 揭秘FACEBOOK未來的機器學習平臺
揭秘FACEBOOK未來的機器學習平臺
粗看上去,世界上的超大規模用戶和云構建商制造的東西通常看上去和感覺上去都像超級計算機,但如果你仔細觀察,就常會看到一些相當大的差異。差異之一是,他們的機器并不是為了實現最高性能而不惜一切代價去設計,而是在性能和成本之間實現了最佳平衡。
簡而言之,這就是為什么社交網絡巨頭Facebook(世界上最大的人工智能用戶之一)大量訂購英偉達的HGX-1和HGX-2系統用于機器學習訓練,然后就到此為止了。(HGX-1和HGX-2系統是GPU加速器制造商英偉達的DGX系列的超大規模用戶版本。)
這并不是巧合,為什么微軟、谷歌、亞馬遜網絡服務、阿里巴巴、騰訊、百度,以及中國第四大巨頭(中國移動或京東)同樣設計自己的服務器,或是使用Facebook在2011年創建的開放計算項目(OCP)中的設計,或是在OCP啟動六個月后由阿里巴巴、百度和騰訊發起了天蝎計劃項目。在某些情況下,他們甚至設計自己的ASIC或在FPGA上運行專門用于機器學習的算法。
公平地說,Facebook確實在2017年6月安裝了英偉達DGX-1 CPU-GPU混合系統的半定制實現,該系統有124個節點,峰值雙精度性能為4.9 petaflops,在HPC常用的Linpack并行Fortran基準測試中的評價為3.31petaflops。但這是個例外,不是常規。
但是,Facebook喜歡設計自己的硬件,然后將其開源,試圖圍繞這些設計構建一個生態系統,以降低工程和制造成本,并降低供應鏈風險,因為越來越多的公司進入了開放計算領域。這與微軟幾年前加入OCP并將一系列完全不同的開源基礎設施設計(從服務器到存儲到交換)拋入OCP生態系統的原因相同。這增加了創新,但也導致了供應鏈分叉。
在本周于圣何塞舉行的OCP全球峰會上,Facebook展示了針對機器學習訓練和基礎設施的未來系統設計,讓世界有機會看到針對現代數據中心的這兩個日益重要的工作負載的成本優化設備的至少一個潛在的未來。這些設計非常有趣,表明Facebook熱衷于創建能夠容納盡可能多的供應商的不同類型計算的系統,再次降低成本和供應鏈風險。
不是基本訓練
第一臺新機器代號為“Zion”,它的目標是Facebook上的機器學習訓練工作負載。Zion系統由兩個不同的子系統組成,就像英偉達的DGX-1和微軟的HGX-1,也包括DGX-2和HGX-2,以及ODM和OEM廠商為客戶制造的各種等價產品。 Zion系統是兩年前Facebook在OCP峰會上與微軟的HGX-1一起發布的“Big Basin”ceepie-geepie系統的繼承者,這兩個系統的設計都為OCP做出了貢獻。Big Basin機器的主機支持多達8個英偉達的“Pascal”GP100或“Volta”GV100 GPU加速器,以及兩個英特爾Xeon CPU。巧妙之處在于CPU計算和GPU計算是分開的,分別位于不同的主板和不同的機箱中,因此它們可以單獨升級。具體取決于品牌和型號。
Big Basin是對其前身“Big Sur”的徹底改進,后者是一款密度較低的設計,基于單個主板,配備兩個Xeon CPU和多達8個PCI-Express Nvidia Tesla加速器(M40或K80是最受歡迎的)。Big Sur于2015年12月曝光。Facebook在談到設計時表示,開發工作已經基本完成,還沒有投入生產,這意味著Zion機器還沒有投入生產,但很快就會問世。(我們在2018年1月討論了Facebook不斷演變的AI工作負載,以及運行這些工作負載的機器。)Zion機器的變化顯示了Facebook在混合CPU-GPU機器上的想法的變遷,這些想法是我們許多人都想不到的。
Zion機器的兩個子系統被稱為“Emerald Pools”和“Angels Landing”,分別指的是GPU和CPU子系統。盡管facebook多年來一直表示,其服務器設計的目的是允許選擇處理器或加速器,但在這個例子中,facebook和微軟合作提出了一種獨特的封裝和主板插接方法,稱為OCP加速器模塊(簡稱OAM),該方法允許使用具有不同插座和熱量的加速器,可以選擇250瓦至350瓦不等的風冷,未來則可以選擇高達700瓦的水冷,但就硬件形式而言,所有這些都一致部署在這些加速系統中。
超大規模用戶谷歌、阿里巴巴和騰訊將與Facebook和微軟一起推廣OAM封裝,芯片制造商AMD、英特爾、Xilinx、Habana、高通和Graphcore也是如此。系統制造商IBM、聯想、浪潮、廣達電腦、企鵝計算、華為技術、WiWynn、Molex和BittWare也都支持OAM。毫無疑問,其它公司也將效仿它們的芯片和系統——惠普和戴爾顯然是缺席的OEM,而富士康和Inventec則是缺席的主要ODM。
通過OAM,加速器被插入一個便攜式插座,它的管腳在一側,然后是一組標準的并行管腳,它在概念上類似于英偉達的SXM2插座,用于Pascal和Volta GPU上的NVLink,從模塊上取下并插入主板上匹配的端口中。下圖說明了它的原理:
任何插入Emerald Pools機箱的特定加速器都會有散熱器,散熱器具有不同數量的鰭片和不同的材料,可用于冷卻其下方的設備,但高度一致,因此無論哪種加速器插入插槽,散熱器都能以一致的方式保持整個機箱中的氣流不變。雖然Facebook沒有這么說,但沒有理由不能將多個不兼容的加速器插入Emerald Pools機箱,并使用該機箱中實現的PCI-Express交換結構相互連接并與主機CPU連接。下圖是OAM的外觀:
它看起來很像小型汽車電池,不是嗎?
每個OAM的尺寸為102毫米×165毫米,足夠容納我們認為未來將會越來越大的多芯片模塊。對于耗電量高達350瓦的設備,OAM可支持12伏特的輸入;對于需要驅動高達700瓦的設備,OAM可支持48伏特的輸入;風冷的散熱能力預計將在450瓦左右。當前的OAM規范允許在加速器和主機之間提供一個或兩個PCI-Express 3.0 x16插槽,而且很顯然,更快的PCI-Express 4.0和5.0插槽已在規劃圖中。這樣就剩下6到7個PCI-Express鏈路用于交叉耦合加速器。順便說一句,這些鏈路可以分成兩部分,以提供更多的互連鏈路,并可以增加或減少任意給定鏈路的通道數量。
下圖是Emerald Pools機箱,里面插了8個加速器中的7個。
Emerald Pools底座后面有四個PCI-Express交換機,位于圖片的右側,每個交換機都插入對應的Angels Landing CPU機箱(即Zion系統的另一半)上的配套PCI-Express交換機。該系統的CPU部分沒有在Facebook展位上展出,但Facebook技術項目經理、設計其AI系統的工程師之一Sam Naghshineh在一次演講中展示了這臺機器:
你可以看到,4個PCI-Express 3.0管線從加速器底座和CPU底座上出來,將它們連接在一起。關于Angels Landing有趣的一點不是它總共有4個服務器底座,每個都有一對Xeon SP處理器,這是超大規模數據中心的常規設計。巧妙之處在于,由于在系統的CPU端進行機器學習訓練期間,對數據密集處理的需求不斷增加,于是它使用處理器上的UltraPath Interconnect(UPI)鏈接將這4個雙插槽機器捆綁在一起,以創建一個8插槽共享內存節點。按照Naghshineh的說法,從技術上講,這稱為扭曲超立方體拓撲:
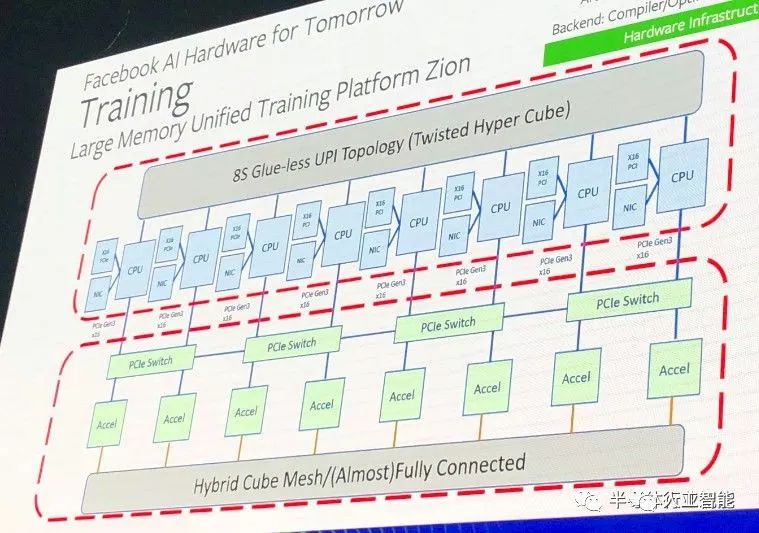
這個大CPU節點設計為擁有2 TB的DRAM主內存,而無需使用大內存條或Optan3D XPoint主內存,而且重要的是,該節點可在系統的CPU端提供足夠的內存帶寬,從而無需使用HBM內存。(這并不是說英特爾或AMD CPU還擁有HBM內存,但某些場合它們確實擁有HBM內存,尤其是對于HPC和AI工作負載而言。)這8個插槽的DRAM內存帶寬和容量一樣重要。
如你所見,Angels Landing CPU機箱中的每個CPU都有自己的網絡接口卡以及PCI-Express 3.0 x16插槽,用于將CPU連接到PCI-Express交換機結構,該交換機結構將加速器計算復合體連接在一起,并連接到CPU。這些加速器鏈接在上圖中幾乎完全連接的混合立方體網格中,但還可以支持其他拓撲,如下所示:
左圖中,每個加速器有6個端口,8個加速器連接在一個混合立方體網格中。右圖中,仍然有8個設備,但是每個設備都有一個額外的端口(總共7個),這些設備可以按照all-to-all的互連方式進行鏈接。顯然還有其他選擇,重點是不同的神經網絡在不同的互連拓撲結構中效果更好,這將允許Facebook和其他公司改變互連的拓撲結構,以滿足神經網絡的需求。
推理的未來
Facebook毫不掩飾地表示,它希望擁有比目前市場上更高效的推理機,這是Facebook去年在一篇論文中討論的一個話題。在本周的OCP全球峰會上,Facebook公司高層概述了機器學習推理硬件的未來。
Facebook技術和戰略主管Vijay Rao提醒大家,早在1980年,英特爾就為8086系列處理器設計了8087數學協處理器,這些處理器如今是客戶端的核心芯片和服務器上的Xeon芯片的前身。這些機器可以在2.4瓦的熱度范圍內實現50 kiloflops(32位單精度),達到相當驚人的每瓦20.8 kiloflops。Facebook的目標是使用像INT8這樣的低精度數學運算,來達到接近每瓦5 teraflops,如果你看看英偉達的GV100,它可以達到每瓦特0.4 teraflops。
Rao在他的主題演講中解釋說:“我們一直在與許多合作伙伴密切合作,設計用于推理的ASIC。與傳統CPU相比,在加速器中運行推理的吞吐量增加是值得的。在我們的情況下,應該是每瓦特10倍左右。”
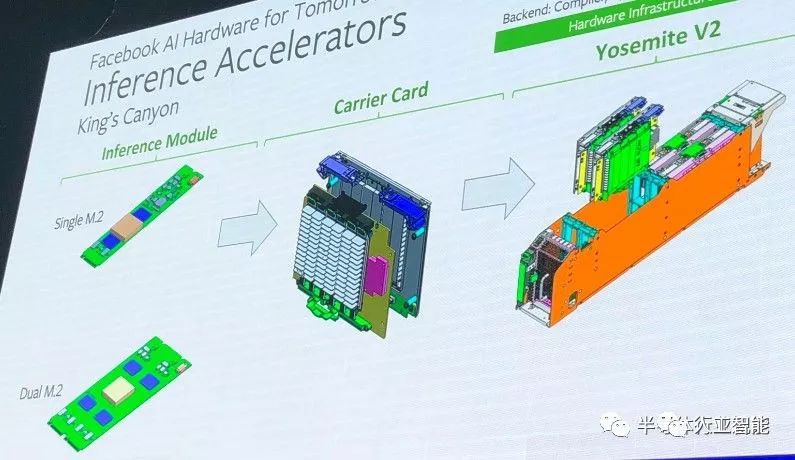
Rao大致談到了將M.2推理引擎組合到微服務器卡上,然后將它們插入到2015年創建的“Yosemite”服務器機箱中,Facebook設計該機箱是為了完成基本的基礎設施工作。但當天晚些時候,Naghshineh實際展示了它的實現方法。以下是M.2推理引擎的“Kings Canyon”系列:
Facebook正試圖鼓勵推理芯片制造商支持兩種不同的形式。一個是單個的寬M.2單元,最大支持12瓦,并帶有一個PCI-Express x4接口,另一個具有兩倍大的內存、20瓦的熱度范圍,一對PCI-Express x4端口,可以單獨使用或捆綁使用。這些M.2推理卡中的多個被插入“Glacier Point”載卡中,該載卡插入真正的PCI-Express x16插槽,最多可以有4個載卡被插入Yosemite機箱,如下所示:
群集推理引擎的框圖如下所示:
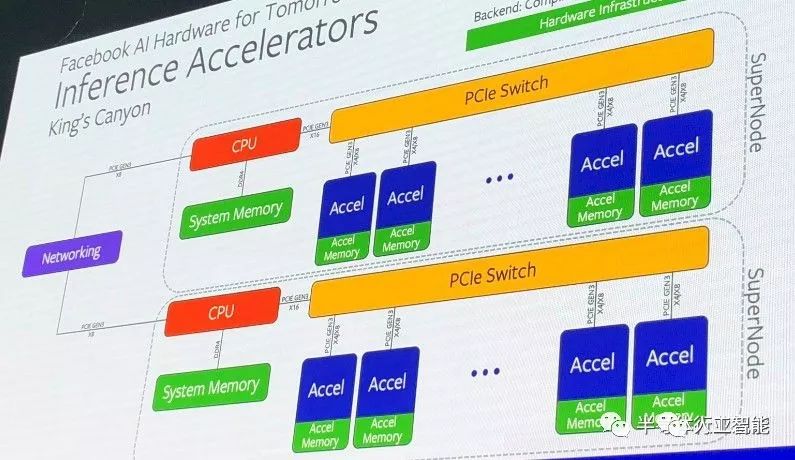
這樣做的唯一原因與使用低核心計數、高頻率、單插槽的微型服務器來運行電子設計自動化(EDA)工作負載相同,英特爾就是這樣做的,盡管它想要向世界銷售雙插槽服務器。推理工作負載類似于Web服務和EDA驗證:你可以將整個較小規模的工作分派到大量松散耦合(幾乎沒有耦合,完全不是真正耦合)計算單元中的一個,然后一次執行大量的這些任務,并同時完成大量工作。對一位數據的推斷決不依賴于對無數其他工作的推斷。機器學習訓練則不同,它更像傳統的HPC仿真和建模,在不同的程度和頻率下,對一個計算元素進行的任何處理都依賴于其他計算元素的結果。
因此,我們所看到的用于機器學習訓練和推理的截然不同的硬件設計都來自Facebook。我們可以肯定的是,Facebook希望能夠采用它認為適合框架的任何類型的CPU和加速器進行訓練,以及任何價格低廉的芯片推理引擎,在任意給定的時間內,它的性能都比CPU好10倍。今天在Facebook運行在X86服務器上的推理業務是英特爾的失敗。或許也未必,沒準Facebook會決定在今年晚些時候推出M.2 Nervana NNP推理引擎。我們將會看到推理是如何流過Kings Canyon的。
-
加速器
+關注
關注
2文章
806瀏覽量
38025 -
機器學習
+關注
關注
66文章
8438瀏覽量
132953 -
生態系統
+關注
關注
0文章
703瀏覽量
20768
原文標題:揭秘FACEBOOK未來的機器學習平臺
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
2016機器學習行業應用國際峰會:唯「智」者,「造」未來
人工智能和機器學習的前世今生
Facebook背后的軟件揭秘
Facebook決定削減對機器學習和人工智能技術的投資
深度揭示 Facebook 內部支持機器學習的硬件和軟件基礎架構
介紹Facebook在機器學習方面的軟硬件基礎架構,來滿足其全球規模的運算需求
Facebook機器學習是什么?它能用來做什么?






 工商網監
工商網監
評論