") 博士論文《面向自然語言處理的神經(jīng)網(wǎng)絡(luò)遷移學(xué)習(xí)》公開
博士論文《面向自然語言處理的神經(jīng)網(wǎng)絡(luò)遷移學(xué)習(xí)》公開
NLP領(lǐng)域知名博主Sebastian Ruder近日公開了他的博士論文,總共 329 頁,他認(rèn)為更明確的遷移學(xué)習(xí)是解決訓(xùn)練數(shù)據(jù)不足和提高自然語言處理模型下游性能的關(guān)鍵,并展示了支持該假設(shè)的相關(guān)領(lǐng)域、任務(wù)和語言遷移知識(shí)的實(shí)驗(yàn)結(jié)果。這篇論文是了解 NLP 遷移學(xué)習(xí)非常好的文獻(xiàn)。
Sebastian Ruder 是 NLP 領(lǐng)域知名博主(ruder.io),近期他從愛爾蘭國立大學(xué)博士畢業(yè)并加入了 DeepMind。
3 月 23 日,他的博士論文《面向自然語言處理的神經(jīng)網(wǎng)絡(luò)遷移學(xué)習(xí)》公開,總共 329 頁。
Sebastian Ruder
在論文中,他認(rèn)為更明確的遷移學(xué)習(xí)是解決訓(xùn)練數(shù)據(jù)不足和提高自然語言處理模型下游性能的關(guān)鍵,并展示了支持該假設(shè)的相關(guān)領(lǐng)域、任務(wù)和語言遷移知識(shí)的實(shí)驗(yàn)結(jié)果。這篇論文是了解 NLP 遷移學(xué)習(xí)非常好的文獻(xiàn)。
論文摘要
當(dāng)前,基于神經(jīng)網(wǎng)絡(luò)的自然語言處理模型擅長(zhǎng)從大量標(biāo)記數(shù)據(jù)中學(xué)習(xí)。鑒于這些功能,自然語言處理越來越多地應(yīng)用于新任務(wù)、新領(lǐng)域和新語言。然而,當(dāng)前的模型對(duì)噪聲和對(duì)抗性示例敏感,并且易于過度擬合。這種脆弱性,加上注意力的成本,對(duì)監(jiān)督學(xué)習(xí)范式提出了挑戰(zhàn)。
遷移學(xué)習(xí)使得我們能夠利用從相關(guān)數(shù)據(jù)中獲取的知識(shí),提高目標(biāo)任務(wù)的性能。以預(yù)訓(xùn)練詞表征形式進(jìn)行的隱式遷移學(xué)習(xí)一直是自然語言處理中的常見組成部分。
本文認(rèn)為,更明確的遷移學(xué)習(xí)是解決訓(xùn)練數(shù)據(jù)不足和提高自然語言處理模型下游性能的關(guān)鍵。我們展示了支持該假設(shè)的相關(guān)領(lǐng)域、任務(wù)和語言轉(zhuǎn)移知識(shí)的實(shí)驗(yàn)結(jié)果。
我們?yōu)樽匀徽Z言處理的遷移學(xué)習(xí)做出了一些貢獻(xiàn):
首先,我們提出了新的方法來自動(dòng)選擇監(jiān)督和無監(jiān)督的領(lǐng)域適應(yīng)的相關(guān)數(shù)據(jù)。
其次,我們提出了兩種新的架構(gòu),改善了多任務(wù)學(xué)習(xí)中的共享,并將單任務(wù)學(xué)習(xí)提升到最先進(jìn)的水平。
第三,我們分析了當(dāng)前模型對(duì)無監(jiān)督跨語言遷移的局限性,提出了一種改善方法,以及一種新的潛變量跨語言詞嵌入模型。
最后,我們提出了一個(gè)基于微調(diào)語言模型的序列遷移學(xué)習(xí)框架,并分析了適應(yīng)階段。
論文簡(jiǎn)介
1.1 動(dòng)機(jī)
語言通常被認(rèn)為是人類智力的標(biāo)志。開發(fā)能夠理解人類語言的系統(tǒng)是人工智能的主要障礙之一,該目標(biāo)推動(dòng)了人工智能,特別是自然語言處理和計(jì)算語言學(xué)研究。隨著語言滲透到人類生存的每個(gè)方面,最終,自然語言處理是計(jì)算機(jī)在增強(qiáng)人類智能方面發(fā)揮其全部潛力所必需的技能。
早期針對(duì)這一難以捉摸的目標(biāo)的象征性方法是試圖利用人類編寫的規(guī)則來捕捉文本的含義。然而,這種基于規(guī)則的系統(tǒng)很脆弱,并且僅限于它們?yōu)?[Winograd,1972] 設(shè)計(jì)的特定領(lǐng)域。它們通常無法處理意外或看不見的輸入,最終被證明限制性太強(qiáng),無法捕捉到自然語言的復(fù)雜性 [國家研究委員會(huì)和自動(dòng)語言處理咨詢委員會(huì),1966 年]。
在過去 20 年中,自然語言處理的統(tǒng)計(jì)方法 [Manning 等人,1999 年] 已經(jīng)變得司空見慣,它使用數(shù)學(xué)模型自動(dòng)從數(shù)據(jù)中學(xué)習(xí)規(guī)則。因此,我們應(yīng)該將人力投入到創(chuàng)建新的特征中去,用于指示模型在預(yù)測(cè)時(shí)應(yīng)該考慮的數(shù)據(jù)中的連接和關(guān)系,而不是去編寫規(guī)則。然而,特征工程非常耗時(shí),因?yàn)檫@些特征通常是針對(duì)特定任務(wù)的,而且需要相關(guān)領(lǐng)域的專業(yè)知識(shí)。
在過去五年中,深度神經(jīng)網(wǎng)絡(luò) [Krizhevsky 等人,2012 a, Goodfellow 等人,2016] 作為機(jī)器學(xué)習(xí)模型的一個(gè)特殊類別,已經(jīng)成為從數(shù)據(jù)中學(xué)習(xí)的首選模型。這些模型通過對(duì)一個(gè)多層次特征結(jié)構(gòu)的學(xué)習(xí),減少了對(duì)特征工程的需求。因此,人力投入的重點(diǎn)集中于為每項(xiàng)任務(wù)確定最合適的架構(gòu)和訓(xùn)練設(shè)置。
在自然語言處理以及機(jī)器學(xué)習(xí)的許多領(lǐng)域,訓(xùn)練模型的標(biāo)準(zhǔn)方法是對(duì)大量的示例進(jìn)行注釋,然后提供給模型,讓其學(xué)習(xí)從輸入映射到輸出的函數(shù)。這被稱為監(jiān)督學(xué)習(xí)。對(duì)于每項(xiàng)任務(wù),如分析文本的句法結(jié)構(gòu)、消除單詞歧義或翻譯文檔,都是從零開始訓(xùn)練新模型。來自相關(guān)任務(wù)或領(lǐng)域的知識(shí)永遠(yuǎn)不會(huì)被組合在一起,模型總是從隨機(jī)初始化開始 tabula rasa。
這種從空白狀態(tài)中去學(xué)習(xí)的方式與人類習(xí)得語言的方式截然不同。人類的語言學(xué)習(xí)并非孤立進(jìn)行,而是發(fā)生在豐富的感官環(huán)境中。兒童通過與周圍環(huán)境的互動(dòng) [Hayes 等人,2002 年],通過持續(xù)的反饋和強(qiáng)化 [Bruner, 1985 年] 來學(xué)習(xí)語言。
然而,最近基于深度神經(jīng)網(wǎng)絡(luò)的方法通過對(duì)從幾十萬到數(shù)百萬對(duì)輸入 - 輸出組合 (如機(jī)器翻譯) 的學(xué)習(xí),在廣泛的任務(wù)上取得了顯著的成功 [Wu 等人,2016 年]。鑒于這些成功,人們可能會(huì)認(rèn)為沒有必要偏離監(jiān)督學(xué)習(xí)的范式,因此沒有必要?jiǎng)?chuàng)建受人類語言習(xí)得啟發(fā)的算法。畢竟,大自然為我們提供的是靈感而非藍(lán)圖;例如,人工神經(jīng)網(wǎng)絡(luò)只是受到人類認(rèn)知的松散啟發(fā) [Rumelhart 等人,1986 年]。
最近的研究 [Jia 和 Liang, 2017 年,Belinkov 和 Bisk, 2018 年] 表明,當(dāng)前算法的脆弱程度與早期基于規(guī)則的系統(tǒng)類似:它們無法概括出其在訓(xùn)練期間看到的數(shù)據(jù)以外的東西。這些算法遵循它們訓(xùn)練的數(shù)據(jù)的特征,并且在條件發(fā)生變化時(shí)無法適應(yīng)。
人類的需求是復(fù)雜的,語言是多種多樣的;因此,不斷有新的任務(wù) - 從識(shí)別法律文件中的新先例,到挖掘看不見的藥物間的相互作用,再到路由支持電子郵件等等,這些都需要使用自然語言處理來解決。
自然語言處理還有望幫助彌合造成網(wǎng)路信息和機(jī)會(huì)不平等的數(shù)字語言鴻溝。為實(shí)現(xiàn)這一目標(biāo),這些模型除英語之外,還需要適用于世界 6, 000 種語言。
為了獲得一個(gè)在以前從未見過的數(shù)據(jù)上表現(xiàn)良好的模型(無論是來自新的任務(wù),領(lǐng)域還是語言 ),監(jiān)督學(xué)習(xí)需要為每個(gè)新的設(shè)置標(biāo)記足夠的示例。
鑒于現(xiàn)實(shí)世界中的語言、任務(wù)和域名過多,為每個(gè)設(shè)置手動(dòng)注釋示例是完全不可行的。因此,標(biāo)準(zhǔn)監(jiān)督學(xué)習(xí)可能會(huì)由于這些現(xiàn)實(shí)挑戰(zhàn)的存在而遭遇失敗。
通過將知識(shí)從相關(guān)領(lǐng)域、任務(wù)和語言轉(zhuǎn)移到目標(biāo)設(shè)置,遷移學(xué)習(xí)將有望扭轉(zhuǎn)這種失敗。
事實(shí)上,遷移學(xué)習(xí)長(zhǎng)期以來一直是許多 NLP 系統(tǒng)的潛在組成部分。NLP 中許多最基本的進(jìn)步,如潛在語義分析 [Deerwester 等人,1990 年]、布朗聚類[Brown 等人,1993b] 和預(yù)訓(xùn)練的單詞嵌入 [Mikolov 等人,2013a] 均可被視為遷移學(xué)習(xí)的特殊形式,作為將知識(shí)從通用源任務(wù)轉(zhuǎn)移到更專業(yè)的目標(biāo)任務(wù)的手段。
在本文中,我們認(rèn)為將 NLP 模型的訓(xùn)練定義為遷移學(xué)習(xí)而非監(jiān)督學(xué)習(xí),有助于釋放新的潛力,使我們的模型能夠得到更好的推廣。我們證明我們的模型優(yōu)于現(xiàn)有的遷移學(xué)習(xí)方法以及不遷移的模型。
為此,我們開發(fā)了針對(duì)各種場(chǎng)景跨域、任務(wù)和語言進(jìn)行轉(zhuǎn)換的新模型,并且證明了我們的模型在性能上比現(xiàn)有的遷移學(xué)習(xí)方法和非遷移的模型都要優(yōu)越。
1.2 研究目標(biāo)
本文研究了使用基于神經(jīng)網(wǎng)絡(luò)的自然語言處理方法在多個(gè)任務(wù)、領(lǐng)域和語言之間進(jìn)行遷移的自動(dòng)表征學(xué)習(xí)問題。
本文的主要假設(shè)如下:
自然語言處理中的深層神經(jīng)網(wǎng)絡(luò)會(huì)利用來自相關(guān)域、任務(wù)和語言的現(xiàn)有相關(guān)信息,其性能優(yōu)于在各種任務(wù)中不使用此信息的模型。
換句話說,我們認(rèn)為在大多數(shù)情況下,遷移學(xué)習(xí)優(yōu)于監(jiān)督學(xué)習(xí),但有兩點(diǎn)需要注意:
1.當(dāng)已經(jīng)有足夠數(shù)量的訓(xùn)練實(shí)例時(shí),遷移學(xué)習(xí)可能沒有那么大的幫助;
2.如果沒有相關(guān)信息,遷移學(xué)習(xí)可能就不那么有用了。
為了解決第一個(gè)方面,我們分析了遷移學(xué)習(xí)的幾個(gè)功能。第二點(diǎn)暗示了本論文中反復(fù)出現(xiàn)的主題:遷移學(xué)習(xí)的成功取決于源的設(shè)置與目標(biāo)設(shè)置的相似性。
總而言之,我們列出了五個(gè)需求,這些需求將通過本文提出的方法來解決:
1.克服源設(shè)置和目標(biāo)設(shè)置之間的差異:該方法應(yīng)克服源設(shè)置和目標(biāo)設(shè)置之間的差異。許多現(xiàn)有方法只有在源和目標(biāo)設(shè)置相似時(shí)才能很好地工作。為了克服這一挑戰(zhàn),我們提出了方法用于:選擇相關(guān)示例、利用弱監(jiān)督、靈活地跨任務(wù)共享參數(shù)、學(xué)習(xí)通用表示和分析任務(wù)相似性。
2.誘導(dǎo)歸納偏差:該模型應(yīng)該誘導(dǎo)歸納偏差,從而提高其推廣能力。我們采用的歸納偏差包括半監(jiān)督學(xué)習(xí)、對(duì)正交約束的多任務(wù)學(xué)習(xí)、弱監(jiān)督、匹配的先驗(yàn)關(guān)系、層次關(guān)系和預(yù)先訓(xùn)練過的表示。
3. 將傳統(tǒng)方法和當(dāng)前方法相結(jié)合:該模型應(yīng)該從經(jīng)典工作中汲取靈感,以便克服最先進(jìn)方法中的局限性。我們提出了兩種模型,明確地結(jié)合了兩方面的優(yōu)點(diǎn),即傳統(tǒng)方法優(yōu)勢(shì)和神經(jīng)網(wǎng)絡(luò)方法的優(yōu)勢(shì)。
4.在 NLP 任務(wù)的層次結(jié)構(gòu)中進(jìn)行遷移:該方法應(yīng)該在 NLP 任務(wù)的層次結(jié)構(gòu)中遷移知識(shí)。這包括在低級(jí)別和高級(jí)別任務(wù)之間進(jìn)行共享,在粗粒度和細(xì)粒度的情感任務(wù)之間進(jìn)行共享,以及從通用任務(wù)遷移到各種各樣的任務(wù)中。
5.推廣到多個(gè)設(shè)置:該方法應(yīng)該能夠推廣到許多不同的設(shè)置之上。為了測(cè)試這一點(diǎn),我們?cè)诙喾N任務(wù)、領(lǐng)域和語言中評(píng)估相關(guān)方法。
1.3 貢獻(xiàn)
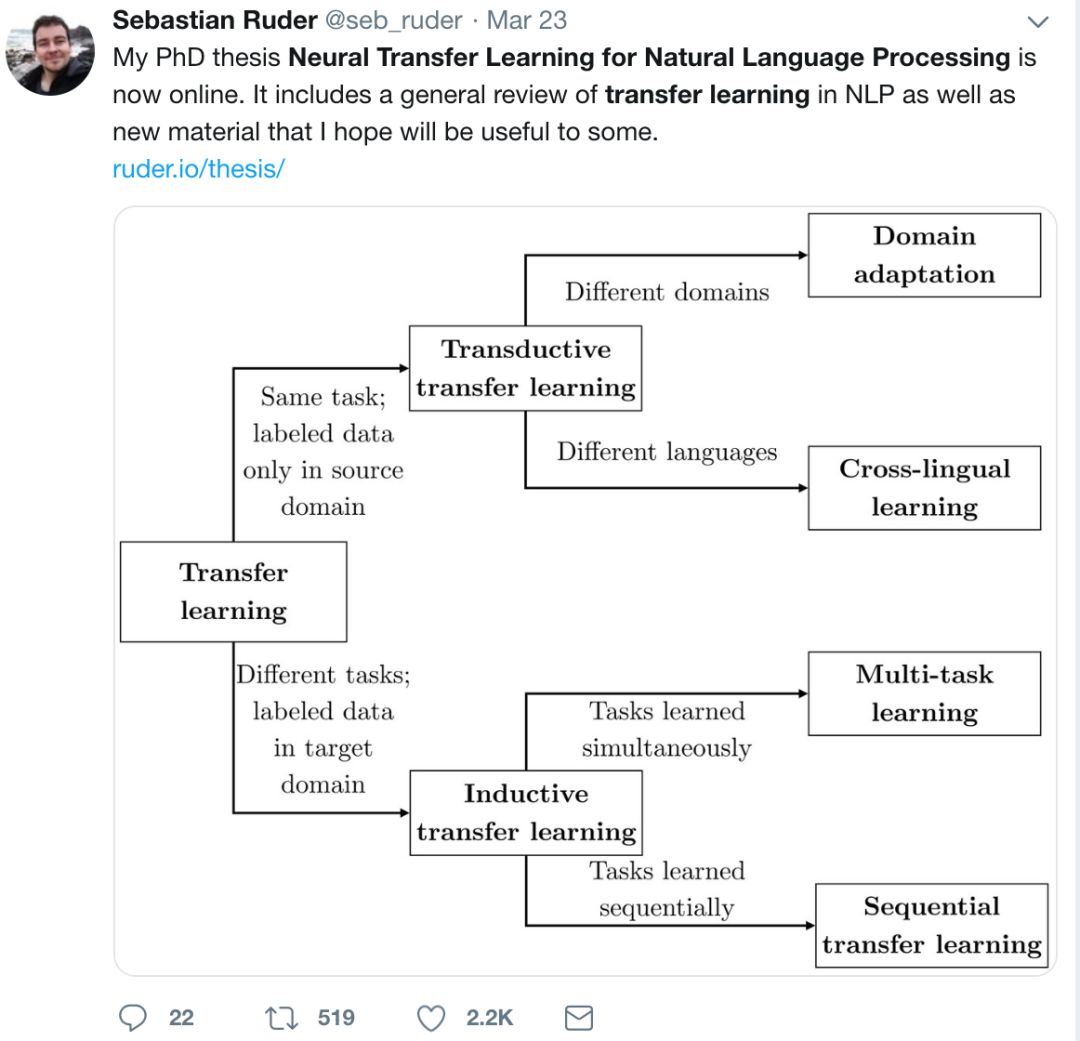
在本文中,我們將重點(diǎn)討論 NLP 遷移學(xué)習(xí)的三個(gè)主要方面:跨領(lǐng)域遷移、跨任務(wù)遷移和跨語言遷移。
根據(jù)源和目標(biāo)任務(wù)的性質(zhì)、領(lǐng)域和學(xué)習(xí)順序的不同,這三個(gè)維度可以自然地分為四個(gè)不同的遷移學(xué)習(xí)設(shè)置:領(lǐng)域適應(yīng)、跨語言學(xué)習(xí)、多任務(wù)學(xué)習(xí)和序列遷移學(xué)習(xí)。我們?cè)诒?1.1 中展示了本文的貢獻(xiàn)是如何與這四種設(shè)置相關(guān)聯(lián)的。
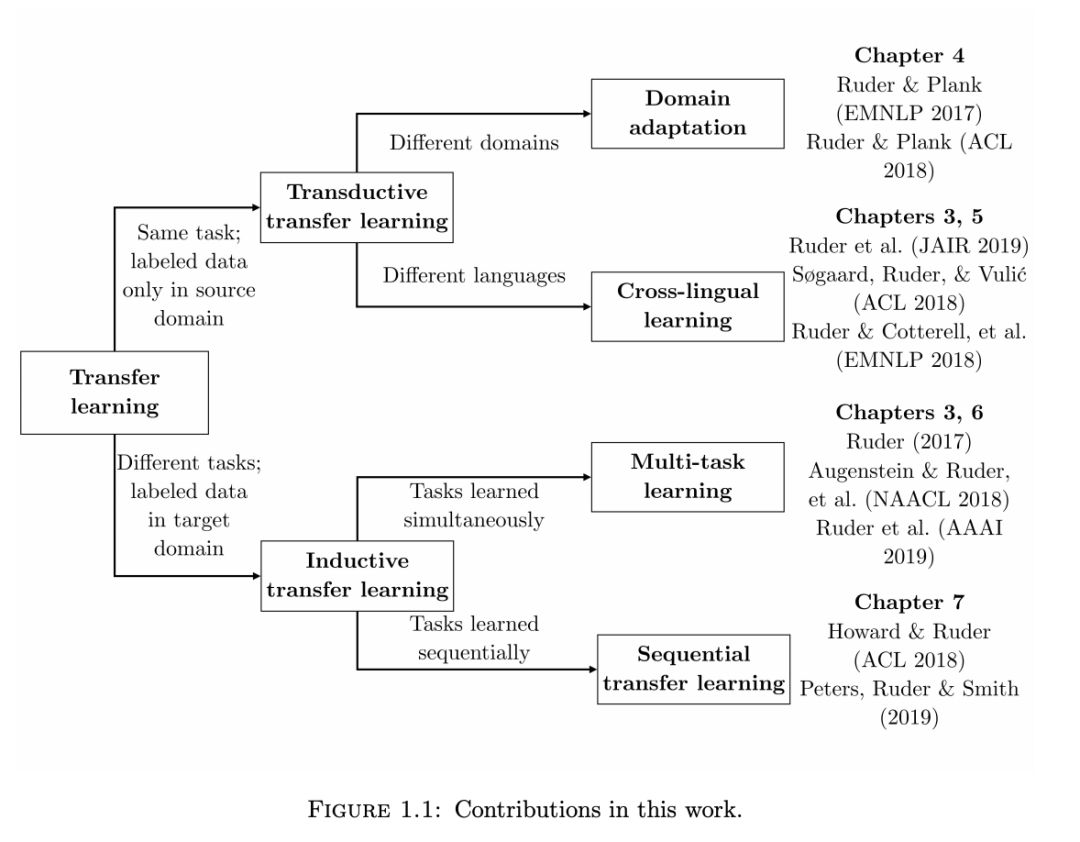
本論文的貢獻(xiàn)可以分為理論、實(shí)踐和實(shí)證三個(gè)方面。
在理論貢獻(xiàn)方面:
我們提供了反映自然語言處理中最常見的遷移學(xué)習(xí)設(shè)置的分類方法;
我們展示了學(xué)習(xí)在單詞級(jí)別上優(yōu)化類似目標(biāo)的跨語言詞嵌入模型;
我們分析了無監(jiān)督跨語言嵌入模型的理論局限性;
我們展示了如何將現(xiàn)有的跨語言嵌入方法視為一個(gè)潛變量模型;
我們提出了一個(gè)理論框架,將現(xiàn)有架構(gòu)推廣到多任務(wù)學(xué)習(xí)。
在實(shí)踐貢獻(xiàn)方面:
我們對(duì)自然語言處理中最常見的四種遷移學(xué)習(xí)設(shè)置進(jìn)行了廣泛的回顧:多任務(wù)學(xué)習(xí)、序列遷移學(xué)習(xí)、領(lǐng)域適應(yīng)和跨語言學(xué)習(xí);
我們提出了一種新的基于特征向量的度量方法,以衡量?jī)煞N語言之間無監(jiān)督雙語詞典歸納的可能性;
我們提供了適應(yīng)預(yù)訓(xùn)練表征的指南;
我們開源了我們的代碼。
我們最終做出以下實(shí)證貢獻(xiàn):
我們提出了一個(gè)模型,它自動(dòng)學(xué)習(xí)如何選擇與特定目標(biāo)領(lǐng)域相關(guān)的訓(xùn)練實(shí)例;
我們將半監(jiān)督學(xué)習(xí)方法與神經(jīng)網(wǎng)絡(luò)相結(jié)合,并將其與最先進(jìn)的方法進(jìn)行比較;
我們提出了一種受 tri-training 啟發(fā)的更有效的半監(jiān)督學(xué)習(xí)方法;
我們實(shí)證分析了無監(jiān)督跨語言詞嵌入模型的局限性;
我們提出了一個(gè)新的雙語詞典歸納的潛變量模型;
我們提出了一個(gè)新的多任務(wù)學(xué)習(xí)模型,可以自動(dòng)學(xué)習(xí)在不同任務(wù)之間共享哪些層;
我們提出了一個(gè)新的多任務(wù)學(xué)習(xí)模型,它集成了來自不同標(biāo)簽空間的信息;
我們提出了一個(gè)新的順序遷移學(xué)習(xí)框架,它采用預(yù)先訓(xùn)練的語言模型和新的微調(diào)技術(shù);
我們將兩種流行的適應(yīng)方法與各種任務(wù)中最先進(jìn)的預(yù)先訓(xùn)練表示進(jìn)行比較。
1.4 論文大綱
在第 2 章中,概述了與理解本文內(nèi)容有關(guān)的背景資料們,回顧了概率和信息論以及機(jī)器學(xué)習(xí)的基礎(chǔ)知識(shí),并進(jìn)一步討論了自然語言處理中基于神經(jīng)網(wǎng)絡(luò)的方法和任務(wù)。
在第 3 章中,定義了遷移學(xué)習(xí),并提出了一個(gè) NLP 遷移學(xué)習(xí)的分類方法。然后,詳細(xì)回顧了四種遷移學(xué)習(xí)場(chǎng)景:領(lǐng)域適應(yīng)、跨語言學(xué)習(xí)、多任務(wù)學(xué)習(xí)和序列遷移學(xué)習(xí)。
以下各章重點(diǎn)介紹了這些方案中的每一個(gè)方案。在每一章中,介紹相應(yīng)設(shè)置的新方法,這些方法的性能都優(yōu)于基準(zhǔn)數(shù)據(jù)集上目前最先進(jìn)的設(shè)置方法。
第 4 章介紹了在領(lǐng)域適應(yīng)數(shù)據(jù)選擇方面的工作。對(duì)于受監(jiān)督的領(lǐng)域適應(yīng),提出了一種使用貝葉斯優(yōu)化來學(xué)習(xí)從多個(gè)域中選擇相關(guān)訓(xùn)練實(shí)例的策略方法。對(duì)于無監(jiān)督領(lǐng)域適應(yīng),將經(jīng)典的半監(jiān)督學(xué)習(xí)方法應(yīng)用于神經(jīng)網(wǎng)絡(luò),并提出了一種 tri-training 啟發(fā)的新方法。這兩種方法都旨在根據(jù)半監(jiān)督學(xué)習(xí)模型選擇與目標(biāo)領(lǐng)域相似或可靠且信息豐富的相關(guān)實(shí)例。
在第 5 章中,首先分析了無監(jiān)督跨語言單詞嵌入模型的局限性。研究發(fā)現(xiàn),現(xiàn)有的無監(jiān)督方法在語言不同的環(huán)境中不再有效,并提供了一種弱監(jiān)督的方法來改善這種情況。進(jìn)一步提出了一種具有正則匹配的潛變量模型,該模型適用于低資源語言。此外,在潛變量的幫助下,為現(xiàn)有的跨語言單詞嵌入模型提供了一個(gè)新的視角。
在第 6 章中,提出了兩種新穎的體系結(jié)構(gòu),可以改善多任務(wù)學(xué)習(xí)中任務(wù)之間的共享。在多任務(wù)學(xué)習(xí)中,當(dāng)任務(wù)不一致時(shí),目前諸如硬參數(shù)共享等方法將會(huì)失效。
第一種方法通過允許模型了解應(yīng)該共享任務(wù)之間的信息程度來克服這一點(diǎn)。
第二種方法包含來自其他任務(wù)的標(biāo)簽空間的信息。
在第 6 章中,提出了兩種新的架構(gòu),以改善多任務(wù)學(xué)習(xí)中任務(wù)之間的共享。在多任務(wù)學(xué)習(xí)中,當(dāng)任務(wù)不相似時(shí),目前諸如硬參數(shù)共享等方法將會(huì)失效。第一種方法是通過允許模型學(xué)習(xí)任務(wù)之間的信息應(yīng)該在多大程度上共享來克服這一點(diǎn)。第二種方法則集成了來自其它任務(wù)的標(biāo)簽空間信息。
在第 7 章中,重點(diǎn)介紹了序列遷移學(xué)習(xí)中先前被忽略的適應(yīng)階段。首先提出了一個(gè)基于語言建模和新的適應(yīng)技術(shù)的新框架。其次,用最先進(jìn)的預(yù)訓(xùn)練表示來分析適應(yīng)性。發(fā)現(xiàn)任務(wù)相似度發(fā)揮著重要作用,并為從業(yè)者提供指導(dǎo)。
第 8 章最后總結(jié)包含了結(jié)論、發(fā)現(xiàn),并提供了對(duì)未來的展望。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4778瀏覽量
101014 -
自然語言處理
+關(guān)注
關(guān)注
1文章
619瀏覽量
13611 -
遷移學(xué)習(xí)
+關(guān)注
關(guān)注
0文章
74瀏覽量
5574
原文標(biāo)題:DeepMind網(wǎng)紅博士300頁論文出爐:面向NLP的神經(jīng)遷移學(xué)習(xí)(附下載)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論