 神經協同過濾NCF原理及實戰
神經協同過濾NCF原理及實戰
1.1 背景
本文討論的主要是隱性反饋協同過濾解決方案,先來明確兩個概念:顯性反饋和隱性反饋:
顯性反饋行為包括用戶明確表示對物品喜好的行為隱性反饋行為指的是那些不能明確反應用戶喜好。
舉例來說:

很多應用場景,并沒有顯性反饋的存在。因為大部分用戶是沉默的用戶,并不會明確給系統反饋“我對這個物品的偏好值是多少”。因此,推薦系統可以根據大量的隱性反饋來推斷用戶的偏好值。
根據已得到的隱性反饋數據,我們將用戶-條目交互矩陣Y定義為:
但是,Yui為1僅代表二者有交互記錄,并不代表用戶u真的喜歡項目i,同理,u和i沒有交互記錄也不能代表u不喜歡i。這對隱性反饋的學習提出了挑戰,因為它提供了關于用戶偏好的噪聲信號。雖然觀察到的條目至少反映了用戶對項目的興趣,但是未查看的條目可能只是丟失數據,并且這其中存在自然稀疏的負反饋。
在隱性反饋上的推薦問題可以表達為估算矩陣 Y中未觀察到的條目的分數問題(這個分數被用來評估項目的排名)。形式上它可以被抽象為學習函數:
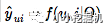
為了處理缺失數據,有兩種常見的做法:要么將所有未觀察到的條目視作負反饋,要么從沒有觀察到條目中抽樣作為負反饋實例。
1.2 矩陣分解及其缺陷
傳統的求解方法是矩陣分解(MF,Matrix Factorization),為每個user和item找到一個隱向量,問題變為:
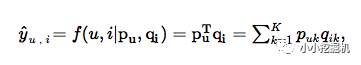
這里的 K表示隱式空間(latent space)的維度。正如我們所看到的,MF模型是用戶和項目的潛在因素的雙向互動,它假設潛在空間的每一維都是相互獨立的并且用相同的權重將它們線性結合。因此,MF可視為隱向量(latent factor)的線性模型。
論文中給出了一個例子來說明這種算法的局限性:
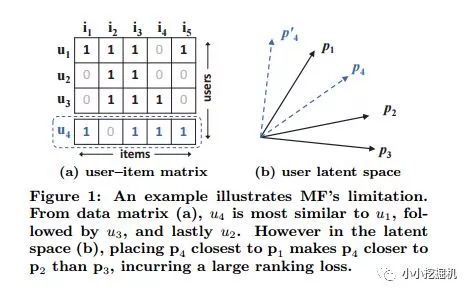
1(a)是user-item交互矩陣,1(b)是用戶的隱式空間,論文中強調了兩點來理解這張圖片:1)MF將user和item分布到同樣的隱式空間中,那么兩個用戶之間的相似性也可以用二者在隱式空間中的向量夾角來確定。
2)使用Jaccard系數來作為真實的用戶相似性。通過MF計算的相似性與Jaccard系數計算的相似性也可以用來評判MF的性能。我們先來看看Jaccard系數


上面的示例顯示了MF因為使用一個簡單的和固定的內積,來估計在低維潛在空間中用戶-項目的復雜交互,從而所可能造成的限制。解決該問題的方法之一是使用大量的潛在因子 K (就是隱式空間向量的維度)。然而這可能對模型的泛化能力產生不利的影響(e.g. 數據的過擬合問題),特別是在稀疏的集合上。論文通過使用DNNs從數據中學習交互函數,突破了這個限制。
1.3 NCF
本文先提出了一種通用框架:
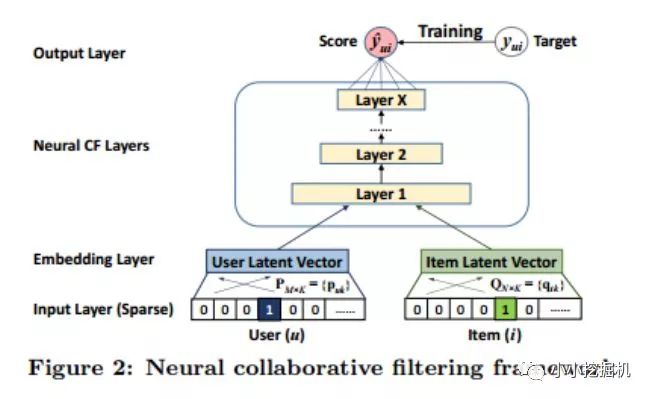
針對這個通用框架,論文提出了三種不同的實現,三種實現可以用一張圖來說明:
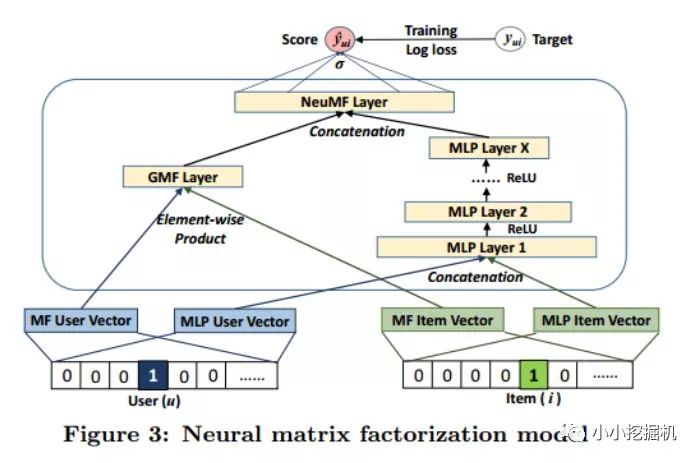
GMF:上圖中僅使用GMF layer,就得到了第一種實現方式GMF,GMF被稱為廣義矩陣分解,輸出層的計算公式為:
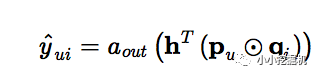
MLP上圖中僅使用右側的MLP Layers,就得到了第二種學習方式,通過多層神經網絡來學習user和item的隱向量。這樣,輸出層的計算公式為:
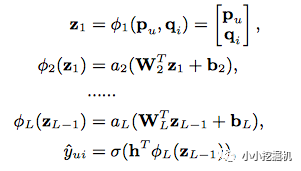
NeuMF結合GMF和MLP,得到的就是第三種實現方式,上圖是該方式的完整實現,輸出層的計算公式為:
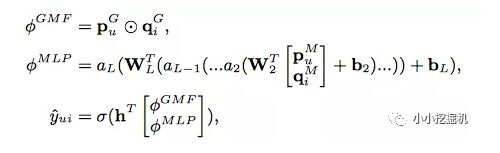
1.4 模型實驗
論文通過三個角度進行了試驗:
RQ1我們提出的NCF方法是否勝過 state-of-the-art 的隱性協同過濾方法?RQ2我們提出的優化框架(消極樣本抽樣的logloss)怎樣為推薦任務服務?RQ3更深的隱藏單元是不是有助于對用戶項目交互數據的學習?
使用的數據集:MovieLens 和 Pinterest 兩個數據集
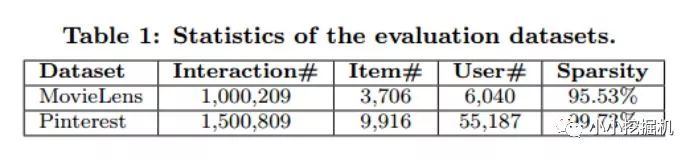
評估方案:為了評價項目推薦的性能,論文采用了leave-one-out方法評估,即:對于每個用戶,我們將其最近的一次交互作為測試集(數據集一般都有時間戳),并利用余下的培訓作為訓練集。由于在評估過程中為每個用戶排列所有項目花費的時間太多,所以遵循一般的策略,隨機抽取100個不與用戶進行交互的項目,將測試項目排列在這100個項目中。排名列表的性能由命中率(HR)和歸一化折扣累積增益(NDCG)來衡量。同時,論文將這兩個指標的排名列表截斷為10。如此一來,HR直觀地衡量測試項目是否存在于前10名列表中,而NDCG通過將較高分數指定為頂級排名來計算命中的位置。本文計算每個測試用戶的這兩個指標,并求取了平均分。
Baselines,論文將NCF方法與下列方法進行了比較:ItemPop,ItemKNN,BPR,eALS。
以下是三個結果的貼圖,關于試驗結果的解讀,由于篇幅的原因,大家可以查看原論文。
RQ1試驗結果
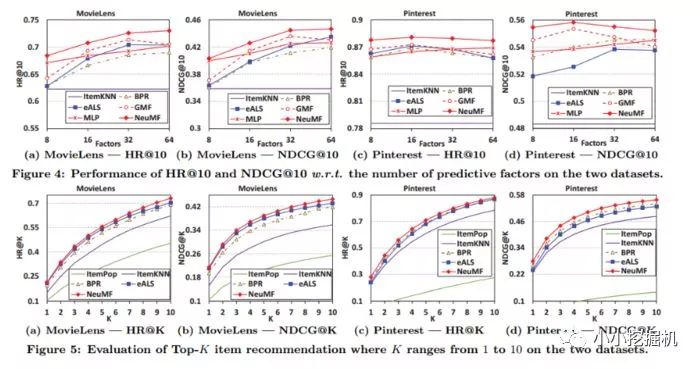
簡單的結論,即NCF效果好于BaseLine模型,如果不好的話論文也不用寫了,哈哈。
RQ2試驗結果
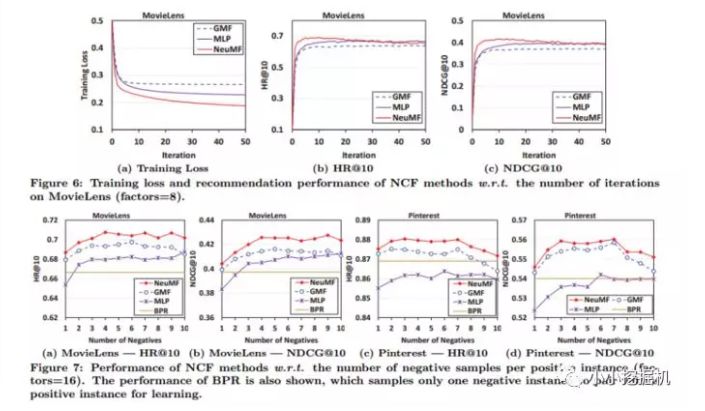
Figure 6 表示將模型看作一個二分類任務并使用logloss作為損失函數時的訓練效果。Figure7 表示采樣率對模型性能的影響(橫軸是采樣率,即負樣本與正樣本的比例)。
RQ3試驗結果
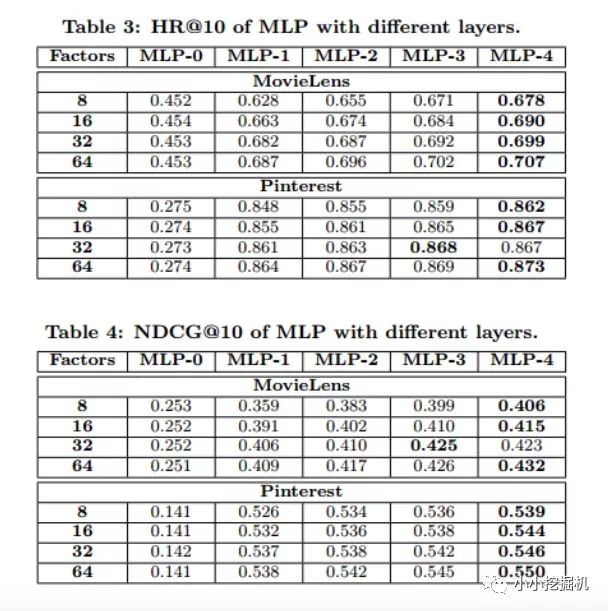
上面的表格設置了兩個變量,分別是Embedding的長度K和神經網絡的層數,使用類似網格搜索的方式展示了在兩個數據集上的結果。增加Embedding的長度和神經網絡的層數是可以提升訓練效果的。
本文的github地址為:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-NCF-Demo
本文僅介紹模型相關細節,數據處理部分就不介紹啦。
項目結構如下:
數據輸入本文使用了一種新的數據處理方式,不過我們的輸入就是三個:userid,itemid以及label,對訓練集來說,label是0-1值,對測試集來說,是具體的itemid
def get_data(self):sample = self.iterator.get_next()self.user = sample['user']self.item = sample['item']self.label = tf.cast(sample['label'],tf.float32)
定義初始化方式、損失函數、優化器
def inference(self):""" Initialize important settings """self.regularizer = tf.contrib.layers.l2_regularizer(self.regularizer_rate)if self.initializer == 'Normal': self.initializer = tf.truncated_normal_initializer(stddev=0.01)elif self.initializer == 'Xavier_Normal': self.initializer = tf.contrib.layers.xavier_initializer()else: self.initializer = tf.glorot_uniform_initializer()if self.activation_func == 'ReLU': self.activation_func = tf.nn.reluelif self.activation_func == 'Leaky_ReLU': self.activation_func = tf.nn.leaky_reluelif self.activation_func == 'ELU': self.activation_func = tf.nn.eluif self.loss_func == 'cross_entropy': # self.loss_func = lambda labels, logits: -tf.reduce_sum( # (labels * tf.log(logits) + ( # tf.ones_like(labels, dtype=tf.float32) - labels) * # tf.log(tf.ones_like(logits, dtype=tf.float32) - logits)), 1) self.loss_func = tf.nn.sigmoid_cross_entropy_with_logitsif self.optim == 'SGD': self.optim = tf.train.GradientDescentOptimizer(self.lr, name='SGD')elif self.optim == 'RMSProp': self.optim = tf.train.RMSPropOptimizer(self.lr, decay=0.9, momentum=0.0, name='RMSProp')elif self.optim == 'Adam': self.optim = tf.train.AdamOptimizer(self.lr, name='Adam')
得到embedding值分別得到GMF和MLP的embedding向量,當然也可以使用embedding_lookup方法:
with tf.name_scope('input'):self.user_onehot = tf.one_hot(self.user,self.user_size,name='user_onehot')self.item_onehot = tf.one_hot(self.item,self.item_size,name='item_onehot')with tf.name_scope('embed'):self.user_embed_GMF = tf.layers.dense(inputs = self.user_onehot, units = self.embed_size, activation = self.activation_func, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='user_embed_GMF')self.item_embed_GMF = tf.layers.dense(inputs=self.item_onehot, units=self.embed_size, activation=self.activation_func, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='item_embed_GMF')self.user_embed_MLP = tf.layers.dense(inputs=self.user_onehot, units=self.embed_size, activation=self.activation_func, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='user_embed_MLP')self.item_embed_MLP = tf.layers.dense(inputs=self.item_onehot, units=self.embed_size, activation=self.activation_func, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='item_embed_MLP')
GMFGMF部分就是求兩個embedding的內積:
with tf.name_scope("GMF"):self.GMF = tf.multiply(self.user_embed_GMF,self.item_embed_GMF,name='GMF')
MLP
with tf.name_scope("MLP"):self.interaction = tf.concat([self.user_embed_MLP, self.item_embed_MLP], axis=-1, name='interaction')self.layer1_MLP = tf.layers.dense(inputs=self.interaction, units=self.embed_size * 2, activation=self.activation_func, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='layer1_MLP')self.layer1_MLP = tf.layers.dropout(self.layer1_MLP, rate=self.dropout)self.layer2_MLP = tf.layers.dense(inputs=self.layer1_MLP, units=self.embed_size, activation=self.activation_func, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='layer2_MLP')self.layer2_MLP = tf.layers.dropout(self.layer2_MLP, rate=self.dropout)self.layer3_MLP = tf.layers.dense(inputs=self.layer2_MLP, units=self.embed_size // 2, activation=self.activation_func, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='layer3_MLP')self.layer3_MLP = tf.layers.dropout(self.layer3_MLP, rate=self.dropout)
得到預測值
with tf.name_scope('concatenation'):self.concatenation = tf.concat([self.GMF,self.layer3_MLP],axis=-1,name='concatenation')self.logits = tf.layers.dense(inputs= self.concatenation, units = 1, activation=None, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='predict')self.logits_dense = tf.reshape(self.logits,[-1])
測試集構建這里只介紹幾行關鍵的測試集構建代碼,整個流程希望大家可以看一下完整的代碼。需要明確的一點是,對于測試集,我們的評價不只是對錯,還要關注排名,所以測試集的label不是0-1,而是具體的itemid首先,對每個user取最后一行作為測試集的正樣本:
with tf.name_scope('concatenation'):self.concatenation = tf.concat([self.GMF,self.layer3_MLP],axis=-1,name='concatenation')self.logits = tf.layers.dense(inputs= self.concatenation, units = 1, activation=None, kernel_initializer=self.initializer, kernel_regularizer=self.regularizer, name='predict')self.logits_dense = tf.reshape(self.logits,[-1])
添加一些負采樣的樣本, 這里順序是,1正樣本-n負樣本-1正樣本-n負樣本....,每個用戶有n+1條數據,便于計算HR和NDCG:
feature_user.append(user)feature_item.append(item)labels_add.append(label)for k in neg_samples:feature_user.append(user)feature_item.append(k)labels_add.append(k)
不打亂測試集的順序,設置batch的大小為1+n:
dataset = tf.data.Dataset.from_tensor_slices(data)dataset = dataset.batch(test_neg + 1)
計算HR和HDCG
def hr(gt_item, pred_items):if gt_item in pred_items: return 1return 0def ndcg(gt_item, pred_items):if gt_item in pred_items: index = np.where(pred_items == gt_item)[0][0] return np.reciprocal(np.log2(index + 2))return 0
更詳細的代碼可以參考github,最好能夠手敲一遍來理解其原理喲!
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101040 -
數據集
+關注
關注
4文章
1209瀏覽量
24792 -
線性模型
+關注
關注
0文章
9瀏覽量
7840
原文標題:推薦系統遇上深度學習(十一)--神經協同過濾NCF原理及實戰
文章出處:【微信號:atleadai,微信公眾號:LeadAI OpenLab】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于協同過濾的垃圾郵件過濾系統
基于聚類協同過濾推薦算法優化

基于巴氏系數的協同過濾算法
一種基于隱私保護的協同過濾推薦算法
基于用戶興趣的改進型協同過濾算法
基于用戶偏好的協同過濾算法
基于加權的Slope One協同過濾算法
一種協同過濾推薦算法
如何解決協同過濾算法的項目分類不準確問題
基于協同過濾算法的推薦
基于顯式反饋的改進協同過濾算法研究

結合本體語義和用戶屬性的改進協同過濾算法
PyTorch教程21.6之用于個性化排名的神經協同過濾






 工商網監
工商網監
評論