 從上到下的系統架構分析方法Intel PMU的詳細資料概述
從上到下的系統架構分析方法Intel PMU的詳細資料概述
引言
現代 CPU 大多具有性能監控單元(Performance Monitoring Unit, PMU),用于統計系統中發生的特定硬件事件,例如緩存未命中(Cache Miss)或者分支預測錯誤(Branch Misprediction)等。同時,多個事件可以結合計算出一些高級指標,例如每指令周期數(CPI),緩存命中率等。一個特定的微體系架構可以通過 PMU 提供數百個事件。對于發現和解決特定的性能問題,我們很難從這數百個事件中挑選出那些真正有用的事件。 這需要我們深入了解微體系架構的設計和 PMU 規范,才能從原始事件數據中獲取有用的信息。
自頂向下的微體系架構分析方法(Top-Down Microarchitecture Analysis Method, TMAM)可以在亂序執行的內核中識別性能瓶頸,其通用的分層框架和技術可以應用于許多亂序執行的微體系架構。TMAM 是基于事件的度量標準的分層組織,用于確定應用程序中的主要性能瓶頸,顯示運行應用程序時 CPU 流水線的使用情況。
概述
現代高性能 CPU 的流水線非常復雜。 一般來說,CPU 流水線在概念上分為兩部分,即前端(Front-end)和后端(Back-end)。Front-end 負責獲取程序代碼指令,并將其解碼為一個或多個稱為微操作(uOps)的底層硬件指令。uOps 被分配給 Back-end 進行執行,Back-end 負責監控 uOp 的數據何時可用,并在可用的執行單元中執行 uOp。 uOp 執行的完成稱為退役(Retirement),uOp 的執行結果提交并反饋到>架構狀態(CPU 寄存器或寫回內存)。 通常情況下,大多數 uOps 通過流水線正常執行然后退役,但有時候投機執行的 uOps 可能會在退役前被取消,例如在分支預測錯誤的情況下。
在最近的英特爾微體系結構上,流水線的 Front-end 每個 CPU 周期(cycle)可以分配4個 uOps ,而 Back-end 可以在每個周期中退役4個 uOps。 流水線槽(pipeline slot)代表處理一個 uOp 所需的硬件資源。 TMAM 假定對于每個 CPU 核心,在每個 CPU 周期內,有4個 pipeline slot 可用,然后使用專門設計的 PMU 事件來測量這些 pipeline slot 的使用情況。在每個 CPU 周期中,pipeline slot 可以是空的或者被 uOp 填充。 如果在一個 CPU 周期內某個 pipeline slot 是空的,稱之為一次停頓(stall)。如果 CPU 經常停頓,系統性能肯定是受到影響的。TMAM 的目標就是確定系統性能問題的主要瓶頸。
下圖展示并總結了亂序執行微體系架構中自頂向下確定性能瓶頸的分類方法。這種自頂向下的分析框架的優點是一種結構化的方法,有選擇地探索可能的性能瓶頸區域。 帶有權重的層次化節點,使得我們能夠將分析的重點放在確實重要的問題上,同時無視那些不重要的問題。
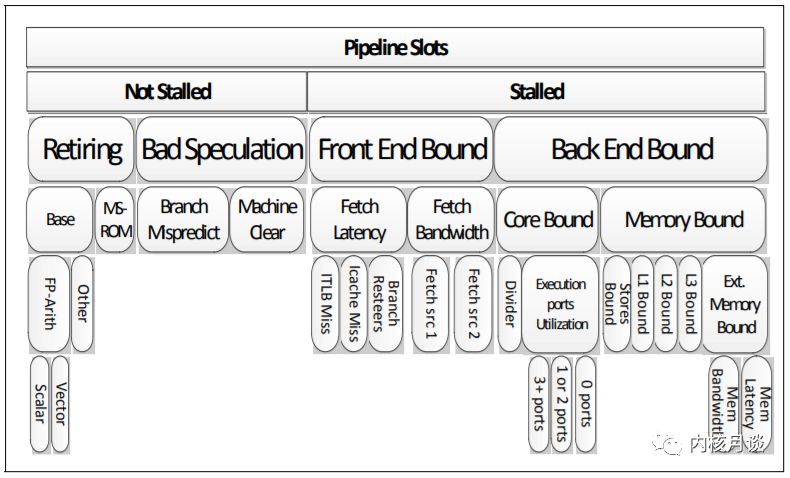
例如,如果應用程序性能受到指令提取問題的嚴重影響, TMAM 將它分類為 Front-end Bound 這個大類。 用戶或者工具可以向下探索并僅聚焦在 Front-end Bound 這個分類上,直到找到導致應用程序性能瓶頸的直接原因或一類原因。
設計
Top Level
在最頂層,TMAM 將 pipeline slot 分為四個主要類別:
Front-end Bound
1Front-endBound表示pipeline的Front-end不足以供應Back-end。
Front-end是pipeline的一部分,負責交付uOps給Back-end執行。
Front-endBound進一步分為FetchLatency(例如,ICacheorITLBmisses)
和FetchBandwidth(例如,sub-optimaldecoding)。
Back-end Bound
1Back-endBound表示由于缺乏接受執行新操作所需的后端資源而導致
停頓的pipelineslot。它進一步分為分為MemoryBound(由于內存子系統造成的
執行停頓)和CoreBound(執行單元壓力ComputeBound或者缺少指令級并行ILP)。
Bad Speculation
1BadSpeculation表示由于分支預測錯誤導致的pipelineslot被浪費,
主要包括(1)執行最終被取消的uOps的pipelineslot,以及(2)由于從
先前的錯誤猜測中恢復而導致阻塞的pipelineslot。
Retiring
1Retiring表示運行有效uOp的pipelineslot。理想情況下,
我們希望看到所有的pipelineslot都能歸類到Retiring,
因為它與IPC密切相關。盡管如此,高Retiring比率并不意味著沒有提升優化的空間。
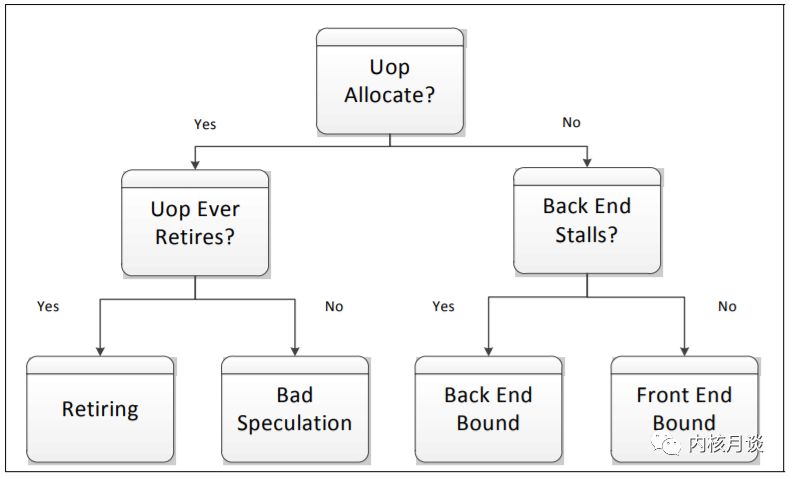
后兩者表示非停頓的 pipeline slot,前兩者表示停頓的 pipeline slot。 下圖描述了一個簡單的決策樹來展示向下分析的過程。如果一個 pipeline slot 被某個 uOp 使用,它將被分類為 Retiring 或 Bad Speculation,具體取決于它是否最終提交。如果 pipeline 的 Back-end 部分不能接受更多操作(也稱為 Back-end Stall),未使用的 pipeline slot 被分類為 Back-end Bound。Front-end Bound 則表示>在沒有 Back-end Stall 的情況下沒有操作(uOps)被分配執行。
Front-end Bound
在許多情況下,Front-end 指令帶寬可能會影響性能,特別是在高 IPC 的情況下。一些專用單元被引入,用來隱藏流水線 Fetch 指令延遲以及維持所需的帶寬,例如 Loop Stream Detector (LSD) 以及 Decoded I-cache (DSB)。
TMAM 進一步將 Front-end Bound 劃分為延遲和帶寬兩個子類:
ICache miss 屬于 Fetch Latency 分類
指令解碼器的低效問題屬于 Fetch Bandwidth 分類
這些度量標準都是以自頂向下的方式定義的。Fetch Latency 表示任何原因導致的指令提取饑餓(沒有指令輸送)。我們所熟知的 icache and i-TLB miss 就屬于這個類別,但是并不局限于此。Branch Resteers 表示流水線刷新(pipeline flush)之后的指令提取延遲。pipeline flush 可能由一些清除狀態的事件引起,例如 branch misprediction 或者 memory nukes。Branch Resteers 與 Bad Speculation 密切相關。
Back-end Bound
Back-end Bound 分為 Memory Bound 和 Core Bound,通過在每個周期內基于執行單元的占用情況來分析 Back-end 停頓。為了達到盡可能大的 IPC,需要使得執行單元保持繁忙。例如,在一個有4個 slot 的機器中,如果在穩定狀態下只能執行三個或更少的 uOps,就不能達到最佳狀態,即 IPC 等于4。這些次優周期稱為 Execution Stalls。
Memory Bound
1MemoryBound對應緩存和內存子系統相關的ExecutionStalls。這些停頓通常表現為執行單元在短時間內饑餓,例如load操作沒有在緩存中命中。對于常見情況,內存訪問的真正代價是調度程序沒有其他準備好的uOps提供給執行單元。后面的uOps可能正在等待進行中的內存訪問,或者依賴于其他未準備好的uOps。23ExecutionStalls包含幾個子類,每個子類都與特定的高速緩存級別相關聯,取決于各個高速緩存級別是否可以滿足所需的數據。在某些情況下,ExecutionStall可能會經歷顯著的延遲,遠遠大于相應緩存級別的標準延遲,即使沒有發生相應的緩存未命中。例如,L1D高速緩存通常具有與ALU停頓相當的較短的延遲。然而在某些情況下,如load操作被阻塞,無法將數據從較早的store操作轉發(forward)到一個重疊地址,這個load負載可能會遭受較高的延遲,雖然最終能在L1D中命中。在這種情況下,in-flight的load操作將持續很長時間并且不會產生L1Dmiss。因此,這個問題屬于L1Bound子類。45此外,與store操作相關的ExecutionStalls都屬于StoresBound子類。由于內存訪問順序要求,store操作被緩存并異步執行。通常,store操作對性能影響很小,但不能完全忽視。TMAM將StoresBound定義為那些執行端口利用率(executionportutilization)較低,以及存在大量需要消耗資源用來緩沖store操作的周期。67最后,TMAM在Ext.MemoryBound子類下使用了一個簡單的啟發式算法來區分MEMBandwidth和MEMLatency。該啟發式算法的主要根據是當前有多少請求依賴從內存中獲取的數據。每當這類請求的占用率超過一個高閾值時(例如最大請求數的70%),TMAM將其標記為可能受內存帶寬的限制。其他部分都屬于內存延遲子類。
Core Bound
1CoreBound對應于執行單元存在壓力或者程序中缺少指令級別并行(ILP)。Corebound的
停頓可能表現為較短的執行饑餓周期或者執行端口利用率不佳,這使得識別Corebound比較困難。
例如,一個長延遲的除法操作可能會序列化執行,而服務于特定類型uOps的執行端口上的壓力
可能表現為一個周期內只有少量端口被使用。23CoreBound的問題一般可以通過更好的代碼生成來緩解。例如,一系列相關的算術
運算將被標記為CoreBound。編譯器可以通過更好的指令調度來緩解這種停頓。
矢量化(Vectorization)也可以緩解CoreBound的問題。
Bad Speculation
Bad Speculation 表示由于不正確的預測而浪費的 pipeline slot,主要包括兩部分:
執行了最終不會被提交的 uOps 的 slots
從錯誤預測中恢復而導致流水線被阻塞的 slots
TMAM 的一個關鍵原則就是將 Bad Speculation 放在了最頂層, Bad Speculation 確定了受到錯誤執行路徑影響的工作負載的比例,并反過來決定了其他類別中觀察值的準確性。TMAM 進一步將 Bad Speculation 分類為 Branch Mispredict 和 Machine Clears,這兩種情況導致的問題和 pipeline flush 相像。Branch Mispredict 主要關注如何使程序控制流對分支預測更友好,Machine Clears 則主要指出一些異常情況,例如清除內存排序機(memory ordering machine clears)或者自修改代碼(self modifying code)。
Retiring
理想情況下,我們希望看到所有的 slots 都被標記為 Retiring 類別。盡管如此,Retiring 比例高并不意味著沒有更多的性能提升空間。諸如 Floating Point Assists (FP_ASSISTS) 的微指令(Microcode)序列通常會影響性能并且可以避免。這類情況被標記為 MSROM 子類以便引起注意。
非矢量化(non-vectorized)代碼的高 Retiring 比值可能是進行向量化(vectorization)代碼的一個重要提示。這樣做基本上可以讓更多的操作通過單指令 uOp 完成,從而提高性能。TMAM 進一步將 Retiring->Base 子類劃分為 FP Arith,并區分標量操作和矢量操作。
應用/工具
pmu-tools 是 Adni Kleen 開發的開源工具包,針對 Intel CPU 提供友好的接口來訪問原始事件,并提供一些附加功能。toplev 是 pmu-tools 中的一個工具,在 Intel CPU 的 Linux perf 基礎上實現了 TMAM 方法。toplev 可以定位 CPU Bound 代碼的瓶頸,不能識別其他(Not bound by CPU)代碼的瓶頸。toplev 是一個計數工具,它使用 PMU 來計數事件。toplev 的一個典型使用場景是,用戶已經根據一個標>準工具(例如 perf, sysprof, pyprof)進行采樣,了解 hot code 的分布,但是你想知道為什么這部分代碼運行很慢。
安裝
toplev 在 Linux 上運行,需要安裝 perf 工具。toplev 還需要訪問 PMU,在 VM 中運行時需要注意啟用這個特性。注意,toplev 需要禁用 NMI watchdog,并以 root 身份運行。
1%gitclonehttps://github.com/andikleen/pmu-tools2%cdpmu-tools3%exportPATH=$PATH:`pwd`4%sudosysctl-p'kernel.nmi_watchdog=0'
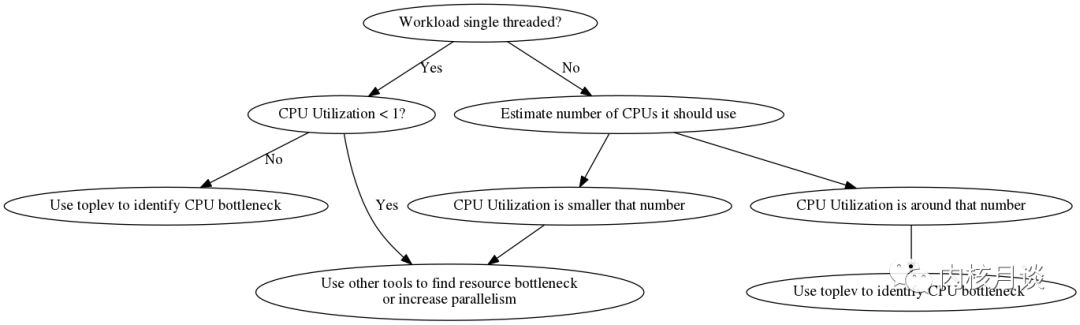
確定 CPU Bound 任務
第一步是確定程序是否真的是 CPU Bound 型工作負載。toplev 只能幫助定位解決 CPU Bound 問題。如果瓶頸在其他地方,則必須使用其他方法。非 CPU 瓶頸可以是網絡,磁盤IO,顯卡等。
選擇要計數的代碼
一般來說toplev測量整個系統的性能數據;當指定一個工作負載時,toplev將在工作負載運行的時間段內測量整個系統,這一點和perf的使用是類似的。
1%toplev.pymy-workload2或者3%toplev.pysleepXXX
讓我們衡量一個簡單的工作負載。這是一個 bc 表達式,在作者電腦上運行大約1秒(在大多數情況下,使用長時間運行的工作負載可能會更好),使用第一層級(-lxxx 參數用來設定測量的最大層級)運行以避免任何 PMU 計數器的多路復用。
1%toplev.py-l1bash-c'echo"7^199999"|bc>/dev/null' 2Willmeasurecompletesystem. 3Usinglevel1. 4... 5C0BADBad_Speculation:31.66% 6Thiscategoryreflectsslotswastedduetoincorrect 7speculations,whichincludeslotsusedtoallocateuopsthat 8donoteventuallygetretiredandslotsforwhichallocation 9wasblockedduetorecoveryfromearlierincorrect10speculation...11C1FEFrontend_Bound:42.46%12ThiscategoryreflectsslotswheretheFrontendofthe13processorundersuppliesitsBackend...14C1BEBackend_Bound:27.25%15Thiscategoryreflectsslotswherenouopsarebeing16deliveredduetoalackofrequiredresourcesforaccepting17moreuopsintheBackendofthepipeline...18C0-T0CPUutilization:0.00CPUs19NumberofCPUsused...20C0-T1CPUutilization:0.00CPUs21C1-T0CPUutilization:0.00CPUs22C1-T1CPUutilization:0.00CPUs
每當首次打印層節點時,toplev 都會打印一個描述。默認情況下,它顯示一個簡短描述,長描述可以使用--long-desc來啟用。在之后的例子中,我們禁用描述以獲得較短的輸出。toplev 輸出中,一些值以 core 為單位,另一些則以 thread 為單位收集。多 socket 的情況下還會有 socket 分類。
上面的例子中,我們沒有將工作負載(bc)綁定到某個 CPU,所以不清楚 C0 或 C1 的值是否相關。由于 bc 是單線程的,我們可以將它綁定到一個已知的 CPU 核心,并使用--core來過濾該核心上的輸出。
1%toplev.py--coreC0--no-desc-l1taskset-c0bash-c'echo"7^199999"|bc>/dev/null'2Willmeasurecompletesystem.3Usinglevel1.4...5C0BADBad_Speculation:33.29%6C0-T0CPUutilization:0.00CPUs7C0-T1CPUutilization:0.00CPUs
可以結合 taskset 綁定到更多的 CPU 進行多線程工作,并將結果進行過濾。結果顯示bc受限于 Bad Speculation。現在我們可以選擇更多的節點并更詳細地分析問題。
如果已知工作負載是單線程的,并且系統當前空閑,那么也可以顯式指定--single-thread選項來測量工作負載,而不是默認測量整個系統
1%toplev.py--no-desc--single-threadbash-c'echo"7^199999"|bc>/dev/null'2..3BADBad_Speculation:32.65%4CPUutilization:0.00CPUs
程序在初始化階段的行為相比生命周期后期的行為有很大的差異。為了精確測量,跳過這個階段通常是有用的。這可以用-D xxx選項來完成,xxx是跳過的毫秒數(需要較新版本的 perf)。當程序運行時間足夠長時,這通常是不需要的,但是它有助于提高小測試的精度。默認情況下,toplev 同時測量內核和用戶代碼。如果只對用戶代碼感興趣,則可以使用--user選項。這往往會減少測量噪聲,因為中斷被過濾掉了。還有一個--kernel選項用來測量內核代碼。在具有多個階段的復雜工作負載上,測量間隔也是有用的。這可以用-I xxxi選項指定,xxx是間隔的毫秒數。perf 要求時間間隔至少需要 100ms。toplev 將輸出每個間隔的測量值。這往往會產生大量的數據,所以繪制輸出很有必要。
選擇正確的層次和多路復用
PMU 只有有限數量的計數器可以同時測量事件。任何多于一個層次的 toplev 運行,或者啟動了額外的CPU 指標,則需要更多的計數器。在這種情況下,內核驅動程序將開始多路復用(Multiplexing),并定期更改事件組(在1毫秒和10毫秒之間,通常2.5毫秒,取決于內核配置)。多路復用可能會導致測量錯誤,因為 toplev 中的幾個節點中的公式需要關聯多個事件組的數據。因此 toplev 在反復執行同樣事情的工作負載上效果最好,但在執行許多不同的短事件的工作負載上效果不佳。
只要沒有使用 PMU 的或者有問題的其他工作負載處于活動狀態,則第一層次(-l1)和未啟用額外指標的 toplev 不會進行多路復用。一開始的時候,不采用多路復用來進行分析通常是一個好主意。更高的層次和指標提供了額外的信息,但也增加了復用,因此可能導致更多的測量錯誤。如果工作負載非常重復,可以使用--no-multiplex關閉復用。toplev 會根據需要多次重新運行工作量。在 BIOS 中禁用超線程將使通用計數器的數量增加一倍,并減少多路復用。
有關問題的更多詳細信息和解決方法,可以參閱 reasons for measuring issues
數組求和實例的測試分析
我們考慮測量一些 beating the compiler 的例子。beating the compiler 實現了一個簡單的問題,即數組求和,從高級腳本語言開始,然后利用底層操作逐步優化。測試代碼運行在啟用了 Turbo 的 Intel Core i7-4600U(Haswell)筆記本電腦上。
開始是簡單直接的Python實現。
1defsum_naive_python():2result=03foriindata:4result+=i5returnresult
我們用 toplev 來運行這段代碼,跳過初始化階段(大約80毫秒,通過預先測量得到)。一般來說,測量太短的程序是很困難的(太多的其他影響占主導地位)。在這種情況下,我們通過迭代5000次測試來調試程序運行至少幾秒鐘。
1%toplev.py-D80-l1--no-desc--coreC0taskset-c0pythonfirst.pynumbers2..3C0FEFrontend_Bound:22.08%4C0RETRetiring:75.01%
所以 Python 是一點 Front-end Bound,但是從 toplev 中沒有其他發現可見的問題。我們可以通過將層級提高到3來更仔細地分析 Front-end Bound。注意這可能有缺點,因為它會導致多路復用。在這種情況下,工作負載運行時間越長越好(我們將基準函數循環5000次)。
1%toplev.py-D80-l3--coreC0taskset-c0pythonfirst.pynumbers 2... 3C0FEFrontend_Bound:21.91% 4C0FEFrontend_Bound.Frontend_Bandwidth:15.91% 5C0FEFrontend_Bound.Frontend_Bandwidth.DSB:32.11% 6ThismetricrepresentsCorecyclesfractioninwhichCPUwas 7likelylimitedduetoDSB(decodeduopcache)fetch 8pipeline... 9C0RETRetiring:74.97%10C0RETRetiring.Base:74.88%
可以觀察到 Front-end Bound 是 DSB (decoded uop cache) fetch。具體描述被簡化了,可以使用--long-desc來查看更具體的描述。
讓我們來看看第二個 Python 版本。這個版本使用 Python 中的內建函數 sum() 來數組求和,以便將更多的執行動作從解釋器推送到 Python C 核心。
1defsum_builtin_python():2returnsum(data)
在這種情況下,我們知道 python 代碼是單線程的(系統的其余部分是空閑的),所以可以使用--single-thread。
1%toplev.py--single-thread-l3-D80pythonsecond.pynumbers2...3FEFrontend_Bound:27.40%4FEFrontend_Bound.Frontend_Bandwidth:23.20%5FEFrontend_Bound.Frontend_Bandwidth.DSB:46.30%6ThismetricrepresentsCorecyclesfractioninwhichCPUwas7likelylimitedduetoDSB(decodeduopcache)fetch8pipeline...
然而這并沒有改變多少結果。Python 是相當重(heavy-weight)的,大大加重了 CPU 的前端,但其中大部分至少在解碼的 icache 中運行。
現在我們來看一個標準的C實現,它應該快得多:
1intsum_simple(int*vec,size_tvecsize)2{3intres=0;4inti;5for(i=0;i
這個循環被編譯成一個簡單的測試工具,使用 gcc 4.8.3 并關閉優化,使用 toplev 進行測量:
1%toplev.py-l1--single-thread--force-events./c1-unoptimizednumbers2BEBackend_Bound:60.34%3Thiscategoryreflectsslotswherenouopsarebeing4deliveredduetoalackofrequiredresourcesforaccepting5moreuopsintheBackendofthepipeline...
這個版本比 Python 版本運行速度快4倍。瓶頸已經完全進入 Back-end。我們可以在第三層級更仔細地看待它:
1%toplev.py-l3--single-thread--force-events./c1-unoptimizednumbers 2BEBackend_Bound:60.42% 3BE/MemBackend_Bound.Memory_Bound:32.23% 4BE/MemBackend_Bound.Memory_Bound.L1_Bound:32.44% 5ThismetricrepresentshowoftenCPUwasstalledwithout 6missingtheL1datacache... 7Samplingevents:mem_load_uops_retired.l1_hit:pp,mem_load_uops_retired.hit_lfb:pp 8BE/CoreBackend_Bound.Core_Bound:45.93% 9BE/CoreBackend_Bound.Core_Bound.Ports_Utilization:45.93%10Thismetricrepresentscyclesfractionapplicationwas11stalledduetoCorecomputationissues(nondivider-12related)...
可以看到它是 L1 Bound 和 Core Bound。 L1 Bound 可能是因為未優化的 gcc 代碼傾向于將所有變量存儲在堆棧上,沒有進行全面的寄存器優化。 我們可以用-O2打開優化器,看看會發生什么:
1%toplev.py-l3--single-thread./c1-o2numbers2RETRetiring:83.66%3RETRetiring.Base:83.62%4ThismetricrepresentsslotsfractionwheretheCPUwas5retiringuopsnotoriginatedfromthemicrocode-sequencer...6Samplingevents:inst_retired.prec_dist:pp
L1 Bound 完全消失,工作負載的大部分時間都在 Retire,這是很好的。這個版本也比未優化的C版本快了85%。注意這些好處有些極端的情況,可能完全取決于代碼的行為。
優化 Retiring 的一種方法是對代碼進行矢量化(Vectorization),并在每條指令上做更多的工作。通過gcc -O3啟用矢量化。不幸的是,它不能矢量化我們簡單的循環。
1c1.c:9:note:notvectorized:notsuitableforgatherload_32=*_31;
我們可以從 beating the compiler 中嘗試Roguelazer手動優化的內嵌匯編 AVX2 版本。這應該會減少 Retiring,因為它在每個 SIMD 指令中可以執行多達8個加法,同時它還使用了循環展開。
1%toplev.py-l3--single-thread./c-asmnumbers 2BEBackend_Bound:64.15% 3BE/MemBackend_Bound.Memory_Bound:... 4BE/MemBackend_Bound.Memory_Bound.L1_Bound:49.32% 5ThismetricrepresentshowoftenCPUwasstalledwithout 6missingtheL1datacache... 7Samplingevents:mem_load_uops_retired.l1_hit:pp,mem_load_uops_retired.hit_lfb:pp 8BE/MemBackend_Bound.Memory_Bound.L3_Bound:48.68% 9ThismetricrepresentshowoftenCPUwasstalledonL3cache10orcontendedwithasiblingCore...11Samplingevents:mem_load_uops_retired.l3_hit:pp12BE/CoreBackend_Bound.Core_Bound:28.27%13BE/CoreBackend_Bound.Core_Bound.Ports_Utilization:28.27%14Thismetricrepresentscyclesfractionapplicationwas15stalledduetoCorecomputationissues(nondivider-16related)...
Retiring 瓶頸已經消失,我們終于看到了 Backend_Bound.Memory_Bound 瓶頸,在這種情況下,L1 Bound 和 L3 Bound所占百分比幾乎相等,其余的是核心執行。
-
寄存器
+關注
關注
31文章
5363瀏覽量
120949 -
cpu
+關注
關注
68文章
10901瀏覽量
212682 -
PMU
+關注
關注
1文章
109瀏覽量
21665
原文標題:從上到下的系統架構分析方法 - Intel PMU
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
stm32 mini板子框體刷屏時框體本身明顯有從上到下的刷屏感覺
汽車控制電腦板的元件分析和詳細資料概述


PLC控制系統的設計與應用實例詳細資料概述





 工商網監
工商網監
評論