") 基于貝塞爾曲線和RNN的手寫識(shí)別新方法
基于貝塞爾曲線和RNN的手寫識(shí)別新方法
手寫輸入作為與設(shè)備的一種重要交互方式一直都受到各個(gè)廠商的重視,特別是對(duì)于中老年朋友來說,更喜歡通過手寫而不是鍵盤的方式來進(jìn)行輸入。此外,對(duì)于一些復(fù)雜的語言、交互演示場(chǎng)景、試教等,手寫輸入扮演著不可或缺的作用。

15年時(shí)谷歌曾經(jīng)推出了支持82種語言的手寫輸入,并在去年升級(jí)為100種語言。但隨著機(jī)器學(xué)習(xí)的迅速發(fā)展,研究人員也在不斷重構(gòu)著以往的方法為用戶帶來更快更準(zhǔn)的體驗(yàn)。
先前的模型基于人工設(shè)計(jì)的方法,將輸入筆畫切分成單個(gè)字符并利用對(duì)應(yīng)的解碼器進(jìn)行理解。為了提高準(zhǔn)確率和速度,研究人員開發(fā)了基于循環(huán)神經(jīng)網(wǎng)絡(luò)的端到端手寫識(shí)別系統(tǒng),通過將輸入筆畫轉(zhuǎn)為貝塞爾曲線序列進(jìn)行分析處理,利用RNN得到了準(zhǔn)確率更高的識(shí)別結(jié)果。在這篇文章中,研究人員以拉丁字母為例詳解了新型手寫字符識(shí)別背后的故事。
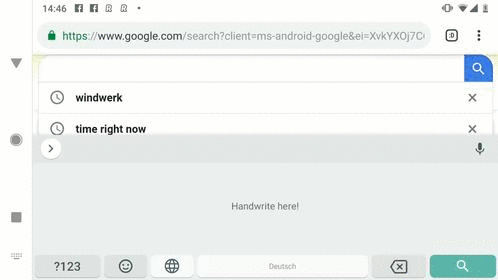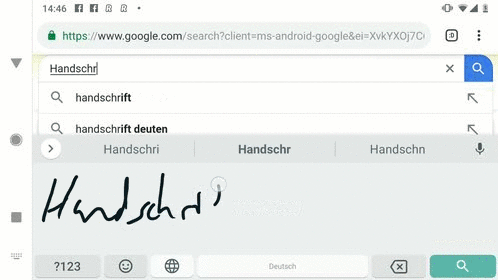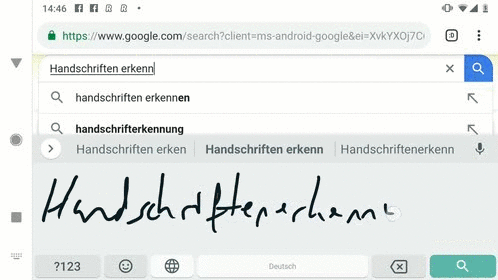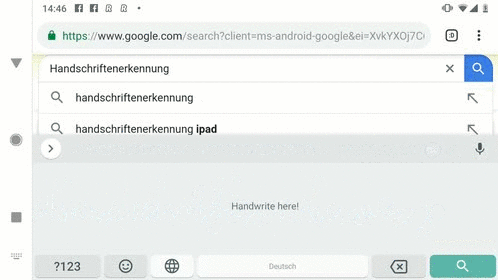
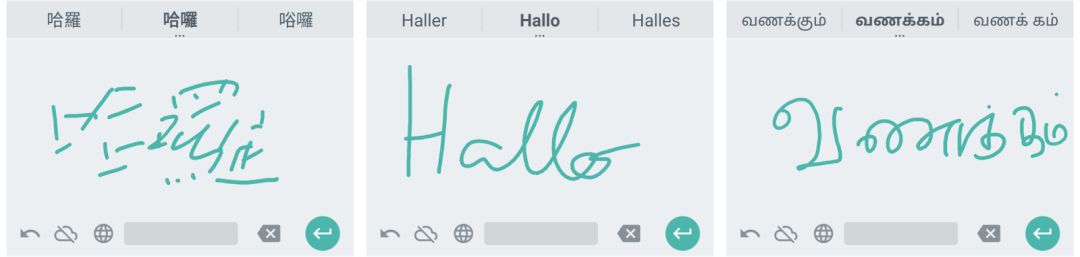
觸點(diǎn)、曲線和循環(huán)神經(jīng)網(wǎng)絡(luò)
任何手寫字符識(shí)別系統(tǒng)都需要從識(shí)別手指/輸入設(shè)備的觸點(diǎn)。我們?cè)谄聊换蛘呤謱懓迳陷斎氲墓P畫可以看做是一系列包含時(shí)間戳的出觸點(diǎn)序列。考慮到輸入的設(shè)備在尺寸、分辨率上各不相同,研究人員首先對(duì)輸入的觸點(diǎn)坐標(biāo)進(jìn)行了歸一化處理。而后利用三次貝塞爾曲線來對(duì)觸點(diǎn)序列進(jìn)行描述,以便RNN能夠更好的理解筆畫序列的形狀。

貝塞爾曲線在手寫識(shí)別中有著很長的應(yīng)用歷史,基于貝塞爾曲線可以對(duì)輸入數(shù)據(jù)進(jìn)行更加連續(xù)的表達(dá),對(duì)于不同的采樣率和分辨率更加魯棒。在貝塞爾曲線表達(dá)中,每一條曲線可以被表示為起始點(diǎn)、終止點(diǎn)和兩個(gè)控制點(diǎn)的多項(xiàng)式,較少的參數(shù)精確的表達(dá)輸入筆畫。

這種方法代替了谷歌先前基于分割-解碼的方案,先前的方案需要先將輸入的筆畫分割成單個(gè)字符,而后利用解碼的方式尋找最有可能的字符。使用貝塞爾曲線表達(dá)輸入筆畫的另一個(gè)優(yōu)點(diǎn)在于它可以更加緊致的表述輸入的觸點(diǎn)序列,這將便于模型從輸入中抽取輸入的時(shí)序依賴性。上圖中顯示了利用貝塞爾曲線擬合“go”字符的過程。原始的輸入點(diǎn)集包含了186個(gè)觸點(diǎn)坐標(biāo),其中對(duì)于字母g可以用圖中的黃色、藍(lán)色、粉色和綠色點(diǎn)來表示四條三次貝塞爾曲線的序列,而對(duì)于字母o可以用橙色、翠綠色和白色表示的三條貝塞爾曲線序列來描述。在貝塞爾曲線序列表示的輸入基礎(chǔ)上,我們需要對(duì)序列進(jìn)行解碼才能得到所表示的字符。RNN是處理序列輸入的有效方式,所以研究人員利用了多層RNN來對(duì)序列數(shù)據(jù)進(jìn)行解碼,并為每一個(gè)輸入序列生成一個(gè)表示其所代表字母可能性的矩陣,從而計(jì)算出手寫筆畫代表的字符。
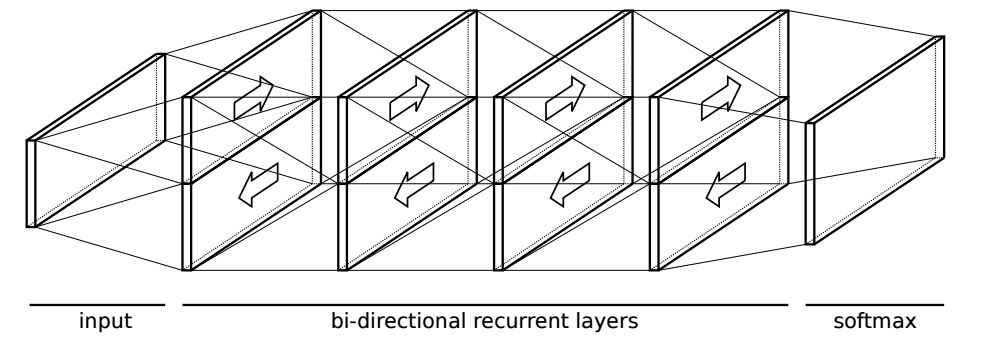
在實(shí)際過程中,研究人員選擇了一種雙向的準(zhǔn)循環(huán)神經(jīng)網(wǎng)絡(luò)來作為處理模型,這種模型中具有交替的卷積和回歸層在理論上具有并行處理的可能性,同時(shí)也在網(wǎng)絡(luò)權(quán)重較少的情況下保持模型的能力。由于手寫字符識(shí)別更多的是在移動(dòng)設(shè)備上進(jìn)行,小尺寸的模型是保持速度的關(guān)鍵所在。

為了對(duì)曲線序列進(jìn)行解碼,識(shí)別出對(duì)應(yīng)的字符,循環(huán)神經(jīng)網(wǎng)絡(luò)會(huì)生成一個(gè)表示字母可能性的解碼矩陣。矩陣的每一列代表了一條貝塞爾曲線,而每一行則代表了對(duì)應(yīng)輸入曲線對(duì)應(yīng)的字母可能性。在上圖中的解碼矩陣中,對(duì)于每一列我們可以看到它和先前的序列一起構(gòu)成了26個(gè)字母上對(duì)應(yīng)的概率分布。第一到第三條曲線序列都對(duì)應(yīng)著blank(代表還沒有識(shí)別出字符,來自于CTC算法),而到了第四條曲線時(shí)網(wǎng)絡(luò)在g字母處得到了較高的概率,這意味著RNN從前面的四條曲線中識(shí)別出了字母g,而后面的第八條曲線上我們又可以看到字母o對(duì)應(yīng)的位置有較高的概率。通過序列處理就能將曲線解碼為對(duì)應(yīng)的字符。
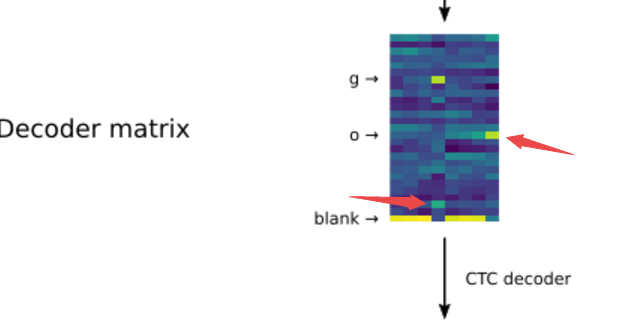
此外還有兩個(gè)有趣的現(xiàn)象值得注意,對(duì)于字母g的識(shí)別,在第四列中y字母(倒數(shù)第二個(gè))對(duì)應(yīng)的激活也比較高,這是因?yàn)間和y看起來比較類似。而對(duì)于o字母的識(shí)別,每一條曲線輸入后o對(duì)應(yīng)的概率在不斷提升,這也和我們的直覺相吻合,o代表的圓圈畫的越完整是o的可能性就越大。此外研究人員還引入了有限狀態(tài)語言模型解碼器來對(duì)網(wǎng)絡(luò)的輸出進(jìn)行組合,對(duì)于某些常見的字符組合會(huì)有更大的可能性輸入,這樣就可以快速的將解碼出的字符轉(zhuǎn)換為單詞輸出。總結(jié)下來新方法一共分為了三個(gè)主要步驟,首先將觸點(diǎn)序列轉(zhuǎn)為緊湊的貝塞爾曲線,隨后利用QRNN進(jìn)行解碼,最后利用字符結(jié)果組合出對(duì)應(yīng)的單詞。雖然看起來很簡單,但這種方法相比原先的方法使得識(shí)別的錯(cuò)誤率下降了20%-40%!
關(guān)于模型訓(xùn)練
模型的訓(xùn)練分為兩部分,一部分是基于connectionist temporal classification(CTC)損失對(duì)模型進(jìn)行訓(xùn)練,另一部分是基于貝葉斯優(yōu)化的解碼器調(diào)參。訓(xùn)練的數(shù)據(jù)主要包含了三個(gè)數(shù)據(jù)集,分別是IAM-OnDB在線手寫字符數(shù)據(jù)集,IBM-UB-1英語數(shù)據(jù)集,以及ICDAR 2013的中文數(shù)據(jù)集Chinese Isolated Characters,ICFHR2018中的越南語數(shù)據(jù)集。詳細(xì)的數(shù)據(jù)集鏈接請(qǐng)參看文末參考文獻(xiàn)。
設(shè)備部署
對(duì)于手寫識(shí)別來說,精確的模型沒有速度的保證對(duì)于用戶來說是無法忍受的。為了減小手寫輸入的延時(shí),研究人員將模型在tensorflow Lite上進(jìn)行了實(shí)現(xiàn),通過如量化等一系列手段成功地減小了模型和最終應(yīng)用安裝包的大小。完善的模型加上小巧的實(shí)現(xiàn)將讓手機(jī)更容易看懂我們筆跡。如果想要了解更多細(xì)節(jié),請(qǐng)參考原文:
https://arxiv.org/pdf/1902.10525.pdf
-
解碼器
+關(guān)注
關(guān)注
9文章
1147瀏覽量
40869 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101039 -
rnn
+關(guān)注
關(guān)注
0文章
89瀏覽量
6900
原文標(biāo)題:Google手寫字符識(shí)別的新進(jìn)展
文章出處:【微信號(hào):thejiangmen,微信公眾號(hào):將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
識(shí)別傳感器信號(hào)的新方法

并聯(lián)APF直流側(cè)電壓選擇新方法

VLSI系統(tǒng)設(shè)計(jì)的最新方法
貝塞爾光束產(chǎn)生的常用方式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論