 和谷歌研究人員一起探索數據并行的邊界極限
和谷歌研究人員一起探索數據并行的邊界極限
在過去的幾年里,神經網絡在圖像分類、機器翻譯和語音識別等領域獲得了長足的進步,取得了十分優異的結果。這樣的成績離不開軟件和硬件的對訓練過程的加速和改進。更快速的訓練使得模型質量飛速提升,不僅在相同的時間內可以處理更多的數據,也使得研究人員得以迅速嘗試更多的想法,研究出更好的模型。
隨著軟硬件和數據中心云計算的迅速發展,支撐神經網絡的算力大幅提升,讓模型訓練地又好又快。但該如何利用這前所未有的算力來得到更好的結果是擺在所有研究人員面前的一個問題,我們是否應該用更大的算力來實現更快的訓練呢?
并行計算
分布式計算是使用大規模算力最常用的方法,可以同時使用不同平臺和不同架構的處理器。在訓練神經網絡的時候,一般會使用模型并行和數據并行兩種方式。其中模型并行會將模型分別置于不同的計算單元上,使得大規模的模型訓練成為可能,但通常需要對網絡架構進行裁剪以適應不同的處理器。而數據并行著是將訓練樣本分散在多個計算單元上,并將訓練結果進行同步。
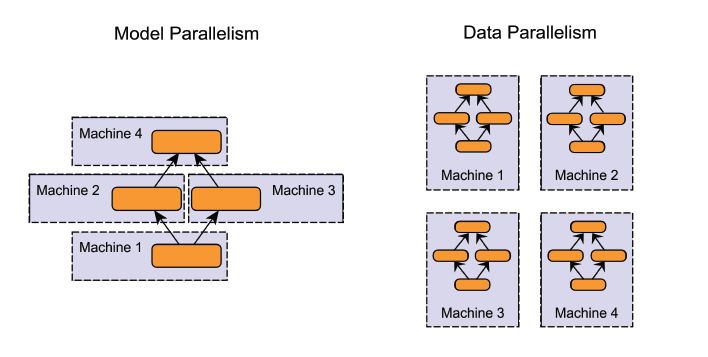
數據并行幾乎可以用于任何模型的訓練加速,它是目前使用最為廣泛也最為簡單的神經網絡并行訓練手段。對于想SGD等常見的訓練優化算法來說,數據并行的規模與訓練樣本的批量大小息息相關。我們需要探索對于數據并行方法的局限性,以及如何充分利用數據并行方法來加速訓練。
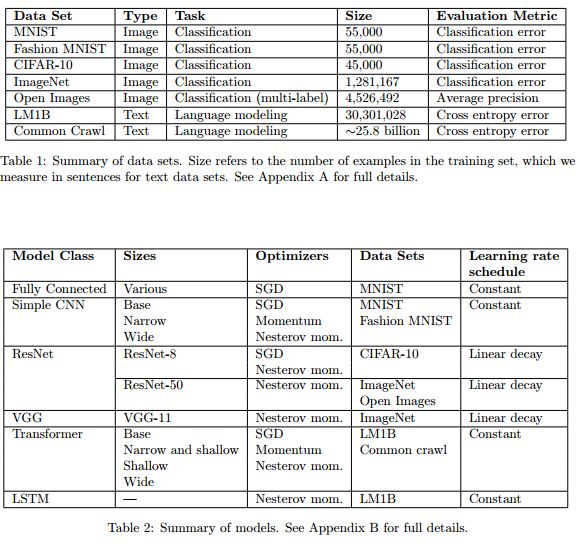
實驗中使用的模型、數據集和優化器。
谷歌的研究人員在先前的研究中評測了數據并行對于神經網絡訓練的影響,深入探索了批次(batch)的大小與訓練時間的關系,并在六種不同的神經網絡/數據集上利用三種不同的優化方法進行了測試。在實驗中研究人員在約450個負載上訓練了超過100k個模型并發現了訓練時間與批量大小的關系。
研究人員分別從數據集、網絡架構、優化器等角度探索了這一關系的變化,發現在不同的負載上訓練時間和批量大小的關系發生了劇烈的變化。研究結果中包含了71M個模型的測評結果,完整的描繪了100k個模型的訓練曲線,并在論文中的24個圖中充分體現了出來。
訓練時間與批量大小間的普遍聯系
在理想的數據并行系統中,模型間的同步時間可忽略不計,訓練時間可以使用訓練的步數(steps)來測定。在這一假設下,研究人員從實驗的結果中發現了三個區間的關系:在完美區間內訓練時間隨著批量大小線性減小,隨之而來的是遞減拐點,最后將達到最大數據并行的極限,無論如何增大批量的大小即使不考慮硬件,模型的訓練時間也不會明顯減小。
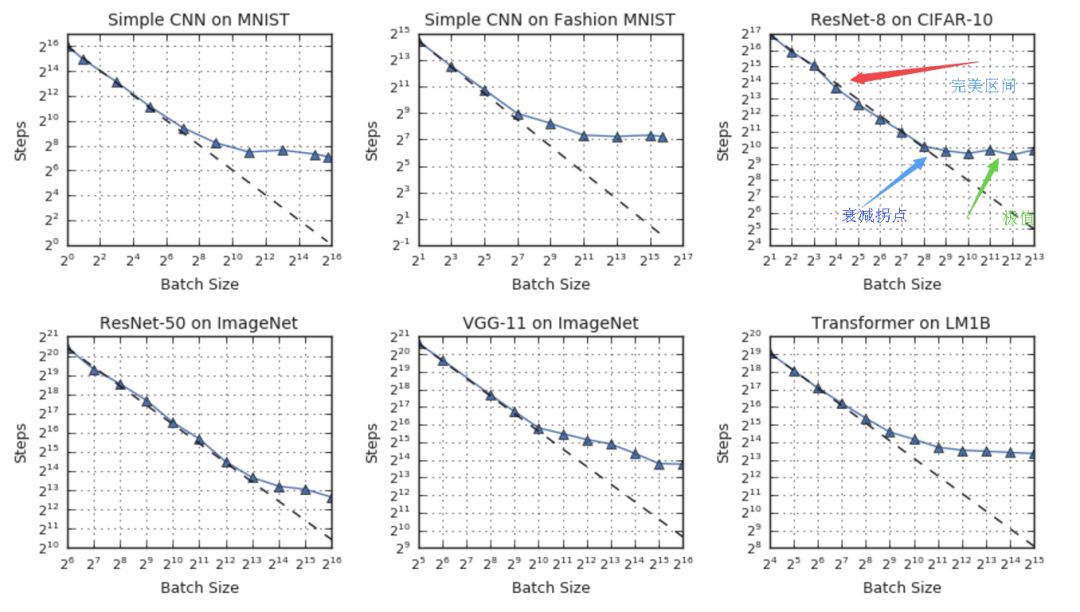
盡管上述的基本關系在不同測試中成立,但研究人員發現上述過程中的拐點在不同數據集和神經網絡架構中的表現十分不同。這意味著簡單的數據并行可以再當今硬件極限的基礎上為某些工作提供加速,但除此之外有些工作也許還需要其他方法來充分利用大規模算力。
在上面的例子中可以看到,ResNet-8在CIFAR-10并不能從超過1024的批大小中獲得明顯的加速,而ResNet-50在ImageNet上則可以一直將批大小提升到65536以上來減小訓練時間。
優化任務
如果可以預測出哪一種負載最適合于數據并行訓練,我們就可以針對性的修改任務負載以充分利用硬件算力。但遺憾的是實驗結果并沒有給出一個明確的計算最大有效批次的方法。拐點與網絡架構、數據集、優化器都有著密切的關系。例如在相同的數據集和優化器上,不同的架構可能會有截然不同的最大可用批次數量。
研究人員認為這主要來源于網絡寬度和深度的不同,但對于某些網絡來說甚至沒有深度和寬度的概念,所以無法得到一個較為清晰的關系來計算最大可用批次數量。甚至當我們發現有的網絡架構可以接受更大的批次,但在不同數據集上的表現又無法得到統一的結論,有時小數據集上大批次的表現甚至要好于大數據上的結果。
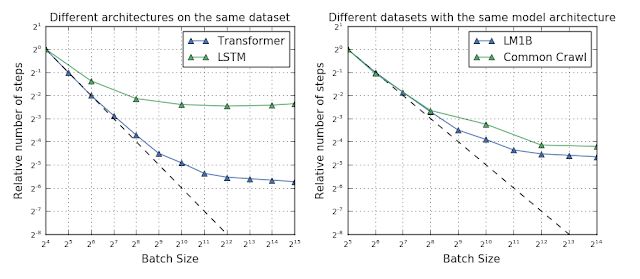
fig 4圖中顯示了遷移模型和LSTM模型在相同數據集上最大批次的不同,右圖則顯示了較大的數據集與最大batch也沒有絕對的相關性,LM1B規模較小但可以達到較大的batch。但毋庸置疑的是,在優化算法上的微小改動都會使得訓練結果在增加批量大小的過程中發生極大的變化。這意味著我們可以通過設計新的優化器來最大化的利用數據并行的能力。
未來的工作
雖然利用通過增加批量大小來提高數據并行能力是提速的有效手段,但由于衰減效應的存在無法達到硬件的極限能力。研究表明優化算法也許可以指導我們找到充分利用硬件算力的解決方案。研究人員未來的工作將集中于對于不同優化器的測評,探索恩能夠加速數據并行能力的新方法,盡可能的延伸批量大小對應訓練時間的加速范圍。
如果想探索研究人員們在千百個模型上訓練出的數據,可以直接訪問colab:https://colab.research.google.com/github/google-research/google-research/blob/master/batch_science/reproduce_paper_plots.ipynb詳細過程見論文包含了24個豐富完整的測評圖,描繪了神經網絡訓練過程各種參數隨批量變化的完整過程:https://arxiv.org/pdf/1811.03600.pdf
ref:https://ai.googleblog.com/2019/03/measuring-limits-of-data-parallel.html
Paper:https://arxiv.org/pdf/1811.03600.pdf
代碼:https://colab.research.google.com/github/google-research/google-research/blob/master/batch_science/reproduce_paper_plots.ipynb
https://blog.skymind.ai/distributed-deep-learning-part-1-an-introduction-to-distributed-training-of-neural-networks/https://blog.inten.to/hardware-for-deep-learning-part-3-gpu-8906c1644664?gi=bdd1e2e4331ehttps://ai.googleblog.com/2019/03/measuring-limits-of-data-parallel.htmlhttps://blog.csdn.net/xbinworld/article/details/74781605
Headpic from: https://dribbble.com/shots/4038074-Data-Center
-
谷歌
+關注
關注
27文章
6180瀏覽量
105768 -
并行計算
+關注
關注
0文章
27瀏覽量
9454 -
分布式計算
+關注
關注
0文章
28瀏覽量
4508
原文標題:和谷歌研究人員一起,探索數據并行的邊界極限
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦


NVIDIA與谷歌量子AI部門達成合作
谷歌研究人員推出革命性首個AI驅動游戲引擎
谷歌發布新型大語言模型Gemma 2
研究人員利用人工智能提升超透鏡相機的圖像質量

【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》2.0
研究人員利用定制光控制二維材料的量子特性
兩個STM32的IO口連接到一起,其中一個IO口被燒壞的原因?
六類網線可以和強電一起走嗎
研究人員發現提高激光加工分辨率的新方法





 工商網監
工商網監
評論