處理扭曲的文檔圖像。
論文鏈接:
http://webee.technion.ac.il/~ayellet/Ps/18-KKT.pdf
八、數據與計算機視覺
模塊主題一:Generate To Adapt: Aligning Domains using Generative Adversarial Network (生成自適應:利用生成對抗網絡實現域對齊)
亮點:本研究利用無監督數據,通過 GAN 拉近源分布和目標分布,使二者更接近聯合的特征空間。
架構和技術細節:模型的結構示意圖如下圖所示:
源域的更新:使用監督分類丟失來更新 F 和 CNNs;F 和 G.D 使用對抗性損失來更新,以產生類別一致的源圖像。
目標域更新:更新FNN,以便目標嵌入 (當通過 GAN 傳遞時) 產生類似的圖像源;這里的損失將源特征表征和目標特征表征對齊。
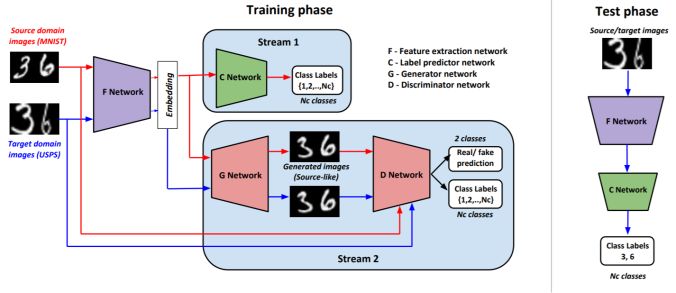
數據集:DIGITS 和 OFFICE 數據集。此外,從合成數據到真實數據的域自適應過程的數據集;從 CAD 數據集到 Pascal,VISDA 數據集。
應用場景:用于在未知數據上改善 CNN 的性能。
其他觀點:
與 Office 實驗相比,該研究中數字實驗的圖像生成質量更佳。
該研究中生成器能夠以類別一致的方式為源輸入和目標輸入生成類似的源圖像。
該研究中,Office 實驗會出現模式崩潰 (mode collaspe) 現象。
該研究的 Office 實驗表明,GAN 模型由合成圖像生成逼真圖像的困難使得以跨域圖像生成的方法作為數據增強操作也變得非常困難。值得注意的是,研究中提出的方法依賴于圖像生成,并將其作為特征提取網絡導出豐富梯度模式,因此即使存在嚴重的模式崩潰現象和較差的生成質量,該方法也能很好地工作。
論文和 github 鏈接:
https://arxiv.org/abs/1704.01705
https://github.com/yogeshbalaji/Generate_To_Adapt
模塊主題二:COCO-Stuff: Thing and Stuff Classes in Context (COCO-Stuff:上下文中的物體和填充物類別)
亮點:眾所周知的是,COCO 數據集缺少數據標注。本項研究通過密集的、逐像素填充注釋的方式來增強 COCO 數據集。
架構和技術細節:由于 COCO 數據是復雜的、含有大量物體的自然場景圖像,因此 COCO-Stuff 這項研究能夠探索不同物體之間的豐富關系,也能為完整的場景理解研究奠定基礎。
數據集:COCO 2017 數據集,其中包含 164K 張圖像,帶有91個類別的像素標注。COCO-Stuff 包含172個類別:其中有 80個類別與 COCO 數據集中的相同。另外的91個類別是由專家標注的。還有1個未標注的類別只在兩種情況下使用:如果標簽不屬于上述171個預定義類中的任何一個,或者標注工具無法推斷像素的標簽時才使用這個未標注類別。
應用場景:用于改善語義分割的性能。
論文鏈接:
http://openaccess.thecvf.com/content_cvpr_2018/papers/Caesar_COCO-Stuff_Thing_and_CVPR_2018_paper.pdf
模塊主題三:Workshop session: vision with sparse and scarce data (研討會專題:稀疏數據和少量數據情況下的視覺研究)
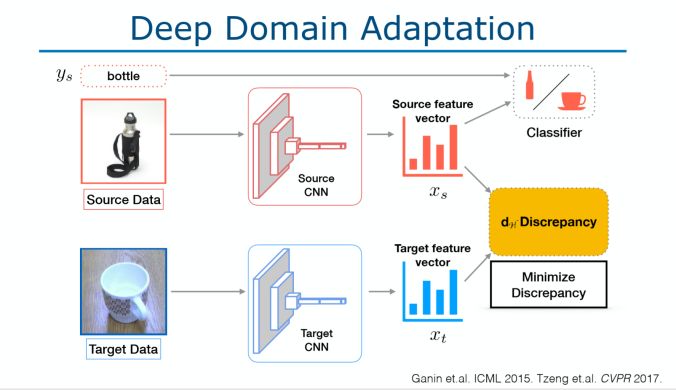
亮點:由Judy Hoffman 演講的關于 Make your data count 的報告。Imagenet 數據集有偏見的,因為它主要來自社交媒體的數據,例如人們喜歡將狗的正臉看作狗圖片等等。在現實生活中,如果我們的數據是低分辨率的,運動模糊的或姿勢變化的短視頻,那么模型將無法很好地運行。
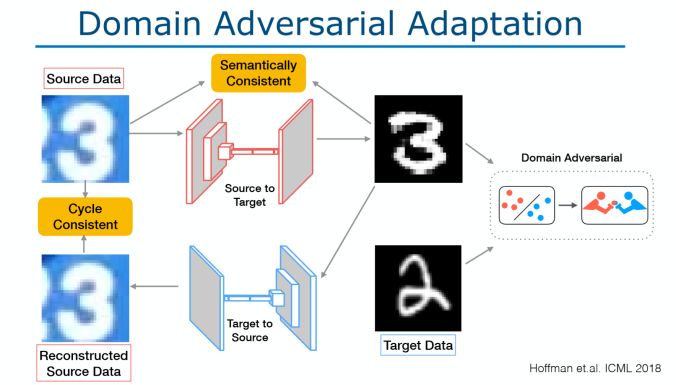
架構和技術細節:我們該如何改善模型的泛化能力呢?當視覺環境發生變化或出現偏差時,我們要讓模型學習無法區分域的表示,可以通過下面兩種方法實現:
深度域自適應:如下圖所示。
域對抗自適應:如下圖所示。
數據集:研究中采用 ImageNet 數據集和 SYNTHIA 數據集。
應用場景:
跨城市的自適應:以德國的數據進行訓練,但是以舊金山的數據進行測試 (標志,隧道,道路大小)。
跨季節的自適應:采用 SYNTHIA數據集。
跨季節的像素自適應,以秋天的數據生成冬天的數據
合成真實像素的自適應:以合成的 GTA 數據進行訓練,以德國的數據進行測試。
其他觀點:從 Judy hoffman的演講中可以發現:該研究涉及到 GANs 的知識,同時這也是計算機視覺中的常見問題。以往,我們通常都是使用轉移學習來處理這些問題,但是 Judy hoffman 這次的演講為我們提供了一些解決交叉自適應問題的新見解。
More and More
CVPR 2018 open access
http://openaccess.thecvf.com/CVPR2018.py
CVPR 2018 視頻
https://www.youtube.com/results?search_query=CVPR18
此文鏈接:
https://olgalitech.wordpress.com/2018/06/30/cvpr-2018-recap-notes-and-trends/
-
計算機視覺
+關注
關注
8文章
1700瀏覽量
46074 -
機器學習
+關注
關注
66文章
8438瀏覽量
132915 -
論文
+關注
關注
1文章
103瀏覽量
14972
原文標題:收藏指數爆表!CVPR 2018-2019幾十篇優質論文解讀大禮包! | 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從市場角度對機器人的基本解讀

一文理解多模態大語言模型——上

NVIDIA視覺生成式AI的最新進展
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
在多FPGA集群上實現高級并行編程
解讀MIPI A-PHY與車載Serdes芯片技術與測試
谷歌DeepMind被曝抄襲開源成果,論文還中了頂流會議

圓滿收官 | 2024慕尼黑上海電子展精彩回顧

OpenCV攜Orbbec 3D相機亮相CVPR 2024,加速AI視覺創新
【5月25日-上海】恩智浦新品MCX N系列線下培訓來啦!LVGL、AI等超多精彩Demo演示,快來報名吧!

恩智浦新品MCX N系列線下培訓來啦!LVGL、AI等超多精彩Demo演示,快來報名吧!


蘋果發布300億參數MM1多模態大模型
Nullmax提出多相機3D目標檢測新方法QAF2D





 工商網監
工商網監
評論